

PythonのParselを用いたウェブスクレイピングに関するこのガイドでは、以下の内容を学びます:
- Parselとは何か
- ウェブスクレイピングにParselを使用する理由
- – Parselを用いたウェブスクレイピングの手順を解説するステップバイステップチュートリアル
- PythonのParselを用いた高度なスクレイピングシナリオ
さあ、始めましょう!
Parselとは?
Parselは、HTML、XML、JSONドキュメントからデータをパース・抽出するためのPythonライブラリです。lxmlを基盤として構築されており、ウェブスクレイピングのためのより高レベルでユーザーフレンドリーなインターフェースを提供します。具体的には、HTMLやXMLドキュメントからのデータ抽出プロセスを簡素化する直感的なAPIを備えています。
ウェブスクレイピングにParselを使う理由
Parselには、以下のようなウェブスクレイピング向けの興味深い機能があります:
- XPathとCSSセレクタのサポート:HTMLやXML文書内の要素を特定するために、XPathまたはCSSセレクタのいずれかを使用できます。詳細については、ウェブスクレイピングにおけるXPathとCSSセレクタの比較ガイドをご覧ください。
- データ抽出:選択した要素からテキスト、属性、その他のコンテンツを取得します。
- セレクタの連鎖: 複数のセレクタを連鎖させてデータ抽出を精緻化できます。
- スケーラビリティ:小規模から大規模なスクレイピングプロジェクトまで幅広く対応します。
このライブラリはScrapyと緊密に統合されており、Scrapyはこれを使用してウェブページからデータをパース・抽出します。ただし、Parselはスタンドアロンライブラリとしても利用可能です。
PythonでParselを使ったウェブスクレイピングの方法:ステップバイステップチュートリアル
このセクションでは、PythonのParselを用いたウェブスクレイピングのプロセスをガイドします。対象サイトは「Hockey Teams: Forms, Searching and Pagination」とします:

Parselスクレイパーは上記テーブルの全データを抽出します。以下の手順に従い構築方法を確認しましょう!
前提条件と依存関係
このチュートリアルを再現するには、マシンにPython 3.10.1以降がインストールされている必要があります。特に、Parselは最近Python 3.8のサポートを終了したことに注意してください。
プロジェクトのメインフォルダをparsel_scraping/とします。このステップ終了時、フォルダ構造は以下のようになります:
parsel_scraping/
├── parsel_scraper.py
└── venv/各要素の説明:
parsel_scraper.pyはスクレイピングロジックを含む Python ファイルです。venv/は仮想環境を含みます。
venv/ 仮想環境ディレクトリは以下のように作成できます:
python -m venv venvWindowsで有効化するには、以下を実行します:
venvScriptsactivatemacOS および Linux では、同等の操作として以下を実行します:
source venv/bin/activateアクティブ化された仮想環境内で、依存関係をインストールするには:
pip install parsel requestsこれらの2つの依存関係は次の通りです:
parsel: HTMLをパースしデータを抽出するためのライブラリ。requests:parselはHTMLパーサーのみのため必須です。ウェブスクレイピングを行うには、スクレイピング対象ページのHTML文書を取得するためのRequestsのようなHTTPクライアントも必要です。
素晴らしい!これでPythonのParselを用いたウェブスクレイピングに必要な環境が整いました。
ステップ1: 対象URLを定義しコンテンツをパースする
このチュートリアルの最初のステップとして、ライブラリをインポートする必要があります:
import requests
from parsel import Selector次に、対象ウェブページを定義し、Requestsでコンテンツを取得し、Parselでパースします:
url = "https://www.scrapethissite.com/pages/forms/"
response = requests.get(url)
selector = Selector(text=response.text)上記のスニペットは、Parsel のSelector()クラスをインスタンス化します。これは、get() で実行した HTTP リクエストのレスポンスから読み取った HTML をパースします。
ステップ2: テーブルから全行を抽出
対象ウェブページのテーブルをブラウザで確認すると、以下のHTMLが表示されます:
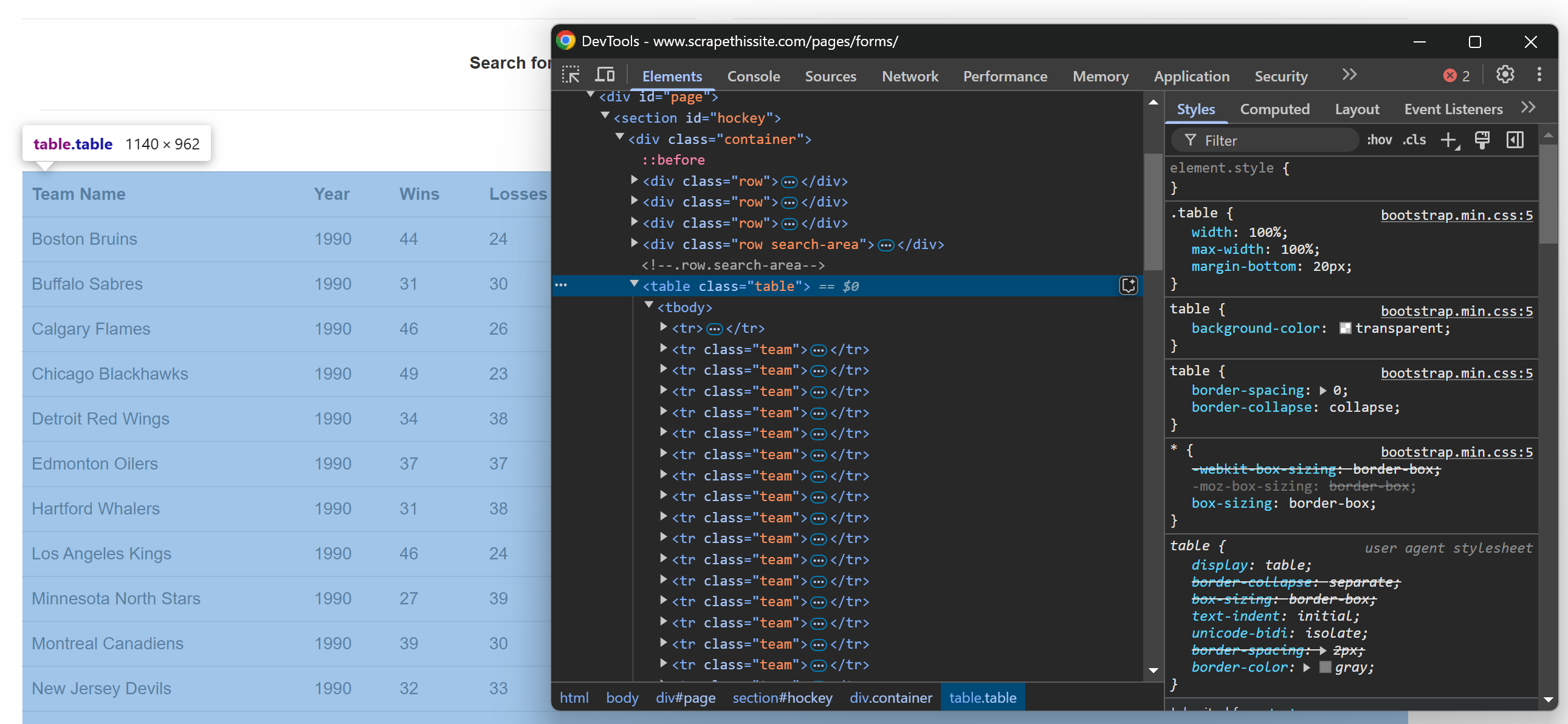
テーブルには複数の行が含まれるため、スクレイピングしたデータを格納する配列を初期化します:
data = []HTMLテーブルは.tableクラスを持っていることに注意してください。テーブルから全ての行を選択するには、以下のコード行を使用できます:
rows = selector.css("table.table tr.team")これはcss()メソッドを使用し、パースされたHTML構造にCSSセレクタを適用します。
選択した行を反復処理し、データを抽出しましょう!
ステップ3: 行の反復処理
以前と同様に、テーブル内の行を検査します:
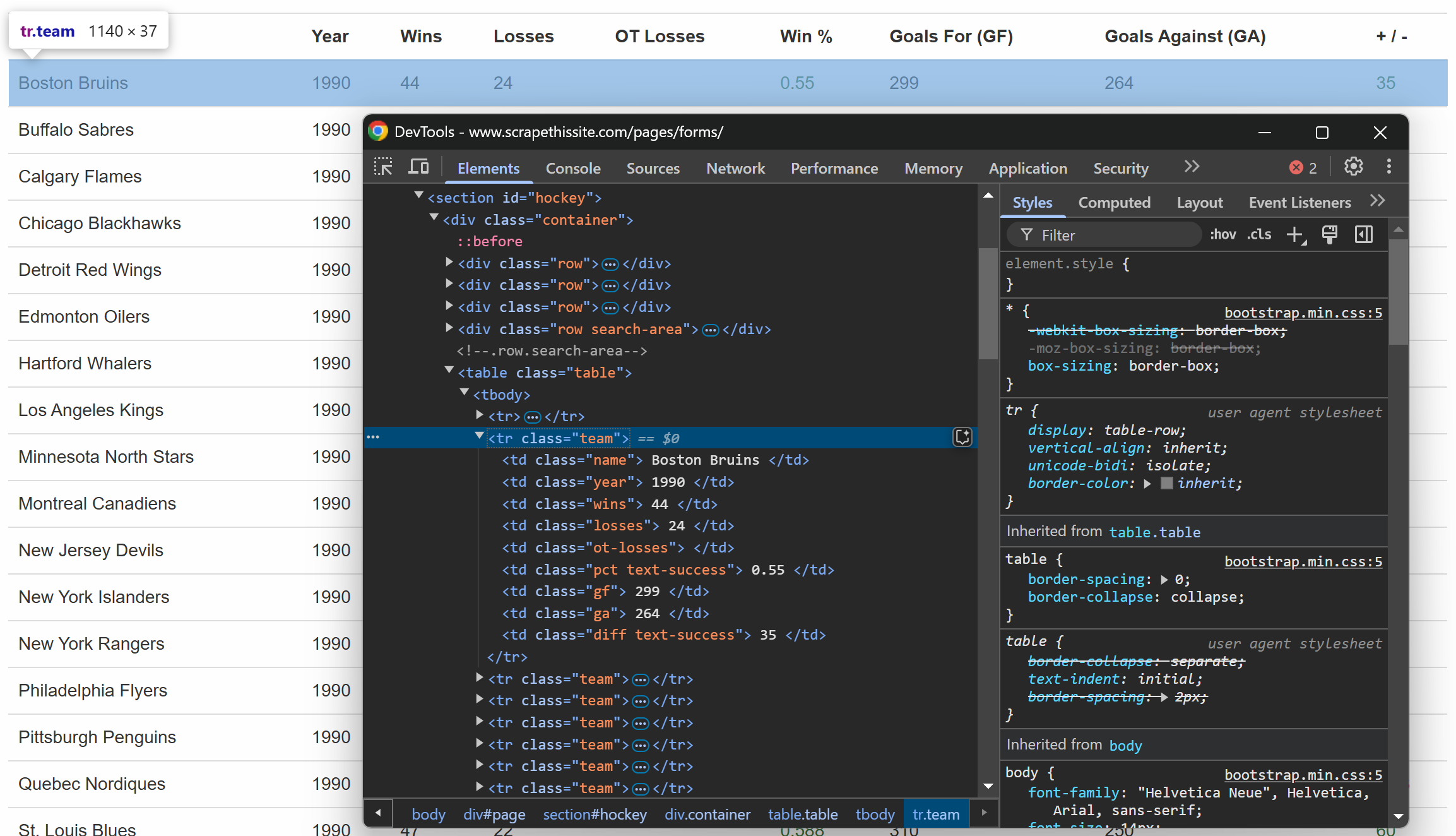
各行には専用の列に以下の情報が含まれていることがわかります:
- チーム名 →
.name要素内 - シーズン年 →
.year要素内に - 勝利数 →
.wins要素内 - 敗戦数 →
.losses要素内 - 延長戦敗戦 →
.ot-losses要素内 - 勝率 →
.pct要素内 - 得点(得点 – GF) →
.gf要素内 - 失点数(失点 – GA) →
.ga要素内 - 得失点差 →
.diff要素内
以下のロジックで全情報を抽出可能:
for row in rows:
# 各列からデータを抽出
name = row.css("td.name::text").get()
year = row.css("td.year::text").get()
wins = row.css("td.wins::text").get()
losses = row.css("td.losses::text").get()
ot_losses = row.css("td.ot-losses::text").get()
pct = row.css("td.pct::text").get()
gf = row.css("td.gf::text").get()
ga = row.css("td.ga::text").get()
diff = row.css("td.diff::text").get()
# 抽出したデータを追加
data.append({
"name": name.strip(),
"year": year.strip(),
"wins": wins.strip(),
"losses": losses.strip(),
"ot_losses": ot_losses.strip(),
"pct": pct.strip(),
"gf": gf.strip(),
"ga": ga.strip(),
"diff": diff.strip()
})上記のコードは以下を行います:
素晴らしい!データスクレイピングのパースロジックが完了しました。
ステップ4: データの出力とプログラムの実行
最終ステップとして、スクレイピングしたデータを CLI で出力します:
# 抽出データを表示
print("ページからのデータ:")
for entry in data:
print(entry)プログラムを実行:
python parsel_scraper.py期待される結果は次の通りです:
素晴らしい!ページ上のデータが構造化された形式で正確に取得できました。
ステップ5: ページネーションの管理
これまでの手順では、対象URLのメインページからデータを取得していました。では、すべてのページを取得したい場合はどうすればよいでしょうか?そのためには、コードにいくつかの変更を加えてページネーションを管理する必要があります。
まず、以前のコードを次のような関数にカプセル化します:
def scrape_page(url):
# ページコンテンツを取得
response = requests.get(url)
# HTMLコンテンツをパース
selector = Selector(text=response.text)
# スクラッピングロジック...
return data次に、ページネーションを管理するHTML要素を確認します:
これは全ページのリストを含み、各ページURLが<a>要素に埋め込まれています。全ページネーションURLを取得するロジックを関数にカプセル化します:
def get_all_page_urls(base_url="https://www.scrapethissite.com/pages/forms/"):
# ページネーションリンク抽出用の最初のページを取得
response = requests.get(base_url)
# ページをパース
selector = Selector(text=response.text)
# ページネーション領域から全ページリンクを抽出
page_links = selector.css("ul.pagination li a::attr(href)").getall() # HTML構造に応じてセレクタを調整
unique_links = list(set(page_links)) # 重複があれば除去
# 全ページの完全なURLを構築
full_urls = [urljoin(base_url, link) for link in unique_links]
return full_urlsこの関数は以下の処理を行います:
getall()メソッドは全ページネーションリンクを取得します。list(set())メソッドは重複を削除し、同一ページへの二重アクセスを防止します。urljoin()メソッド(urllib.parseライブラリ)は、すべての相対URLを絶対URLに変換し、以降のHTTPリクエストで使用できるようにします。
上記のコードを動作させるには、Python標準ライブラリからurljoinをインポートしてください:
from urllib.parse import urljoin これで以下のコードですべてのページをスクレイピングできます:
# スクレイピングしたデータの保存先
data = []
# 全ページのURLを取得
page_urls = get_all_page_urls()
# URLを反復処理しスクレイピングロジックを適用
for url in page_urls:
# 現在のページをスクレイピング
page_data = scrape_page(url)
# スクレイピングデータをリストに追加
data.extend(page_data)
# 抽出データを表示
print("全ページのデータ:")
for entry in data:
print(entry)上記のスニペット:
- 関数
get_all_page_urls()を呼び出して全ページURLを取得します。 - 各ページからデータをスクレイピングするために関数
scrape_page()を呼び出します。その後、メソッドextend()で結果を集約します。 - スクレイピングしたデータを表示します。
素晴らしい!これでParselのページネーションロジックが実装されました。
ステップ6: 全てを統合する
以下の内容がparsel_scraper.pyファイルに記述されているはずです:
import requests
from parsel import Selector
from urllib.parse import urljoin
def scrape_page(url):
# ページコンテンツを取得
response = requests.get(url)
# HTMLコンテンツをパース
selector = Selector(text=response.text)
# スクレイピングしたデータの保存先
data = []
# テーブル本体の全行を選択
rows = selector.css("table.table tr.team")
# 各行を反復処理しデータをスクレイピング
for row in rows:
# 各列からデータを抽出
name = row.css("td.name::text").get()
year = row.css("td.year::text").get()
wins = row.css("td.wins::text").get()
losses = row.css("td.losses::text").get()
ot_losses = row.css("td.ot-losses::text").get()
pct = row.css("td.pct::text").get()
gf = row.css("td.gf::text").get()
ga = row.css("td.ga::text").get()
diff = row.css("td.diff::text").get()
# 抽出データをリストに追加
data.append({
"name": name.strip(),
"year": year.strip(),
"wins": wins.strip(),
"losses": losses.strip(),
"ot_losses": ot_losses.strip(),
"勝率": pct.strip(),
"GF": gf.strip(),
"GA": ga.strip(),
"差": diff.strip(),
})
return data
def get_all_page_urls(base_url="https://www.scrapethissite.com/pages/forms/"):
# ページネーションリンク抽出のため最初のページを取得
response = requests.get(base_url)
# ページをパース
selector = Selector(text=response.text)
# ページネーション領域から全ページリンクを抽出
page_links = selector.css("ul.pagination li a::attr(href)").getall() # HTML構造に応じてセレクタを調整
unique_links = list(set(page_links)) # 重複があれば除去
# 全ページの完全なURLを構築
full_urls = [urljoin(base_url, link) for link in unique_links]
return full_urls
# スクレイピングしたデータの保存先
data = []
# 全ページのURLを取得
page_urls = get_all_page_urls()
# ページURLを反復処理しスクレイピングロジックを適用
for url in page_urls:
# 現在のページをスクレイピング
page_data = scrape_page(url)
# スクレイピングデータをリストに追加
data.extend(page_data)
# 抽出データを表示
print("全ページからのデータ:")
for entry in data:
print(entry)素晴らしい!これでParselを使った最初のスクラッピングプロジェクトが完了しました。
PythonのParselを用いた高度なウェブスクレイピングシナリオ
前のセクションでは、PythonのParselを使用してCSSセレクタで対象ウェブページからデータを抽出する方法を学びました。次は、より高度なシナリオを考えてみましょう!
テキストによる要素の選択
ParselはXPathを用いてHTMLからテキストを取得する様々なクエリメソッドを提供します。この場合、text()関数を使用して要素のテキストコンテンツを抽出します。
次のようなHTMLコードがあると想像してください:
<html>
<body>
<h1>Welcome to Parsel</h1>
<p>This is a paragraph.</p>
<p>Another paragraph.</p>
</body>
</html>すべてのテキストは次のように取得できます:
from parsel import Selector
html = """
<html>
<body>
<h1>Welcome to Parsel</h1>
<p>This is a paragraph.</p>
<p>Another paragraph.</p>
</body>
</html>
"""
selector = Selector(text=html)
# <h1>タグからテキストを抽出
h1_text = selector.xpath("//h1/text()").get()
print("H1テキスト:", h1_text)
# 全ての<p>タグからテキストを抽出
p_texts = selector.xpath("//p/text()").getall()
print("段落テキストノード:", p_texts)このスニペットは<p>と<h1>タグを特定し、text()でテキストを抽出します。結果は以下の通りです:
H1 Text: Welcome to Parsel
Paragraph Text Nodes: ['This is a paragraph.', 'Another paragraph.']もう1つの便利な関数がcontains()です。これは特定のテキストを含む要素を一致させるために使用できます。例えば、次のようなHTMLコードがあるとします:
<html>
<body>
<p>これはテスト段落です。</p>
<p>別のテスト段落です。</p>
<p>無関係なコンテンツです。</p>
</body>
</html>ここで、段落内のテキストから「test」という単語のみを含む部分を抽出したいとします。以下のコードで実現できます:
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# "test" を含む段落を抽出
test_paragraphs = selector.xpath("//p[contains(text(), 'test')]/text()").getall()
print("'test' を含む段落:", test_paragraphs)XPathp[contains(text(), 'test')]/text()は「test」のみを含む段落をクエリします。結果は次のようになります:
'test'を含む段落: ['これはテスト段落です。', '別のテスト段落です。']では、特定の文字列で始まるテキストを抽出したい場合はどうすればよいでしょうか?starts-with()関数を使用できます!次の HTML を考えてみましょう:
<html>
<body>
<p>Start here.</p>
<p>Start again.</p>
<p>End here.</p>
</body>
</html>「start」という単語で始まる段落のテキストを取得するには、p[starts-with(text(), 'Start')]/text()のように使用します:
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# 「Start」で始まるテキストを含む段落を抽出
start_paragraphs = selector.xpath("//p[starts-with(text(), 'Start')]/text()").getall()
print("'Start'で始まる段落:", start_paragraphs)上記のコードは以下を出力します:
'Start' で始まる段落: ['Start here.', 'Start again.']CSSとXPathセレクタの違いについて詳しく学ぶ。
正規表現の使用
Parselでは、re:test()関数で正規表現を使用することで、高度な条件に合致するテキストを取得できます。
次のHTMLを考えてみましょう:
<html>
<body>
<p>アイテム 12345</p>
<p>アイテム ABCDE</p>
<p>段落</p>
<p>2026 年は現在の年です</p>
</body>
</html>数値のみを含む段落のテキストを抽出するには、re:test()を次のように使用します:
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# テキストが数値パターンに一致する段落を抽出
numeric_items = selector.xpath("//p[re:test(text(), 'd+')]/text()").getall()
print("数値項目:", numeric_items)結果は次の通りです:
数値項目: ['Item 12345', '2026 is the current year']正規表現のもう一つの典型的な用途はメールアドレスの抽出です。これにより、メールアドレスのみを含む段落からテキストを抽出できます。例えば、以下のHTMLを考えてみましょう:
<HTML>
<BODY>
<P>お問い合わせは [email protected] まで</P>
<P>メールは [email protected] へお送りください</P>
<P>ここにメールアドレスはありません</P>
</BODY>
</HTML>以下は、re:test()を使用してメールアドレスを含むノードを選択する方法です:
from parsel import Selector
selector = Selector(text=html)
# メールアドレスを含む段落を抽出
emails = selector.xpath("//p[re:test(text(), '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}')]/text()").getall()
print("一致したメールアドレス:", emails)結果:
Email Matches: ['お問い合わせは [email protected]まで、メールは [email protected]までご送信ください']HTMLツリーの探索
Parselでは、XPathを使用してHTMLツリーをナビゲートできます。どれだけネストされていても問題ありません。
次のHTMLを考えてみましょう:
<html>
<body>
<div>
<h1>タイトル</h1>
<p>最初の段落</p>
</div>
</body>
</html><p>ノードのすべての親要素を次のように取得できます:
from parsel import Selector
selector = Selector(text=html)
# <p>タグの親要素を選択
parent_of_p = selector.xpath("//p/parent::*").get()
print("<p>の親要素:", parent_of_p)結果:
Parent of <p>: <div>
<h1>Title</h1>
<p>First paragraph</p>
</div>同様に、兄弟要素も管理できます。次のようなHTMLコードがあるとします:
<html>
<body>
<ul>
<li>項目1</li>
<li>項目2</li>
<li>項目3</li>
</ul>
</body>
</html>兄弟要素を取得するには、following-siblingを使用します:
from parsel import Selector
selector = Selector(text=html)
# 最初の<li>要素の次の兄弟要素を選択
next_sibling = selector.xpath("//li[1]/following-sibling::li[1]/text()").get()
print("最初の<li>の次の兄弟要素:", next_sibling)
# 最初の<li>要素のすべての兄弟要素を選択
all_siblings = selector.xpath("//li[1]/following-sibling::li/text()").getall()
print("最初の<li>のすべての兄弟要素:", all_siblings)結果:
最初の<li>の次の兄弟要素: Item 2
最初の<li>のすべての兄弟要素: ['Item 2', 'Item 3']PythonにおけるHTMLパースのパース代替手段
ParselはPythonでウェブスクレイピングに利用できるライブラリの一つですが、唯一のものではありません。以下に他のよく知られ広く使われているものを挙げます:
- Beautiful Soup: ウェブページから情報を簡単にスクレイピングできるPythonライブラリ。Beautiful Soupを用いたウェブスクレイピングガイドでその使用方法を学べます。
lxml:libxml2およびlibxsltライブラリ向けのPythonicなバインディングです。ウェブデータパースのためのlxmlチュートリアルで実際の動作を確認してください。- PyQuery: XMLドキュメントに対してjQueryクエリを実行可能にするライブラリ。これにより、Python HTMLパーサーのベスト5の一つとなっています。
- Scrapy: ウェブサイトから必要なデータを抽出するためのオープンソースで共同開発型のフレームワーク。Scrapyを使ったウェブスクレイピングの方法をご覧ください。
html.parser: Python標準ライブラリのモジュール。テキスト形式のHTMLおよびXTHMLコンテンツをパースするクラスを提供します。html5-parser: Python による HTML 5 の高速実装。
まとめ
この記事では、PythonのParselとウェブスクレイピングでの活用方法を学びました。基礎から始め、より複雑なシナリオを探求しました。
どのPythonスクレイピングライブラリを使用する場合でも、最大の障壁は、ほとんどのウェブサイトがデータをボット対策やスクレイピング対策で保護していることです。これらの防御策は自動化されたリクエストを識別してブロックするため、従来のスクレイピング手法は無効化されます。
幸い、Bright Dataはあらゆる問題を回避するソリューション群を提供しています:
- Web Unlocker: アンチスクレイピング対策を回避し、最小限の労力であらゆるウェブページからクリーンなHTMLを配信するAPI。
- スクレイピングブラウザ: JavaScriptレンダリング機能を備えたクラウドベースの制御可能なブラウザ。CAPTCHA、ブラウザフィンガープリント、再試行などを自動的に処理します。PantherやSelenium PHPとシームレスに連携します。
- WebスクレイパーAPI:数十の人気ドメインから構造化されたウェブデータへプログラムでアクセスするためのエンドポイント。
ウェブスクレイピングは扱いたくないが、オンラインデータには興味がある?すぐに使えるデータセットを探索しよう!
Bright Dataに今すぐ登録し、無料トライアルでスクレイピングソリューションをお試しください。





