このガイドでは
- ウェブサイトをMarkdownにスクレイピングすることの意味と、なぜそれが便利なのか。
- 静的サイトと動的サイトのためにウェブページのHTMLをMarkdownに変換する主なアプローチ。
- Pythonを使ってウェブページをMarkdownにスクレイピングする方法。
- このソリューションの限界とBright Dataでそれを克服する方法。
さあ、始めましょう!
ウェブサイトをMarkdownにスクレイピング “とはどういう意味ですか?
ウェブサイトをMarkdownにスクレイピング “とは、コンテンツをMarkdownに変換することを意味します。
具体的には、ウェブページのHTMLをMarkdownデータフォーマットに変換することです。
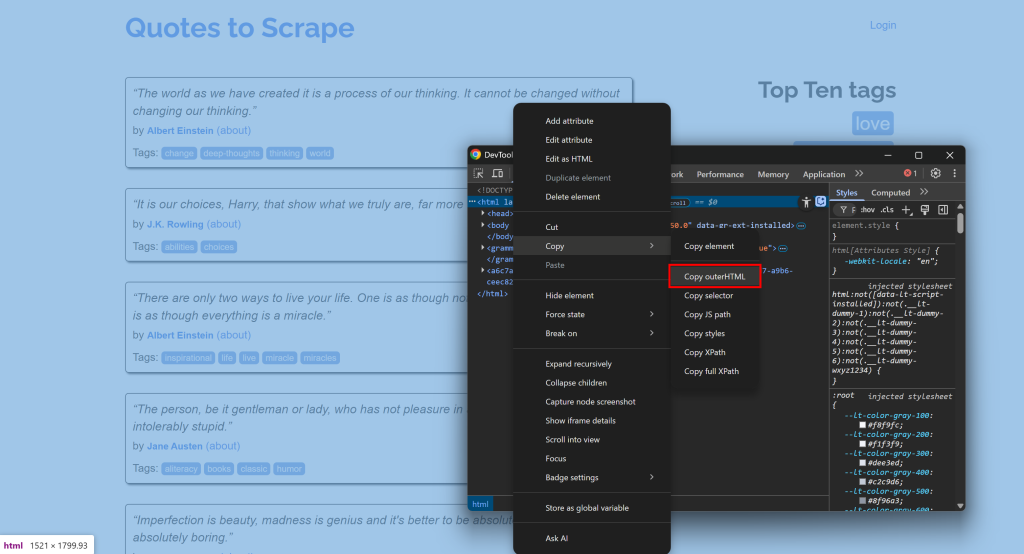
例えば、サイトに接続し、DevToolsを開き、そのHTMLをコピーします:
そして、それをHTMLからMarkdownへのコンバーターに貼り付けます:
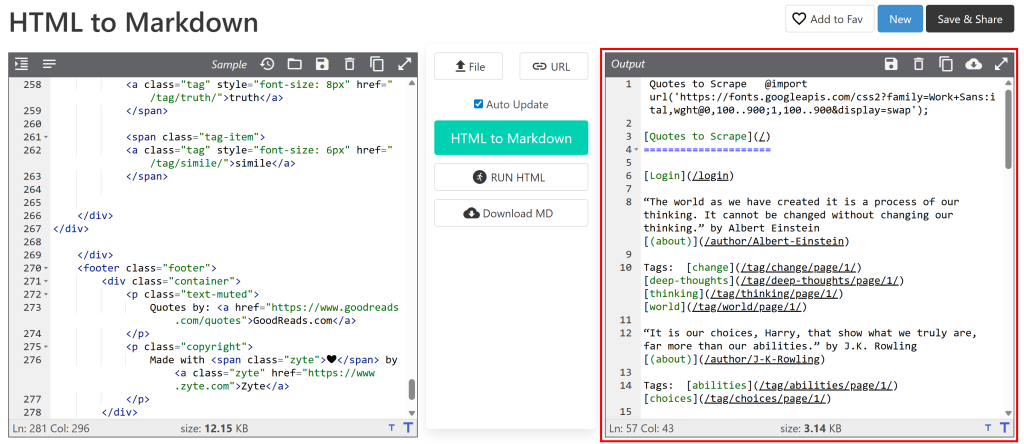
出力は、ウェブスクレイピングで取得したいMarkdownドキュメントと同じように見えるだろう。さて、ゴールはこのプロセスを自動化することであり、それこそがこの記事の主題である!
[おまけ】なぜMarkdownなのか?
なぜ他のフォーマット(プレーンテキストなど)ではなくMarkdownなのか?なぜなら、データフォーマットのベンチマークで示したように、MarkdownはLLMの取り込みに最適なフォーマットの1つだからです。理由のトップ3は
- ページの構造や情報(リンク、画像、見出しなど)をほとんど保持できる。
- 簡潔であるため、トークンの使用が制限され、AIの処理が速くなる。
- LLMは、プレーンなHTMLよりもMarkdownを理解する傾向がある。
これが、最高のAIスクレイピング・ツールがMarkdownでの作業をデフォルトとしている理由だ。
HTMLからMarkdownへのアプローチ
サイトをMarkdownにスクレイピングするということは、単にそのページのHTMLをMarkdownに変換するということであることはお分かりいただけただろう。大まかに言うと、プロセスは以下のようになる:
- サイトに接続する。
- HTMLを文字列として取得する。
- HTML-to-Markdownライブラリを使用して、Markdown出力を生成する。
課題は、すべてのウェブページが同じ方法で配信されるわけではないということだ。最初の2つのステップは、ターゲット・ページが静的か動的かによって大きく異なります。必要なステップを拡張することで、両方のシナリオに対応する方法を探ってみましょう!
ステップ #1: サイトへの接続
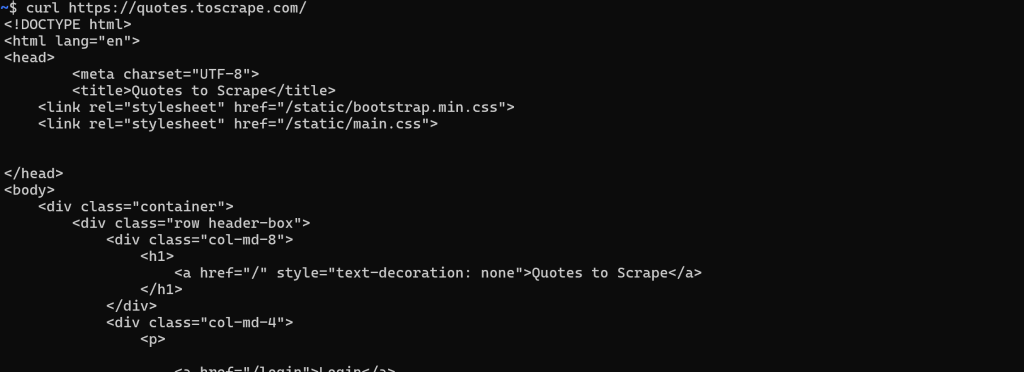
静的なウェブページの場合、サーバーから返されるHTMLドキュメントは、ブラウザに表示されるものとまったく同じです。言い換えれば、サーバーが生成するHTMLにはすべてが固定され、埋め込まれています。
この場合、HTMLを取得するのは簡単です。どのHTTPクライアントでも、ページのURLに対してGET HTTPリクエストを実行するだけでよい:
対照的に、動的ウェブサイトでは、コンテンツの大部分(または一部)がAJAX経由で取得され、JavaScript経由でブラウザにレンダリングされる。つまり、ウェブサーバーから返される最初のHTMLドキュメントには、必要最低限のものしか含まれていません。クライアント側でJavaScriptが実行された後、初めてページに完全なコンテンツが入力されます:

このような場合、単純なHTTPクライアントでHTMLを取得することはできません。代わりに、ブラウザ自動化ツールのような、ページを実際にレンダリングできるツールが必要になる。Playwright、Puppeteer、Seleniumのようなソリューションを使えば、プログラムでブラウザを制御して対象ページを読み込ませ、完全にレンダリングされたHTMLを取得することができる。
ステップ #2: HTMLを文字列として取得する
静的なウェブページの場合、このステップは簡単です。GETリクエストに対するウェブサーバーからのレスポンスには、すでに完全なHTMLドキュメントが文字列として含まれています。ほとんどのHTTPクライアントは、PythonのRequestsのように、直接アクセスするためのメソッドやフィールドを提供しています:
url = "https://quotes.toscrape.com/"
レスポンス = requests.get(url)
# ページのHTMLコンテンツに文字列でアクセスする
html = response.text動的なウェブサイトの場合は、もっとやっかいだ。今回は、サーバーから返された生のHTMLドキュメントに興味があるわけではありません。その代わりに、ブラウザがページをレンダリングしてDOMが安定するまで待ち、それから最終的なHTMLにアクセスする必要がある。
これは通常、DevToolsを開いて<html>ノードからHTMLをコピーすることによって手動で行うことに相当します:
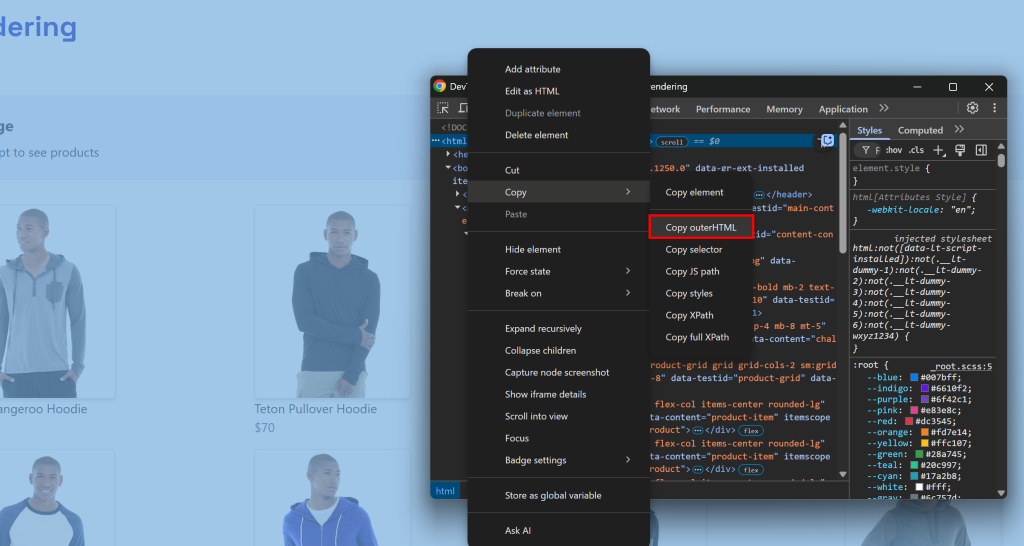
課題は、ページのレンダリングがいつ終了したかを知ることです。一般的な戦略には次のようなものがあります:
-
DOMContentLoadedイベントを待つ:最初のHTMLが解析され、遅延された<script>が読み込まれて実行されたときにパースされます。このイベントを待つのがPlaywrightのデフォルトの動作です。 -
loadイベントを待つ:スタイルシート、スクリプト、iframe、イメージ(遅延ロードされたものを除く)など、ページ全体がロードされたときに発生します。 -
networkidleイベントを待つ:指定された時間(たとえば、Playwrightでは500ミリ秒)ネットワークからのリクエストがない場合に、レンダリングが完了したとみなします。これは決して発生しないため、ライブ更新コンテンツを含むサイトでは信頼できません。 - 特定の要素を待つ:ブラウザ自動化フレームワークが提供するカスタム待ちAPIを使用して、特定の要素がDOMに表示されるまで待ちます。
ページが完全にレンダリングされたら、ブラウザ自動化ツールが提供する特定のメソッド/フィールドを使用してHTMLを抽出できます。例えば、Playwrightでは
html = await page.content()ステップ #3: HTML-to-Markdownライブラリを使用してMarkdown出力を生成する
HTMLを文字列として取得したら、それをHTML-to-Markdownライブラリのどれかに渡すだけです。最も人気があるのは
| ライブラリ | プログラミング言語 | GitHubスター |
|---|---|---|
markdownify |
Python | 1.8k+ |
ターンダウン |
JavaScript/Node.js | 10k+ |
Html2Markdown |
C# | 300+ |
コモンマークジャバ |
Java | 2.5k+ |
html-to-マークダウン |
囲碁 | 3k+ |
html-to-マークダウン |
PHP | 1.8k+ |
ウェブサイトをMarkdownにスクレイピングする:実用的なPythonの例
このセクションでは、ウェブサイトをMarkdownにスクレイピングするための完全なPythonスニペットを紹介します。以下のスクリプトは、先に説明したステップを実装します。ロジックをJavaScriptや他のプログラミング言語に簡単に変換できることに注意してください。
入力はウェブページのURLで、出力は対応するMarkdownコンテンツになります!
静的サイト
この例では、以下の2つのライブラリを使用します:
リクエストGETリクエストを行い、ページのHTMLを文字列として取得します。markdownify:ページのHTMLをMarkdownに変換する。
この2つのライブラリをインストールする:
pip install requests markdownifyターゲットページは、静的な “Quotes to Scrape“ページになる。以下のスニペットで目的を達成できる:
import requests
from markdownify import markdownify as md
# スクレイピングするページのURL
url = "http://quotes.toscrape.com/"
# リクエストを使ってHTMLコンテンツを取得する
レスポンス = requests.get(url)
# HTMLを文字列として取得する
html_content = response.text
# HTMLコンテンツをMarkdownに変換する
markdown_content = md(html_content)
# マークダウンの出力を印刷する
print(markdown_content)オプションで、コンテンツを.mdファイルにエクスポートすることができます:
with open("page.md", "w", encoding="utf-8") as f:
f.write(markdown_content)スクリプトの結果はこうなる:
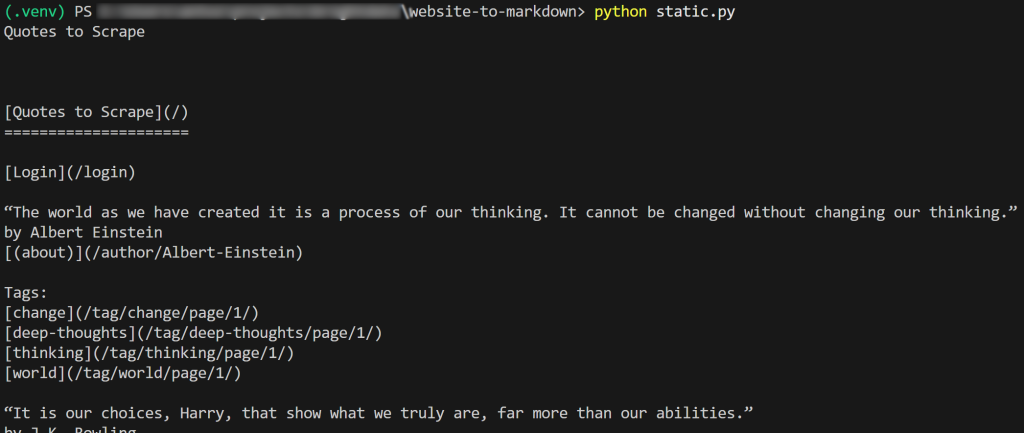
出力されたMarkdownをコピーしてMarkdownレンダラーに貼り付けると、次のようになる:
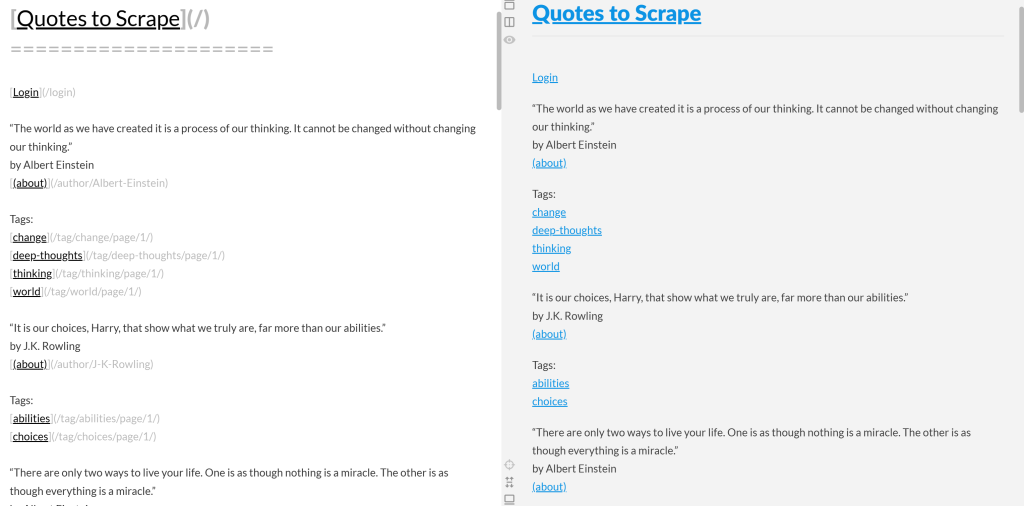
これが、”Quotes to Scrape “ページのオリジナル・コンテンツの簡略版のように見えることに注目してほしい:
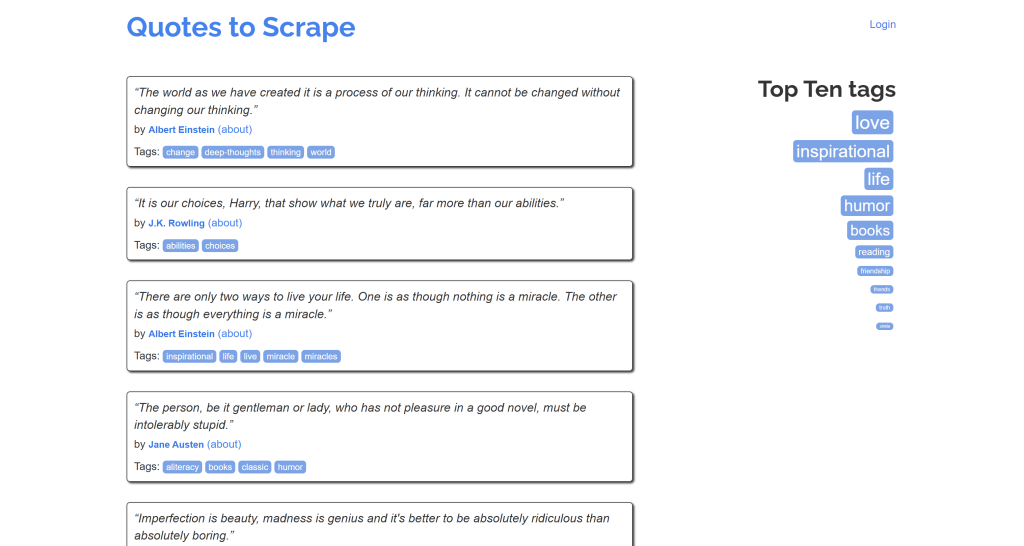
ミッション完了!
ダイナミックサイト
ここでは、以下の2つのライブラリを利用する:
playwright:コントロールされたブラウザのインスタンスでターゲットページをレンダリングする。markdownify:レンダリングされたページのDOMをMarkdownに変換する。
上記の2つの依存関係をインストールします:
pip install playwright markdownify次に、Playwrightのインストールを完了します:
python -m playwright installデスティネーションは、ScrapingCourse.comサイトのダイナミックな “JavaScriptレンダリング“ページになる:
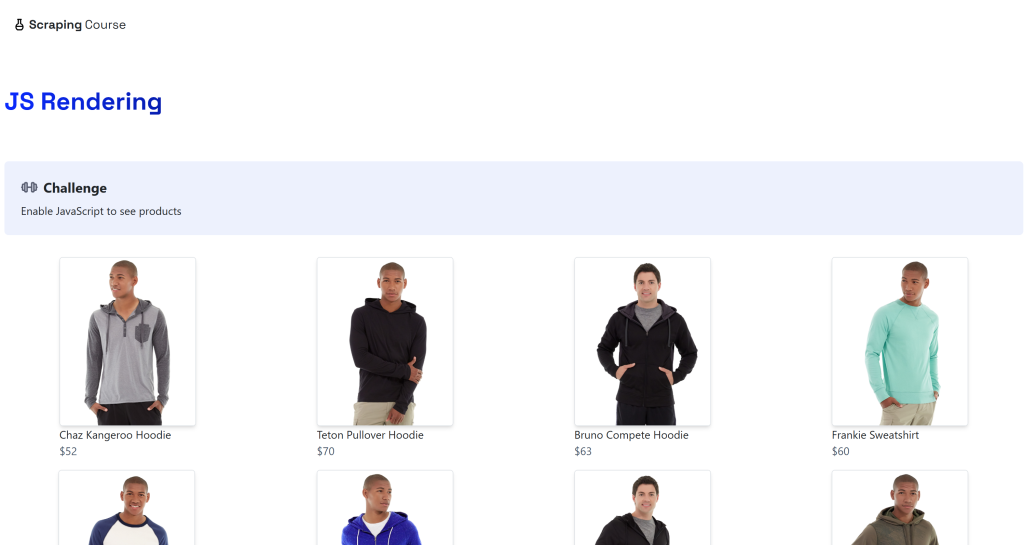
このページはAJAXを通してクライアントサイドでデータを取得し、JavaScriptを使ってレンダリングします:
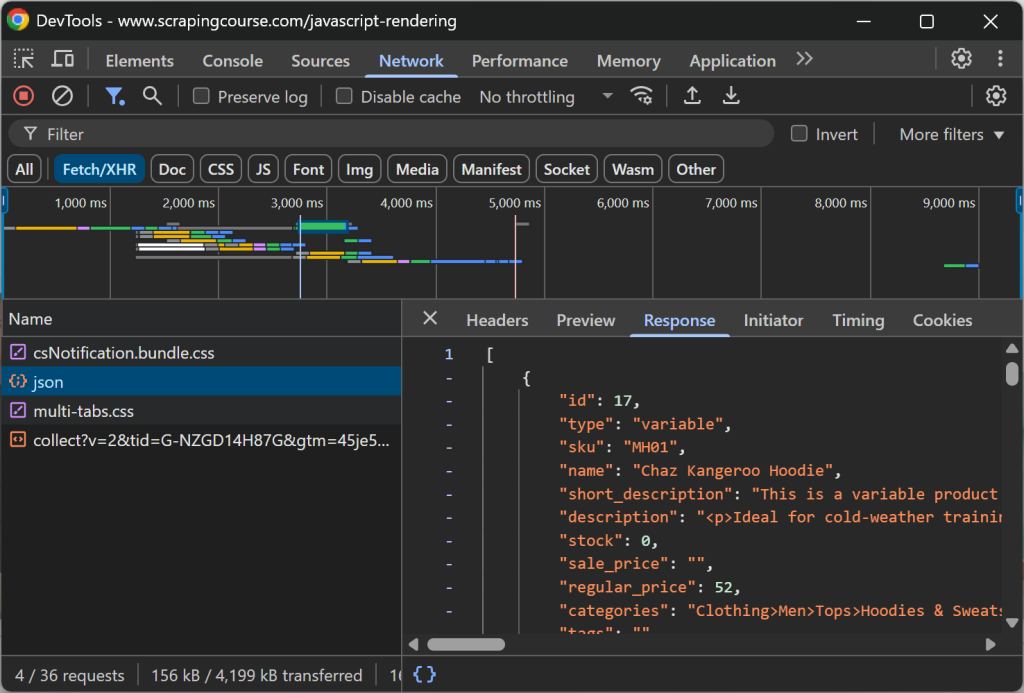
以下のように、動的なウェブサイトをMarkdownにスクレイピングする:
from playwright.sync_api import sync_playwright
from markdownify import markdownify as md
with sync_playwright() as p. # ヘッドレスブラウザを起動する:
# ヘッドレスブラウザを起動する
browser = p.chromium.launch()
page = browser.new_page()
# 動的ページのURL
url = "https://scrapingcourse.com/javascript-rendering"
# ページへの移動
page.goto(url)
# 最初の商品リンク要素が記入されるまで最大5秒待つ
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)
# 完全にレンダリングされたHTMLを取得する
rendered_html = page.content()
# HTMLをMarkdownに変換する
markdown_content = md(rendered_html)
# 結果のMarkdownを印刷する
print(markdown_content)
# ブラウザを閉じ、リソースを解放する
ブラウザを閉じる上記のスニペットでは、オプション4(「特定の要素を待つ」)を選択しました。詳しくは、次のコードを見てください:
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)これは、.product-link要素(<a>タグ)が空でないhref属性を持つまで、最大5000ミリ秒(5秒)待ちます。これは、ページ上の最初の商品要素がレンダリングされたことを示すのに十分で、データが取得され、DOMが安定したことを意味します。
結果はこうなる:
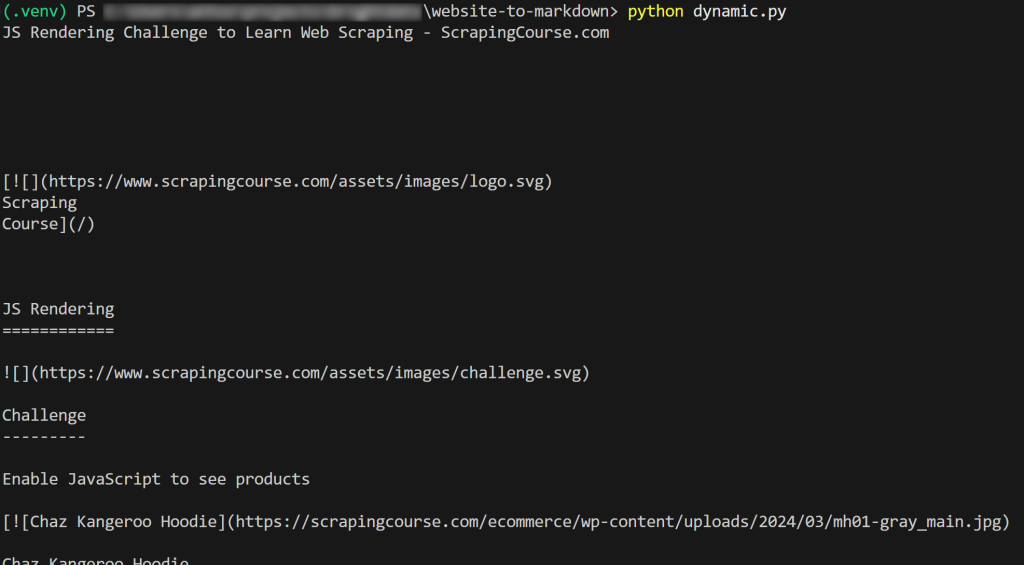
出来上がり!あなたは今、ウェブサイトをMarkdownにスクレイピングする方法を学んだところです。
これらのアプローチの限界と解決策
このブログポストの全ての例には、スクレイピングしやすいようにデザインされたページを参照しているという基本的な点が共通しています!
残念ながら、現実世界のほとんどのウェブページはウェブスクレイピングボットに対してそれほどオープンではない。それどころか、多くのサイトがCAPTCHA、IP禁止、ブラウザ・フィンガープリントなどのスクレイピング防止策を導入している。
言い換えれば、単純なHTTPリクエストやPlaywrightのgoto()命令が意図したとおりに動作するとは期待できない。現実世界のほとんどのウェブサイトをターゲットにすると、403 Forbiddenエラーに遭遇する可能性があります:

あるいは、エラー/人による検証ページです:
考慮すべきもう一つの重要な点は、ほとんどのHTML-to-Markdownライブラリが生のデータ変換を行うことです。これは望ましくない結果につながる可能性があります。例えば、ページがHTMLに直接埋め込まれた<style>要素や<script>要素を含んでいる場合、それらのコンテンツ(それぞれCSSやJavaScriptのコード)はMarkdownの出力に含まれます:

これは、特にデータ処理のためにMarkdownをLLMに送ることを計画している場合、一般的に望ましくないことです。結局のところ、これらのテキスト要素はノイズを加えるだけなのです。
解決策は?専用のWeb Unlocker APIに頼れば、その保護に関係なく、どんなサイトにもアクセスでき、LLM対応のMarkdownを生成することができます。これにより、抽出されたコンテンツはクリーンで構造化され、下流のAIタスクに対応できるようになります。
Web UnlockerによるMarkdownへのスクレイピング
Bright DataのWeb UnlockerはクラウドベースのウェブスクレイピングAPIで、あらゆるウェブページのHTMLを返すことができます。これは、アンチスクレイピングやアンチボットプロテクションの有無や、ページが静的か動的かに関係なく同じです。
APIは1億5千万以上のIPからなるプロキシ・ネットワークに支えられており、Bright Dataが完全なブロック解除インフラ、JavaScriptレンダリング、CAPTCHAの解決、スケーリング、メンテナンスアップデートを処理する間、お客様はデータ収集に集中することができます。
使い方は簡単です。正しい引数で Web Unlocker に POST HTTP リクエストを行うと、完全にアンロックされた Web ページが返されます。LLMに最適化されたMarkdown形式でコンテンツを返すようにAPIを設定することもできます。
初期セットアップガイドに従って、Web Unlockerを使って、たった数行のコードでウェブサイトをMarkdownにスクレイピングしましょう:
# pip install requests
import requests
# これらをあなたのBright Dataアカウントから正しい値に置き換えてください。
bright_data_api_key= "<your_bright_data_api_key>"
web_unlocker_zone = "<your_web_unlocker_zone_name>"
# ターゲットのURLで置き換える
url_to_scrape = "https://www.g2.com/products/bright-data/reviews"
# 必要なヘッダーを準備する
headers = {
"Authorization": f "Bearer {BRIGHT_DATA_API_KEY}", # 認証用
"Content-Type":"application/json"
}
# Web UnlockerのPOSTペイロードを準備する
payload = {
"url": url_to_scrape、
「ゾーン":web_unlocker_zone、
"format":"raw"、
"data_format":"markdown" # レスポンスをMarkdownコンテンツとして取得する場合
}
# Bright Data Web Unlocker APIにPOSTリクエストを行う。
レスポンス = requests.post(
"https://api.brightdata.com/request"、
json=payload、
ヘッダー
)
# Markdownのレスポンスを取得し、それを表示する
markdown_content = response.text
print(markdown_content)スクリプトを実行すると、次のようになる:
今回、G2にブロックされなかったことに注目してほしい。今回はG2によってブロックされなかったことに注目してほしい。
完璧だ!ウェブサイトをMarkdownに変換するのは、かつてないほど簡単になった。
注:このソリューションは、CrawlAI、Agno、LlamaIndex、LangChainなどのAIエージェントツールと75以上の統合を通じて利用可能です。さらに、Bright Data Web MCPサーバー上のscrape_as_markdownツールを介して直接使用することもできます。
結論
このブログポストでは、ウェブページをMarkdownに変換する理由と方法について説明しました。議論したように、HTMLをMarkdownに変換することは、スクレイピング防止や最適なMarkdownの結果といった課題のため、必ずしも簡単ではありません。
Bright Dataは、あらゆるウェブページをLLMに最適化されたMarkdownに変換できるクラウドベースのウェブスクレイピングAPIであるWeb Unlockerであなたをカバーします。このAPIを手動で呼び出すことも、AIエージェント構築ソリューションに直接統合することも、Web MCP統合を介して統合することもできます。
Web Unlockerは、Bright DataのAIインフラで利用可能な数多くのウェブデータおよびスクレイピングツールの1つに過ぎません。
今すぐBright Dataの無料アカウントにサインアップして、AIに対応したWebデータソリューションをお試しください!