

優れたパースツールは数多く存在します。Pythonでは選択肢がほぼ無限に感じられます。しかしGoでは、実際にはあまり選択肢がありません。
Goはパフォーマンスとメモリ管理に優れた言語ですが、パースライブラリはかなり限定的です。Goの標準ライブラリから利用できる選択肢としてNode ParserとTokenizerがあります。ウェブスクレイピングの仕組みが全く分からない場合は、こちらのガイドを参照してください。当ガイドに沿って進めながら、これらのツールを使用すべき場面や、より完全なスクレイピングソリューションのためにサードパーティライブラリを選択すべき場面を学びましょう。
前提条件
Go言語とウェブスクレイピングの基本的な理解があると役立ちますが、必須ではありません。Go言語に精通しているがウェブスクレイピングのプロセスを知りたい場合は、こちらのガイドを参照してください。
まず、お使いのマシンにGoがインストールされていることを確認してください。最新リリースはこちらから入手できます。お使いのシステムに対応した最新リリースをダウンロードすれば、すぐに始められます!
新しいプロジェクトフォルダを作成し、そのフォルダに移動します。
mkdir goparser
cd goparser
新しいGoプロジェクトを初期化します。
go mod init goparser
設定の確認
次のコードを新しいファイルmain.go に貼り付けます。
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
次のコマンドでファイルを実行できます。
go run main.go
正常に動作している場合、以下の出力が表示されます。
Hello, World!
唯一の依存関係をインストールします。
go get golang.org/x/net/html
ページの調査
Quotes to Scrapeは、チュートリアルをスクレイピングするために特別に構築されたサイトです。このチュートリアルでは、ページから各引用文とその著者を抽出します。
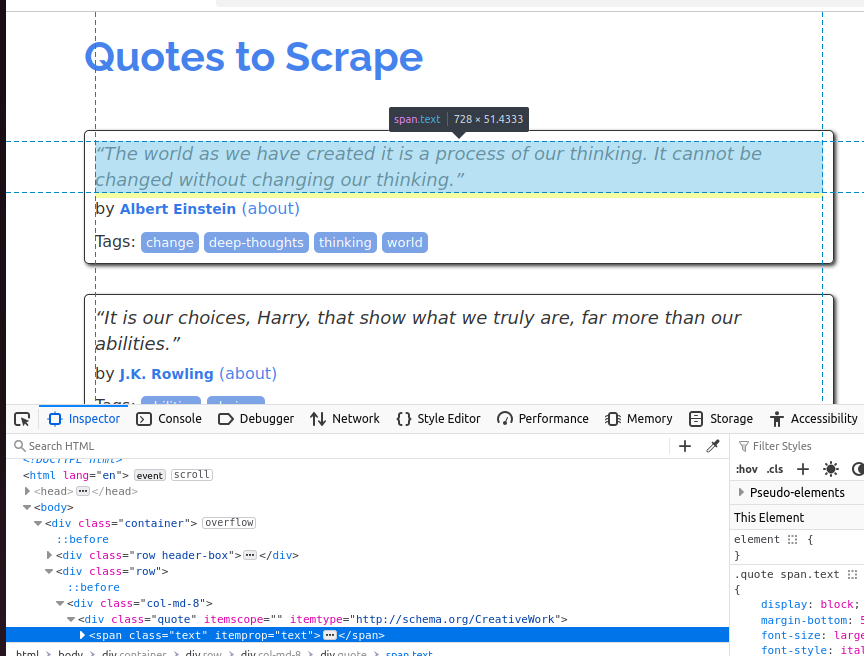
引用文オブジェクトをより理解するために、以下のスクリーンショットをご覧ください。各引用文はspan 要素であり、そのクラスは text です。
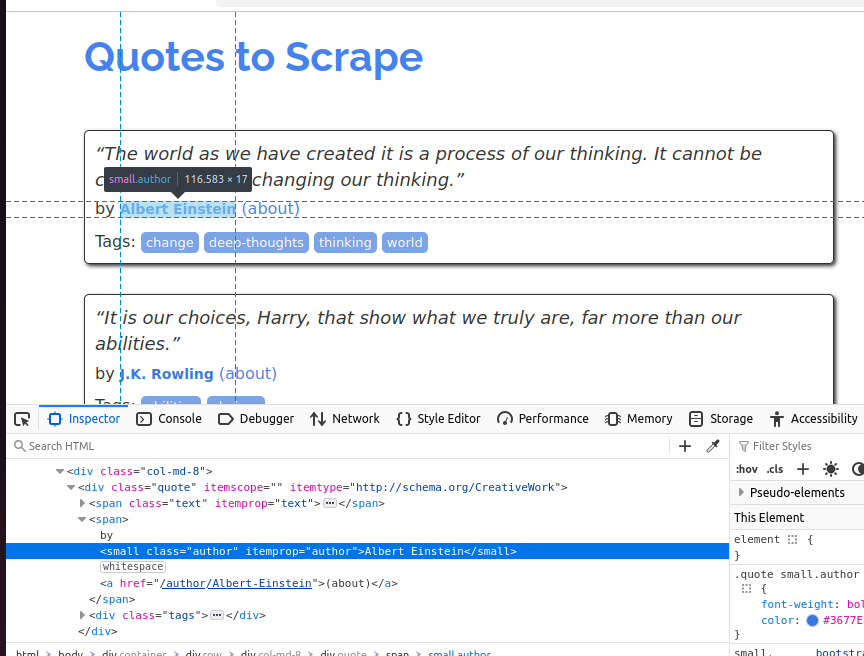
次のスクリーンショットでは著者を確認します。小さな要素で、クラスは author です。
Node ParserとTokenizerの両方の例は、以下に示すのと同じ出力を生成します。
引用: 「我々が創造した世界は、我々の思考の産物である。思考を変えずに世界を変えることはできない。」
著者: アルベルト・アインシュタイン
引用: 「ハリー、我々の真の姿を示すのは能力よりも、選択そのものなのだ。」
著者: J.K.ローリング
引用: 「人生を生きる道は二つしかない。一つは、何も奇跡ではないかのように生きる道。 もう一つは、すべてが奇跡であるかのように生きることだ。」
著者:アルバート・アインシュタイン
引用:「紳士であれ淑女であれ、良質な小説に喜びを見出せない者は、耐え難いほど愚かなに違いない。」
著者:ジェーン・オースティン
引用:「不完全さは美であり、狂気は天才である。そして、まったく退屈であるよりは、まったく滑稽であるほうがましだ。」
引用元:マリリン・モンロー
引用:「成功者になろうとするな。むしろ価値ある人間になれ。」
引用元:アルバート・アインシュタイン
引用:「偽りの自分を愛されるより、ありのままの自分を憎まれる方がましだ。」
引用元:アンドレ・ジッド
引用:「私は失敗したのではない。ただ1万通りの失敗の方法を見つけただけだ。」
著者:トーマス・A・エジソン
引用:「女性はティーバッグのようなものです。熱湯に浸けてみなければ、その強さはわからないのです。」
著者:エレノア・ルーズベルト
引用:「太陽の光のない日は、まるで夜のようなものです。」
著者:スティーブ・マーティン
Node Parser によるデータ抽出
Go の Node Parser を使用すると、DOM (Document Object Model) をトラバースし、再帰的に操作することができます。Node Parser を使用すると、HTML ページ全体が、解析可能なNode オブジェクトのツリー構造に変換されます。
以下のコードでは、再帰関数processNode() を作成しています。この関数は、HTML ノードへのポインタを受け取ります。ノードがspan であり、そのクラスが text である場合は、引用文をコンソールに出力します。ノードがsmall 要素であり、そのクラスが author である場合は、著者をコンソールに出力します。これらは、先ほどページを検査したときに発見した属性と同じものです。
package main
import (
"fmt"
"net/http"
"golang.org/x/net/html")
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
doc, _ := html.Parse(resp.Body)
var processNode func(*html.Node)
processNode = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "span" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "text" {
fmt.Println("引用:", n.FirstChild.Data)
}
}
}
if n.Type == html.ElementNode && n.Data == "small" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "author" {
fmt.Println("Author:", n.FirstChild.Data)
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
processNode(c)
}
}
processNode(doc)
}
ノードパーサーAPIは、ドキュメント全体を処理する必要がある場合に非常に便利です。メモリ効率の観点からは、実際のドキュメントへのポインタを使用し、トラバースしながらデータを処理する方法も有効です。
トークナイザーによるデータ抽出
トークナイザーはページを少し異なる方法で処理します。html.NewTokenizer(resp.Body) を使用してレスポンス本文からトークナイザーオブジェクトを作成します。その後、ページから抽出したいトークン(HTMLタグ、テキストコンテンツ、属性)を選択します。
各トークン処理時には、inQuote とinAuthor の2つのブールオブジェクトが利用可能です。トークンが引用文または著者タグ内に存在する場合、トリミング処理を施しコンソールに出力します。このコードの出力結果はNode Parserと同様ですが、実際の動作は大きく異なります。Node Parserではツリーを辿りながらノード単位でデータを処理するのに対し、トークナイザーではチャンク単位で処理します。
以下のコードでは、開始トークンとしてspan とsmall を指定しています。チャンクがspan 要素で、そのクラスが text の場合、コンソールに出力します。チャンクがsmall で、そのクラスが author の場合も同様にコンソールに出力します。ページ上のその他のトークン(HTMLタグ)は完全に無視されます。
package main
import (
"fmt"
"net/http"
"strings"
"golang.org/x/net/html"
)
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
tokenizer := html.NewTokenizer(resp.Body)
inQuote := false
inAuthor := false
for {
tt := tokenizer.Next()
switch tt {
case html.ErrorToken:
return
case html.StartTagToken:
t := tokenizer.Token()
if t.Data == "span" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "text" {
inQuote = true
}
}
}
if t.Data == "small" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "author" {
inAuthor = true
}
}
}
case html.TextToken:
if inQuote {
fmt.Println("引用:", strings.TrimSpace(tokenizer.Token().Data))
inQuote = false
}
if inAuthor {
fmt.Println("著者:", strings.TrimSpace(tokenizer.Token().Data))
inAuthor = false
}
}
}
}
トークナイザーはノードパーサーよりも低レベルですが、はるかに効率的です。ドキュメント全体を走査する代わりに、関連するトークン(HTMLタグ)のみを処理すればよいのです。これはデータストリームからの大規模なチャンク処理に最適です。トークナイザーを使えば、ページ全体ではなく関連データのみを処理すれば済みます。
サードパーティ製代替ツール
Node ParserとTokenizerは、PythonやJavaScriptで利用できるツールと比べるとかなり低レベルです。スクレイピングを少し簡単にするサードパーティ製ツールをいくつか紹介します。
Goquery
JqueryのGo言語版として開発されたGoqueryは、より直感的なパーサーを求める場合に最適な選択肢です。GoqueryではDOMトラバースとCSSセレクタがサポートされており、他の言語で慣れ親しんだソリューションに近い動作を実現します。
htmlquery
Goqueryと同様に、htmlqueryでもDOMトラバーサルとセレクタの両方を使用できます。ただしhtmlqueryではCSSセレクタの代わりにXPathセレクタを使用します。Goqueryとhtmlqueryの選択は、どちらのタイプのセレクタを好むかによって決めるべきです。
Colly
CollyはGo向けの完全なウェブスクレイピングフレームワークです。CSSセレクターや並行処理など、豊富な機能をサポートしています。ScrapyのGo版と考えることができます。Collyの使用に興味がある方は、こちらの優れたチュートリアルをご覧ください。
Bright Data Web スクレイパー
当社のウェブスクレイパーを利用すれば、ウェブスクレイピングプロセスを完全に回避できます。ウェブスクレイパーがページをスクレイピングし、データをJSON形式で返します。DOMの探索やトークンの作成、セレクタの記述といった手間をかけず、APIリクエストを実行してすぐに作業を進めたい場合に最適な選択肢です。 当社のウェブスクレイパーはGoライブラリではなく、APIサービスです。REST APIの扱いに慣れている方なら、ウェブスクレイピングプロセスを自動化する非常にシンプルな方法です。
まとめ
これでGoを用いたHTMLパースの方法が理解できたはずです。より高度なスキルセットを習得するには、Goにおけるプロキシ統合ガイドをご覧ください。ページ全体をトラバースしたい場合はNode Parserを、ページから関連データのみをパースしたい場合はTokenizerをお試しください。これらに該当しない場合は、Bright DataのWebスクレイパーなど様々なサードパーティ製ツールも選択肢となります。 今すぐ登録して無料トライアルを始めましょう!





