

このNode.jsユーザーエージェント設定ガイドでは、以下の内容を確認できます:
ユーザーエージェントヘッダーの設定が重要な理由- Node.jsにおけるデフォルトのユーザーエージェントの形式
- Fetch APIを使用したユーザーエージェントの設定方法
- Node.jsでのユーザーエージェントローテーションの実装方法
さっそく見ていきましょう!
ユーザーエージェント設定が重要な理由
User-Agentヘッダーは、HTTPリクエストを送信するクライアントソフトウェアを識別する文字列です。通常、リクエストの発信元であるブラウザやアプリケーション、オペレーティングシステム、システムアーキテクチャに関する詳細が含まれます。このヘッダーは通常、Webブラウザ、HTTPクライアント、またはWebリクエストを実行するソフトウェアによって設定されます。
例えば、Chromeがページをリクエストする際に設定する現在のユーザーエージェントは以下の通りです:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36以下に、このユーザーエージェント文字列の構成要素を分解して説明します:
Mozilla/5.0: 元々はMozillaブラウザとの互換性を示すために使用されていましたが、現在はこの接頭辞は互換性のために追加されています。Windows NT 10.0; Win64; x64:オペレーティングシステム(Windows NT 10.0)、プラットフォーム(Win64)、システムアーキテクチャ(x64)を示します。AppleWebKit/537.36: Chromeが使用するブラウザエンジンを指します。- (
KHTML, like Gecko): KHTML および Gecko レイアウトエンジンとの互換性を示します。 Chrome/127.0.0.0: ブラウザ名とバージョンを指定します。Safari/537.36: Safari との互換性を示します。
基本的に、ユーザーエージェントは、リクエストが信頼できるブラウザから送信されたものか、別の種類のソフトウェアから送信されたものかを明らかにすることができます。
ウェブスクレイピングボットや自動化スクリプトは、デフォルトまたは非ブラウザのユーザーエージェント文字列を使用することが多いです。これらは、受信リクエストを精査してウェブデータを保護するアンチボットシステムに、自動化された性質を露呈する可能性があります。これらのソリューションはUser-Agentヘッダーを分析することで、リクエストが本物のユーザーからのものかボットからのものかを判別できます。
詳細については、ウェブスクレイピング向けユーザーエージェントガイドをご覧ください。
Node.jsのデフォルトユーザーエージェントとは?
バージョン18以降、Node.jsにはFetch APIの 組み込み実装としてfetch()メソッドが含まれています。これは外部依存関係を必要としないため、Node.jsでHTTPリクエストを実行する推奨方法です。Node.jsでFetch APIを使用してHTTPリクエストを送信する方法の詳細をご覧ください。
他のほとんどのHTTPクライアントと同様に、fetch()はリクエスト時にデフォルトのUser-Agentヘッダーを自動的に設定します。例えばPythonのrequestsライブラリでも同様の動作をします。
特に、fetch()によって設定されるNode.jsのデフォルトUser-Agentは次の通りです:
nodeこの動作は、httpbin.io/user-agentエンドポイントへの GET リクエストを実行することで確認できます。このエンドポイントは受信リクエストのUser-Agentヘッダーを返すため、HTTP クライアントが設定したユーザーエージェントを特定するのに役立ちます。
Node.jsスクリプトを作成し、非同期関数を定義してfetch()で目的のHTTPリクエストを実行します:
async function getFetchDefaultUserAgent() {
// HTTPBinエンドポイントへのHTTPリクエストを実行
// ユーザーエージェントを取得
const response = await fetch("https://httpbin.io/user-agent");
// レスポンスからデフォルトのユーザーエージェントを読み取り
// 出力する
const data = await response.json();
console.log(data);
}
getFetchDefaultUserAgent();上記のJavaScriptコードを実行すると、以下の文字列が返されます:
{ 'user-agent': 'node' }ご覧の通り、Node.jsのfetch()で設定されるユーザーエージェントは単純に「node」です。この文字列は、アンチボットシステムを起動させる可能性のあるブラウザが使用するユーザーエージェントとは大きく異なります。
ボット対策ソリューションは、不審なパターン(例:異常なユーザーエージェント文字列)を監視します。検知されると、そのリクエストはボットからのものと判断されブロックされます。このため、デフォルトのNode.jsユーザーエージェント値を変更することが、フラグ付けを回避する鍵となるのです!
Fetch API を使用した Node.js ユーザーエージェントの変更方法
Fetch API仕様はユーザーエージェント変更の特定メソッドを提供していません。一方でUser-Agentは単なるHTTPヘッダーです。つまりfetch()のヘッダーオプションで値をカスタマイズ可能です。
Node.jsでfetch() を使用してUser-Agentヘッダーを設定する方法をご覧ください!
ローカルでユーザーエージェントを設定する
fetch() は headersオプションによるヘッダーのカスタマイズをサポートしています。特定の HTTP リクエスト時にUser-Agentヘッダーを設定するには、以下のように使用します:
const response = await fetch("https://httpbin.io/user-agent", {
headers: {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36",
},
});すべてをまとめると次のようになります:
async function getFetchUserAgent() {
// カスタムユーザーエージェントでHTTPBinへのリクエストを送信
const response = await fetch("https://httpbin.io/user-agent", {
headers: {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36",
},
});
// レスポンスからデフォルトのユーザーエージェントを読み取る
// それを出力する
const data = await response.json();
console.log(data);
}
getFetchUserAgent();上記スクリプトを実行すると、今回は以下の結果が得られます:
{
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}素晴らしい!APIが返したユーザーエージェントは、コードで設定したユーザーエージェントと一致しています。これでNode.jsのユーザーエージェントを変更する方法がわかりました。
グローバルにユーザーエージェントを設定する
リクエストごとにUser-Agentを設定するのは簡単ですが、繰り返し記述する定型コードが生じます。Node.jsのデフォルトユーザーエージェントをグローバルに変更したい場合はどうすればよいでしょうか?残念ながら、執筆時点ではfetch()APIはデフォルト設定をグローバルに上書きする手段を提供していません。
代わりに、希望の設定でfetch()の動作をカスタマイズするラッパー関数を作成できます:
function customFetch(url, options = {}) {
// カスタムヘッダー
const customHeaders = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36",
...options.headers, // オプションで渡された他のヘッダーとマージ
};
const mergedOptions = {
...options,
headers: customHeaders,
};
return fetch(url, mergedOptions);
}カスタムユーザーエージェントでHTTPリクエストを実行するには、`fetch()`の代わりに`customFetch()`を呼び出します:
const response = await customFetch("https://httpbin.io/user-agent");完全なNode.jsスクリプトは以下のようになります:
function customFetch(url, options = {}) {
// カスタムユーザーエージェントヘッダーを追加
const customHeaders = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36",
...options.headers, // オプションで渡された他のヘッダーとマージ
};
const mergedOptions = {
...options,
headers: customHeaders,
};
return fetch(url, mergedOptions);
}
async function getFetchUserAgent() {
// カスタムフェッチラッパー経由でHTTPBinへのリクエストを実行
const response = await customFetch("https://httpbin.io/user-agent");
// レスポンスからデフォルトのユーザーエージェントを読み取り
// 出力する
const data = await response.json();
console.log(data);
}
getFetchUserAgent();上記のNode.jsスクリプトを実行すると、以下のように出力されます:
{
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}素晴らしい!これで Node.js でfetch() を使用してグローバルなユーザーエージェントを設定する方法を学びました。
Node.jsでユーザーエージェントローテーションを実装する
HTTPクライアントのデフォルトUser-Agentヘッダーを実ブラウザのものに上書きしても、ボット検知を回避するには不十分な場合があります。同一IPアドレスから同一ユーザーエージェントで大量のリクエストを送信すると、スクレイピング対策システムは依然として自動化された活動と識別します。問題は、リクエストが依然として非人間的な行動を示唆している点です。
Node.jsでボット検知リスクを低減するには、HTTPリクエストに多様性を持たせる必要があります。効果的な手法の一つがユーザーエージェントローテーションで、各リクエストごとにUser-Agentヘッダーを変更します。この手法により自動リクエストが異なるブラウザからのものに見え、ボット対策システムに検知されにくくなります。
次のセクションでは、Node.jsでユーザーエージェントローテーションを実現する方法を学びます!
ステップ #1: ユーザーエージェントのリストを取得する
WhatIsMyBrowser.comなどのサイトにアクセスし、有効なユーザーエージェント値のリストを作成します:
const userAgents = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 14_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.5 Safari/605.1.15",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/126.0.2592.113",
// その他のユーザーエージェント...
];ヒント: この配列に実世界のユーザーエージェント文字列を多く含めるほど、ボット対策検出を回避しやすくなります。
ステップ #2: ユーザーエージェントをランダムに選択
リストからランダムにユーザーエージェント文字列を選択して返す関数を作成します:
function getRandomUserAgent() {
const userAgents = [
// 簡略化のためユーザーエージェント省略...
];
// リストからランダムに抽出されたユーザーエージェントを返す
return userAgents[Math.floor(Math.random() * userAgents.length)];
}この関数の動作を分解してみましょう:
Math.random()は 0 から 1 の間の乱数を生成します- この数値に
userAgents配列の長さを乗算します。 Math.floor()は結果をその数以下の最大の整数に切り捨てます。- 前の操作で得られた数値は、0から
userAgents.length - 1までの範囲でランダムに生成されたインデックスに対応します。 - このインデックスを用いて、ユーザーエージェント配列からランダムなユーザーエージェントを返します。
getRandomUserAgent()関数を呼び出すたびに、異なるユーザーエージェントが取得される可能性が高いです。
ステップ 3: ランダムなユーザーエージェントで HTTP リクエストを実行
Node.jsでfetch()を使用してユーザーエージェントローテーションを実装するには、getRandomUserAgent()関数の値でUser-Agentヘッダーを設定します:
const response = await fetch("https://httpbin.io/user-agent", {
headers: {
"User-Agent": getRandomUserAgent(),
},
});Fetch API経由で実行されるHTTPリクエストは、ランダムなユーザーエージェントを持つようになります。
ステップ #4: 全てをまとめる
前のステップのスニペットをNode.jsスクリプトに追加し、fetch()リクエストを行うロジックをasync関数で囲みます。
最終的なNode.jsユーザーエージェントローテーションスクリプトは以下のようになります:
function getRandomUserAgent() {
const userAgents = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 14_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.5 Safari/605.1.15",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/126.0.2592.113",
// その他のユーザーエージェント...
];
// リストからランダムに抽出したユーザーエージェントを返す
return userAgents[Math.floor(Math.random() * userAgents.length)];
}
async function getFetchUserAgent() {
// ランダムなユーザーエージェントでHTTPリクエストを実行
const response = await fetch("https://httpbin.io/user-agent", {
headers: {
"User-Agent": getRandomUserAgent(),
},
});
// レスポンスからデフォルトのユーザーエージェントを読み取り
// 出力する
const data = await response.json();
console.log(data);
}
getFetchUserAgent();スクリプトを3~4回実行してください。統計的に、以下のように異なるユーザーエージェントの応答が確認できるはずです:
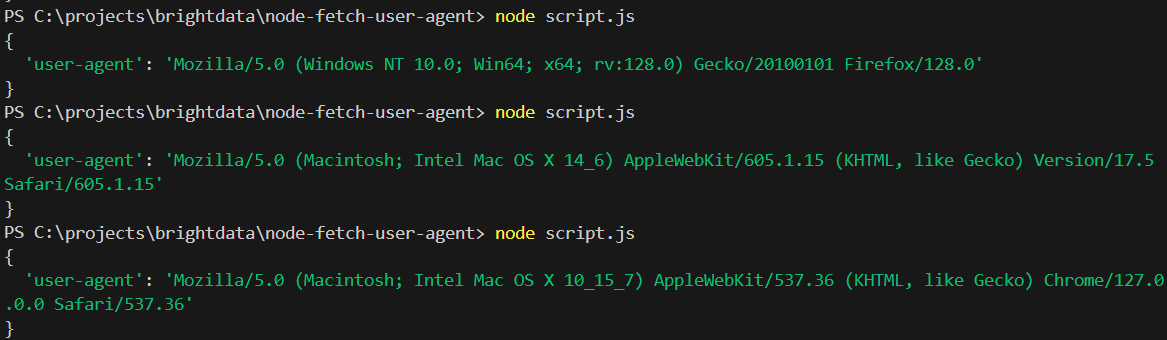
これでユーザーエージェントのローテーションが効果的に機能していることが確認できます。
さあ、これで Node.js で Fetch API を使ってユーザーエージェントを設定するスキルを身につけました。
まとめ
このチュートリアルでは、User-Agentヘッダーを設定すべき理由と、fetch()におけるNode.jsのデフォルトユーザーエージェントを確認しました。また、この値を上書きし、Node.jsでユーザーエージェントローテーションを実装して基本的なスクレイピング対策システムを回避する方法も探りました。しかし、より高度なシステムは依然として自動リクエストを検知・ブロックする可能性があります。IP禁止を回避するにはNode.jsでプロキシを設定できますが、それでも十分でない場合もあります!
より堅牢な解決策として、次世代スクレイピングサービス「Web Scraper API」をご検討ください。Node.jsやその他技術における自動ウェブリクエストを簡素化し、IP/ユーザーエージェントローテーション機能でアンチスクレイピング対策を効果的に回避。ウェブスクレイピングをかつてないほど容易にします。
今すぐ登録して、プロジェクトに最適な製品を見つけましょう。無料トライアルを今日始めましょう!



