

Etsyはスクレイピングが極めて困難なサイトとして知られています。様々なブロック対策を採用しており、ウェブ上で最も洗練されたボット遮断システムの一つを有しています。詳細なヘッダー解析から終わりのないCAPTCHAの波まで、Etsyは世界中のウェブスクレイパーにとって悩みの種です。これらの障壁を突破できれば、Etsyは比較的スクレイピングしやすいサイトとなります。
Etsyをスクレイピングできれば、インターネット最大のマーケットプレイスの一つから豊富な中小企業データにアクセスできます。今日から手順を追えば、すぐにプロのようにEtsyをスクレイピングできるようになります。Etsyから以下の全ページタイプをスクレイピングする方法を学びます。
- 検索結果ページ
- 商品ページ
- ショップページ
はじめに
このチュートリアルではPythonのRequests とBeautifulSoupを使用します。以下のコマンドでインストール可能です。RequestsはHTTPリクエストを送信しEtsyサーバーと通信する機能を提供します。BeautifulSoupはPythonでウェブページをパースする力を与えます。まずBeautifulSoupを用いたウェブスクレイピングのガイドをお読みになることをお勧めします。
Requests のインストール
pip install requests
BeautifulSoupのインストール
pip install beautifulsoup4
Etsyからスクレイピングする対象
Etsyのページを調査すると、入れ子になった要素の厄介な網に引っかかるかもしれません。どこを見ればよいか分かれば、これは簡単に克服できます。Etsyのページは、ブラウザでページをレンダリングするためにJSONデータを使用しています。JSONを見つけられれば、ドキュメントのHTMLを深く掘り下げることなく、ページ構築に使用されたすべてのデータを見つけられます。
検索結果
Etsyの検索ページにはJSONオブジェクトの配列が含まれています。下の画像を見ると、このデータはすべてtype="application/ld+json" のscript要素内に収められています。よく見ると、このJSONデータにはitemListElementという配列が含まれています。この配列を抽出できれば、ページ構築に使用された全データを取得できます。
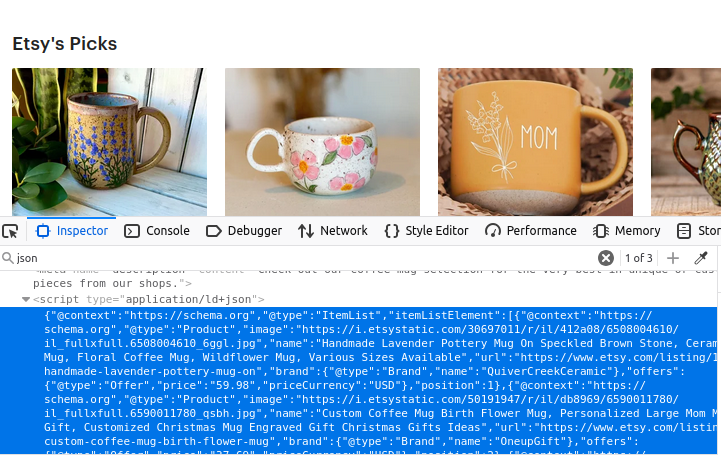
商品情報
商品ページもほぼ同様です。下の画像を見ると、ここでもtype="application/ld+json" のスクリプトタグが存在します。このタグには商品ページ作成に使用された全情報が含まれています。
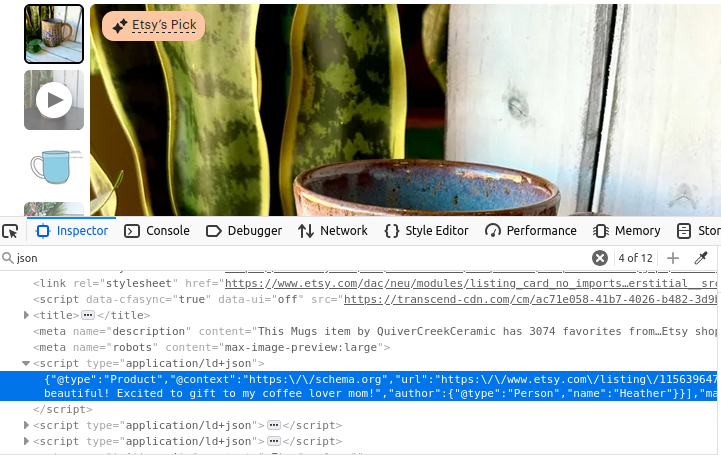
ショップ
おそらくお気づきでしょうが、ショップページも同様の方法で構築されています。ページ内で最初にtype="application/ld+json"を持つスクリプトオブジェクトを見つけ出せば、データを入手できます。
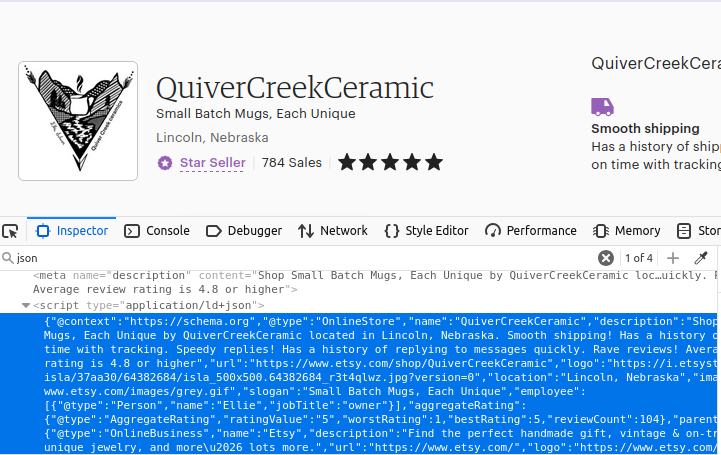
PythonでEtsyをスクレイピングする方法
では、構築に必要なすべてのコンポーネントを確認していきましょう。前述の通り、Etsyはサイトへのアクセスをブロックするために様々な手法を採用しています。これらのブロック対策として、Web Unlockerを万能ツールとして使用します。プロキシ接続を管理するだけでなく、発生するCAPTCHAも解決してくれます。プロキシなしで試すことも可能ですが、初期テストではWeb UnlockerなしではEtsyのブロックシステムを突破できませんでした。
Web Unlockerのインスタンスを入手したら、シンプルな辞書(dict)を作成することでプロキシ接続を設定できます。データ転送中の暗号化を確保するため、Bright DataのSSL証明書を使用します。 以下のコードでは、SSL証明書のパスを指定し、ユーザー名・ゾーン名・パスワードを用いてプロキシURLを生成しています。プロキシはBright Dataのプロキシサービスを経由するカスタムURLを構築することで実現されます。
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>@brd.superproxy.io:33335',
'https': 'http://brd-customer-<YOUR-USERNAME>-ゾーン-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>@brd.superproxy.io:33335'
}
検索結果
検索結果を抽出するため、プロキシを使用してリクエストを送信します。その後、BeautifulSoupを使用して受信したHTMLドキュメントをパースします。scriptタグ内のデータを検出し、JSONオブジェクトとして読み込みます。その後、JSONからitemListElementフィールドを返します。
def etsy_search(keyword):
encoded_keyword = urlencode({"q": keyword})
url = f"https://www.etsy.com/search?{encoded_keyword}"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
full_json = json.loads(script.text)
return full_json["itemListElement"]
製品情報
当社の製品情報は基本的に同じ方法で抽出されます。唯一の違いはitemListElementが存在しない点です。今回はlisting_idを使用してURLを作成し、JSONオブジェクト全体を抽出します。
def etsy_product(listing_id):
url = f"https://www.etsy.com/listing/{listing_id}/"
response = requests.get(url, プロキシ=プロキシ, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)
ショップ
ショップの抽出では、商品と同様の手法を採用します。shop_name を使用して URL を構築します。レスポンスを取得後、JSON を検索し、JSON として読み込み、抽出されたページデータを返します。
def etsy_shop(shop_name):
url = f"https://www.etsy.com/shop/{shop_name}"
response = requests.get(url, プロキシ=プロキシ, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)
データの保存
データを抽出すると、整然と構造化されたJSON形式になります。Pythonの基本的なファイル操作とjson.dumps()を使用して、出力をファイルに書き込むことができます。人間がファイルを見たときに読みやすくするため、indent=4で書き出します。
with open("products.json", "w") as file:
json.dump(products, file, indent=4)
すべてを組み合わせる
各パーツの構築方法がわかったので、すべてを統合します。以下のコードは先ほど作成した関数を使用し、目的のデータをJSON形式で返します。その後、これらのオブジェクトをそれぞれ個別のJSONファイルに書き出します。
import requests
import json
from bs4 import BeautifulSoup
from urllib.parse import urlencode
# プロキシと証明書の設定(ハードコードされた認証情報)
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>@brd.superproxy.io:22225',
'https': 'http://brd-customer-<YOUR-USERNAME>-ゾーン-<YOUR-ゾーン-NAME>:<YOUR-PASSWORD>@brd.superproxy.io:22225'
}
def fetch_etsy_data(url):
"""EtsyページからJSON-LDデータを取得・パースする"""
try:
response = requests.get(url, proxies=proxies, verify=path_to_cert)
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"リクエスト失敗: {e}")
return None
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
if not script:
print("ページにJSON-LDスクリプトが見つかりません。")
return None
try:
return json.loads(script.text)
except json.JSONDecodeError as e:
print(f"JSONパースエラー: {e}")
return None
def etsy_search(keyword):
"""指定キーワードでEtsyを検索し結果を返す"""
encoded_keyword = urlencode({"q": keyword})
url = f"https://www.etsy.com/search?{encoded_keyword}"
data = fetch_etsy_data(url)
return data.get("itemListElement", []) if data else None
def etsy_product(listing_id):
"""Etsyの出品ページから商品詳細を取得します。"""
url = f"https://www.etsy.com/listing/{listing_id}/"
return fetch_etsy_data(url)
def etsy_shop(shop_name):
"""Etsyショップページからショップ詳細を取得します。"""
url = f"https://www.etsy.com/shop/{shop_name}"
return fetch_etsy_data(url)
def save_to_json(data, filename):
"""エラー処理付きでデータをJSONファイルに保存する"""
try:
with open(filename, "w", encoding="utf-8") as file:
json.dump(data, file, indent=4, ensure_ascii=False, default=str)
print(f"データを{filename}に正常に保存しました")
except (IOError, TypeError) as e:
print(f"{filename}へのデータ保存エラー: {e}")
if __name__ == "__main__":
# 商品検索
products = etsy_search("coffee mug")
if products:
save_to_json(products, "products.json")
# 特定アイテム
item_info = etsy_product(1156396477)
if item_info:
save_to_json(item_info, "item.json")
# Etsyショップ
shop = etsy_shop("QuiverCreekCeramic")
if shop:
save_to_json(shop, "shop.json")
以下はproducts.json からのサンプルデータです。
{
"@context": "https://schema.org",
"@type": "Product",
"image": "https://i.etsystatic.com/34923795/r/il/8f3bba/5855230678/il_fullxfull.5855230678_n9el.jpg",
"name": "写真入りカスタムコーヒーマグ、パーソナライズされた写真入りコーヒーカップ、彼/彼女への記念日マグギフト、男性・女性向けカスタマイズ可能なロゴ・テキストマグ",
"url": "https://www.etsy.com/listing/1193808036/custom-coffee-mug-with-photo",
"brand": {
"@type": "Brand",
"name": "TheGiftBucks"
},
"offers": {
"@type": "Offer",
"price": "14.99",
"priceCurrency": "USD"
},
"position": 1
},
データセットの利用をご検討ください
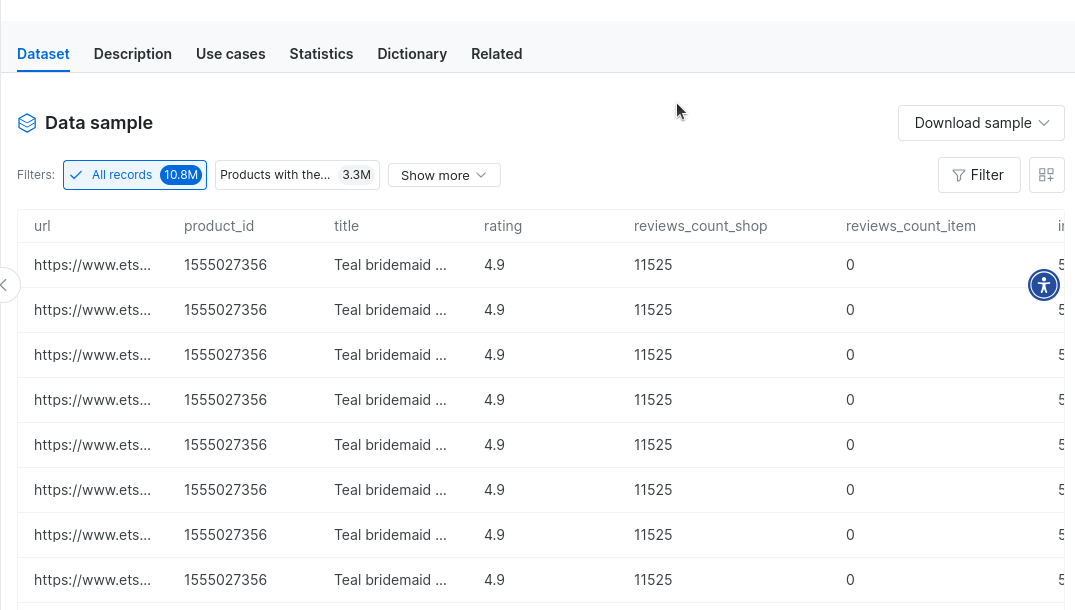
当社のデータセットはウェブスクレイピングに代わる優れた選択肢です。今すぐ購入できるEtsyデータセットやその他のeコマースデータセットがあれば、スクレイピング作業を完全に省略できます!アカウント作成後、データセットマーケットプレイスへアクセスしてください。
「Etsy」と入力し、Etsyデータセットをクリックしてください。

これにより、Etsyデータから数百万件のレコードに…すぐにアクセスできます。サンプルデータをダウンロードして、実際の操作感を確認することも可能です。
まとめ
本チュートリアルではEtsyスクレイピングを詳細に解説しました。プロキシ統合の基礎を習得し、Web Unlockerで最も厳格なボットブロックを回避する手法を学びました。データ抽出と保存方法も理解できたはずです。スクレイピング作業を完全に不要にする当社プリメイドデータセットの活用例も紹介しました。データ取得方法に関わらず、当社が全面的にサポートします。
今すぐ登録して無料トライアルを開始しましょう。





