

このガイドで、あなたは学ぶだろう:
- LlamaIndexとは?
- LlamaIndexで構築されたAIエージェントがウェブ検索を行うべき理由。
- ウェブ検索機能を持つLlamaIndex AIエージェントの作り方。
さあ、飛び込もう!
LlamaIndexとは?
LlamaIndexは、LLMを燃料とするアプリケーションを構築するためのオープンソースのPythonフレームワークです。非構造化データとLLMの架け橋となる。特に、様々なデータソースにまたがるLLMワークフローのオーケストレーションを容易にします。
LlamaIndexを使用すると、本番環境に対応したAIワークフローとエージェントを作成することができます。これらは、関連する情報の検索と取得、洞察の合成、詳細なレポートの生成、自動化されたアクションなどを行うことができます。
この記事を書いている時点で、このライブラリはAIエコシステムで最も急成長しているライブラリのひとつであり、GitHubのスター数は42kを超えている。
ウェブ検索データをLlamaIndex AIエージェントに統合する理由
他のAIエージェントフレームワークと比較して、LlamaIndexはLLMの最大の限界のひとつを解決するために作られた。それは、最新の実世界の知識の欠如である。
この問題に対処するため、LlamaIndexは複数のデータコネクターとの統合を提供しており、複数のソースからコンテンツを取り込むことができます。さて、AIエージェントにとって最も価値のあるデータソースはどれだろうか?
この疑問に答えるには、LLMのトレーニングにどのようなデータソースが使われているかを考えることが役立つ。成功したLLMは、最大かつ最も多様な公共データ源であるウェブからトレーニングデータのほとんどを受け取った。
LlamaIndexのAIエージェントに静的なトレーニングデータを突破させたいのであれば、必要な重要な能力は、ウェブを検索し、見つけたものから学習する能力です。したがって、あなたのエージェントは、検索結果ページ(”SERPs“と呼ばれる)から構造化された情報を抽出できなければなりません。そして、それらを有意義に処理し、そこから学習する。
課題は、単純なスクレイピングスクリプトに対するGoogleの最近の取り締まりにより、SERPスクレイピングがより難しくなっていることです。LlamaIndexと統合し、このプロセスを簡素化するツールが必要な理由はここにあります。そこで、LlamaIndexのBright Data統合の出番です!
Bright Dataは、SERPスクレイピングの複雑な作業を処理します。search_engineツールにより、LlamaIndexエージェントに検索クエリを実行させ、構造化された結果をMarkdownまたはJSON形式で受け取ることができます。
これは、あなたのAIエージェントが現在も将来も質問に答えられるように準備しておくために必要なものです。この統合がどのように機能するかは、次の章でご覧ください!
ブライト・データ・ツールを使ってウェブを検索できるLlamaIndexエージェントを構築する
このステップ・バイ・ステップのガイドでは、LlamaIndexを使って、ウェブを検索できるPythonのAIエージェントを構築する方法を紹介します。
Bright Dataと統合することで、貴社のエージェントは、新鮮で、文脈的で、リッチなウェブ検索データにアクセスできるようになります。詳しくは、公式ドキュメントをご覧ください。
以下の手順に従って、LlamaIndexを使用してBright Dataを搭載したAI SERPエージェントを作成してください!
前提条件
このチュートリアルに従うには、以下のものが必要です:
- Python 3.9以上がインストールされていること(最新バージョンの使用を推奨します)。
- Bright DataのSERP APIと統合するためのBright Data APIキー。
- サポートされているLLMからのAPIキー。(このガイドでは、API経由の統合を無料でサポートするGeminiを使用します。同時に、LlamaIndexがサポートするLLMプロバイダであれば、どのプロバイダでも使用することができます)。
GeminiまたはBright DataのAPIキーをまだお持ちでない方もご安心ください。次のステップで両方の作成方法を説明します。
ステップ #1: Pythonプロジェクトの初期化
まずターミナルを起動し、LlamaIndex AIエージェントプロジェクト用の新しいフォルダを作成します:
mkdir llamaindex-bright-data-serp-agentllamaindex-bright-data-serp-agent/は、Bright Dataによるウェブ検索機能を備えたAIエージェントのすべてのコードを保持します。
次に、プロジェクト・ディレクトリに移動し、その中にPython仮想環境を作成する:
cd llamaindex-bright-data-serp-agent
python -m venv venvプロジェクトフォルダをお気に入りのPython IDEで開きます。Python拡張機能付きのVisual Studio Codeか、PyCharm Community Editionをお勧めします。
プロジェクトディレクトリのルートにagent.pyという新しいファイルを作成します。プロジェクトの構造は以下のようになります:
llamaindex-bright-data-serp-agent/
├── venv/
└── agent.pyターミナルで、仮想環境をアクティブにする。LinuxまたはmacOSでは、以下を実行する:
source venv/bin/activate同様に、Windowsでは、実行する:
venv/Scripts/activate次のステップでは、必要なパッケージのインストールを案内する。しかし、前もってすべてをインストールしたい場合は、以下を実行してください:
pip install python-dotenv llama-index-tools-brightdata llama-index-llms-google-genai llama-index注: このチュートリアルでは、LlamaIndex LLMプロバイダとしてGeminiを使用しているため、llama-index-llms-google-genaiをインストールしています。他のプロバイダを使用する場合は、対応するLLMインテグレーションをインストールしてください。
お疲れ様です!あなたのPython開発環境は、LlamaIndexを使ったBright DataのSERP統合でAIエージェントを構築する準備が整いました。
ステップ2:環境変数の統合 読み方
LlamaIndexエージェントは、API経由でGeminiやBright Dataのような外部サービスに接続します。セキュリティのため、APIキーを直接Pythonコードにハードコードすべきではありません。その代わりに、環境変数を使用してAPIキーを非公開にしてください。
環境変数の管理を簡単にするためにpython-dotenvライブラリをインストールします。起動した仮想環境で
pip install python-dotenv次に、agent.pyファイルを開き、.envファイルからenvをロードするために以下の行を先頭に追加します:
from dotenv import load_dotenv
load_dotenv()load_dotenv()は、プロジェクトのルート・ディレクトリにある.envファイルを探し、その値を環境にロードします。
次に、.envファイルをagent.pyファイルと一緒に作成します。新しいプロジェクトのファイル構造は以下のようになります:
llamaindex-bright-data-serp-agent/
├── venv/
├── .env # <-------------
└── agent.py素晴らしい!サードパーティ・サービスのAPIクレデンシャルを安全に管理できるようになった。
.envファイルに必要な環境変数を入力して、初期セットアップを続けます!
ステップ3:ブライト・データの設定
公式統合パッケージを使用してLlamaIndexのBright Data SERP APIに接続するには、まず、以下の手順が必要です:
- Bright DataダッシュボードでWeb Unlockerソリューションを有効にします。
- Bright Data API トークンを取得します。
以下の手順に従ってセットアップを完了してください!
まだブライトデータのアカウントをお持ちでない場合は、[アカウントを作成]().アカウントをお持ちの場合は、ログインしてください。ダッシュボードで「プロキシ製品を取得」ボタンをクリックします:
プロキシとスクレイピング・インフラストラクチャ」ページに移動します:
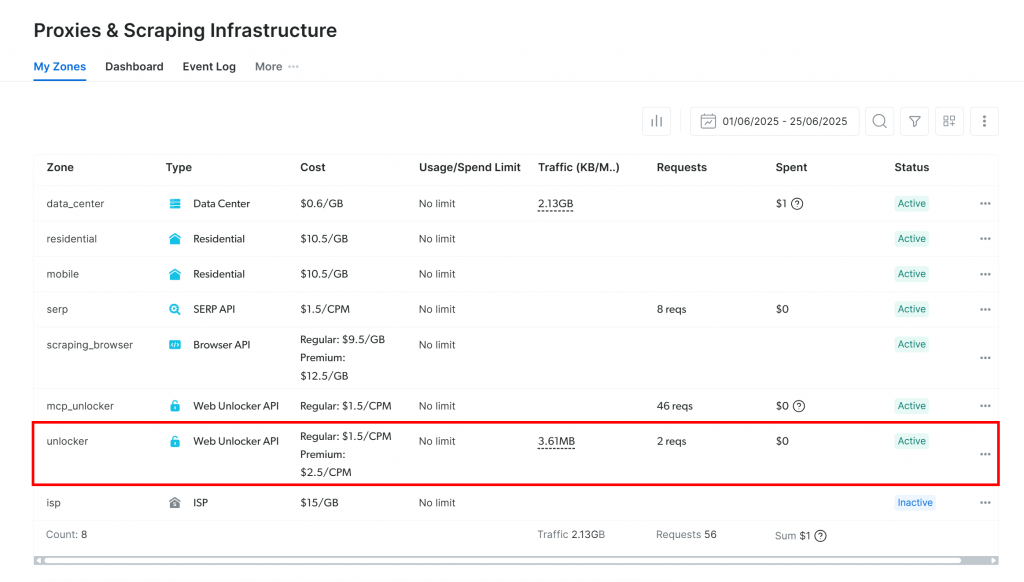
すでにアクティブな Web Unlocker API ゾーンが表示されていれば (上の画像のように)、準備は完了です。ゾーン名(例えば、unlocker)をメモしておいてください。
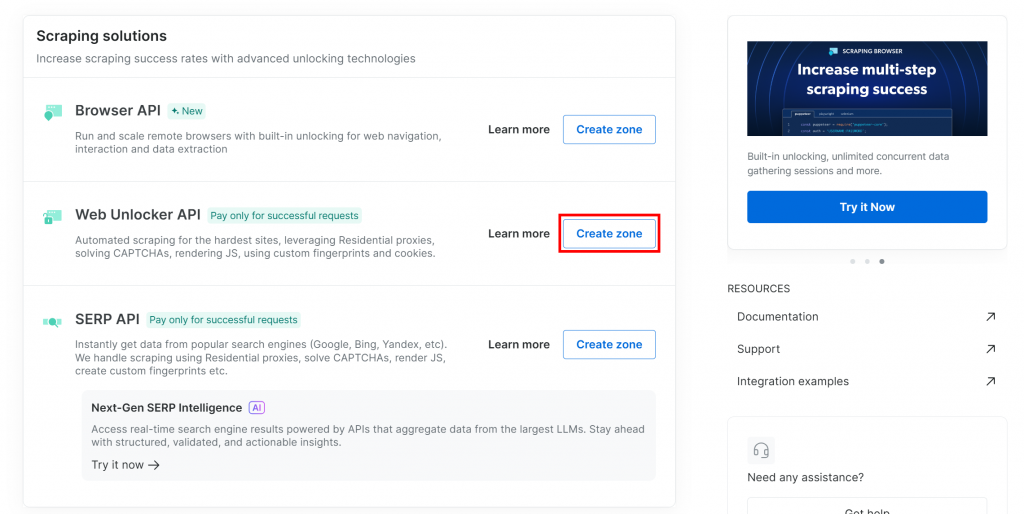
Web Unlockerゾーンをまだお持ちでない場合は、「Web Unlocker API」セクションまでスクロールダウンし、「ゾーンを作成」ボタンを押してください:
なぜ専用のSERP APIではなく、Web Unlocker APIを使用するのですか?
Bright DataのLlamaIndex SERP統合は、Web Unlocker APIを通して動作します。具体的には、適切に設定すれば、Web Unlockerは専用のSERP APIと同じように機能します。つまり、LlamaIndex Bright Data統合でWeb Unlocker APIゾーンを設定すると、自動的にSERP APIにもアクセスできるようになります。
新しいゾーンにアンロッカーなどの名前を付け、パフォーマンスを向上させるために高度な機能を有効にし、”Add “をクリックします:
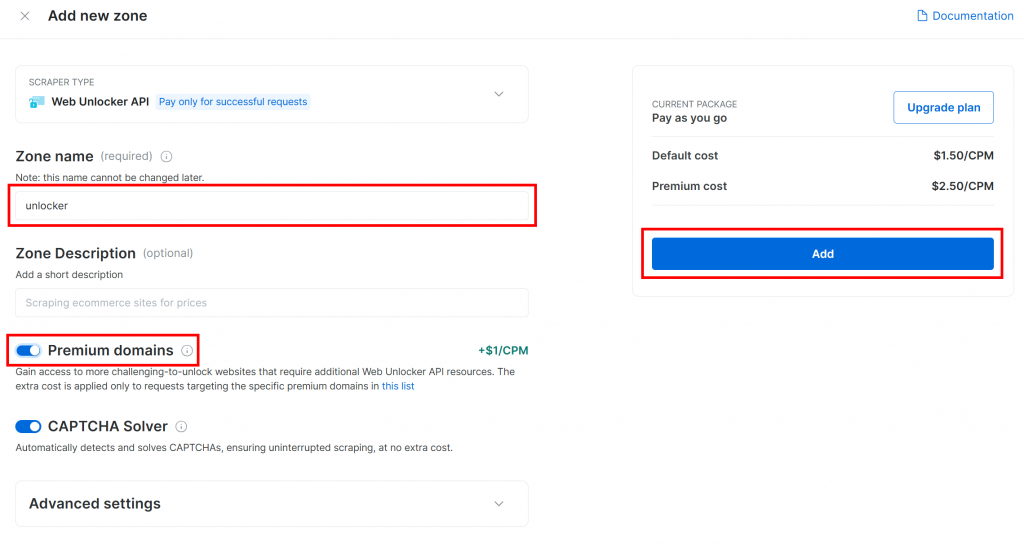
作成されると、ゾーンの設定ページにリダイレクトされます:
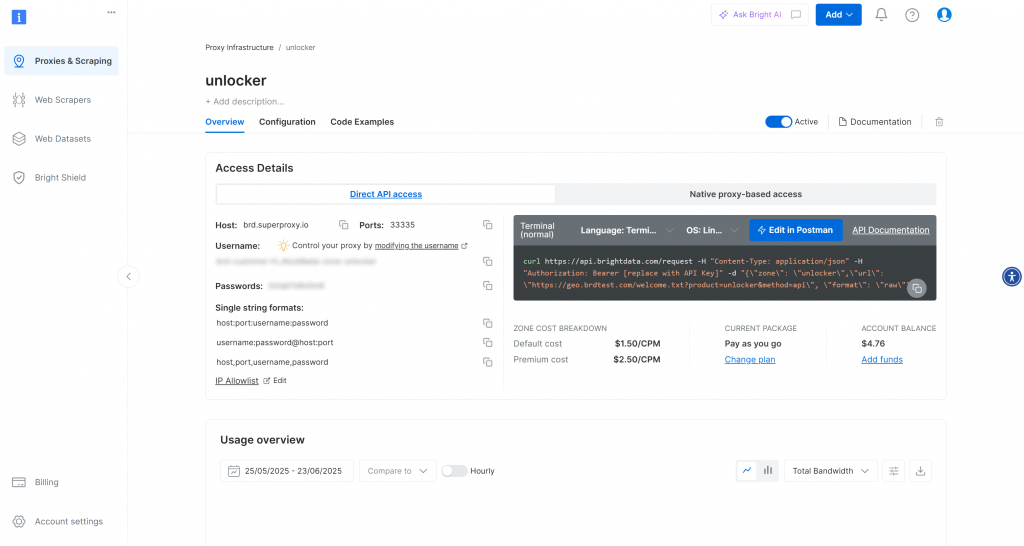
アクティベーション・トグルが「アクティブ」ステータスに設定されていることを確認します。これでゾーンが使用可能な状態になったことが確認されます。
次に、Bright Dataの公式ガイドに従ってAPIキーを生成します。キーを取得したら、次のように.envファイルに安全に保存してください:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"プレースホルダを プレースホルダを実際のAPIキー値に置き換える。
すごい!LlamaIndexエージェントスクリプトでBright Data SERPツールを設定します。
ステップ#4: Bright Data LlamaIndex SERPツールにアクセスする
agent.pyで、まずBright Data APIキーを環境から読み込みます:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Python標準ライブラリからosを必ずインポートすること:
import os起動した仮想環境に、LlamaIndex Bright Data ツールパッケージをインストールします:
pip install llama-index-tools-brightdata次に、agent.pyファイルでBrightDataToolSpecクラスをインポートします:
from llama_index.tools.brightdata import BrightDataToolSpecAPI キーと Web Unlocker ゾーンの名前を指定して、BrightDataToolSpec のインスタンスを作成します:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker", # Replace with the name of your Web Unlocker zone
verbose=True,
)zoneの値を、先ほど設定したWeb Unlocker APIゾーンの名前に置き換えてください(この場合はunlockerです)。
verbose=Trueに設定すると、開発中に便利です。そうすることで、LlamaIndexエージェントがBright Dataを通してリクエストしたときに、ライブラリが有用なログを出力します。
さて、BrightDataToolSpecはいくつかのツールを提供していますが、ここではsearch_engineツールに焦点を当てます。これは、Google、Bing、Yandexなどにクエリし、結果をMarkdownまたはJSONで返すことができます。
そのツールだけを取り出すには、こう書く:
brightdata_serp_tools = brightdata_tool_spec.to_tool_list(["search_engine"])to_tool_list()に渡された配列は、search_engineという名前のツールだけを含むフィルターとして機能する。
注意:デフォルトでは、LlamaIndexは与えられたユーザーリクエストに対して最も適切なツールを選択する。したがって、ツールのフィルタリングは厳密には必要ありません。このチュートリアルはBright DataのSERP機能を統合することに特化しているため、わかりやすくするためにsearch_engineツールに限定することに意味があります。
素晴らしい!Bright Dataが統合され、LlamaIndexエージェントにウェブ検索機能を提供する準備が整いました。
ステップ5:LLMモデルを接続する
このステップの説明では、この統合のためのLLMプロバイダーとしてGeminiを使用します。Geminiを選択する良い理由は、いくつかのモデルへのAPIアクセスを無料で提供していることです。
LlamaIndexでGeminiを使い始めるには、必要な統合パッケージをインストールしてください:
pip install llama-index-llms-google-genai次に、agent.pyでGoogleGenAIクラスをインポートします:
from llama_index.llms.google_genai import GoogleGenAIさて、ジェミニLLMを次のように初期化する:
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)この例では、gemini-2.5-flashモデルを使用しています。サポートされている他のGeminiモデルを自由に選択してください。
舞台裏では、GoogleGenAIクラスは自動的にGEMINI_API_KEYという環境変数を探します。この環境変数から読み取ったAPIキーを使用して、Gemini APIに接続します。
.envファイルを開き、追加して設定する:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"プレースホルダを プレースホルダを実際のGemini APIキーに置き換えてください。まだお持ちでない場合は、公式のGemini API取得ガイドに従って無料で取得できます。
注:別のLLMプロバイダーを使いたい場合、LlamaIndexは多くのオプションをサポートしています。設定方法についてはLlamaIndexの公式ドキュメントを参照してください。
よくやった!これで、ウェブを検索できるLlamaIndex AIエージェントを構築するための核となるピースがすべて揃ったことになる。
ステップ #6: LlamaIndexエージェントの定義
まず、メインのLlamaIndexパッケージをインストールする:
pip install llama-index次に、agent.py ファイルで FunctionAgent クラスをインポートします:
from llama_index.core.agent.workflow import FunctionAgentFunctionAgentはLlamaIndexに特化したAIエージェントで、先に設定したBright Data SERPツールのような外部ツールと対話することができます。
以下のように、LLM と Bright Data SERP ツールでエージェントを初期化します:
agent = FunctionAgent(
tools=brightdata_serp_tools,
llm=llm,
verbose=True, # Useful while developing
system_prompt="""
You are a helpful assistant that can retrieve SERP results in JSON format.
"""
)これは、LLMを通してユーザーの入力を処理するAIエージェントを作成し、必要な時にリアルタイムのウェブ検索を実行するためにBright Data SERPツールを呼び出すことができます。エージェントの役割と動作を定義する system_prompt 引数に注意してください。ここでも、verbose=Trueフラグは内部アクティビティを検査するのに便利です。
素晴らしい!LlamaIndex + Bright Data SERPの統合が完了しました。次のステップは、インタラクティブに使用するためのREPLの実装です。
ステップ7: REPLの構築
REPLとは、”Read-Eval-Print Loop“の略で、コマンドを入力し、評価され、その結果を見るというインタラクティブなプログラミング・パターンである。
この文脈では、REPLは次のように動作する:
- AIエージェントに処理させたいタスクを記述する。
- AIエージェントがタスクを実行し、必要に応じてオンライン検索を行う。
- ターミナルに表示される応答を見る。
このループは、「exit」と入力するまで無限に続く。
agent.pyに、REPLのロジックを処理するための非同期関数を追加します:
async def main():
print("Gemini-based agent with web searching capabilities powered by Bright Data. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = await agent.run(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")このREPL関数:
input()経由でコマンドラインからのユーザー入力を受け付ける。agent.run()を通して、GeminiとBright Dataが提供するLlamaIndexエージェントを使用して入力を処理する。- コンソールに応答を表示する。
agent.run()は非同期なので、REPLロジックは非同期関数内に記述する必要があります。ファイルの一番下でこのように実行します:
if __name__ == "__main__":
asyncio.run(main())asyncioのインポートも忘れずに:
import asyncioお待たせしました!SERPスクレイピングツールを備えたLlamaIndex AIエージェントの準備が整いました。
ステップ#8:すべてをまとめてAIエージェントを動かす
これがあなたのagent.pyファイルが含むべき内容です:
from dotenv import load_dotenv
import os
from llama_index.tools.brightdata import BrightDataToolSpec
from llama_index.llms.google_genai import GoogleGenAI
from llama_index.core.agent.workflow import FunctionAgent
import asyncio
# Load environment variables from the .env file
load_dotenv()
# Read the Bright Data API key from the envs
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Set up the Bright Data Tools
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker", # Replace with the name of your Web Unlocker zone
verbose=True, # Useful while developing
)
# Get only the "search_engine" (SERP scraping) tool
brightdata_serp_tools = brightdata_tool_spec.to_tool_list(["search_engine"])
# Configure the connection to Gemini
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)
# Create the LlamaIndex agent powered by Gemini and connected to Bright Data tools
agent = FunctionAgent(
tools=brightdata_serp_tools,
llm=llm,
verbose=True, # Useful while developing
system_prompt="""
You are a helpful assistant that can retrieve SERP results in JSON format.
"""
)
# Async REPL loop
async def main():
print("Gemini-based agent with web searching capabilities powered by Bright Data. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = await agent.run(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")
if __name__ == "__main__":
asyncio.run(main())LlamaIndex SERPエージェントを実行する:
python agent.pyスクリプトが起動すると、ターミナルに次のようなプロンプトが表示される:

例えば、新鮮な情報が必要なことをエージェントに尋ねてみてください:
Write a short Markdown report on the new AI protocols, including some real-world links for further reading.このタスクを効果的に実行するために、AIエージェントは最新の情報をウェブ上で検索する必要がある。
結果はこうなる:
かなり早かったので、何が起こったかを説明しよう:
- エージェントは、”新しいAIプロトコル “を検索する必要性を検出し、search_engineツールを介してBright Data SERP APIをこの入力URLを使って
呼び出します: https://www.google.com/search?q=new%20AI%20protocols&num=10&brd_json=1. - このツールは、Bright DataのGoogle Search APIからJSON形式のSERPデータを非同期に取得します。
- エージェントは、JSON応答をGemini LLMに渡す。
- ジェミニは新鮮なデータを処理し、関連するリンクを含む明確で正確なMarkdownレポートを作成します。
この場合、AIエージェントは戻ってきた:
## New AI Protocols: A Brief Report
The rapid advancement of Artificial Intelligence has led to the emergence of new protocols designed to enhance interoperability, communication, and data handling among AI systems and with external data sources. These protocols aim to standardize how AI agents interact, leading to more scalable and integrated AI deployments.
Here are some of the key new AI protocols:
### 1. Model Context Protocol (MCP)
The Model Context Protocol (MCP) is an open standard that facilitates secure, two-way connections between AI-powered tools and various data sources. It fundamentally changes how AI assistants interact with the digital world by allowing them to access and utilize external information more effectively. This protocol is crucial for enabling AI models to communicate with external data sources and for building more capable and context-aware AI applications.
**Further Reading:**
* **Introducing the Model Context Protocol:** [https://www.anthropic.com/news/model-context-protocol](https://www.anthropic.com/news/model-context-protocol)
* **How A Simple Protocol Is Changing Everything About AI:** [https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/](https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/)
* **The New Model Context Protocol for AI Agents:** [https://evergreen.insightglobal.com/the-new-model-context-protocol-for-ai-agents/](https://evergreen.insightglobal.com/the-new-model-context-protocol-for-ai-agents/)
* **Model Context Protocol: The New Standard for AI Interoperability:** [https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/](https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/)
* **Hot new protocol glues together AI and apps:** [https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source](https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source)
### 2. Agent2Agent Protocol (A2A)
The Agent2Agent Protocol (A2A) is a cross-platform specification designed to enable AI agents to communicate with each other, securely exchange information, and coordinate actions. This protocol is vital for fostering collaboration among different AI agents, allowing them to work together on complex tasks and delegate responsibilities across various enterprise systems.
**Further Reading:**
* **Announcing the Agent2Agent Protocol (A2A):** [https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/](https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/)
* **What Every AI Engineer Should Know About A2A, MCP & ACP:** [https://medium.com/@elisowski/what-every-ai-engineer-should-know-about-a2a-mcp-acp-8335a210a742](https://medium.com/@elisowski/what-every-ai-engineer-should-know-about-a2a-mcp-acp-8335a210a742)
* **What a new AI protocol means for journalists:** [https://www.dw.com/en/what-coding-agents-and-a-new-ai-protocol-mean-for-journalists/a-72976193](https://www.dw.com/en/what-coding-agents-and-a-new-ai-protocol-mean-for-journalists/a-72976193)
### 3. Agent Communication Protocol (ACP)
The Agent Communication Protocol (ACP) is an open standard specifically for agent-to-agent communication. Its purpose is to transform the current landscape of siloed AI agents into interoperable agentic systems, promoting easier integration and collaboration between them. ACP provides a standardized messaging framework for structured communication.
**Further Reading:**
* **MCP, ACP, and Agent2Agent set standards for scalable AI:** [https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html](https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html)
* **What is Agent Communication Protocol (ACP)?** [https://www.ibm.com/think/topics/agent-communication-protocol](https://www.ibm.com/think/topics/agent-communication-protocol)
* **MCP vs A2A vs ACP: AI Protocols Explained:** [https://www.bluebash.co/blog/mcp-vs-a2a-vs-acp-agent-communication-protocols/](https://www.bluebash.co/blog/mcp-vs-a2a-vs-acp-agent-communication-protocols/)
These emerging protocols are crucial steps towards a more interconnected and efficient AI ecosystem, enabling more sophisticated and collaborative AI applications across various industries.AIエージェントの応答には、ジェミニの最後のトレーニング更新後に公開された最新のプロトコルや最新のリンクが含まれていることに注目してほしい。これは、ライブウェブ検索機能を統合することの価値を強調している。
具体的には、Googleで “new ai protocols “と検索すると出てくるような、文脈に沿ったリンクが含まれている:
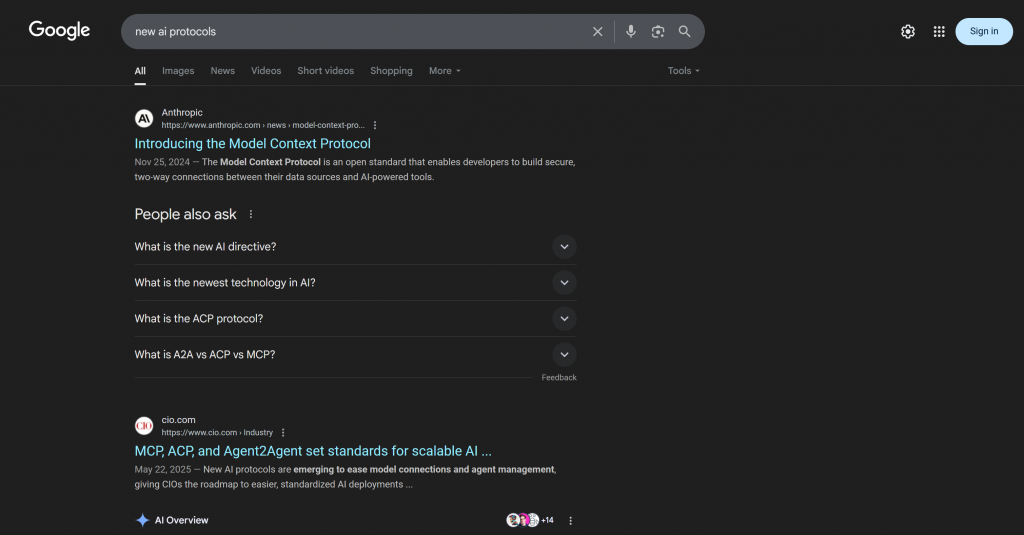
この回答には、実際の「新しいAIプロトコル」SERP(少なくとも執筆時点)で見られるのと同じリンクが多数含まれていることに注目してほしい。
出来上がり!これで、Bright Dataによる検索エンジンのスクレイピング機能を備えたLlamaIndex AIエージェントの完成です。
ステップ#9:次のステップ
現在のLlamaIndex SERP AIエージェントは、Bright Dataのsearch_engineツールだけを使用した単純な例に過ぎない。
より高度なシナリオでは、おそらくエージェントを一つのツールに限定したくないでしょう。その代わりに、エージェントがすべての利用可能なツールにアクセスできるようにし、LLMがそれぞれの目標に対してどのツールを使うかを決定できるように、明確なシステムプロンプトを書く方が良いでしょう。
たとえば、プロンプトをさらに一歩進めて、こうすることもできる:
- 複数の検索クエリを実行する。
- SERPの結果から上位N個のリンクを選択する。
- それらのページにアクセスし、コンテンツをMarkdownでスクレイピングする。
- その情報から学び、より豊かで詳細なアウトプットを生み出す。
利用可能なすべてのツールとの統合に関する詳しいガイダンスについては、LlamaIndexとBright Dataを使ったAIエージェントの構築に関するチュートリアルをご覧ください。
結論
この記事では、LlamaIndexを使用して、Bright Data経由でウェブ検索が可能なAIエージェントを構築する方法を学びました。この統合により、エージェントはGoogle、Bing、Yandexなどの主要な検索エンジンで検索クエリを実行できるようになります。
ここで取り上げた例は、出発点に過ぎないことに留意してください。より高度なエージェントを開発するつもりであれば、ライブのウェブデータを取得、検証、変換するための堅牢なツールが必要です。それこそが、Bright Dataのエージェント用AIインフラストラクチャが提供するものです。
ブライトデータの無料アカウントを作成し、エージェント型AIデータツールの探索を今すぐ始めましょう!




