

データ収集の手法である Web スクレイピングは、IP の禁止、ジオブロッキング、プライバシーの問題など、さまざまな障害によって妨げられることがよくあります。幸い、これらの課題を乗り越えるのにプロキシサーバーが有効です。プロキシサーバーはユーザーのコンピューターとインターネットの間の仲介役となり、独自の IP アドレスで要求を処理します。この機能は、IP 関連の制限や禁止を回避するだけでなく、地理的に制限されたコンテンツへのアクセスも容易になります。さらに、プロキシサーバーは Web スクレイピング中に匿名性を維持し、プライバシーの保護にも役立ちます。
また、プロキシサーバーを利用することで、Web スクレイピングのパフォーマンスと信頼性を向上させることもできます。要求を複数のサーバーに分散させることで、1 台のサーバーに過剰な負荷がかからないようにし、プロセスを最適化します。
このチュートリアルでは、Web スクレイピングプロジェクト向けに Node.js でプロキシサーバーを使用する方法を解説します。
前提条件
このチュートリアルを始める前に、JavaScript と Node.js についてある程度理解しておくことをお勧めします。Node.js がコンピューターにまだインストールされていない場合は、 今すぐインストールする必要があります。
適切なテキストエディターも必要です。Sublime Text など、いくつかの選択肢があります。このチュートリアルでは、Visual Studio Code (VS Code) を使用します。このエディターは使いやすく、コーディングを容易にする機能が満載です。
はじめに、web-scraping-proxy という名前の新しいディレクトリを作成し、Node.js プロジェクトを初期化します。ターミナルまたはシェルを開き、次のコマンドを使用して新しいディレクトリに移動します。
cd web-scraping-proxy
npm init -y
次に、HTTP 要求を処理して HTML を解析するために、Node.js パッケージをいくつかインストールする必要があります。
プロジェクトディレクトリにいることを確認し、次のコマンドを実行します。
npm install axios playwright puppeteer http-proxy-agent
npx playwright install
HTTP 要求で Web コンテンツを取得するには、axios を使用します。Playwright と Puppeteer は、動的な Web サイトのスクレイピングに不可欠なブラウザの操作を自動化します。Playwright はさまざまなブラウザをサポートしており、Puppeteer は Chrome または Chromium に焦点を当てています。http-proxy-agent ライブラリは、HTTP 要求用のプロキシエージェントの作成に使用します。
playwright ライブラリが使用する必須のドライバをインストールするには、npx playwright のインストールが必要です。
これらの手順を終えたら、Node.js を使用して Web スクレイピングの世界に飛び込む準備は完了です。
Web スクレイピング用のローカルプロキシの設定
Web スクレイピングの重要な最初のステップは、プロキシサーバーの確立です。このチュートリアルでは、オープンソースツールの mitmproxy を使用します。
はじめに、mitmproxy ダウンロードページにアクセスして、お使いのオペレーティングシステムに合わせたバージョン 10.1.6 をダウンロードします。インストール中にガイダンスが必要な場合は、mitmproxy インストールガイドを参照してください。
mitmproxy をインストールしたら、ターミナルで次のコマンドを入力して起動します。
mitmproxy
このコマンドは、mitmproxy のインターフェースとなるウィンドウをターミナルに開きます。
プロキシが正しく設定されていることを確認するには、テストしてみます。新しいターミナルウィンドウを開き、次のコマンドを実行します。
curl --proxy http://localhost:8080 "http://wttr.in/Paris?0"
このコマンドは、パリの天気予報を取得します。出力は以下のようになります。
Weather report: Paris
Overcast
.--. -2(-6) °C
.-( ). ↙ 11 km/h
(___.__)__) 10 km
0.0 mm
mitmproxy ウィンドウに戻ると、要求がキャプチャされたことがわかります。これは、ローカルプロキシが正しく機能していることを示しています。

Web スクレイピング用の Node.js へのプロキシの実装
それでは、Node.js を使った Web スクレイピングの実用的な側面に移ります。このセクションでは、ローカルプロキシサーバー経由で要求を送信して Web サイトをスクレイピングするスクリプトを作成します。
Fetch メソッドによる Web サイトのスクレイピング
プロジェクトのルートディレクトリに fetchScraping.js という新しいファイルを作成します。このファイルには、Web サイト (この例では https://toscrape.com/) からコンテンツをスクレイピングするコードが含まれます。
fetchScraping.js に、次の JavaScript コードを入力します。このスクリプトは fetch メソッドを使用してプロキシサーバー経由で要求を送信します。
const fetch = require("node-fetch");
const HttpProxyAgent = require("http-proxy-agent");
async function fetchData(url) {
try {
const proxyAgent = new HttpProxyAgent.HttpProxyAgent(
"http://localhost:8080"
);
const response = await fetch(url, { agent: proxyAgent });
const data = await response.text();
console.log(data); // Outputs the fetched data
} catch (error) {
console.error("Error fetching data:", error);
}
}
fetchData("http://toscrape.com/");
このコードスニペットは、非同期関数 fetchData を定義しています。この関数は URL を受け取り、ローカルプロキシにルーティングすると同時に fetch を使用してその URL に要求を送信します。次に、応答データが出力されます。
Web スクレイピングスクリプトを実行するには、ターミナルまたはシェルを開き、fetchScraping.js ファイルがあるプロジェクトのルートディレクトリに移動します。次のコマンドを使用してスクリプトを実行します。
node fetchScraping.js
ターミナルに次の出力が表示されます。
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
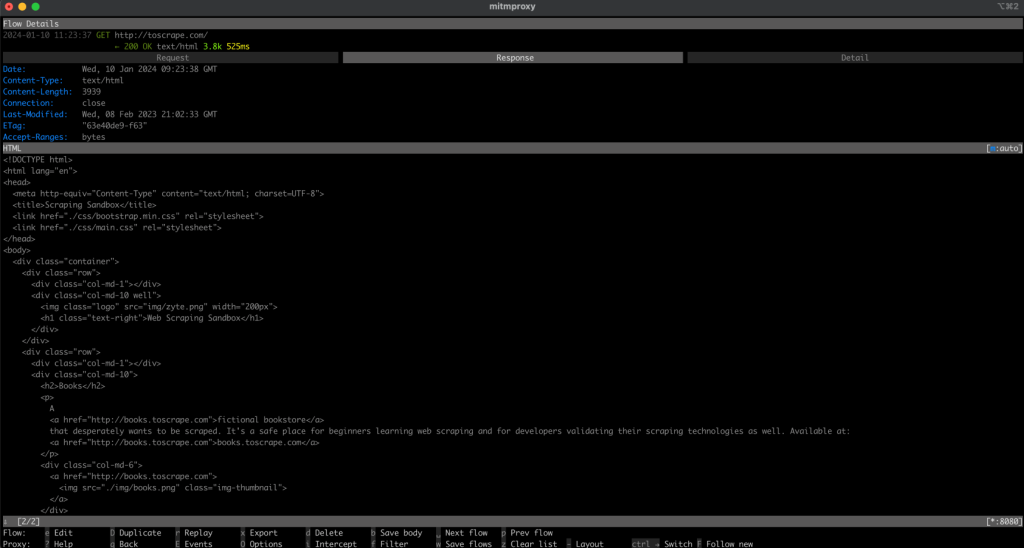
この出力は http://toscrape.com Web ページの HTML コンテンツです。このデータが正常に表示されたということは、ローカルプロキシ経由でルーティングされた Web スクレイピングスクリプトが正しく機能していることを示しています。
mitmproxy ウィンドウに戻ると、要求がログに記録されています。つまり、要求はローカルプロキシを経由したということです。
Playwright を使用した Web サイトのスクレイピング
Fetch と比較して、Playwright は Web ページのより動的な操作を可能にする高度なツールです。使用するには、プロジェクトに playwrightScraping.js という新しいファイルを作成する必要があります。このファイルに、次の JavaScript コードを入力します。
const { chromium } = require("playwright");
(async () => {
const browser = await chromium.launch({
proxy: {
server: "http://localhost:8080",
},
});
const page = await browser.newPage();
await page.goto("http://toscrape.com/");
// Extract and log the entire HTML content
const content = await page.content();
console.log(content);
await browser.close();
})();
このコードは Playwright を使用して、ローカルプロキシサーバーを使用するように構成された Chromium ブラウザインスタンスを起動します。その後、ブラウザで新しいページを開き、 http://toscrape.com に移動し、ページが読み込まれるのを待ちます。必要なデータをスクレイピングした後、ブラウザは閉じられます。
このスクリプトを実行するには、playwrightScraping.js があるディレクトリにいることを確認してください。ターミナルまたはシェルを開き、次のコマンドを使用してスクリプトを実行します。
node playwrightScraping.js
スクリプトを実行すると、Playwright は Chromium ブラウザを起動し、指定された URL に移動し、ユーザーが追加した他のスクレイピングコマンドを実行します。このプロセスではローカルプロキシサーバーを使用するため、IP アドレスが公開されるのを防ぎ、潜在的な制限を回避できます。
出力は前のものと似たものになります。
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
以前と同様に、要求が mitmproxy ウィンドウに記録されます。
Puppeteer を使用した Web サイトのスクレイピング
今度は Puppeteer を使って Web サイトをスクレイピングします。Puppeteer は、ヘッドレスの Chrome または Chromium ブラウザを高度に制御できる強力なツールです。この方法は、JavaScript のレンダリングを必要とする動的 Web サイトをスクレイピングする場合に特に有効です。
まず、プロジェクトに puppeteerScraping.js という新しいファイルを作成します。このファイルには、要求に応じてプロキシサーバーを使用して Web サイトをスクレイピングするための Puppeteer コードが含まれます。
新しく作成した puppeteerScraping.js ファイルを開き、次の JavaScript コードを挿入します。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
args: ['--proxy-server=http://localhost:8080']
});
const page = await browser.newPage();
await page.goto('http://toscrape.com/');
const content = await page.content();
console.log(content); // Outputs the page HTML
await browser.close();
})();
このコードは、Puppeteer を初期化してヘッドレスブラウザを起動し、ローカルプロキシサーバーを使用するよう指定します。ブラウザは新しいページを開き、http://toscrape.com に移動して、ページの HTML コンテンツを取得します。コンテンツがコンソールに記録されると、ブラウザセッションは閉じられます。
スクリプトを実行するには、ターミナルまたはシェルで puppeteerScraping.js を含むフォルダに移動します。次のコマンドを使用してスクリプトを実行します。
node puppeteerScraping.js
スクリプトを実行した後、Puppeteer はプロキシサーバーを使用して http://toscrape.com/ URL を開きます。ターミナルにページの HTML コンテンツが出力されます。これは、Puppeteer スクリプトがローカルプロキシ経由で Web ページを正常にスクレイピングしていることを示しています。
出力は前のものと同様になり、要求が mitmproxy ウィンドウに記録されます。
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
より優れた代替手段: Bright Data プロキシサーバー
Web スクレイピングの能力向上を検討している場合は、Bright Data の使用をお勧めします。Bright Data プロキシサーバーは、Web 要求を管理するための高度なソリューションを提供します。
Bright Data は、居住用、ISP、データセンター、モバイルプロキシなど、多様なプロキシサーバーを提供しており、さまざまな場所からあらゆる Web サイトにアクセスできます。これにより、異なるタイプのユーザーエージェントをエミュレートして匿名性を維持できます。
また、Bright Data はプロキシローテーションも提供し、異なるプロキシを自動的に切り替えて IP が禁止されるのを防ぐることで、Web スクレイピングの効率と匿名性を向上させます。
さらに、Bright Data のスクレイピングブラウザも使用できます。これは、CAPTCHA、cookie、ブラウザフィンガープリントなどに対するブロック解除機能が組み込まれた自動ブラウザです。また、機械学習アルゴリズムを搭載した Bright Data Web Unlocker を活用して、ターゲット Web サイトからのあらゆるブロックを回避し、妨害されずにデータを収集することもできます。
Node.js プロジェクトへの Bright Data プロキシの実装
Bright Data プロキシを Node.js プロジェクトに取り入れるには、無料トライアルにサインアップする必要があります。アカウントが有効になったら、サインインしてプロキシおよびスクレイピングインフラストラクチャに移動し、住宅用プロキシを選択して新しいプロキシを追加します。
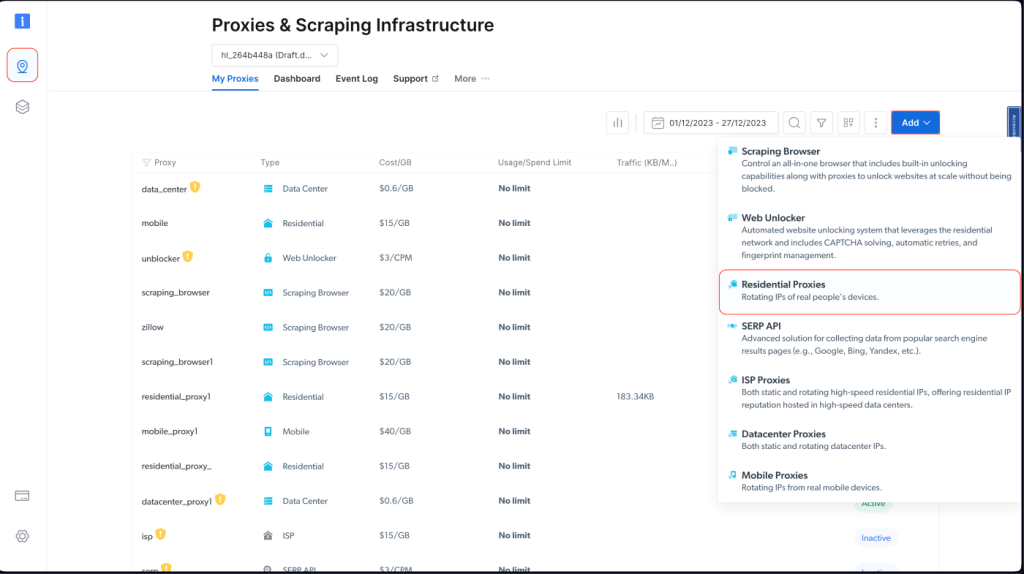
デフォルトの設定のまま、住宅用プロキシの作成を完了させます。
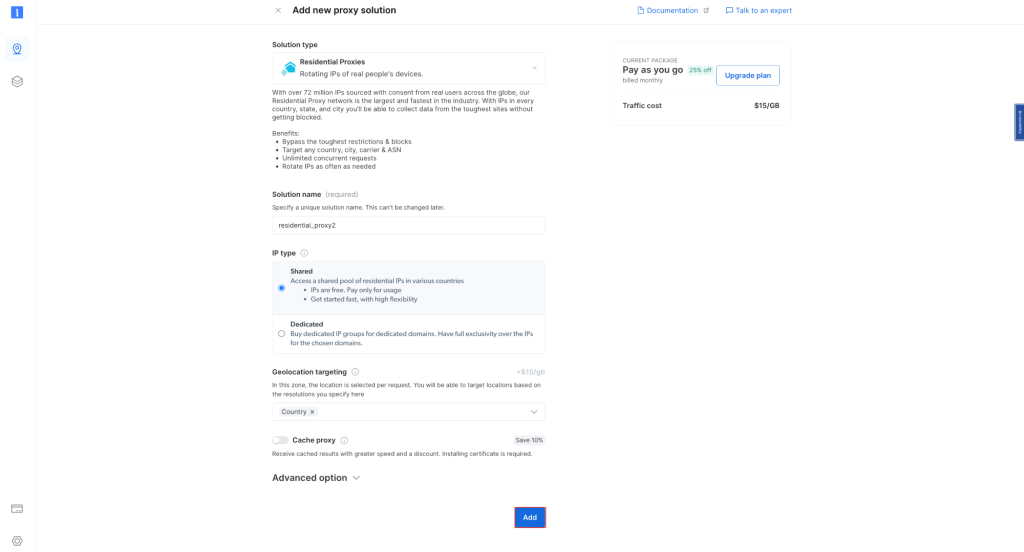
作成したら、ホスト、ポート、ユーザー名、パスワードなどのプロキシ認証情報を書き留めます。これらは次のステップで必要になります。
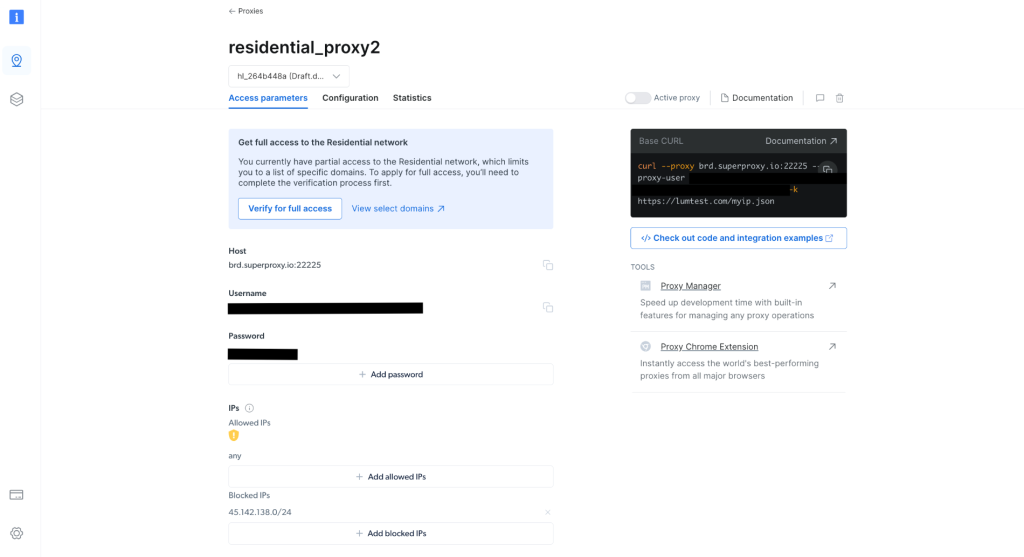
プロジェクトで scrapingWithBrightData.js ファイルを作成し、次のスニペットを追加します。プレースホルダーのテキストは、Bright Data のプロキシ認証情報に置き換えてください。
const axios = require('axios');
async function fetchDataWithBrightData(url) {
const proxyOptions = {
proxy: {
host: 'YOUR_BRIGHTDATA_PROXY_HOST',
port: YOUR_BRIGHTDATA_PROXY_PORT,
auth: {
username: 'YOUR_BRIGHTDATA_USERNAME',
password: 'YOUR_BRIGHTDATA_PASSWORD'
}
}
};
try {
const response = await axios.get(url, proxyOptions);
console.log(response.data); // Outputs the fetched data
} catch (error) {
console.error('Error:', error);
}
}
fetchDataWithBrightData('http://lumtest.com/myip.json');
このスクリプトは、Bright Data プロキシ経由で HTTP 要求をルーティングするように、axios を構成します。このプロキシ構成を使用して、指定された URL からデータを取得します。この例では、Bright Data の構成に基づいてさまざまなプロキシサーバーソースが使用されていることを確認できるように、http://lumtest.com/myip.json をターゲットにします。
スクリプトを実行するには、ターミナルまたはシェルで scrapingWithBrightData.js を含むフォルダに移動します。次に、次のコマンドを使用してスクリプトを実行します。
node scrapingWithBrightData.js
コマンドを実行すると、主に Bright Data のプロキシサーバーに関連する IP アドレスの場所が、コンソールに出力されます。
出力は次のようになります。
{
ip: '108.53.191.230',
country: 'US',
asn: { asnum: 701, org_name: 'UUNET' },
geo: {
city: 'Jersey City',
region: 'NJ',
region_name: 'New Jersey',
postal_code: '07302',
latitude: 40.7182,
longitude: -74.0476,
tz: 'America/New_York',
lum_city: 'jerseycity',
lum_region: 'nj'
}
}
ここで、ノード scrapingWithBrightData.js でスクリプトを再度実行すると、Bright Data プロキシサーバーにより異なる IP アドレスの場所が使用されていることがわかります。これにより、Bright Data はスクレイピングスクリプトを実行するたびに異なる場所と IP を使用するため、ターゲット Web サイトからのブロックや IP の禁止を回避できることが確認できます。
出力は次のようになります。
{
ip: '93.85.111.202',
country: 'BY',
asn: {
asnum: 6697,
org_name: 'Republican Unitary Telecommunication Enterprise Beltelecom'
},
geo: {
city: 'Orsha',
region: 'VI',
region_name: 'Vitebsk',
postal_code: '211030',
latitude: 54.5081,
longitude: 30.4172,
tz: 'Europe/Minsk',
lum_city: 'orsha',
lum_region: 'vi'
}
}
Bright Data はわかりやすいインターフェースと設定により、誰でも (初心者でも) 簡単に強力なプロキシ管理機能を効果的に使用できます。
まとめ
この記事では、Node.js でプロキシを使用する方法を解説しました。Bright Data のような適切なプロキシ管理ソリューションがないと、IP の禁止やターゲット Web サイトへのアクセス制限などの課題に直面し、スクレイピングが妨げられる可能性があります。また、Bright Data プロキシを使って Web スクレイピングを強化するのがいかに簡単かについても、ご理解いただけたと思います。これらのサーバーは、データ収集プロセスの堅牢性と効率性を高めるだけでなく、さまざまなスクレイピングシナリオに必要な汎用性も実現します。
これらのスキルを実践する際には、Web サイトの利用規約やデータプライバシー法の範囲内で行うことの重要性を忘れないでください。Web サイトで定められたルールに従い、責任を持ってスクレイピングすることが重要です。この記事で得た知識、特に Bright Data プロキシが提供する機能を利用すれば、倫理的な Web スクレイピングを成功させるための準備は万端です。スレイピングをお楽しみください!
このチュートリアルで使用されたコードはすべて、こちらの GitHub リポジトリでご利用いただけます。



