

HtmlUnitは、HTMLページのモデリングが可能なヘッドレスブラウザです。ページをプログラムでモデリングした後、フォームへの入力や送信、ページ間の移動などのタスクを実行してページとやり取りできます。これを使ってウェブスクレイピングを行い、データを抽出して後で操作することも、自動テストを作成してプログラムが期待通りにウェブページを作成しているか確認することもできます。
HtmlUnitを使ったWebスクレイピング
HtmlUnitとGradleを使ってウェブスクレイピングを実装するために、IntelliJ IDEA IDEが使用されますが、好みのIDEやコードエディタを使ってもかまいません。
IntelliJはGradleとの完全な機能統合をサポートしており、JetBrainsのサイトからダウンロードできます。Gradleは、アプリケーションのビルドやパッケージの作成をサポートするビルド自動化ツールです。また、依存関係を追加して、シームレスに管理できます。IntelliJ IDEAの最新バージョンでは、GradleおよびGradle拡張機能がデフォルトでインストールされ、有効になっています。
このチュートリアルのすべてのコードは、このGitHubリポジトリで見つけることができます。
Gradleプロジェクトを作成する
IntelliJ IDEでGradleプロジェクトを新規作成するには、メニューオプションから「ファイル」 > 「新規」 > 「プロジェクト」を選択して、新規プロジェクトウィザードを表示します。プロジェクト名を入力し、目的の場所を選択します。

HtmlUnitを使用してJava言語でウェブスクレイピングアプリケーションを作成するため、Javaを選択する必要があります。さらに、Gradleビルドシステムを選択します。次に「作成」をクリックします。これで、デフォルトの構造と必要なファイルをすべて備えたGradleプロジェクトが作成されます。例えば、build.gradleファイルには、このプロジェクトをビルドするのに必要なすべての依存関係が含まれています。
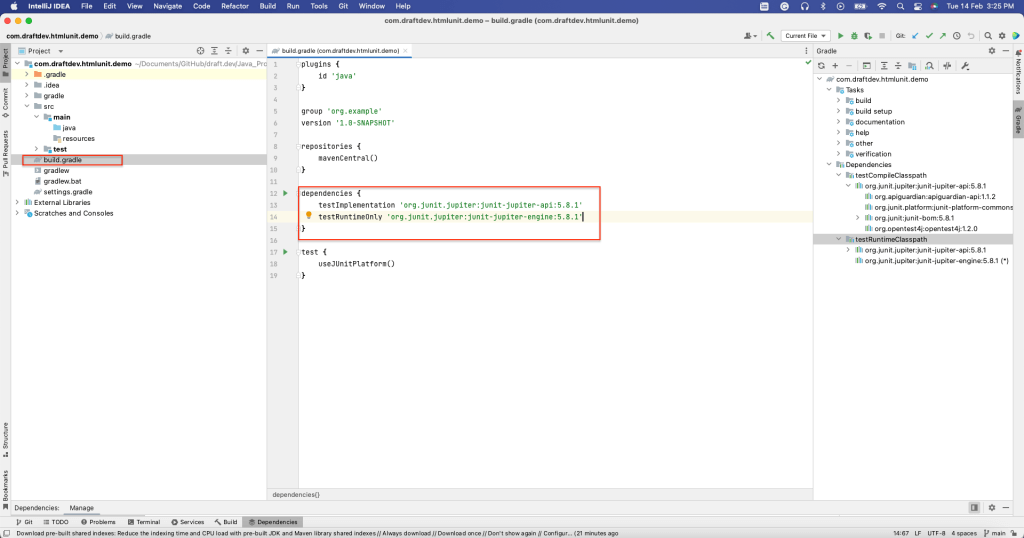
HtmlUnitをインストールする
HtmlUnitを依存関係としてインストールするには、「表示」 > 「ツールウィンドウ」 > 「依存関係」を選択して、「依存関係」ウィンドウを開きます。
次に、「htmlunit」を検索して、「追加」を選択します。
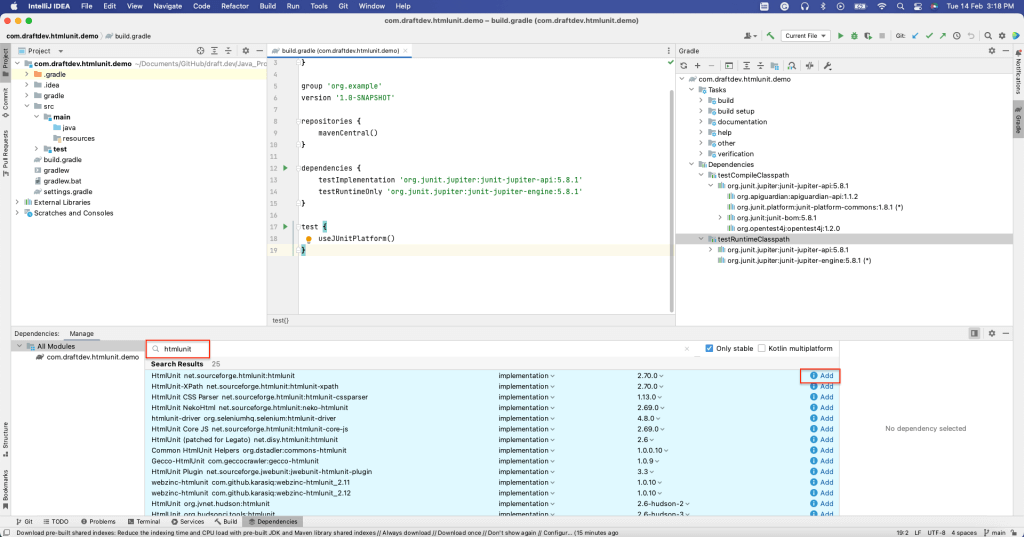
build.gradleファイルのdependenciesセクションにHtmlUnitがインストールされたことが確認できるはずです。

HtmlUnitをインストールしたので、いよいよ静的および動的なウェブページからデータをスクレイピングしましょう。
静的なページをスクレイピングする
このセクションでは、静的なウェブページであるHtmlUnit Wikiをスクレイピングする方法について学びます。このウェブページには、タイトル、目次、小見出しのリスト、各小見出しのコンテンツなどの要素が含まれます。
HTMLウェブページの各要素には属性があります。例えば、IDはHTMLドキュメント全体の中で要素を一意に識別する属性で、Nameはその要素を識別する属性です。Name属性は一意ではなく、HTMLドキュメント内の複数の要素が同じ名前を持つことがあります。ウェブページ内の要素は、これらの属性のいずれかを使用して識別できます。
また、そのXPathを利用して要素を識別することもできます。XPathは、ウェブページのHTML内の要素を識別し、ナビゲートするためにパスのような構文を使用します。
以下の例では、これらの方法の両方を使用してHTMLページ内の要素を識別します。
ウェブページをスクレイピングするためには、HtmlUnit WebClientを作成する必要があります。WebClientは、Javaアプリケーション内のブラウザを表します。WebClientの初期化は、ブラウザを起動してウェブページを表示するのに似ています。
WebClientを初期化するには、次のコードを使用します。
WebClient webClient = new WebClient(BrowserVersion.CHROME);
このコードは、Chromeブラウザを初期化します。その他のブラウザにも対応しています。
webClientオブジェクトで利用可能なgetPage()メソッドを使用してウェブページを取得できます。ウェブページを入手したら、さまざまな方法でウェブページからデータをスクレイピングできます。
ページタイトルを取得するには、次のコードに示すようにgetTitleText()メソッドを使用します。
String webPageURl = u0022https://en.wikipedia.org/wiki/HtmlUnitu0022;n try {nn HtmlPage page = webClient.getPage(webPageURl);n n System.out.println(page.getTitleText());n n } catch (FailingHttpStatusCodeException | IOException e) {n n e.printStackTrace();n n }
すると、ページのタイトルが次のように出力されます。
HtmlUnit - Wikipedia
さらに一歩踏み込んで、ウェブページで利用可能なすべてのH2要素を取得しましょう。この例では、ページ内の2つのセクションでH2が利用可能です。
- 左側のサイドバーには、コンテンツが表示されます。ご覧のように、Contentsセクションの見出しはH2要素です。
- ページのメインボディ:すべての小見出しはH2要素です。
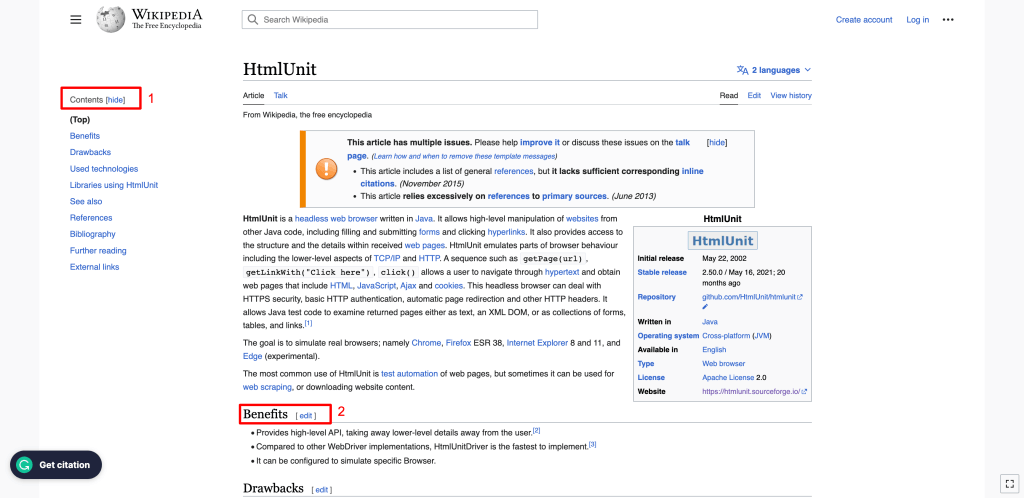
コンテンツボディ内のH2要素のXPathを使用して、すべてのH2を取得できます。XPathを見つけるには、任意のH2要素を右クリックし、「検査」を選択します。次に、ハイライトされた要素を右クリックし、「コピー」 > 「フルXPathをコピー」を選択します。
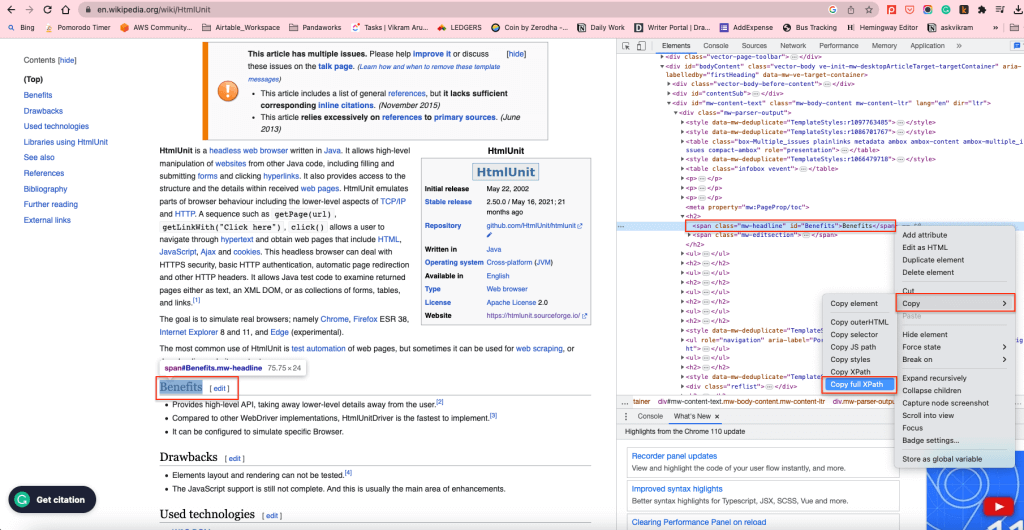
これにより、XPathがクリップボードにコピーされます。例えば、コンテンツボディ内のH2のXPath要素は、/html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/h2です。
XPathを使用してすべてのH2要素を取得するには、getByXpath()メソッドを使用します。
String xPath = u0022/html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/h2u0022;nn String webPageURL = u0022https://en.wikipedia.org/wiki/HtmlUnitu0022;n n try {n HtmlPage page = webClient.getPage(webPageURL);nn //Get all the headings using its XPath+n Listu003cHtmlHeading2u003e h2 = (Listu003cHtmlHeading2u003e)(Object) page.getByXPath(xPath);n n //print the first heading text contentn System.out.println((h2.get(0)).getTextContent());nn } catch (FailingHttpStatusCodeException | IOException e) {n n e.printStackTrace();n n }
最初のH2要素のテキストコンテンツは、次のように出力されます。
Benefits[edit]
同様に、getElementById()メソッドを使用し、IDを介して要素を取得できます。また、getElementByName()メソッドを使用して、その名前から要素を取得できます。
次のセクションでは、これらのメソッドを使用して、動的なウェブページをスクレイピングします。
HtmlUnitを使用して動的なウェブページをスクレイピングする
このセクションでは、ログインフォームに入力して送信するにより、HtmlUnitのフォーム入力とボタンクリックの機能について学びます。また、ヘッドレスブラウザを使ってウェブページをナビゲートする方法についても学びます。
動的なウェブスクレイピングを実証するために、Hacker Newsのウェブサイトを使用しましょう。ログインページは次のようになっています。

次のコードは、前のページのHTMLフォームコードです。このコードは、「ログインラベル」を右クリックしてから、「検査」をクリックして取得できます。
u003cform action=u0022loginu0022 method=u0022postu0022u003enu003cinput type=u0022hiddenu0022 name=u0022gotou0022 value=u0022newsu0022u003enu003ctable border=u00220u0022u003enu003ctbodyu003enu003ctru003eu003ctdu003eusername:u003c/tdu003eu003ctdu003eu003cinput type=u0022textu0022 name=u0022acctu0022 size=u002220u0022 autocorrect=u0022offu0022 spellcheck=u0022falseu0022 autocapitalize=u0022offu0022 autofocus=u0022trueu0022u003eu003c/tdu003eu003c/tru003enu003ctru003eu003ctdu003epassword:u003c/tdu003eu003ctdu003eu003cinput type=u0022passwordu0022 name=u0022pwu0022 size=u002220u0022u003eu003c/tdu003eu003c/tru003eu003c/tbodyu003eu003c/tableu003eu003cbru003enu003cinput type=u0022submitu0022 value=u0022loginu0022u003eu003c/formu003e
HtmlUnitを使ってフォームに入力するには、webClientオブジェクトを使ってウェブページを取得します。このページには、ログインとアカウントの作成という2つのフォームがあります。ログインフォームは、getForms().get(0)メソッドで取得できます。また、フォームに一意の名前がある場合は、getFormByName()メソッドを使用できます。
次に、getInputByName()メソッドとname属性を使用して、フォーム入力(つまりユーザー名とパスワードフィールド)を取得する必要があります。
ユーザー名とパスワードの値を、setValueAttribute()メソッドを使用して入力フィールドに設定し、送信ボタンをgetInputByValue()メソッドを使用して取得します。click()メソッドを使用してボタンをクリックすることもできます。
ボタンがクリックされ、ログインに成功すると、送信ボタンのターゲットページがHTMLPageオブジェクトとして返され、以降の操作に使用できるようになります。
以下のコードは、フォームの取得して、記入し、送信する方法を示しています。
HtmlPage page = null;nnString webPageURl = u0022https://en.wikipedia.org/wiki/HtmlUnitu0022;nn try {n // Get the first pagenn HtmlPage signUpPage = webClient.getPage(webPageURL);nn // Get the form using its index. 0 returns the first form.n HtmlForm form = signUpPage.getForms().get(0);nn //Get the Username and Password field using its namen HtmlTextInput userField = form.getInputByName(u0022acctu0022);n HtmlInput pwField = form.getInputByName(u0022pwu0022);n n //Set the User name and Password in the appropriate fieldsn userField.setValueAttribute(u0022draftdemoacctu0022);n pwField.setValueAttribute(u0022test@12345u0022);nn //Get the submit button using its Valuen HtmlSubmitInput submitButton = form.getInputByValue(u0022loginu0022);nn //Click the submit button, and it'll return the target page of the submit buttonn page = submitButton.click();nnn } catch (FailingHttpStatusCodeException | IOException e) {n e.printStackTrace();n }
フォームが送信され、ログインに成功すると、ユーザーのホームページが表示され、右隅にユーザー名が表示されます。
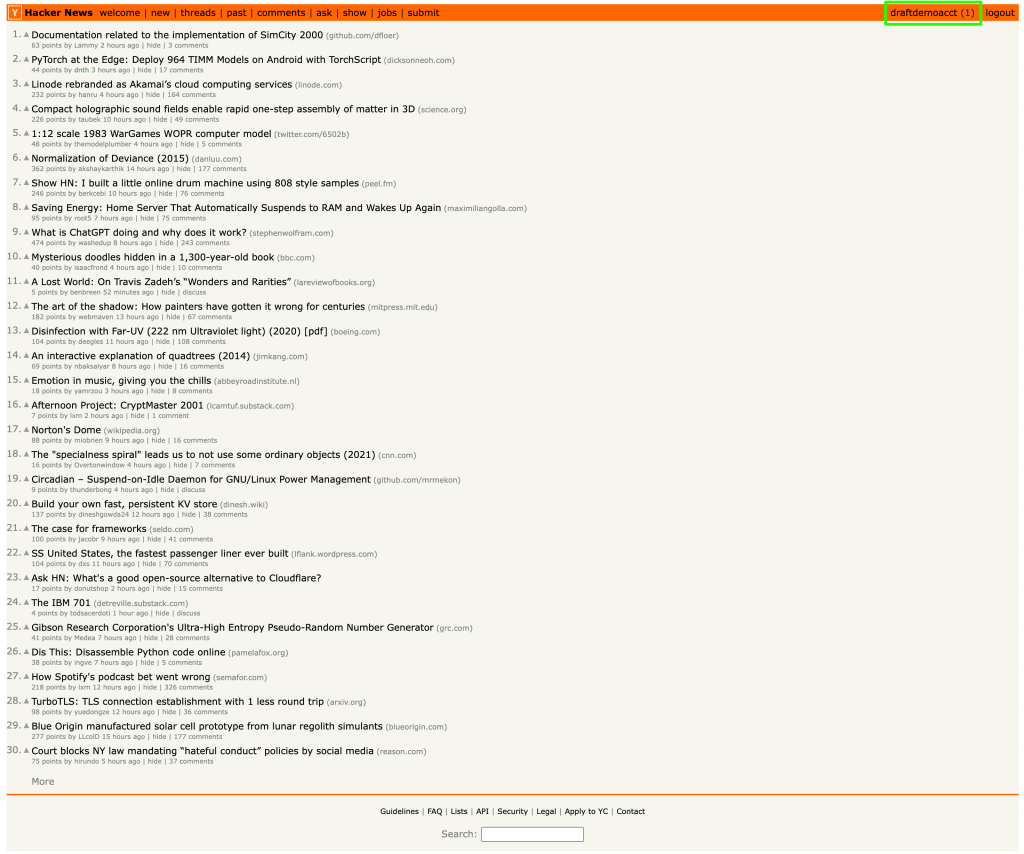
ユーザー名の要素には、ID「me」があります。以下のコードに示すように、getElementById()メソッドを使用してユーザー名を取得し、ID「me」を渡すことができます。
System.out.println(page.getElementById(u0022meu0022).getTextContent());
ユーザー名がウェブページからスクレイピングされ、出力として表示されます。
draftdemoacct
次に、ページの最後にある「その他」ハイパーリンクボタンをクリックして、Hacker Newsサイトの2ページ目に移動する必要があります。

「その他」ボタンオブジェクトを取得するには、「検査」オプションを使用して「その他」ボタンのXPathを取得し、インデックス0を使用して最初のlinkオブジェクトを取得します
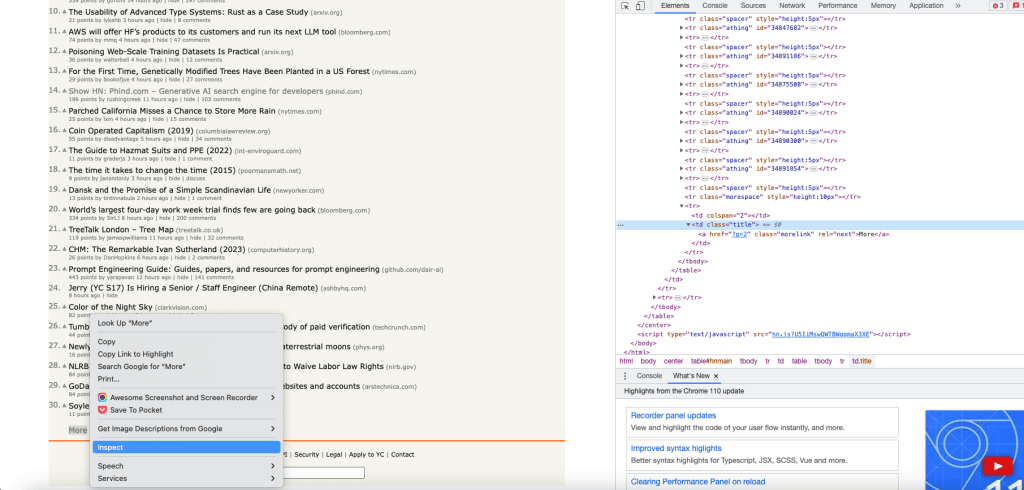
click()メソッドを使用して「その他」リンクをクリックします。linkがクリックされると、リンク先のページがHtmlPageオブジェクトとして返されます。
HtmlPage nextPage = null;nn try {n Listu003cHtmlAnchoru003e links = (Listu003cHtmlAnchoru003e)(Object)page.getByXPath(u0022html/body/center/table/tbody/tr[3]/td/table/tbody/tr[92]/td[2]/au0022);n n HtmlAnchor anchor = links.get(0);n n nextPage = anchor.click();nn } catch (IOException e) {n throw new RuntimeException(e);n }
この時点で、HtmlPageオブジェクトには2ページ目が含まれているはずです。
HtmlPageのURLを出力して、2ページ目が正常に読み込まれたかどうかを確認できます。
System.out.println(nextPage.getUrl().toString());
以下は、2ページ目のURLです。
https://news.ycombinator.com/news?p=2
Hacker Newsサイトの各ページには、30件のエントリがあります。これが、2ページ目のエントリがシリアル番号31から始まる理由です。
2ページ目の最初のエントリのIDを取得し、それが31に等しいかどうかを確認しましょう。前と同様に、
「検査」オプションを使用して、最初のエントリのXPathを取得します。次に、リストから最初のエントリを取得し、そのテキストコンテンツを表示します。
String firstItemId = null;nn Listu003cObjectu003e entries = nextPage.getByXPath(u0022/html/body/center/table/tbody/tr[3]/td/table/tbody/tr[1]/td[1]/spanu0022);nn HtmlSpan span = (HtmlSpan) (entries.get(0));nn firstItemId = span.getTextContent();n n System.out.println(firstItemId);
最初のエントリのIDが表示されるようになりました。
31.
このコードは、HtmlUnitを使用して、フォームへの入力、ボタンのクリック、ウェブページのナビゲーションを行う方法を示しています。
まとめ
この記事では、HtmlUnitを使って静的・動的なウェブサイトをスクレイピングする方法を学びました。また、ウェブページをスクレイピングして構造化データに変換することで、HtmlUnitの高度な機能の一端を知ることができました。
IntelliJ IDEAのようなIDEを使用してこれを行う場合、要素属性を手動で検査して見つけ、要素属性を使ってスクレイピング関数をゼロから記述する必要があります。それに比べて、Bright DataのウェブスクレイパーIDEは、堅牢なブロック解除プロキシインフラストラクチャ、便利なスクレイピング機能、および一般的なウェブサイト用のコードテンプレートを提供します。IPブロックやレート制限の問題なしにウェブページをスクレイピングするには、効率的なプロキシインフラストラクチャが必要です。また、プロキシは、地理的位置の異なるユーザーをエミュレートするのに役立ちます。
Talk to one of Bright Data’s experts and find the right solution for your business.





