

このガイドで、あなたは学ぶだろう:
- Ferretとは何か、そして宣言型Webスクレイピング・ライブラリとして何を提供するか
- Go環境でローカルに使用するための設定方法
- 静的ウェブサイトからデータを収集する方法
- 動的サイトをスクレイピングする方法
- Ferretの主な制限とその回避方法
さあ、飛び込もう!
ウェブスクレイピングのためのFerret入門
実際に使用する前に、Ferretとは何か、どのように機能するのか、何を提供するのか、そしてどのような場合に使用するのかについて調べてみよう。
フェレットとは?
FerretはGoで書かれたオープンソースのウェブスクレイピング・ライブラリだ。Ferretの目標は、宣言的なアプローチを使ってウェブページからのデータ抽出を簡素化することだ。具体的には、独自の宣言型言語であるFerret Query Language(FQL)を使用することで、解析と抽出の技術的な複雑さを抽象化しています。
GitHubで約6kのスターを持つFerretは、Go用の最も人気のあるウェブスクレイピングライブラリの一つです。組み込み可能で、静的、動的なウェブスクレイピングの両方をサポートしています。
FQL:宣言的ウェブスクレイピングのためのFerretクエリー言語
Ferret Query Language(FQL)は、ArangoDBのAQLに大きくインスパイアされた汎用クエリ言語です。FQLはより多くのことができますが、主にウェブページからデータを抽出するために使用されます。
FQLは宣言的なアプローチに従う。つまり、どのようにデータを取得するかよりも、どのデータを取得するかに重点を置く。AQLと同様、SQLと類似している。しかしAQLとは異なり、FQLは厳密に読み取り専用です。どのような形のデータ操作も、特定の組み込み関数を使って行わなければならないことに注意してほしい。
FQL構文、キーワード、構成要素、およびサポートされるデータ型の詳細については、FQLドキュメントのページを参照してください。
使用例
公式GitHubページで強調されているように、Ferretの主な使用例には以下のようなものがある:
- UIテスト:ブラウザのインタラクションをシミュレートし、ページ要素がさまざまなシナリオで正しく動作し、レンダリングされることを検証することで、Webアプリケーションのテストを自動化します。
- 機械学習:ウェブページから構造化データを抽出し、それを使って高品質のデータセットを作成する。そうすれば、機械学習モデルをより効果的にトレーニングまたは検証することができる。機械学習にウェブスクレイピングを使用する方法をご覧ください。
- アナリティクス:価格、レビュー、ユーザーアクティビティなどのウェブデータをスクレイピングして集約し、洞察の生成、トレンドの追跡、ダッシュボードの作成に使用します。
同時に、ウェブスクレイピングの潜在的なユースケースは、これらの例をはるかに超えていることを心に留めておいてください。
フェレットを始める
Ferretがどのようなものかお分かりいただけたと思いますので、実際に静的なウェブページと動的なウェブページの両方でFerretを使用してみましょう。この2つの違いについてよく分からない場合は、ウェブスクレイピングにおける静的コンテンツと動的コンテンツについてのガイドをお読みください。
Ferretをウェブ・スクレイピングに使うための環境を整えよう!
前提条件
ローカルマシンに以下がインストールされていることを確認してください:
- 行く
- ドッカー
Golangがインストールされ、準備ができていることを確認するには、ターミナルで以下のコマンドを実行する:
go versionこのような出力が表示されるはずだ:
go version go1.24.3 windows/amd64エラーが表示されたら、Golangをインストールして、あなたのオペレーティング・システム用に設定してください。
同様に、Dockerがインストールされ、システム用に適切に設定されていることを確認する。
フェレット・プロジェクトを立ち上げる
次に、Ferretウェブスクレイピングプロジェクト用のフォルダを作成し、その中に移動する:
mkdir ferret-web-scraping
cd ferret-web-scrapingお使いのOS用のFerret CLIをダウンロードし、ferret-web-scraping/フォルダに直接解凍します。実行し、動作することを確認する:
./ferret help出力はこうなるはずだ:
Usage:
ferret [flags]
ferret [command]
Available Commands:
browser Manage Ferret browsers
config Manage Ferret configs
exec Execute a FQL script or launch REPL
help Help about any command
update
version Show the CLI version information
Flags:
-h, --help help for ferret
-l, --log-level string Set the logging level ("debug"|"info"|"warn"|"error"|"fatal") (default "info")
Use "ferret [command] --help" for more information about a command.次に、Visual Studio Codeのようなお気に入りのIDEでプロジェクト・フォルダーを開く。プロジェクト・フォルダーの中に、scraper.fqlという名前のファイルを作成する:
ferret-web-scraping/
├── ferret
├── CHANGELOG.md
├── LICENSE
├── README.md
└── scraper.fql # <-- The FQL file for web scraping in Ferretscraper.fqlはウェブスクレイピングのためのFQL宣言ロジックを含みます。
Ferret Dockerセットアップの設定
Ferretのすべての機能を使用するには、ChromeまたはChromiumがローカルにインストールされているか、Docker内で実行されている必要があります。公式ドキュメントでは、Dockerコンテナ内でChrome/Chromiumを実行することを推奨しています。
Chromiumベースのヘッドレスイメージなら何でも使えますが、montferret/chromiumのものを推奨します。これを取得するには
docker pull montferret/chromium次に、このコマンドでDockerイメージを起動する:
docker run -d -p 9222:9222 montferret/chromiumメモ: FQLスクリプトの実行中にブラウザーで何が起こっているかを確認したい場合は、ホストマシンでChromeを起動し、リモートデバッグを有効にしてください:
chrome.exe --remote-debugging-port=9222Ferretで静的サイトをスクレイピングする
Ferretを使って静的なウェブサイトをスクレイピングする方法を学ぶには、以下の手順に従ってください。この例では、対象ページはサンドボックス・サイト “Books to Scrape“です:
目標は、FQLを介したFerretの宣言的アプローチを使って、ページ上の各書籍から重要な情報を抽出することだ。
ステップ #1: ターゲットサイトへの接続
scraper.fqlで、DOCUMENT関数を使ってターゲットページに接続する:
LET doc = DOCUMENT("https://books.toscrape.com/")LETはFQLで変数を定義することができる。この命令の後、docにはターゲット・ページのHTMLが格納される。
ステップ2:すべてのブック要素を選択する
まず、ブラウザでターゲット・ウェブ・ページにアクセスし、それを検査することによって、ターゲット・ウェブ・ページの構造に慣れ親しんでください。詳しくは、ブックエレメントを右クリックし、”Inspect “オプションを選択してDevToolsを開いてください:
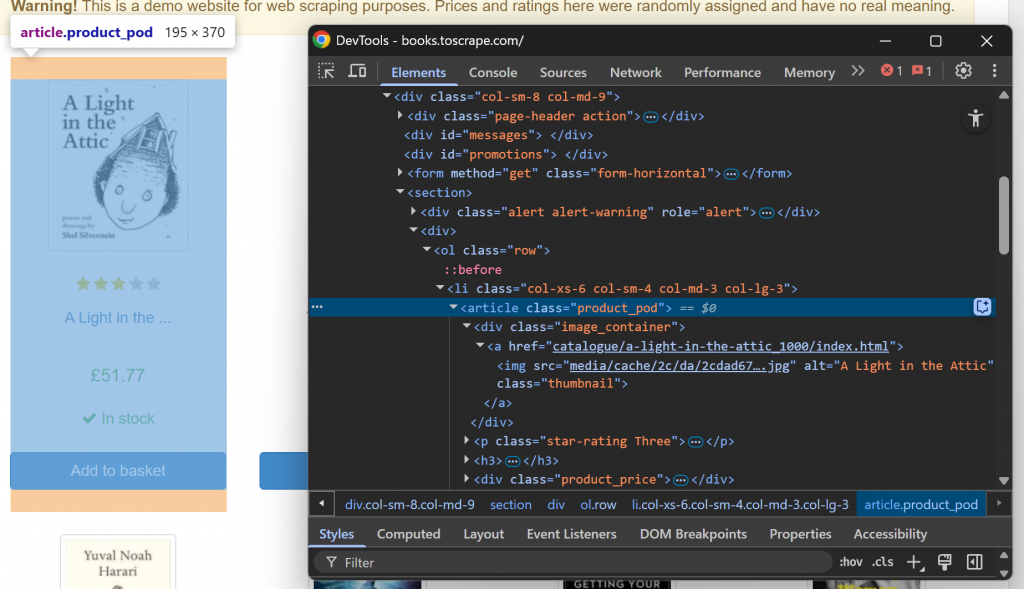
各ブック要素は
.ELEMENTS()関数ですべてのbooks要素を選択します:
LET book_elements = ELEMENTS(doc, "section article")ELEMENTS()は、第2引数として渡されたCSSセレクタをドキュメントに適用します。つまり、ページ上の必要な HTML 要素を選択します。
選択した要素のリストを繰り返し、スクレイピングロジックを適用する準備をする:
FOR book_element IN book_elements
// book scraping logic...驚いた!各書籍要素を繰り返し、それぞれからデータを抽出する時間だ。
ステップ #3: 各見積もりからデータを抽出する
では、HTMLのbook要素をひとつ調べてみよう:
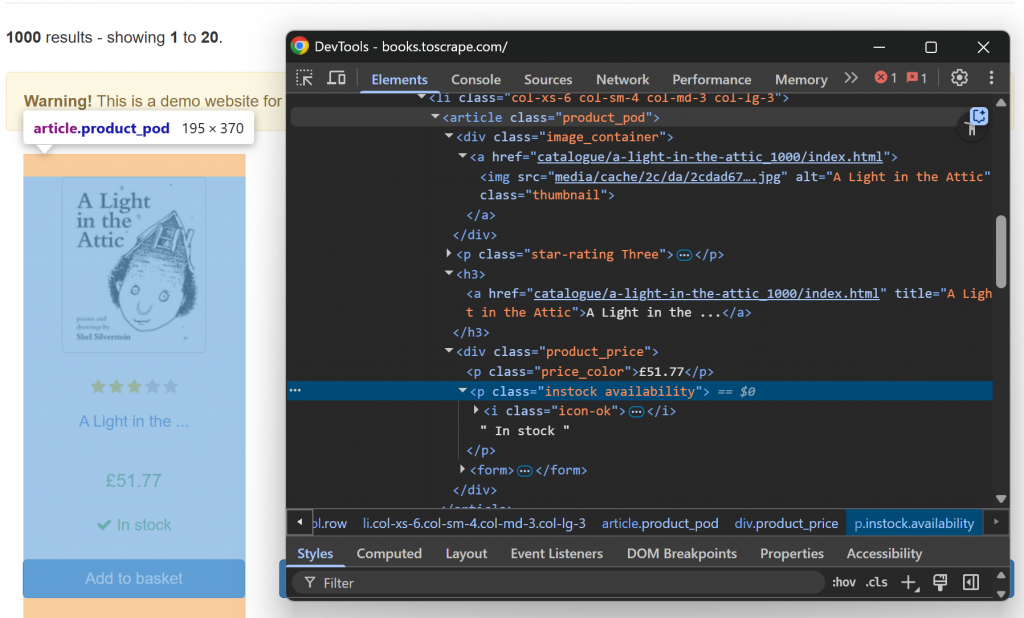
なお、削ることはできる:
.image_container img要素のsrc属性にある画像のURL。h3 a要素のtitle属性にある本のタイトル。h3 aノードのhref属性からブックページへのURL。.price_colorのテキストにある書籍価格。.instockのテキストにある在庫情報。
このデータ解析ロジックを実装する:
LET image_element = ELEMENT(book_element, ".image_container img")
LET title_element = ELEMENT(book_element, "h3 a")
LET price_element = ELEMENT(book_element, ".price_color")
LET availability_element = ELEMENT(book_element, ".instock")
RETURN {
image_url: base_url + image_element.attributes.src,
title: base_url+ title_element.attributes.title,
book_url: title_element.attributes.href,
price: TRIM(INNER_TEXT(price_element)),
availability: TRIM(INNER_TEXT(availability_element))
}base_urlは forループの外側で定義された変数です:
LET base_url = "https://books.toscrape.com/"上記のコードでは
ELEMENT()を使用すると、CSSセレクタを使用してページ上の単一の要素を選択することができます。attributesは、ELEMENT()が返すすべてのオブジェクトが持つ特別な属性です。これは、現在の要素の HTML 属性の値を含みます。INNER_TEXT()は、現在の要素に含まれるテキストを返します。TRIM() は、先頭と末尾の空白を除去する。
素晴らしい!スタティック・スクレイピング・ロジック完成。
ステップ4:すべてをまとめる
scraper.fqlファイルは以下のようになるはずだ:
// connect to the target site
LET doc = DOCUMENT("https://books.toscrape.com/")
// select the book HTML elements
LET book_elements = ELEMENTS(doc, "section article")
// the base URL of the target site
LET base_url = "https://books.toscrape.com/"
// iterate over each book element and apply the scraping logic
FOR book_element IN book_elements
// select all info elements
LET image_element = ELEMENT(book_element, ".image_container img")
LET title_element = ELEMENT(book_element, "h3 a")
LET price_element = ELEMENT(book_element, ".price_color")
LET availability_element = ELEMENT(book_element, ".instock")
// scrape the data of interest
RETURN {
image_url: base_url + image_element.attributes.src,
title: base_url+ title_element.attributes.title,
book_url: title_element.attributes.href,
price: TRIM(INNER_TEXT(price_element)),
availability: TRIM(INNER_TEXT(availability_element))
}ご覧の通り、スクレイピングのロジックは、どのように抽出するかよりも、どのデータを抽出するかに重点を置いている。これがFerretを使った宣言的ウェブスクレイピングの威力だ!
ステップ #5: FQLスクリプトの実行
でFerretスクリプトを実行する:
./ferret exec scraper.fqlターミナルでは、次のように出力される:
[{"availability":"In stock","book_url":"catalogue/a-light-in-the-attic_1000/index.html","image_url":"https://books.toscrape.com/media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg","price":"£51.77","title":"https://books.toscrape.com/A Light in the Attic"},{"availability":"In stock","book_url":"catalogue/tipping-the-velvet_999/index.html","image_url":"https://books.toscrape.com/media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg","price":"£53.74","title":"https://books.toscrape.com/Tipping the Velvet"},
// omitted for brevity...
,{"availability":"In stock","book_url":"catalogue/its-only-the-himalayas_981/index.html","image_url":"https://books.toscrape.com/media/cache/27/a5/27a53d0bb95bdd88288eaf66c9230d7e.jpg","price":"£45.17","title":"https://books.toscrape.com/It's Only the Himalayas"}]これは、ウェブページから収集されたすべてのブックデータを含むJSON文字列です。データ解析の非宣言的なアプローチについては、Goを使ったウェブスクレイピングのガイドをご覧ください。
ミッションは達成された!
Ferretで動的サイトをスクレイピングする
FerretはJavaScriptの実行を必要とする動的なウェブサイトのスクレイピングもサポートしています。このセクションでは、“Quotes to Scrape “サイトのJavaScript遅延バージョンを対象とする:

このページでは、JavaScriptを使って、短い遅延の後に動的に引用要素をDOMに挿入している。このシナリオではJavaScriptを実行する必要があるため、ブラウザでページをレンダリングする必要がある。(以前Chromium Dockerコンテナをセットアップしたのもそのためだ)。
Ferretを使用して動的なウェブページを処理する方法については、以下の手順に従ってください!
ステップ #1: ブラウザでターゲットページに接続する
ヘッドレス・ブラウザでターゲット・ページに接続するには、以下の行を使用する:
LET doc = DOCUMENT("https://quotes.toscrape.com/js-delayed/?delay=2000", {
driver: "cdp"
})DOCUMENT()関数でdriverフィールドを使用していることに注目してほしい。これは、Docker経由で設定されたヘッドレスChroumiumインスタンスでページをレンダリングするようにFerretに指示するものです。
ステップ2:ターゲットとなる要素がページ上に表示されるのを待つ
ブラウザで対象ページにアクセスし、引用要素がロードされるのを待ち、そのうちの1つを検査する:
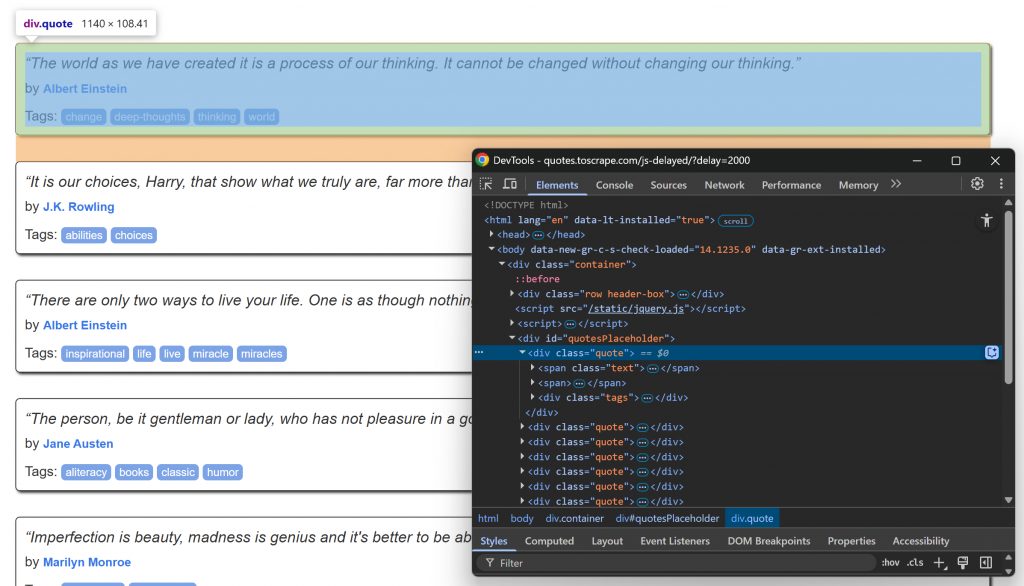
.quoteのCSSセレクタを使って引用要素を選択できることに注目してください。これらの引用要素は、少し遅れてJavaScriptでレンダリングされるので、それを待つ必要があります。
FerretのWAIT_ELEMENT()関数を使用して、引用要素がページに表示されるのを待ちます:
// wait up to 5 seconds for the quote elements to be on the page
WAIT_ELEMENT(doc, ".quote", 5000)これは、コンテンツのレンダリングにJavaScriptを使用している動的なウェブページをスクレイピングする際に不可欠な構造である。
ステップ3:スクレイピング・ロジックの適用
次に、.quoteノード内のinfo要素のHTML構造に注目してください:
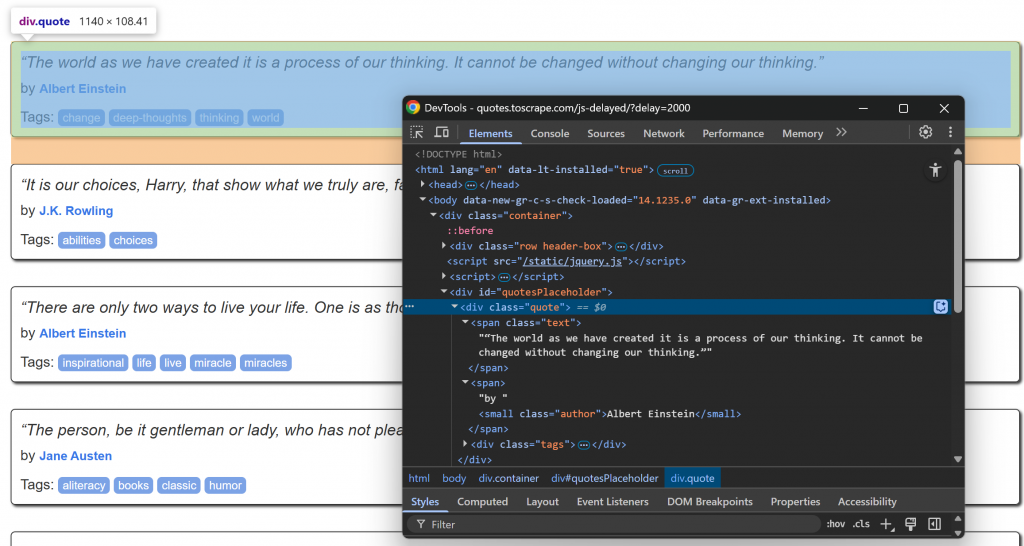
なお、削ることはできる:
.quoteからの引用テキスト.authorの作者
Ferretのウェブスクレイピングロジックを実装する:
// select the quote HTML elements
LET quote_elements = ELEMENTS(doc, ".quote")
// iterate over each quote element and apply the scraping logic
FOR quote_element IN quote_elements
// select all info elements
LET text_element = ELEMENT(quote_element, ".text")
LET author_element = ELEMENT(quote_element, ".author")
// scrape the data of interest
RETURN {
quote: TRIM(INNER_TEXT(text_element)),
author: TRIM(INNER_TEXT(author_element))
} すごい!解析ロジック完了。
ステップ4:すべてを組み立てる
scraper.fqlファイルには以下の内容が含まれていなければならない:
// connect to the target site via the Chromium headless instance
LET doc = DOCUMENT("https://quotes.toscrape.com/js-delayed/?delay=2000", {
driver: "cdp"
})
// wait up to 5 seconds for the quote elements to be on the page
WAIT_ELEMENT(doc, ".quote", 5000)
// select the quote HTML elements
LET quote_elements = ELEMENTS(doc, ".quote")
// iterate over each quote element and apply the scraping logic
FOR quote_element IN quote_elements
// select all info elements
LET text_element = ELEMENT(quote_element, ".text")
LET author_element = ELEMENT(quote_element, ".author")
// scrape the data of interest
RETURN {
quote: TRIM(INNER_TEXT(text_element)),
author: TRIM(INNER_TEXT(author_element))
}見ての通り、これは静的サイトのスクリプトと大差ない。繰り返しになるが、Ferretはウェブ・スクレイピングに宣言的アプローチを採用しているからだ。
ステップ #5: FQLコードを実行する
でFerretスクレイピングスクリプトを実行する:
./ferret exec scraper.fql今回の結果はこうなるだろう:
[{"author":"Albert Einstein","quote":"“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”"},{"author":"J.K. Rowling","quote":"“It is our choices, Harry, that show what we truly are, far more than our abilities.”"},{"author":"Albert Einstein","quote":"“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”"},{"author":"Jane Austen","quote":"“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”"},{"author":"Marilyn Monroe","quote":"“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”"},{"author":"Albert Einstein","quote":"“Try not to become a man of success. Rather become a man of value.”"},{"author":"André Gide","quote":"“It is better to be hated for what you are than to be loved for what you are not.”"},{"author":"Thomas A. Edison","quote":"“I have not failed. I've just found 10,000 ways that won't work.”"},{"author":"Eleanor Roosevelt","quote":"“A woman is like a tea bag; you never know how strong it is until it's in hot water.”"},{"author":"Steve Martin","quote":"“A day without sunshine is like, you know, night.”"}]出来上がり!これがJavaScriptでレンダリングされたページから取得された構造化コンテンツだ。
Ferret宣言的ウェブ・スクレイピング・アプローチの限界
Ferretは間違いなく強力なツールであり、ウェブスクレイピングに宣言的なアプローチをとる数少ないツールのひとつだ。しかし、少なくとも3つの大きな欠点がある:
- 貧弱なドキュメントと頻繁でないアップデート:公式ドキュメントには役に立つ文章が含まれているが、包括的なAPIリファレンスがない。そのため、複雑なスクリプトを作成するのは難しい。さらに、このプロジェクトは定期的な更新を受けていないため、最新のスクレイピング技術に遅れをとっている可能性がある。
- アンチスクレイピング・バイパスをサポートしていません:Ferretは、CAPTCHA、レート制限、その他の高度なアンチスクレイピング防御を処理するメカニズムを内蔵していません。そのため、より保護されたサイトのスクレイピングには不向きです。
- 限られた表現力:Ferret Query LanguageであるFQはまだ開発中であり、PlaywrightやPuppeteerのような最新のスクレイピング・ツールのような柔軟性や制御性はない。
これらの制限は、単純な統合では簡単に対処できない。また、Ferretの中心はウェブデータの検索であることも忘れてはならない。ですから、解決策としては、より堅牢な代替手段を検討することです。
ブライトデータのAIインフラストラクチャには、信頼性の高いインテリジェントなウェブデータ抽出用に調整された高度なサービス群が含まれています。これらにより、あらゆるウェブサイトからデータを大規模に取得することができます。
結論
このチュートリアルでは、Goで宣言的ウェブスクレイピングを行うためのFerretの使い方を学びました。このライブラリを使えば、静的なページからも動的なページからもデータを抽出することができます。
問題は、Ferretにはいくつかの制限があるため、最良のソリューションとは言えないかもしれないということだ。ウェブデータを取得するための、より合理的でスケーラブルな方法をお探しなら、Web Scraper APIの採用を検討してください。
今すぐ無料のBright Dataアカウントにサインアップして、弊社の強力なウェブスクレイピングインフラストラクチャをお試しください!




