

このガイドでは、次のように説明する:
- JavaScriptを多用するサイトとは?
- ブラウザ・レンダリングによるスクレイピングの課題と方法。
- AJAXコールインターセプトの仕組みとその限界。
- JavaScriptを多用するウェブサイトをスクレイピングするための最新ソリューション。
さあ、飛び込もう!
JavaScriptを多用するウェブサイトとは?
ウェブスクレイピングの領域では、収集するデータがサーバーから返される最初のHTMLドキュメントにない場合、そのサイトは「JavaScriptを多用」している。その代わりに、実際のコンテンツは動的にフェッチされ、ユーザーのブラウザでJavaScriptによってレンダリングされる。
サイトがどのようにJavaScriptを使用しているかは、そのデータを抽出するためにどのように進める必要があるかに直接影響します。一般的に、JavaScriptを使ったサイトは主に以下の3つのパターンに従っている:
- シングル・ページ・アプリケーション(SPA):SPAは、サーバーからの新しいコンテンツで特定のセクションを更新するJavaScriptに依存する1つのウェブページです。言い換えれば、ウェブアプリケーション全体は、ユーザーとのインタラクションのたびに再読み込みされない単一のウェブページです。
- ユーザー主導のインタラクション:特定のアクションを行った後にのみコンテンツが表示される。例えば、”load more “ボタンや動的なページネーションなどです。
- 非同期データ:多くのサイトでは、スピードのためにまず基本的なページレイアウトをロードし、次にAJAXを使ってバックグラウンドコールを行い、データを取得する。この仕組みは、ページをリロードせずに株価を更新するようなライブアップデートによく使われる。
フルブラウザ・レンダリングによるJavaScriptを多用するサイトのスクレイピング
ブラウザ自動化ツールを使えば、ウェブブラウザを起動し制御するスクリプトを書くことができる。これにより、ページを完全にレンダリングするために必要なJavaScriptを実行することができる。その後、これらのツールが提供するHTML要素の選択とデータ抽出APIを使用して、必要なデータを引き出すことができます。
これはJavaScriptを多用するサイトをスクレイピングするための基本的なアプローチであり、ここでは以下のセクションでそれを紹介する:
- 自動化ツールの仕組み
- ヘッドレスモードと “ヘッドフル “モードとは何か。
- このアプローチの課題と解決策
- 最も使用されているブラウザ自動化ツール。
自動化ツールの仕組み
ブラウザ自動化ツールは、プロトコル(CDPやBiDiなど)を使ってブラウザに直接コマンドを送ることで動作する。簡単に言えば、「このURLに移動する」「この要素を見つける」「このボタンをクリックする」といったコマンドを発行するための完全なAPIを公開する。
ブラウザはページ上でこれらのコマンドを実行し、スクレイピングスクリプトに記述されたインタラクションに必要なJavaScriptを実行する。ブラウザ自動化ツールは、レンダリングされたDOM(Document Object Model)にもアクセスできる。そこでスクレイピングするデータを見つけることができる。
ヘッドレス・ブラウザと “ヘッドフル “ブラウザ
ブラウザを自動化する場合、その実行方法を決める必要がある。通常、2つのモードから選択する:
- ヘッドフル:ブラウザーは、人間のユーザーが開いたときと同じように、完全なグラフィカル・インターフェースで起動します。ブラウザー・ウィンドウを画面に表示し、スクリプトがクリック、タイプ、ナビゲートする様子をリアルタイムで見ることができます。これは、スクリプトが期待どおりに動作することを視覚的に確認するのに便利です。また、ボット対策システムに対して、自動化を実際のユーザーの動きに近づけることもできる。一方、GUIでブラウザを実行すると、リソースを大量に消費するため(私たちは皆、ブラウザがいかにメモリを消費するか知っている)、ウェブスクレイピングが遅くなる。
- ヘッドレス:ブラウザはバックグラウンドで実行され、インターフェイスは表示されません。システムリソースの消費が少なく、より高速に動作する。これは本番用スクレイパーの標準であり、特にサーバー上で何百もの並列インスタンスを実行する場合に適している。欠点としては、注意深く設定しないと、GUIなしのブラウザは不審に思われるかもしれない。市場で最高のヘッドレス・ブラウザを見つけよう。
ブラウザレンダリングの課題と解決策
ブラウザの自動化は、JavaScriptを多用するウェブサイトを扱う際の第一歩に過ぎない。このようなサイトをスクレイピングする場合、必然的に以下のような2つの大きな課題に直面することになる:
- 複雑なナビゲーション:スクレイピング・スクリプトは、単なるコマンド・フォロワーであってはならない。ユーザージャーニー全体を処理できるようにプログラムする必要がある。つまり、新しいコンテンツの読み込み待ちや無限スクロールへの対応など、複雑なナビゲーションフローをスクレイピングするためのコードを書くということだ。JavaScriptを多用するサイトのスクレイピングには、複数ページのフォームやドロップダウンメニューなどの処理も含まれます。
- アンチボットシステムの回避適切に適用されていない場合、ブラウザの自動化は、アンチボットシステムが検出することができる赤旗です。ブラウザ自動化ツールを使ったスクレイピングシナリオで成功するためには、スクレイパーは、以下のような課題に対処することで、どうにかして人間に見えるようにしなければなりません:
- ブラウザのフィンガープリンティング:アンチボットは、クライアントのブラウザから何百ものデータポイントを分析し、ユニークなシグネチャを作成します。これには、ユーザーエージェント文字列、画面解像度、インストールされているフォント、WebGLレンダリング機能などが含まれます。明らかに、デフォルトの自動化設定は簡単に識別可能です。ヘッドレスでないUser-Agentを設定することは素晴らしいヒントです。また、undetected-chromedriverのような特殊なツールが必要になるかもしれない。
- 行動分析:ボット対策は、スクレイパーがどのようにページとやりとりするかも観察する。ページがロードされてから5ミリ秒後にボタンをクリックするスクリプトは、明らかに人間ではない。その挙動がロボット的と判断されれば、防御システムはあなたを禁止することができる。
- CAPTCHA:CAPTCHAは、ブラウザの自動化に基づくスクレイピング手法にとって、しばしば究極の障害となる。標準的な自動化スクリプトでは自律的に解決できないからだ。これを克服するには、CAPTCHA解決サービスを統合する必要がある。
詳しくは、動的サイトのスクレイピングに関するガイドをご覧ください。
トップブラウザ自動化フレームワーク
ブラウザ自動化のための3つの主要なフレームワークがある:
- Playwright:マイクロソフトのモダンなフレームワーク。現代の複雑なサイトを扱うために一から設計されている。そのため、新しいスクレイピング・プロジェクトに最適である。JavaScript、Python、C#、Javaで利用可能で、コミュニティによる追加言語サポートもある。このため、Playwrightを使ったウェブスクレイピングはほとんどの開発者にとって良い選択となる。
- Selenium:ウェブ自動化のオープンソースの巨人である。その最大の強みは汎用性にある。特に、ほぼすべてのプログラミング言語とブラウザをサポートし、幅広く成熟したエコシステムを持っています。そのため、Seleniumはスクレイピングのためのブラウザ自動化ツールとして主に使われている。
- Puppeteer:Googleが開発したライブラリで、CDP(Chrome DevTools Protocol)を介してChromeやChromiumベースのブラウザをきめ細かく制御できる。現在はFirefoxもサポートしている。このライブラリを使えば、制御されたブラウザでユーザーの行動をシミュレートすることで、一般ユーザーのように見せることができる。そのため、Puppeteerはウェブスクレイピングに広く利用されています。
これらのソリューション(およびその他のソリューション)の比較については、最高のブラウザ自動化ツールについてのリポジトリをご覧ください。
代替方法AJAXコールの複製
ブラウザで視覚的なウェブページ全体をレンダリングするコストを負担する代わりに、探偵的なアプローチを取ることができる。代わりにできることは、ウェブサイトのフロントエンドがバックエンドに行う直接的なAPIコールを特定し、それを自分で再現することだ。
これらのAPIコールは通常、サイトが後でページにレンダリングする生データを返すので、それらを直接ターゲットにすることができる。このテクニックはAJAXコールを模倣することに依存しており、一般的にAPIウェブスクレイピングとして知られている。
どう動くか見てみよう!
AJAXコールレプリケーションの仕組み
AJAXレプリケーションは、実用的なスクレイピング技術である。コアとなるアイデアは、ウェブアプリケーションがバックエンドからデータをフェッチするために行うネットワークリクエスト(通常はAJAXコール)を模倣することで、ページ全体のレンダリングを回避することである。
高いレベルでは、これには主に2つのステップがある:
- 盗み見る:ブラウザの開発者ツール(通常は「ネットワーク」タブで「Fetch/XHR」フィルターを有効にする)を開き、ウェブサイトとやりとりする。新しいデータがロードされたとき、バックグラウンドでどのAPIコールが行われるかを観察する。例えば、無限スクロール中や、”Load more “ボタンをクリックした時など。
- リプレイする:正しいAPIリクエストを特定したら、そのURL、HTTPメソッド(GET、POSTなど)、ヘッダー、ペイロード(あれば)を記録する。次に、PythonのRequestsのようなHTTPクライアントを使用して、スクレイピングスクリプトでこのリクエストを複製する。
これらのAPIエンドポイントは通常、構造化されたフォーマット、多くの場合JSONでデータを返す。HTMLを解析する余分な手間をかけずにJSONデータにアクセスできるので、これは大きな利点だ。
例えば、より多くのデータを読み込むために無限スクロールを使用するサイトが行うAPIコールを見てみよう:
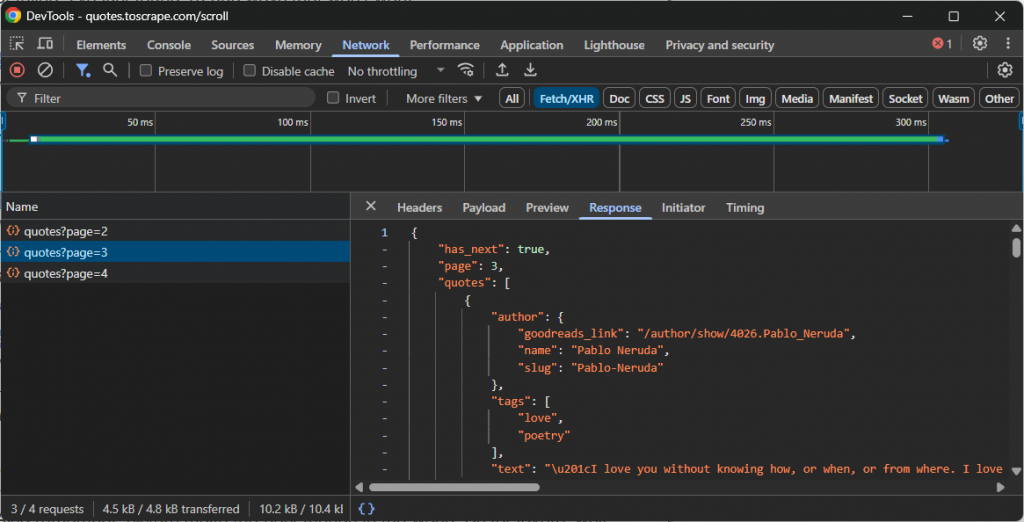
この場合、上記の無限スクロールAPIコールを再現し、データにアクセスする簡単なスクレイピング・スクリプトを書くことができる。
AJAXコールをインターセプトする際の主な課題
うまくいけば、この方法は速く、効果的で、シンプルだ。しかし、いくつかの課題もある:
- 難読化されたペイロード:APIは暗号化されたペイロードを要求するかもしれないし、クリーンで読みやすいJSONを返さないかもしれない。特定のJavaScript関数がデコード方法を知っている暗号化された文字列かもしれない。これはリバースエンジニアリングを必要とするスクレイピング対策である。
- 動的なエンドポイントとヘッダー:APIエンドポイントとその呼び出し方(適切なヘッダーの設定、適切なペイロードの追加など)は時間とともに変化する。このソリューションの主な課題は、APIが進化するとスクレーパーが壊れてしまうことだ。これは機能を復元するためにコードのメンテナンスが必要で、ほとんどの(これから見るようにすべてではないが)ウェブスクレイピング・アプローチに共通する問題である。
- TLSフィンガープリンティング:最先端のアンチボットは、プログラムのデジタル署名である「TLSハンドシェイク」を分析する。Chromeからのリクエストと標準的なPythonスクリプトからのリクエストを簡単に見分けることができる。これを回避するには、ブラウザのTLSシグネチャを偽装できる特別なツールが必要です。
JavaScriptを多用するサイトのスクレイピングへの最新アプローチ:AIを搭載したブラウザ・スクレイピング・エージェント
これまで説明してきた方法は、依然として大きな課題に直面している。JavaScriptを多用するサイトをスクレイピングするための、より現代的なソリューションには、パラダイムシフトが必要だ。命令型のコマンドを書くことから、AI駆動型のブラウザ・エージェントを使った宣言型のゴールを定義することに移行することだ。
エージェントブラウザは、ページのコンテンツ、コンテキスト、ビジュアルレイアウトを理解するLLMと統合されたブラウザである。これは、ウェブスクレイピング、特にJavaScriptを多用するウェブサイトへのアプローチ方法を根本的に変える。
そのようなサイトでは通常、必要なデータをロードするために複雑なユーザーインタラクションが必要になります。従来であれば、スクリプトにそれらのインタラクションを複製するロジックを注入しなければなりませんでした。このアプローチは、本質的にもろく、メンテナンスに手間がかかります。問題は、ユーザーフローが変更されるたびに、自動化ロジックを手動で更新する必要があることです。
AIを搭載したブラウザエージェントのおかげで、そのような事態を避けることができます。シンプルな説明プロンプトを表示するだけで、サイトのUIやフローが変わっても適応する効果的な自動化を推進することができます。この柔軟性は大きな利点であり、他の多くの自動化の可能性への扉を開くものである。
さて、あなたのAIブラウザ・エージェント・ライブラリがどれほど強力であっても、あなたのスクレイピング・ロジックは依然として通常のブラウザに依存しています。これは、ブラウザのフィンガープリンティングやCAPTCHAのような問題に対して脆弱であることを意味します。また、このようなソリューションのスケーリングは、レート制限やIP禁止により困難になります。
真の解決策は、あらゆるエージェントライブラリと統合し、ブロックされないように設計された、クラウドベースのAI対応スクレイピングプラットフォームです。これこそが、ブライト・データのエージェント・ブラウザが提供するものです。
Agent Browserは、ブロックされることのないリモートブラウザ上でAI主導のワークフローを実行することができます。無限に拡張可能で、ヘッドレスモードとヘッドフルモードの両方をサポートし、世界で最も信頼性の高いプロキシネットワークを搭載しています。
結論
この記事では、JavaScriptを多用するWebサイトとは何か、そして、それらからデータをスクレイピングするための一般的な課題と解決策を学びました。説明されたそれぞれの実装には制限が伴いますが、輝くものはエージェントブラウザを使用することです。
説明したように、Bright Dataのエージェントブラウザは、最も一般的なエージェントAIライブラリと統合しながら、一般的なスクレイピングの問題をすべて解決することができます。
高度なAIスクレイピングエージェントを使用する場合、ウェブコンテンツを取得、検証、変換する信頼性の高いツールが必要です。ブライトデータのAIインフラストラクチャをぜひお試しください。
ブライトデータのアカウントを作成し、AIエージェント開発のためのすべての製品とサービスをお試しください!





