

Pinterestからのデータ抽出は、一般的なHTMLスクレイピングとは異なります。Pinterestはすべてのコンテンツを動的に生成し、JSONのようなデータ構造をページに残しません。
以下の方法でPinterestのデータを収集する方法を学ぶことができます:
- PlaywrightでPinterestのデータを抽出
- Bright DataのスクレイパーAPIでPinterestのデータを抽出する
何を抽出できるか?
ブラウザでPinterestを見ると、すべてのピンはdata-test-id="pinWrapper "のdiv要素の中に深くネストされています。
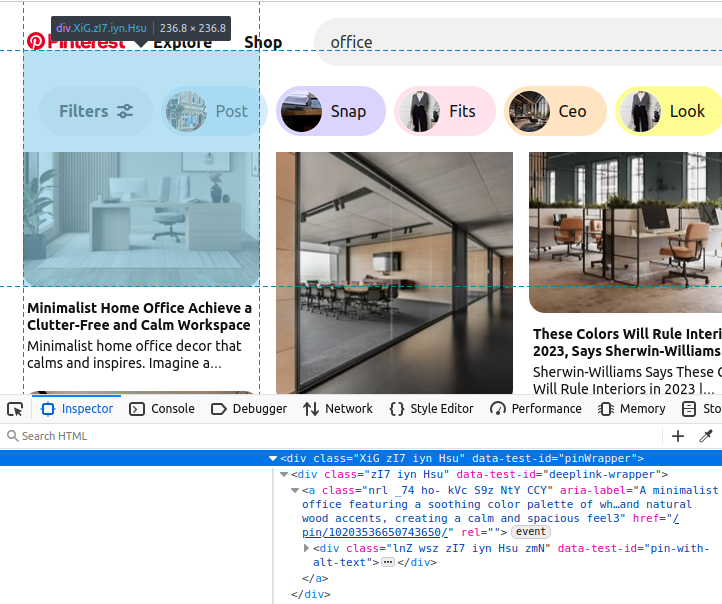
ページ上のこれらのオブジェクトをすべて見つけることができれば、次のようなデータをすべて抽出することができる:
- 各ピンのタイトル。
- ピンを直接指すURL。
- 検索結果のピンの画像。
劇作家とPinterestをスクラップする
はじめに
Pythonには素晴らしいスクレイピング・ライブラリがたくさんあるが、今回はPlaywrightを使ってみよう。まず、Playwrightがインストールされていることを確認する必要がある。Playwrightのドキュメントはここで見ることができる。Playwrightは最高のヘッドレスブラウザの一つです。
劇作家のインストール
pip install playwright
プレイライト・ブラウザのインストール
playwright install
実際のピンを削る
それでは、Pinterestから実際のピンをスクレイピングする方法を見てみましょう。以下のコードでは、scrape_pins()とmain ()の2つの関数を作成しています。scrape_pins()はブラウザを開き、Pinterestからデータを抽出します。
import asyncio
from playwright.async_api import async_playwright
import json
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36"
async def scrape_pins(query):
search_url = f"https://www.pinterest.com/search/pins/?q={query}&rs=typed"
scraped_data = []
async with async_playwright() as p:
browser = await p.chromium.launch()
page = await browser.new_page(user_agent=user_agent)
response = await page.goto(search_url)
await asyncio.sleep(2)
try:
#find the pins on the page
pins = await page.query_selector_all("div[data-test-id='pinWrapper']")
#iterate through the pins and extract data
for pin in pins:
title_link = await pin.query_selector("a")
pin_url = await title_link.get_attribute("href")
title = await title_link.get_attribute("aria-label")
img = await title_link.query_selector("img")
img_src = await img.get_attribute("src")
extracted_data = {
"title": title,
"url": pin_url,
"img": img_src
}
#add the data to our results
scraped_data.append(extracted_data)
except:
print(f"Failed to scrape pins at {search_url}")
finally:
await browser.close()
#everything has finished, return our scraped data
return scraped_data
async def main():
search_query = "office"
office_results = await scrape_pins(search_query)
with open(f"{search_query}-results.json", "w") as file:
try:
json.dump(office_results, file, indent=4)
except Exception as e:
print(f"Failed to save results: {e}")
if __name__ == "__main__":
asyncio.run(main())
scrape_pins()はスクレイピング中に以下のステップを実行する:
search_urlを作成する。- 結果を格納する配列を
作成します。 - 新しいブラウザのインスタンスを開く。
- ヘッドレスモードで実行するには、カスタム
user_agentを設定してください。これがないとPinterestにブロックされます。 asyncio.sleep(2)でコンテンツのロードを2秒待つ。div[data-test-id='pinWrapper']というセレクタを使用して、ページ上のすべての可視ピンを見つけます。- 各ピンについて、以下のデータを抽出する:
タイトル:ピンのタイトル。url:ピンに直接つながるURL。img:検索結果に表示されるピンの画像。
上のPlaywrightスクレイパーからのサンプルデータです。
[
{
"title": "A minimalist office featuring a soothing color palette of whites, greys, and natural wood accents, creating a calm and spacious feel3",
"url": "/pin/10203536650743650/",
"img": "https://i.pinimg.com/236x/b3/21/e2/b321e2485da40c0dde2685c3a4fdcb56.jpg"
},
{
"title": "a home office with two desks and an open door that leads to the outside",
"url": "/pin/261912534574291013/",
"img": "https://i.pinimg.com/236x/56/f1/29/56f129512885e1b3c9971b16f9445c9a.jpg"
},
{
"title": "home office decor, blakc home office, dark home office, moody home office, small home office",
"url": "/pin/60094976273327121/",
"img": "https://i.pinimg.com/236x/ba/75/c9/ba75c9be7e635cce3ee80acdf70d6f9f.jpg"
},
{
"title": "an office with a desk, chair and bookshelf in the middle of it",
"url": "/pin/599682506666665720/",
"img": "https://i.pinimg.com/236x/57/66/1d/57661dc80bebda3dfe946c070ee8ed13.jpg"
},
{
"title": "a home office with green walls and plants on the shelves, along with a computer desk",
"url": "/pin/1147080967585091410/",
"img": "https://i.pinimg.com/236x/ce/e8/b7/cee8b74151b29605a80e0f61898c249d.jpg"
},
Bright Data Scraper APIでPinterestをスクレイピングする
私たちのPinterest Scraper APIを使えば、このプロセスを完全に自動化することができ、ヘッドレスブラウザやセレクタなどを気にする必要はありません!
Python Requestsがインストールされていることを確認してください。
インストールリクエスト
pip install requests
APIコールをセットアップしたら、Pythonからそれをトリガーできる。以下では、get_pins()とpoll_and_retrieve_snapshot() という2つの関数も用意している。
get_pins():この関数は、api_keyと一緒にキーワードを受け取ります。そして、スクレイパーAPIへのリクエストを作成し送信します。このリクエストは、あなたの希望するキーワードでPinterestのスクレイピングをトリガーします。poll_and_retrieve_snapshot() はapi_keyとsnapshot_idを受け取ります。そして、スナップショットの準備ができたかどうかを10秒ごとにチェックします。スナップショットの準備ができたら、データをダウンロードして関数を終了します。
import requests
import json
import time
#function to trigger the scrape
def get_pins(api_key, keyword):
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lk0sjs4d21kdr7cnlv",
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
}
data = [
{"keyword":keyword},
]
#trigger the scrape
response = requests.post(url, headers=headers, params=params, json=data)
#return the snapshot_id
return response.json()["snapshot_id"]
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file="snapshot-data.json"):
#create the snapshot url
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
#write the snapshot to a new json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
break
elif response.status_code == 202:
print("Snapshot is not ready yet. Retrying in 10 seconds...")
else:
print(f"Error: {response.status_code}")
print(response.text)
break
time.sleep(10)
if __name__ == "__main__":
API_KEY = "YOUR-BRIGHT-DATA-API-KEY"
KEYWORD = "office"
snapshot_id = get_pins(API_KEY, KEYWORD)
poll_and_retrieve_snapshot(API_KEY, snapshot_id)
ダウンロードしたファイルからのサンプルデータです。我々のトリガーリクエストは、"include_errors":「true "であったため、ファイルにはエラーのあるピンも含まれていた。以下のサンプルデータには、2つのエラーピンと2つの正常なデータが含まれています。
[
{
"post_type": null,
"timestamp": "2026-02-17T15:26:17.248Z",
"input": {
"url": "https://www.pinterest.com/pin/jh46IGe2",
"discovery_input": {
"keyword": "office"
}
},
"warning": "Bad input. Wrong id!",
"warning_code": "dead_page",
"discovery_input": {
"keyword": "office"
}
},
{
"post_type": null,
"timestamp": "2026-02-17T15:26:18.757Z",
"input": {
"url": "https://www.pinterest.com/pin/4471026676503806548",
"discovery_input": {
"keyword": "office"
}
},
"warning": "Bad input. Page does not exist.",
"warning_code": "dead_page",
"discovery_input": {
"keyword": "office"
}
},
{
"url": "https://www.pinterest.com/pin/929782285570058239",
"post_id": "929782285570058239",
"title": "Essential Tips for Designing a Functional Small Office Space: Maximize Efficiency",
"content": "17 Smart Tips for Designing a Productive Small Office Space",
"date_posted": "2026-02-06T15:00:47.000Z",
"user_name": "wellnesswink",
"user_url": "https://www.pinterest.com/wellnesswink",
"user_id": "929782422978147260",
"followers": 232,
"likes": 0,
"categories": [
"Explore",
"Home Decor"
],
"attached_files": [
"https://i.pinimg.com/originals/c8/c0/d5/c8c0d5fb45352e40535db4510049a142.jpg"
],
"image_video_url": "https://i.pinimg.com/originals/c8/c0/d5/c8c0d5fb45352e40535db4510049a142.jpg",
"video_length": 0,
"post_type": "image",
"comments_num": 0,
"discovery_input": {
"keyword": "office"
},
"timestamp": "2026-02-17T15:26:19.502Z",
"input": {
"url": "https://www.pinterest.com/pin/929782285570058239",
"discovery_input": {
"keyword": "office"
}
}
},
{
"url": "https://www.pinterest.com/pin/889812838892568569",
"post_id": "889812838892568569",
"title": "20 Modern Masculine Home Office Design Ideas for Men",
"content": "Explore 25 chic home office decor ideas that blend style and functionality. Create a workspace you love and boost your productivity effortlessly!",
"date_posted": "2026-01-27T07:11:38.000Z",
"user_name": "artfullhouses",
"user_url": "https://www.pinterest.com/artfullhouses",
"user_id": "889812976285233957",
"followers": 10,
"likes": 0,
"categories": [
"Explore",
"Home Decor"
],
"attached_files": [
"https://i.pinimg.com/originals/f1/cb/f7/f1cbf7b127db2bef2306ba19ffcc0646.png"
],
"image_video_url": "https://i.pinimg.com/originals/f1/cb/f7/f1cbf7b127db2bef2306ba19ffcc0646.png",
"video_length": 0,
"hashtags": [
"Mens Desk Decor",
"Chic Home Office Decor",
"Mens Desk",
"Home Office Ideas For Men",
"Office Ideas For Men",
"Masculine Home Office Ideas",
"Masculine Home Office",
"Masculine Home",
"Chic Home Office"
],
"post_type": "image",
"comments_num": 0,
"discovery_input": {
"keyword": "office"
},
"timestamp": "2026-02-17T15:26:20.069Z",
"input": {
"url": "https://www.pinterest.com/pin/889812838892568569",
"discovery_input": {
"keyword": "office"
}
}
},
ご覧のように、Scraper APIは、Playwrightで構築した最初のスクレイパーよりもはるかに多くのデータを収集します。私たちのAPIは、あなたのキーワードでPinterestをクロールし、クロール中に見つけた個々のピンをすべてスクレイピングします。
このアプローチの利点は利便性だけではありません。私たちのPinterest Scraper APIは、非常に低コストでデータを抽出します。私たちの結果ファイルの合計は、ほぼ45,000行で、生成にかかったコストはわずか0.97ドルでした。

同じ品質のスクレイパーを構築するために誰かを雇うと、おそらく数百ドルかかり、データを得るために何日も待たなければならないでしょう。私たちのスクレーパーAPIを使えば、ほんのわずかなコストで数分以内にデータを手に入れることができます。
結論
Pinterestからデータを抽出することは難しくありません。Playwrightを使って独自のスクレイパーを構築するにしても、弊社のPinterestスクレイパーのような完全自動化ソリューションを選ぶにしても、適切なアプローチはニーズによって異なります。
ブライトデータのスクレイパーAPIは、迅速で信頼性が高く、スケーラブルなPinterestデータ抽出のために、ヘッドレスブラウザ、プロキシ、CAPTCHAを処理する手間を省き、構造化データを簡単に提供します。
✅迅速な結果 – 数時間ではなく数分でデータを取得
✅費用対効果 – 抽出した分だけを支払う
✅メンテナンス不要 – ブロックされたリクエストへの対応を回避
今すぐ無料トライアルを開始し、Bright DataのWeb Scraper APIでPinterestのスクレイピングを効率化しましょう!





