

このブログ記事で、あなたは学ぶだろう:
- オープンシー・スクレーパーとは
- OpenSeaから自動的に抽出できるデータの種類
- Pythonを使ったOpenSeaスクレイピングスクリプトの作成方法
- より高度なソリューションが必要な場合とその理由
さあ、飛び込もう!
オープンシー・スクレーパーとは?
OpenSeaスクレーパーは、世界最大のNFTマーケットプレイスであるOpenSeaのデータを収集するために設計されたツールです。このツールの主な目的は、様々なNFT関連情報の収集を自動化することです。通常、自動化されたブラウザーソリューションを使用し、手作業を必要とせずにリアルタイムのOpenSeaデータを取得します。
OpenSeaからスクレイピングするデータ
以下は、OpenSeaからスクレイピングできる主要なデータポイントです:
- NFTコレクション名:NFTコレクションのタイトルまたは名前。
- コレクションランク: パフォーマンスに基づくコレクションのランクまたは位置。
- NFT画像:NFTコレクションまたはアイテムに関連する画像。
- フロアプライス:コレクション内のアイテムの最低価格。
- 出来高:NFTコレクションの総取引量。
- 変化率:特定の期間におけるコレクションのパフォーマンスの価格変化または変化率。
- トークンID:コレクション内の各NFTの一意の識別子。
- 最終販売価格:コレクション内のNFTの直近の売却価格。
- 販売履歴:各 NFT アイテムの取引履歴(過去の価格やバイヤーを含む)。
- オファーコレクション内のNFTに対して出された有効なオファー。
- 作成者情報:ユーザー名やプロフィールなど、NFTの作成者に関する詳細。
- 特性/属性:NFTアイテムの具体的な特徴や特性(希少性、色など)。
- アイテムの説明:NFTアイテムの簡単な説明または情報。
OpenSeaのスクレイピング方法:ステップバイステップガイド
このガイドセクションでは、OpenSea スクレイパーの作り方を学びます。目標は、“Gaming “ページの “Top “セクションからNFTコレクションに関するデータを自動的に収集するPythonスクリプトを開発することです:
以下の手順に従って、OpenSeaをスクレイピングする方法をご覧ください!
ステップ1:プロジェクトのセットアップ
始める前に、あなたのマシンにPython 3がインストールされていることを確認してください。そうでなければ、ダウンロードしてインストール手順に従ってください。
以下のコマンドを使用して、プロジェクト用のフォルダを作成します:
mkdir opensea-scraper
opensea-scraperディレクトリは、Python OpenSea スクレイパーのプロジェクトフォルダを表します。
ターミナルでそこに移動し、その中で仮想環境を初期化する:
cd opensea-scraper
python -m venv venv
お気に入りのPython IDEでプロジェクトフォルダを読み込みます。Python拡張機能付きのVisual Studio Codeや PyCharm Community Editionでも構いません。
プロジェクトのフォルダにscraper.pyファイルを作成します:

現在、scraper.pyは空白のPythonスクリプトですが、すぐに目的のスクレイピングロジックを含むようになります。
IDEのターミナルで、仮想環境を有効にします。LinuxまたはmacOSでは、このコマンドを起動する:
./env/bin/activate
同様に、Windowsでは、実行する:
env/Scripts/activate
驚くべきことに、これでウェブスクレイピングのためのPython環境が整った!
ステップ2:スクレイピング・ライブラリの選択
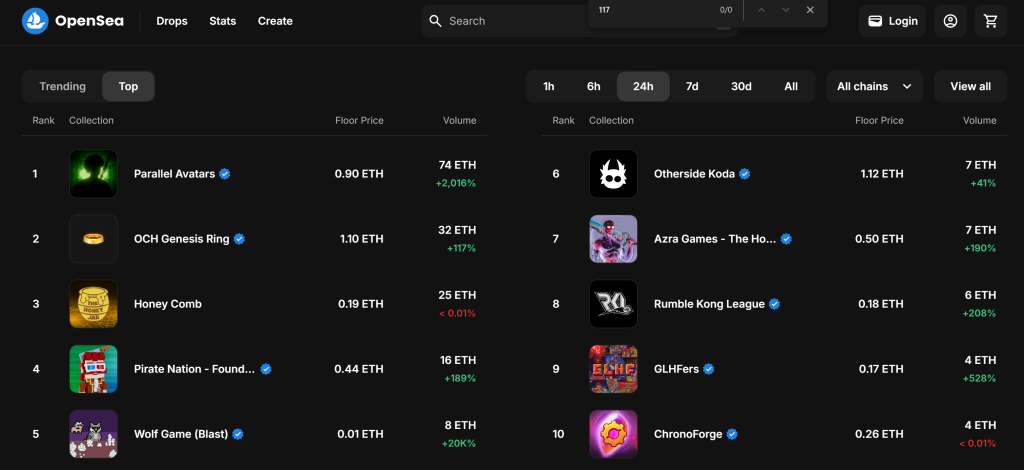
コーディングに入る前に、必要なデータを抽出するための最適なスクレイピング・ツールを決定する必要がある。そのためには、まず予備テストを行い、対象サイトがどのような挙動を示すかを以下のように分析する必要がある:
- 事前に保存されたクッキーや設定が分析に影響しないように、シークレットモードで対象ページを開きます。
- ページ上の任意の場所で右クリックし、”Inspect “を選択してブラウザの開発者ツールを開く。
- ネットワーク」タブに移動する。
- 例えば、”1h “と “6h “のボタンをクリックする。
- Fetch/XHR」タブでアクティビティを監視する。
これにより、ウェブページが動的にデータをロードし、レンダリングしているかどうかを知ることができる:
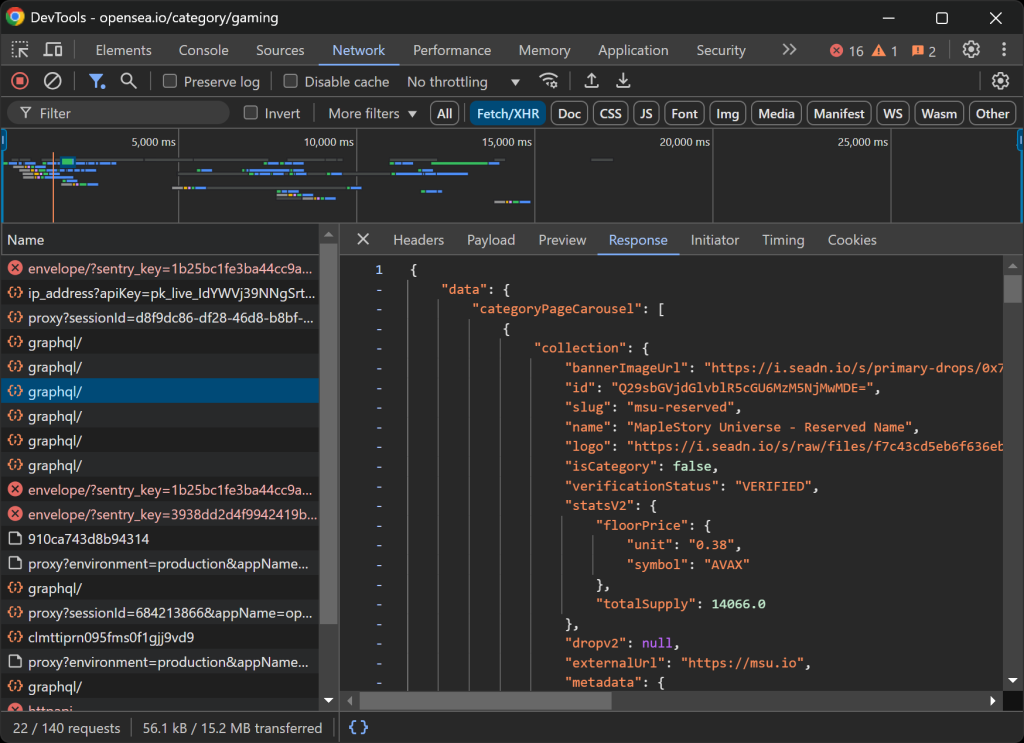
このセクションでは、ページがリアルタイムで行うすべてのAJAXリクエストを見ることができます。これらのリクエストを検査することで、OpenSeaが動的にサーバからデータを取得していることがわかります。加えて、さらなる分析により、いくつかのボタンのインタラクションがJavaScriptのレンダリングをトリガーし、ページのコンテンツを動的に更新していることがわかります。
これは、OpenSeaのスクレイピングにはSeleniumのようなブラウザ自動化ツールが必要であることを示している!
Seleniumを使うと、ウェブブラウザをプログラムで制御し、実際のユーザーインタラクションを真似て効率的にデータを抽出することができる。さあ、インストールして始めましょう。
ステップ #3: Seleniumのインストールとセットアップ
Seleniumはseleniumpipパッケージで入手できます。仮想環境をアクティブにして、以下のコマンドを実行してSeleniumをインストールしてください:
pip install -U selenium
ブラウザ自動化ツールの使い方については、Seleniumを使ったウェブスクレイピングのガイドをお読みください。
scraper.pyでSeleniumをインポートし、Chromeを制御するためのWebDriverオブジェクトを初期化します:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
上のスニペットは、Chromeとやり取りするためのWebDriverインスタンスをセットアップしています。OpenSea は、ヘッドレスブラウザを検出してブロックするスクレイピング対策を採用していることに留意してください。具体的には、サーバは “Access Denied” ページを返します。
つまり、このスクレーパーには--headlessフラグは使えない。別のアプローチとして、Playwright StealthやSeleniumBase を検討してみてください。
OpenSeaはウィンドウの大きさに応じてレイアウトを変更するので、ブラウザのウィンドウを最大化して、デスクトップ版がレンダリングされるようにしてください:
driver.maximize_window()
最後に、必ずWebDriverを適切に終了してリソースを解放してください:
driver.quit()
素晴らしい!これで OpenSea のスクレイピングを開始するための設定は完了です。
ステップ4:ターゲット・ページを訪問する
SeleniumWebDriverの get()メソッドを使って、ブラウザに目的のページを表示させます:
driver.get("https://opensea.io/category/gaming")
あなたのscraper.pyファイルには以下の行が含まれているはずです:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Scraping logic...
# close the browser and release its resources
driver.quit()
スクリプトの最終行にデバッグ用のブレークポイントを置き、実行してください。これが表示されるはずです:
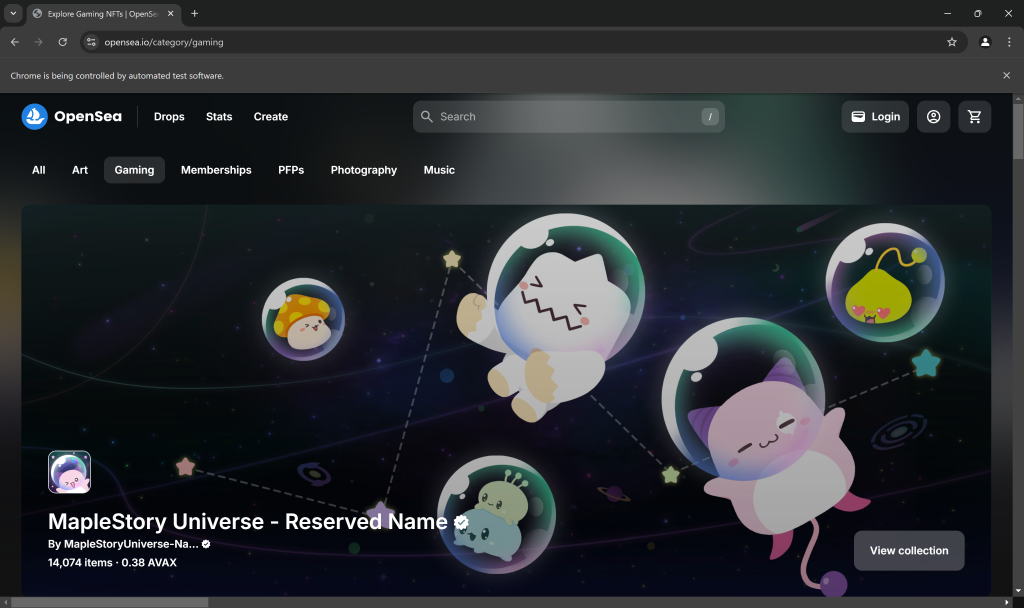
Chromeは自動テストソフトウェアによって制御されています。”というメッセージは、Seleniumが期待通りにChromeを制御していることを証明しています。よくできました!
ステップ#5:ウェブページと対話する
デフォルトでは、”Gaming “ページには “Trending “NFTコレクションが表示されます:
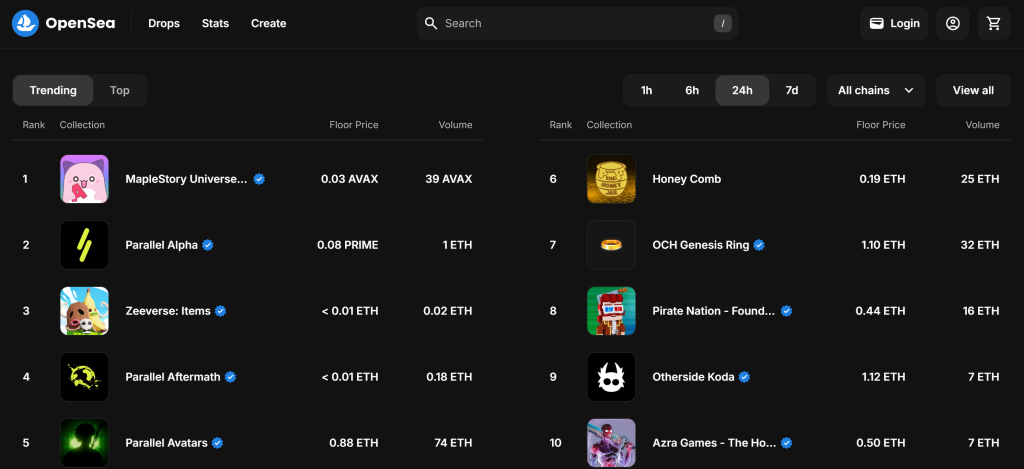
トップ」NFTコレクションに興味があることを忘れないでください。つまり、OpenSeaスクレーパーに、以下のように「トップ」ボタンをクリックするように指示します:
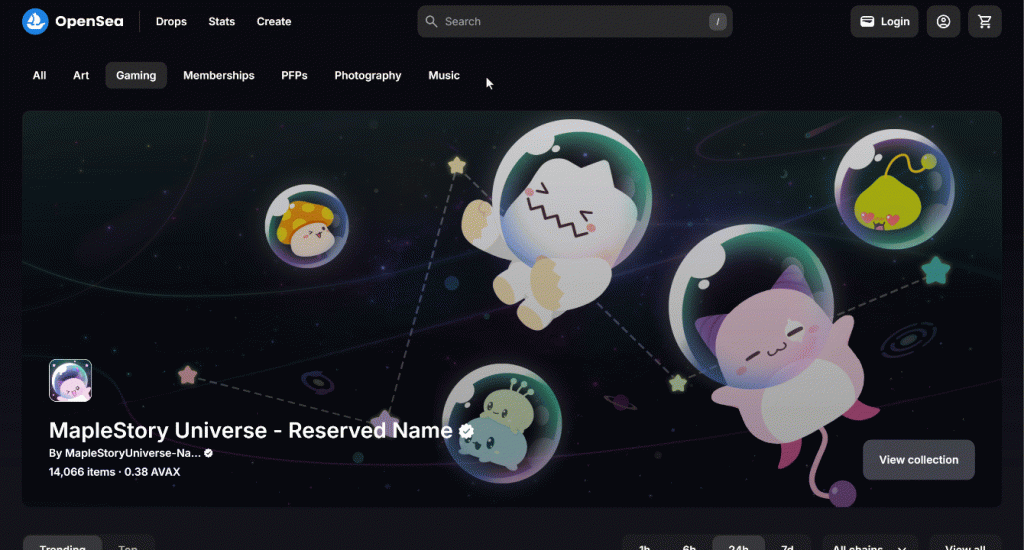
最初のステップとして、”Top “ボタンを右クリックし、”Inspect “オプションを選択して検査する:
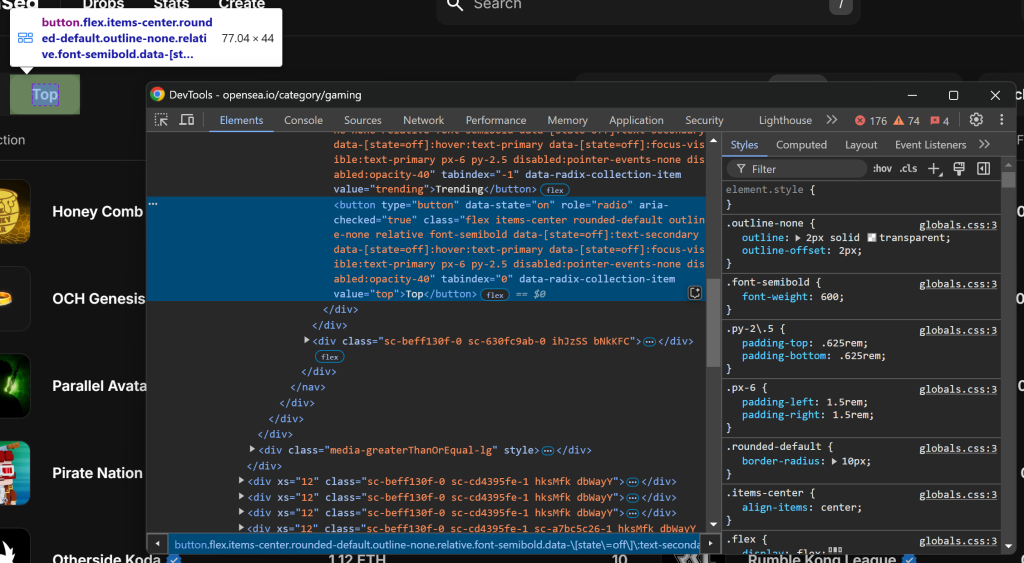
value="top"]CSSセレクタで選択できることに注意してください。Seleniumのfind_element()を使って、そのCSSセレクタをページに適用します。要素を選択したら、click() でその要素をクリックします:
top_element = driver.find_element(By.CSS_SELECTOR, "[value="top"]")
top_element.click()
上記のコードを動作させるには、Byimportを追加するのを忘れないこと:
from selenium.webdriver.common.by import By
素晴らしい!これらのコード行は、目的のインタラクションをシミュレートする。
ステップ6:NFTのコレクションをかき集める準備
ターゲットページには、選択したカテゴリのNFTコレクショントップ10が表示されます。これはリストなので、スクレイピングされた情報を格納するために空の配列を初期化します:
nft_collections = []
次に、NFTコレクション・エントリーのHTML要素を調べます:
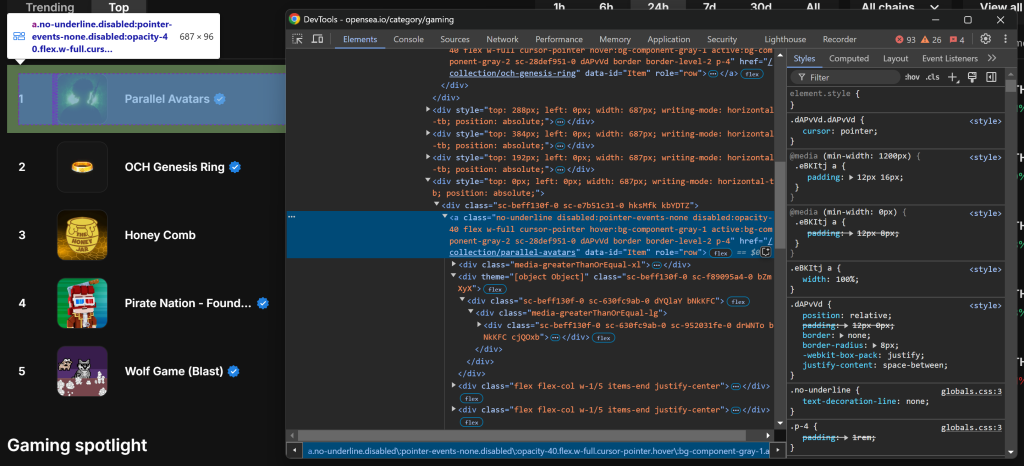
a[data-id="Item"]CSSセレクタを使用すると、すべてのNFTコレクション・エントリを選択できることに注意してください。要素内のいくつかのクラス名はランダムに生成されているように見えるので、それらを直接ターゲットにすることは避けてください。代わりに、data-*属性に注目してください。これらは一般的にテストに使用され、長期間にわたって一貫性が保たれるからです。
find_elements() を使用して、すべての NFT コレクション・エントリ要素を取得する:
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id="Item"]")
次に、エレメントを繰り返し処理し、それぞれのエレメントからデータを抽出する準備をする:
for item_element in item_elements:
# Scraping logic...
素晴らしい!これで、OpenSea NFT要素からデータのスクレイピングを開始する準備ができました。
ステップ#7:NFTのコレクション要素をかき集める
NFTコレクションエントリーを検査する:
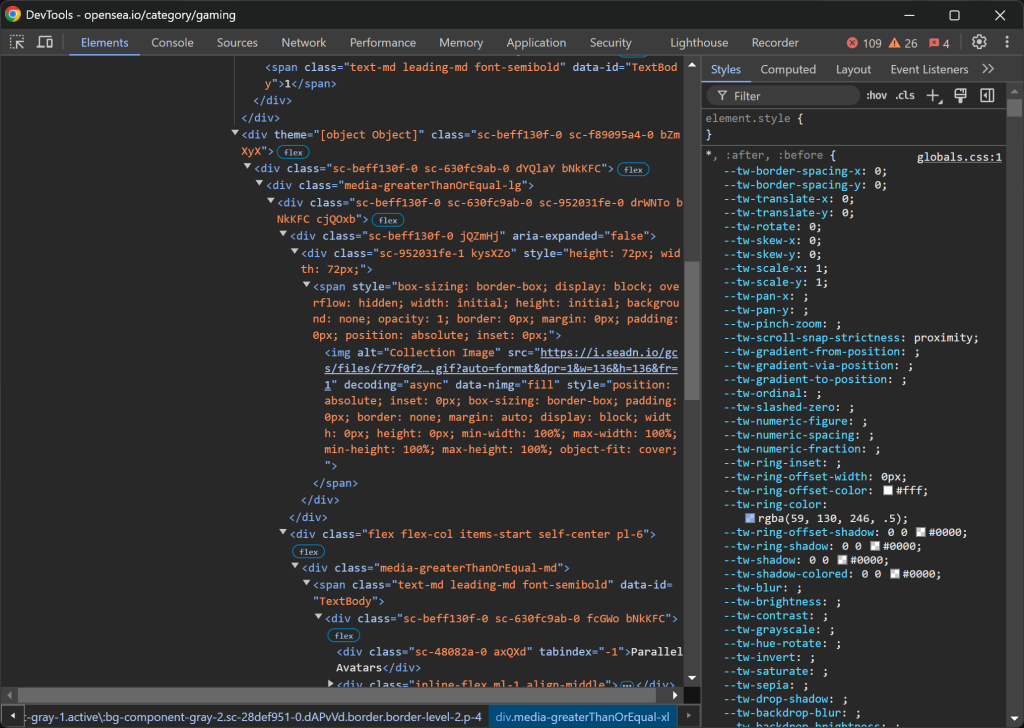
HTMLの構造はかなり入り組んでいるが、以下の詳細を抽出することができる:
img[alt="コレクション画像"]のコレクション画像。data-id="TextBody"]からのコレクションランク。tabindex="-1"]のコレクション名。
残念ながら、これらの要素にはユニークな属性や安定した属性がないため、潜在的に不安定なセレクタに頼る必要があります。これら最初の3つの属性のスクレイピング・ロジックを実装することから始めましょう:
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt="Collection Image"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id="TextBody"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
name = name_element.text
.textプロパティは、選択された要素のテキストコンテンツを取得します。ランクは後でスクレイピングされたデータのソートに使用されるため、整数に変換されます。一方、.get_attribute("src")は src属性の値を取得し、画像のURLを抽出します。
次に、.w-1/5の列に注目する:
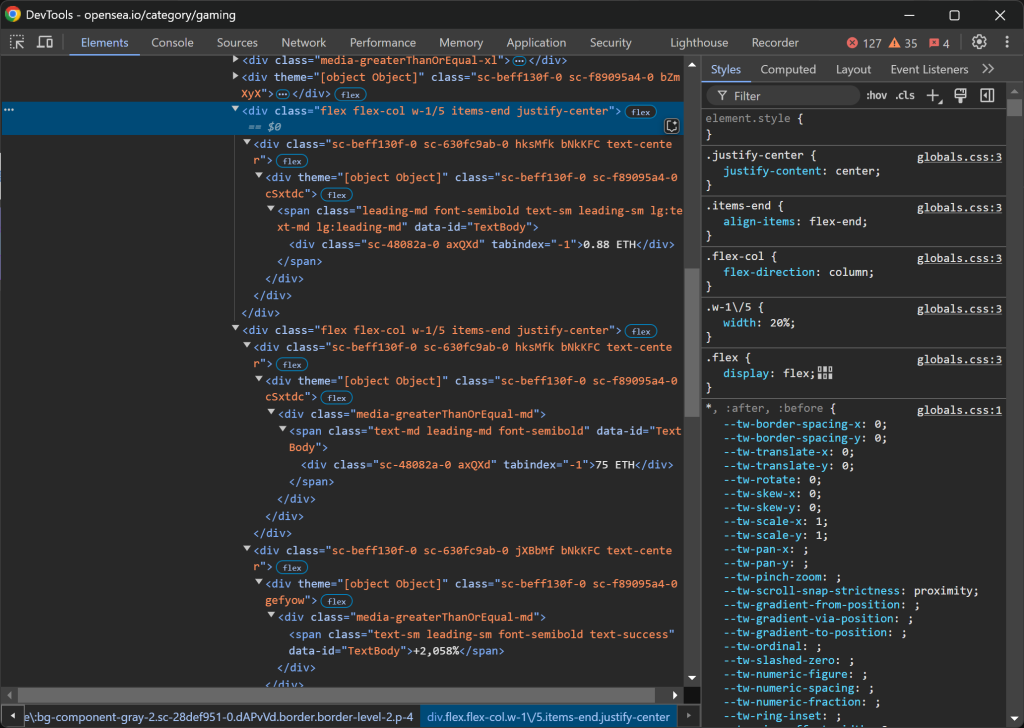
データの構造はこうなっている:
- 最初の
.w-1/5の列にはフロアプライスが含まれている。 - 2番目の
.w-1/5の列には、体積と変化率がそれぞれ別々の要素で含まれている。
以下のロジックでこれらの値を抽出する:
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text
なお、.w-1/5を直接使うことはできず、/を ˶でエスケープする必要がある。
お待たせしました!NFTコレクションを取得するためのOpenSeaスクレイピングロジックが完成しました。
ステップ#8:スクレイピングしたデータを収集する
現在、スクレイピングされたデータは複数の変数にまたがっています。そのデータで新しい nft_collection オブジェクトを生成します:
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}
それから、nft_collectionsの配列に追加するのを忘れないように:
nft_collections.append(nft_collection)
forループの外で、スクレイピングされたデータを昇順にソートする:
nft_collections.sort(key=lambda x: x["rank"])
素晴らしい!あとは、この情報をCSVのような人間が読めるファイルにエクスポートするだけだ。
ステップ #9: スクレイピングしたデータをCSVにエクスポートする
PythonはCSVのようなフォーマットへのデータエクスポートをビルトインサポートしています。以下のコードでそれを実現できます:
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)
このスニペットはnft_collectionsリストからスクレイピングされたデータをnft_collections.csvというCSVファイルにエクスポートします。Pythonのcsvモジュールを使用して、構造化されたフォーマットでデータを書き込むライターオブジェクトを作成します。各エントリは、nft_collectionsリストの辞書キーに対応するカラムヘッダーを持つ行として格納されます。
でPython標準ライブラリからcsvをインポートする:
imprort csv
ステップ10:すべてをまとめる
これがOpenSeaスクレイパーの最終的なコードです:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Select the "Top" NFTs
top_element = driver.find_element(By.CSS_SELECTOR, "[value="top"]")
top_element.click()
# Where to store the scraped data
nft_collections = []
# Select all NFT collection HTML elements
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id="Item"]")
# Iterate over them and scrape data from them
for item_element in item_elements:
# Scraping logic
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt="Collection Image"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id="TextBody"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
name = name_element.text
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text
# Populate a new NFT collection object with the scraped data
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}
# Add it to the list
nft_collections.append(nft_collection)
# Sort the collections by rank in ascending order
nft_collections.sort(key=lambda x: x["rank"])
# Save to CSV
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)
# close the browser and release its resources
driver.quit()
出来上がりです!100行以下のコードで、シンプルなPython OpenSeaスクレイピングスクリプトを構築することができます。
ターミナルで以下のコマンドを入力して起動する:
python scraper.py
しばらくすると、このnft_collections.csvファイルがプロジェクトのフォルダに表示されます:
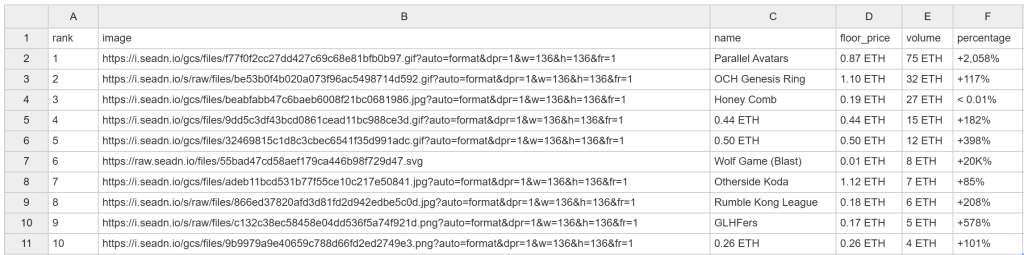
おめでとう!予定通りOpenSeaをスクラップしましたね。
OpenSeaのデータを簡単にロック解除
OpenSeaが提供するのは、NFTコレクションのランキングだけではありません。各NFTコレクションとその中の個々のアイテムの詳細ページも提供しています。NFTの価格は頻繁に変動するため、スクレイピングスクリプトを自動的かつ頻繁に実行し、新鮮なデータを取得する必要があります。しかし、ほとんどのOpenSeaページは厳格なスクレイピング防止対策によって保護されているため、データの取得は困難です。
先に述べたように、ヘッドレス・ブラウザを使うという選択肢はなく、ブラウザのインスタンスを開き続けるためにリソースを浪費することになる。さらに、ページ上の他の要素とやりとりしようとすると、問題が発生する可能性があります:
例えば、データの読み込みが滞ったり、ブラウザのAJAXリクエストがブロックされて403 Forbiddenエラーになったりする:
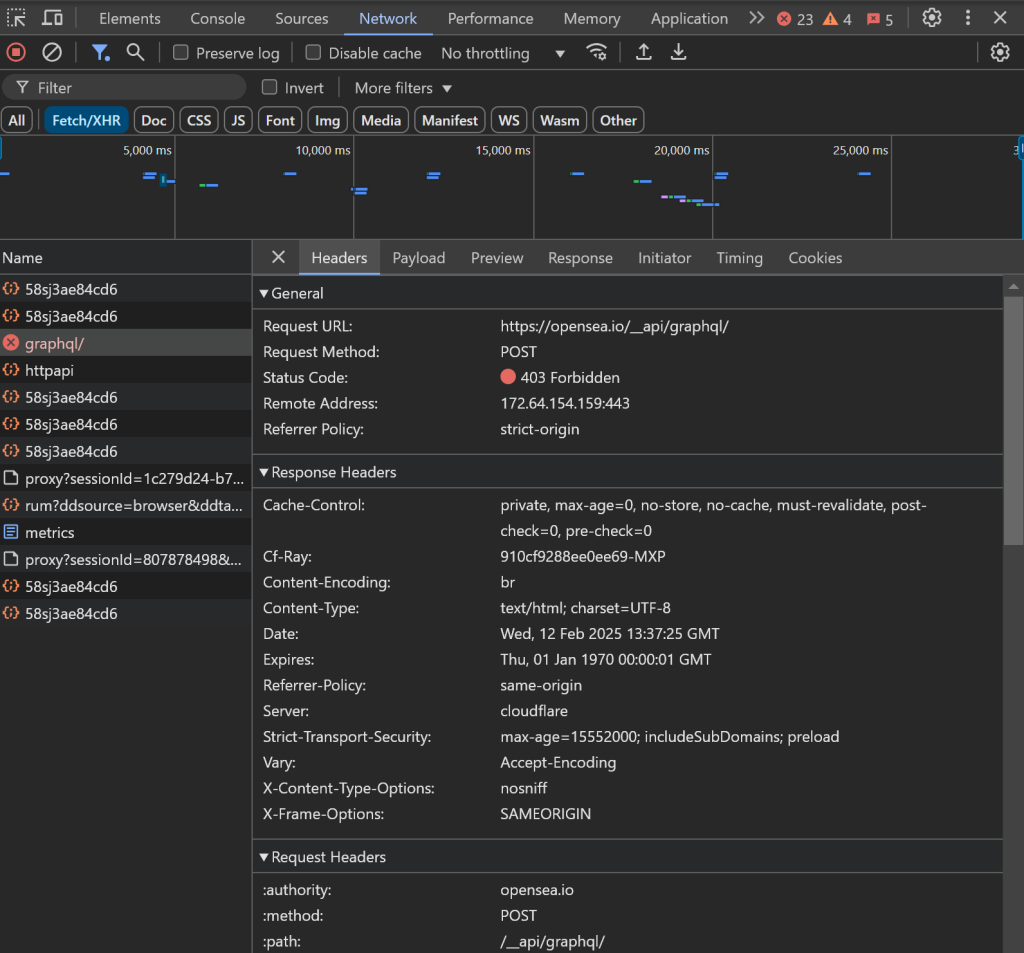
これは、OpenSeaがスクレイピングボットをブロックするための高度なボット対策を行っているためです。
これらの問題は、適切なツールなしでOpenSeaをスクレイピングすることをイライラさせる経験にしています。解決策は?Bright Dataの専用OpenSeaスクレイパーを使えば、ブロックされるリスクなしに、簡単なAPIコールやノーコードでサイトからデータを取得することができます!
結論
このステップバイステップのチュートリアルでは、OpenSeaスクレーパーとは何か、そして収集できるデータの種類を学びました。また、OpenSea NFTデータをスクレイピングするPythonスクリプトを作成しました。
課題はOpenSeaの厳しいボット対策にあり、自動化されたブラウザとのやり取りをブロックしています。OpenSea Scraperは、名前、説明、トークンID、現在価格、最終販売価格、履歴、オファーなどを含む公開NFTデータを取得するために、APIまたはノーコードで簡単に統合できるツールです。
今すぐBright Dataの無料アカウントを作成し、スクレイパーAPIの使用を開始しましょう!




