

分散ウェブクローリングは、複数のマシンにまたがるウェブスクレイパーのスケーリング戦略であり、それによってシングルノードクローラーの限界を克服する。本記事では、その方法を探る:
- 分散型ウェブクローリングとシングルノード型ウェブクローリング
- 分散型ウェブクローリングのコアアーキテクチャ
- 分散ウェブクローリングの実例
- 実施戦略とベストプラクティス
- よくある落とし穴とその対処法
TL;DR: 分散型ウェブクローリングは、マシンのクラスタを使用してウェブサイトを並行してクロールし、シングルノードのクローラーでは処理できないスケーラビリティとスピードの課題を解決します。アーキテクチャの複雑さとオーバーヘッドを追加する代償として、より高いスループットと信頼性(単一のボトルネックがない)を提供します。
分散クロールとシングルノードクローリング
ほとんどのクローリングプロジェクトは分散システムを必要としないにもかかわらず、チームは日常的に、単一のサーバーで十分であるにもかかわらず、複雑な分散アーキテクチャを構築して何ヶ月も無駄にしている。
シングルノード・クローラーでは、1台のマシンがすべての取得、解析、保存を処理する。この種のシステムは開発・保守が容易で、コストも節約できる。毎分60~500ページのフェッチには最適ですが、クロールのニーズが高まるにつれ、CPU、メモリ、ネットワークの制約を受けるため、シングルノードがボトルネックになります。
対照的に、分散型クローラーは複数のノードに作業を分散させるため、規模に応じた同時取得、高速化、耐障害性の向上が可能になる。1つのワーカーがクラッシュしても、他のワーカーが動作を継続するため、信頼性が向上する。トレードオフとして、分散システムにはメッセージキュー、URLフロンティアの同期、ターゲットサイトの重複や過負荷を避けるための慎重な設計が必要となる。
総合比較
| アスペクト | シングルノード | 分散型 |
|---|---|---|
| パフォーマンス | 平均4秒/ページ、60~120ページ/分 | 30倍高速、50,000リクエスト/秒以上 |
| スケーラビリティ | 単一マシンのリソースによる制限 | ノード間の線形スケーリング |
| フォールト・トレランス | 単一障害点 | 自動フェイルオーバー、自己修復 |
| 地理的分布 | 固定位置 | マルチリージョン展開 |
| 資源利用 | 垂直方向のスケーリングのみ | 水平スケーリングの最適化 |
| 複雑さ | シンプルなセットアップ、最小限のオーバーヘッド | 複雑なオーケストレーション、高い運用コスト |
| コスト | 初期投資の低減 | インフラコストは高いが、ROIは高い |
| メンテナンス | 最小限の運用負担 | 分散システムの専門知識が必要 |
| データ処理 | ローカル処理のみ | ノード間の並列処理 |
| 探知防止 | 限定的なIPローテーション | 高度なプロキシ管理、フィンガープリンティング |
分散型にすべきか?(意思決定ツリー)
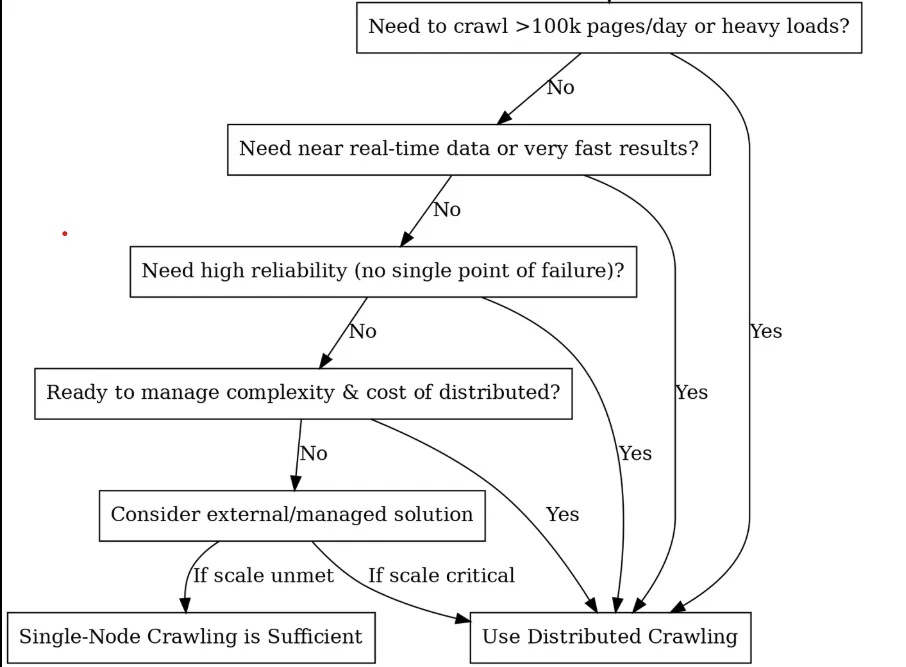
コア・ビルディング・ブロックとアーキテクチャー
分散クロールを採用すると決めたら、次のステップは実際に構築するものを分解することだ。高性能のレーシングチームを編成するようなもので、それぞれのコンポーネントが特定の仕事を持ち、それらがシームレスに連携する必要があると考えてほしい。以下は、分散型クローリングシステムを構築するために必要な主要コンポーネントである:
スケジューラー/キュー(頭脳)
分散クローラーの中心には、ノード間の作業を調整するスケジューラーやタスクキューがあり、クロールされる前のURLはここに保存されます。スケジューラコンポーネントは、ポライトネス(タイミング)やリトライを処理することもできる。例えば、あるサイトがすべてのワーカーによって一度にヒットされないように、ドメイン別のキューを実装することもできる。
スケジューラーには主に3つの選択肢があり、それぞれに個性がある:
- カフカこれはヘビー級チャンピオンのようなものだ。膨大なスループットのために構築されており、毎秒数百万のメッセージを処理しても汗をかくことはない。優れた点はログベースの設計にあり、URLフロンティアの管理に最適です。クロールを丁寧に行うために、ドメインごとに分割することができる。
- RabbitMQ:これはスイスアーミーナイフのようなものだ。Kafkaよりも柔軟なルーティングが可能で、プライオリティキューなどの機能がある。RabbitMQにはインメモリーストレージがあるので、小規模なワークロードでも高速に処理できる。コンテンツの種類によって異なるクロール戦略が必要な場合に最適。
- Celery:Python開発者の親友。このオプションは他のものほど効率的ではないが、使いやすい。Celeryは、プロトタイピングや中規模のクローリングなど、素早く何かを動かしたいときに最適です。
URLフロンティアと重複排除:クローラーの記憶
うっかり同じページを1,000回もクロールしてしまったことはありませんか?そんな時に役立つのが重複排除だ。サーバーの礼儀を守りつつ、何を見たかを追跡する必要があるので、同じドメインを繰り返しクロールすることはない。
Redisセットは完璧な精度を出せるが、メモリを大量に消費する。ブルームフィルターは90%少ないメモリーで済みますが(10億URLで1.2GB対12GB以上)、時々誤検出があります(URLを見ているのに見ていないと言われることがあります):
class DistributedURLFrontier:
def __init__(self, redis_client):
self.redis = redis_client
def add_url(self, url, priority=0):
domain = urlparse(url).netloc
# Skip if already seen
if self.redis.sismember("seen_urls", url):
return
# Mark as seen and queue by domain
self.redis.sadd("seen_urls", url)
self.redis.lpush(f"queue:{domain}", url)
self.redis.zadd("priority_queue", {url: priority})
def get_next_url(self):
# Get highest priority URL
result = self.redis.zrevrange("priority_queue", 0, 0)
if not result:
return None
url = result[0]
domain = urlparse(url).netloc
# Respect crawl delay (1 second between requests per domain)
last_crawl = self.redis.get(f"last_crawl:{domain}")
if last_crawl and time.time() - float(last_crawl) < 1.0:
return None
# Remove from queues and update last crawl time
self.redis.zrem("priority_queue", url)
self.redis.rpop(f"queue:{domain}")
self.redis.set(f"last_crawl:{domain}", time.time())
return url
ワーカー・ノード(筋肉)
ワーカーノードはクロールの主力です。URLの取得やコンテンツの処理など、実際にクロール作業を行うプロセスやマシンです。各ワーカーは同一のクロールロジック(同じPythonスクリプトやアプリケーションなど)を実行しますが、キューから異なるURLに対して並行して動作します。
ワーカーを最大限に活用するには、ワーカーをステートレスにしておく必要があります。状態(訪問したURLや結果など)はすべて共有ストレージに保存するか、メッセージで渡します。こうすることで、どのワーカーでもどんな仕事でもこなすことができ、一人が死んでも他のワーカーが即座にその仕事を引き継ぐことができます。
class DistributedWorker:
def __init__(self, worker_id, max_concurrent=50):
self.worker_id = worker_id
self.semaphore = asyncio.Semaphore(max_concurrent)
self.session = aiohttp.ClientSession(
timeout=aiohttp.ClientTimeout(total=30),
connector=aiohttp.TCPConnector(limit=100)
)
async def crawl_batch(self, urls):
tasks = [self.crawl_url(url) for url in urls]
return await asyncio.gather(*tasks, return_exceptions=True)
async def crawl_url(self, url):
async with self.semaphore:
try:
async with self.session.get(url) as response:
content = await response.text()
return {'url': url, 'content': content, 'status': response.status}
except Exception as e:
return {'url': url, 'error': str(e)}
プロからのアドバイス:ワーカーでは、すべてにスレッジハンマーを使わないことが重要です。静的なHTMLには軽量なHTTPワーカーを使い、JavaScriptでレンダリングされたページには重いPuppeteerワーカーを使うべきです。異なるツール、異なるワーカープール。包括的なプロキシ選択ガイドで、ワーカーフリートに適したプロキシタイプを簡単に選択できます。
ストレージ層(倉庫)
ストレージレイヤーは、クロールされたデータとメタデータを保存する場所で、多くの場合、2つの部分から構成される:
- コンテンツ・ストレージは、大量の生のHTML、JSONレスポンス、画像、PDFを処理します。デジタル倉庫と考えてほしい。S3、Google Cloud Storage、HDFSのようなオブジェクト・ストアは、無限にスケールし、複数のワーカーからの同時書き込みを汗をかくことなく処理できるため、この分野で優れている。
- メタデータ・ストレージは、解析されたフィールド、エンティティのリレーションシップ、クロールのタイムスタンプ、成功/失敗のステータスなど、あなたが抽出した構造化されたデータを保持する。これは、ストレージ容量だけでなく、クエリと更新のために最適化されたデータベースに格納される。
分散クローラーには、大量の同時書き込みを処理するストレージが必要だ。S3やGoogle Cloud Storageのようなオブジェクト・ストアは、無限にスケールするため、生のコンテンツに優れている。一方、NoSQLデータベース(MongoDB、Cassandra)やSQLは、構造化されたメタデータを効率的に処理する。
監視と警告
分散クローラーを運用するには、システムのパフォーマンスを可視化する必要があります。PrometheusとGrafanaを使用して、クロール率、成功率、応答時間、キューの深さを追跡する包括的な監視ダッシュボードを作成できます。主なメトリクスには、ドメインごとの1秒あたりのリクエスト数、95パーセンタイルのレスポンスタイム、キューサイズの傾向などがあります。
アンチボット&回避レイヤー
大規模なウェブクローリングは、アンチボットシステムとの絶え間ない駆け引きを意味する。何千もの家庭用 プロキシやデータセンター用プロキシにまたがるIPローテーション、ユーザーエージェントやブラウザのシグネチャのフィンガープリント無作為化、そして検知パターンを回避するための行動模倣だ。
Bright Data Web Unlockerは、自動 CAPTCHA 解読、IP ローテーション、ブラウザフィンガープリントにより、99% 以上の成功率を誇るエンタープライズグレードのアンチ検出機能を提供します。その API ベースのアプローチは、複雑なボット対策の課題を処理しながら、統合を簡素化します。
class BrightDataWebUnlocker:
def crawl_url(self, url: str, options: Dict = None) -> Dict:
payload = {
"url": url,
"zone": self.zone,
"format": "raw",
"country": "US",
"render_js": True,
"wait_for_selector": ".content"
}
response = requests.post(
self.base_url,
headers={"Authorization": f"Bearer {self.api_key}"},
json=payload,
timeout=60
)
高度なプロキシローテーションは、住宅、データセンター、およびモバイルプロキシプール全体で、ヘルスチェック、地理的最適化、および障害回復を実装しています。プロキシ管理を成功させるには、インテリジェントなローテーションアルゴリズムによる1000以上のIPが必要です。
フィンガープリントの回避はユーザーエージェント、ブラウザのフィンガープリント、ネットワークの特徴をランダム化し、高度なアンチボットシステムによる検出を防ぎます。これには TLS フィンガープリントのローテーション、キャンバスフィンガープリントのスプーフィング、行動パターンのシミュレーションが含まれます。
コード例による実際の使用例
分散クローラの一般的なユースケースを2つ取り上げ、コード・スニペットで実装方法を概説しよう。例では簡単のためにPythonとCeleryを使うが、原理は一般的に適用できる。
ユースケース1:Eコマース価格モニタリング
毎日50,000の商品ページで競合他社の価格を追跡しているとしよう。1台のマシンでこれらのURLをすべてヒットさせようとすると、何も問題がなければ、クロールに12時間以上かかることになる。さらに、ほとんどのeコマースサイトは、同じIPから数千回ものリクエストがあるとブロックし始めます。
ここで役に立つのが分散クロールだ。1台のマシンに負担をかけるのではなく、50,000のURLを数十のワーカーに分散させ、それぞれが異なるIPアドレスを使用する。これまで半日かかっていた作業が2〜3時間で完了し、ボット対策システムのレーダーをかいくぐることができる。
セットアップは簡単だ。競合のURLリストを管理し(サイトマップやディスカバリークロールから取得する)、CeleryとRedisのようなものを使って作業を分散させる。毎朝、50,000のURLをキューに入れ、ワーカーに仕事をさせる。ワーカー1はナイキのランニングシューズ、ワーカー2はアディダスのスニーカー、ワーカー3はプーマの価格設定を担当する。すべて同時に、すべて異なるIPから。
from celery import Celery
import requests
from bs4 import BeautifulSoup
import random
import time
import re
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# Initialize Celery app with Redis as broker
app = Celery('price_monitor', broker='redis://localhost:6379/0')
# Realistic user agents for rotation
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15"
]
# Proxy pool (replace with your actual proxy service)
PROXY_POOL = [
"<http://proxy1:8080>",
"<http://proxy2:8080>",
"<http://proxy3:8080>",
# Add your proxy endpoints here
]
def get_session_with_retries():
"""Create a session with retry strategy and random proxy."""
session = requests.Session()
# Retry strategy for resilience
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504],
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("http://", adapter)
session.mount("https://", adapter)
# Random proxy rotation
if PROXY_POOL:
proxy = random.choice(PROXY_POOL)
session.proxies = {"http": proxy, "https": proxy}
return session
@app.task(bind=True, max_retries=3)
def fetch_product_price(self, url, site_config=None):
"""Fetches product price with full anti-detection measures."""
# Human-like delay before starting
time.sleep(random.uniform(2, 8))
# Randomized headers to avoid fingerprinting
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Cache-Control": "max-age=0"
}
try:
session = get_session_with_retries()
resp = session.get(url, headers=headers, timeout=30)
resp.raise_for_status()
# Parse the page for price
soup = BeautifulSoup(resp.text, 'html.parser')
price_value = extract_price(soup, url, site_config)
if price_value:
# Store in database (implement your storage logic here)
store_price_data(url, price_value, resp.status_code)
return {"url": url, "price": price_value, "status": "success"}
else:
return {"url": url, "error": "Price not found", "status": "failed"}
except requests.exceptions.RequestException as e:
print(f"Request failed for {url}: {e}")
# Retry with exponential backoff
if self.request.retries < self.max_retries:
raise self.retry(countdown=60 * (2 ** self.request.retries))
return {"url": url, "error": str(e), "status": "failed"}
def extract_price(soup, url, site_config=None):
"""Extract price using multiple strategies."""
# Site-specific selectors (customize for each competitor)
price_selectors = [
".price", ".product-price", ".current-price", ".sale-price",
"[data-price]", ".price-current", ".price-now", ".offer-price"
]
# Try configured selectors first
if site_config and site_config.get('price_selector'):
price_selectors.insert(0, site_config['price_selector'])
price_text = None
for selector in price_selectors:
price_elem = soup.select_one(selector)
if price_elem:
price_text = price_elem.get_text(strip=True)
break
# Try data attributes as fallback
if not price_text:
price_elem = soup.find(attrs={"data-price": True})
if price_elem:
price_text = price_elem.get("data-price")
if not price_text:
return None
# Clean and parse price
return parse_price(price_text)
def parse_price(price_text):
"""Parse price from various formats."""
# Remove common currency symbols and whitespace
cleaned = re.sub(r'[^\d.,]', '', price_text)
# Handle formats like "1,299.99" or "1299.99"
try:
# Remove commas and convert to float
if ',' in cleaned and '.' in cleaned:
# Format: 1,299.99
price_value = float(cleaned.replace(',', ''))
elif ',' in cleaned:
# Could be European format: 1299,99
if cleaned.count(',') == 1 and len(cleaned.split(',')[1]) == 2:
price_value = float(cleaned.replace(',', '.'))
else:
# Format: 1,299 (no cents)
price_value = float(cleaned.replace(',', ''))
else:
price_value = float(cleaned)
return price_value
except ValueError:
print(f"Could not parse price from: {price_text}")
return None
def store_price_data(url, price, status_code):
"""Store price data in your database."""
# Implement your storage logic here
# Could be PostgreSQL, MongoDB, or any other database
print(f"Storing: {url} -> ${price} (Status: {status_code})")
# Site-specific configurations for better accuracy
SITE_CONFIGS = {
"competitor1.com": {"price_selector": ".price-box .price"},
"competitor2.com": {"price_selector": "[data-testid='price']"},
"competitor3.com": {"price_selector": ".product-price-value"},
}
def get_site_config(url):
"""Get site-specific configuration."""
for domain, config in SITE_CONFIGS.items():
if domain in url:
return config
return None
# Load your 50k product URLs (from database, file, or API)
def load_product_urls():
"""Load URLs from your data source."""
# Replace with your actual data loading logic
urls = [
"<https://competitor1.com/product/123>",
"<https://competitor2.com/product/456>",
# ... 49,998 more URLs
]
return urls
# Main execution: dispatch all crawling tasks
def start_daily_price_monitoring():
"""Start the daily price monitoring job."""
product_urls = load_product_urls()
print(f"Starting crawl for {len(product_urls)} URLs...")
for url in product_urls:
site_config = get_site_config(url)
fetch_product_price.delay(url, site_config)
print("All tasks queued successfully!")
# Run with: python -m celery worker -A price_monitor --loglevel=info
# Start monitoring with: start_daily_price_monitoring()
上記の拡張コードでは、fetch_product_priceはエンタープライズ規模の価格監視用に設計された堅牢なCeleryタスクです。各URLに対してdelay(url, site_config)を呼び出すことで、100人以上のワーカーが即座に取得できるRedisにタスクをキューイングします。分散アプローチは、12時間のシングルマシンのクロールを、ワーカーフリート全体で2-3時間のオペレーションに変換します。
主な生産上の考慮事項:
- プロキシ管理は非常に重要である。この例では、リクエストごとにIPをローテートするPROXY_POOLが含まれている。これがないと、実質的に1つのIPからターゲットサイトをDoSすることになり、ブロックが保証される。
- ドメインごとのレート制限:分散させたとしても、1つの競合サイトから50,000のURLが数分以内にすべてヒットすれば、アラームが作動する。人間のような遅延
(time.sleep(random.uniform(2,8)))を含むが、ドメインごとのスロットリングを考慮する。 - スケジューリングとモニタリング。日々のスケジューリングにはCelery Beatを、複雑なワークフローにはAirflowと統合しましょう。
start_daily_price_monitoring()関数は、cronやオーケストレーションプラットフォームを介してトリガーすることができます。 - データパイプラインの統合。各クロールの後、
store_price_data()関数は結果をデータベースに保存します。 - 障害の回復力。コードには指数関数的バックオフによる再試行ロジックが含まれているが、部分的な失敗も想定しておくこと。URLの5%が常に失敗する場合は、それらの製品が販売中止されたか、移動されたか、またはそれらの特定のサイトが異なるアプローチを必要とする強力なボット対策を持っているかどうかを調査する。
使用例2:SEOと市場調査
SEOと市場調査には、コンテンツ分析と検索エンジンのモニタリングという2つの重要な流れにわたって、何百万ものページをクロールする必要があります。単なるスクレイピングではなく、スピード、ステルス性、精度が要求される競合情報を構築するのです。
100万の競合ページにわたるキーワードの言及を追跡し、同時に数百のターゲットキーワードのSERPランキングを毎日監視したい場合、1台のマシンでは数週間かかり、数時間でブロックされてしまう。これは分散アーキテクチャの悲鳴である。
このための分散型ウェブクローリングアプローチは、2つの流れに分けることができる:
- コンテンツ・インテリジェンス:競合サイト、ニュースアウトレット、業界ブログをクロールし、キーワード密度、コンテンツギャップ、市場動向を追跡します。
- SERPサーベイランスターゲットキーワードのGoogle/Bingランキングを監視し、競合の順位やSERPの機能変更を追跡します。
from celery import Celery
import requests
from bs4 import BeautifulSoup
import redis
import hashlib
import json
import time
import random
import re
from urllib.parse import urljoin, urlparse
from dataclasses import dataclass
from typing import List, Dict, Optional
import logging
# Initialize Celery and Redis
app = Celery('seo_intelligence', broker='redis://localhost:6379/0')
redis_client = redis.Redis(host='localhost', port=6379, db=1)
# Anti-detection configurations
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 Safari/605.1.15"
]
PROXY_POOL = [
"<http://user:[email protected]:8080>",
"<http://user:[email protected]:8080>",
# Add your proxy endpoints
]
@dataclass
class KeywordData:
keyword: str
frequency: int
context: List[str] # Surrounding text snippets
url: str
domain: str
@dataclass
class SERPResult:
keyword: str
position: int
title: str
url: str
snippet: str
domain: str
class SEOCrawler:
def __init__(self):
self.session = self._create_session()
def _create_session(self):
session = requests.Session()
if PROXY_POOL:
proxy = random.choice(PROXY_POOL)
session.proxies = {"http": proxy, "https": proxy}
return session
def _get_headers(self):
return {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Cache-Control": "max-age=0"
}
# Deduplication utilities
def get_url_hash(url: str) -> str:
"""Generate consistent hash for URL deduplication."""
return hashlib.md5(url.encode()).hexdigest()
def is_url_processed(url: str) -> bool:
"""Check if URL was already processed today."""
url_hash = get_url_hash(url)
today = time.strftime("%Y-%m-%d")
return redis_client.exists(f"processed:{today}:{url_hash}")
def mark_url_processed(url: str):
"""Mark URL as processed with 24h expiry."""
url_hash = get_url_hash(url)
today = time.strftime("%Y-%m-%d")
redis_client.setex(f"processed:{today}:{url_hash}", 86400, 1)
# Stream 1: Content Intelligence Crawling
@app.task(bind=True, max_retries=3)
def crawl_content_for_keywords(self, url: str, target_keywords: List[str]):
"""Crawl a page and extract keyword intelligence."""
# Skip if already processed today
if is_url_processed(url):
return {"status": "skipped", "reason": "already_processed", "url": url}
# Human-like delay
time.sleep(random.uniform(3, 7))
try:
crawler = SEOCrawler()
response = crawler.session.get(
url,
headers=crawler._get_headers(),
timeout=30
)
response.raise_for_status()
# Extract content and analyze keywords
soup = BeautifulSoup(response.text, 'html.parser')
content_data = extract_keyword_intelligence(soup, url, target_keywords)
# Store results
store_keyword_data(content_data)
mark_url_processed(url)
return {
"status": "success",
"url": url,
"keywords_found": len(content_data),
"total_mentions": sum(kd.frequency for kd in content_data)
}
except Exception as e:
logging.error(f"Content crawl failed for {url}: {e}")
if self.request.retries < self.max_retries:
raise self.retry(countdown=60 * (2 ** self.request.retries))
return {"status": "failed", "url": url, "error": str(e)}
def extract_keyword_intelligence(soup: BeautifulSoup, url: str, keywords: List[str]) -> List[KeywordData]:
"""Extract keyword data from page content."""
# Remove script and style elements
for script in soup(["script", "style", "nav", "footer", "header"]):
script.decompose()
# Get clean text content
text = soup.get_text()
text = re.sub(r'\s+', ' ', text).strip().lower()
domain = urlparse(url).netloc
keyword_data = []
for keyword in keywords:
keyword_lower = keyword.lower()
# Find all occurrences
pattern = r'\b' + re.escape(keyword_lower) + r'\b'
matches = list(re.finditer(pattern, text))
if matches:
# Extract context around each match
contexts = []
for match in matches[:5]: # Limit to first 5 for performance
start = max(0, match.start() - 100)
end = min(len(text), match.end() + 100)
context = text[start:end].strip()
contexts.append(context)
keyword_data.append(KeywordData(
keyword=keyword,
frequency=len(matches),
context=contexts,
url=url,
domain=domain
))
return keyword_data
# Stream 2: SERP Tracking
@app.task(bind=True, max_retries=3)
def track_serp_rankings(self, keyword: str, search_engine: str = "google"):
"""Track SERP positions for a keyword."""
time.sleep(random.uniform(5, 10)) # Longer delay for search engines
try:
crawler = SEOCrawler()
if search_engine == "google":
search_url = f"<https://www.google.com/search?q={keyword}&num=20>"
else: # Bing
search_url = f"<https://www.bing.com/search?q={keyword}&count=20>"
# Special headers for search engines
headers = crawler._get_headers()
headers.update({
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Referer": "<https://www.google.com/>" if search_engine == "google" else "<https://www.bing.com/>"
})
response = crawler.session.get(search_url, headers=headers, timeout=30)
response.raise_for_status()
# Parse SERP results
soup = BeautifulSoup(response.text, 'html.parser')
serp_data = parse_serp_results(soup, keyword, search_engine)
# Store SERP data
store_serp_data(serp_data)
return {
"status": "success",
"keyword": keyword,
"results_found": len(serp_data),
"search_engine": search_engine
}
except Exception as e:
logging.error(f"SERP tracking failed for '{keyword}': {e}")
if self.request.retries < self.max_retries:
raise self.retry(countdown=120 * (2 ** self.request.retries))
return {"status": "failed", "keyword": keyword, "error": str(e)}
def parse_serp_results(soup: BeautifulSoup, keyword: str, search_engine: str) -> List[SERPResult]:
"""Parse search engine results page."""
results = []
position = 1
if search_engine == "google":
# Google result selectors
result_elements = soup.select('div.g')
for element in result_elements:
title_elem = element.select_one('h3')
link_elem = element.select_one('a[href]')
snippet_elem = element.select_one('.VwiC3b, .s3v9rd')
if title_elem and link_elem:
url = link_elem.get('href', '')
if url.startswith('/url?q='):
url = url.split('/url?q=')[1].split('&')[0]
results.append(SERPResult(
keyword=keyword,
position=position,
title=title_elem.get_text(strip=True),
url=url,
snippet=snippet_elem.get_text(strip=True) if snippet_elem else "",
domain=urlparse(url).netloc if url else ""
))
position += 1
if position > 20: # Limit to top 20
break
else: # Bing
result_elements = soup.select('.b_algo')
for element in result_elements:
title_elem = element.select_one('h2 a')
snippet_elem = element.select_one('.b_caption p')
if title_elem:
url = title_elem.get('href', '')
results.append(SERPResult(
keyword=keyword,
position=position,
title=title_elem.get_text(strip=True),
url=url,
snippet=snippet_elem.get_text(strip=True) if snippet_elem else "",
domain=urlparse(url).netloc if url else ""
))
position += 1
if position > 20:
break
return results
# Data storage functions
def store_keyword_data(keyword_data: List[KeywordData]):
"""Store keyword intelligence in database."""
for kd in keyword_data:
data = {
"keyword": kd.keyword,
"frequency": kd.frequency,
"context": kd.context,
"url": kd.url,
"domain": kd.domain,
"crawled_at": time.time()
}
# Store in your preferred database (PostgreSQL, MongoDB, etc.)
redis_client.lpush(f"keyword_data:{kd.keyword}", json.dumps(data))
print(f"Stored: {kd.keyword} found {kd.frequency} times on {kd.domain}")
def store_serp_data(serp_data: List[SERPResult]):
"""Store SERP tracking data."""
for result in serp_data:
data = {
"keyword": result.keyword,
"position": result.position,
"title": result.title,
"url": result.url,
"snippet": result.snippet,
"domain": result.domain,
"tracked_at": time.time()
}
redis_client.lpush(f"serp_data:{result.keyword}", json.dumps(data))
print(f"SERP: '{result.keyword}' -> #{result.position} {result.domain}")
# Orchestration functions
def start_content_intelligence_crawl(urls: List[str], keywords: List[str]):
"""Launch content crawling across 1M+ URLs."""
print(f"Starting content intelligence crawl for {len(urls)} URLs...")
for url in urls:
crawl_content_for_keywords.delay(url, keywords)
print(f"Queued {len(urls)} content crawling tasks")
def start_serp_tracking(keywords: List[str], search_engines: List[str] = ["google", "bing"]):
"""Launch SERP tracking for target keywords."""
print(f"Starting SERP tracking for {len(keywords)} keywords...")
for keyword in keywords:
for engine in search_engines:
track_serp_rankings.delay(keyword, engine)
print(f"Queued {len(keywords) * len(search_engines)} SERP tracking tasks")
# Example usage
if __name__ == "__main__":
# Target keywords for analysis
target_keywords = [
"artificial intelligence", "machine learning", "data science",
"cloud computing", "cybersecurity", "digital transformation"
]
# URLs to crawl for content intelligence (load from your database)
content_urls = [
"<https://techcrunch.com/ai>",
"<https://venturebeat.com/ai>",
"<https://competitor-blog.com/insights>",
# ... 999,997 more URLs
]
# Keywords to track in SERPs
serp_keywords = [
"best AI tools 2026", "enterprise machine learning",
"data analytics platform", "cloud security solutions"
]
# Launch both crawling streams
start_content_intelligence_crawl(content_urls, target_keywords)
start_serp_tracking(serp_keywords)
主な生産上の考慮事項:
- インテリジェントな重複排除:システムは24時間有効のRedisを使用し、毎日同じコンテンツを再クロールすることを避ける。より深く重複排除を行うには、URLを変更しても同じコンテンツを保持するページを検出するためのコンテンツハッシュ化を検討する。
- ドメインを意識したレート制限:SERPクロールは、検索エンジンがブロックに対してより積極的であるため、特に注意が必要である。私たちの例では、検索クエリに対するより長い遅延(5-10秒)とコンテンツクロール(3-7秒)が含まれます。
- SERP機能のトラッキング:パーサーはGoogleとBingの両方の結果を扱いますが、フィーチャードスニペット、ローカルパック、その他のSERPの特徴を追跡するように拡張することができます。
- データパイプラインの統合:結果をお好みのデータベース(リレーショナル分析にはPostgreSQL、柔軟なスキーマにはMongoDB)に保存します。
ベストプラクティス
robots.txtを尊重するか、その結果に直面するか
URLをキューに入れる前にrobots.txtを解析し、クロール遅延ディレクティブを忠実に守ること。これらを無視すると、”分散クローラー “と言うよりも早く、あなたのIP範囲全体がブラックリストに載ってしまいます。robots.txtのチェックをURLフロンティアに直接組み込み、ワーカーノードの責任にしないこと。
robots.txtの遵守だけでなく、分散した艦隊全体に包括的な検出回避戦略を導入する必要があります。
午前3時のデバッグのために常にログを記録
深夜にクロールが停止した場合、メタデータが必要になる:URL、HTTPステータス、レイテンシ、プロキシID、ワーカーID、タイムスタンプ。JSON構造化されたログは、あなたの正気を守ります。問題は、本番環境での失敗をデバッグする必要があるかどうかではなく、いつあるかということです。
すべてを検証し、何も信用しない
たった1つの不正なレスポンスがデータセット全体を汚染する可能性があるからです。取り込み時にフィールドタイプ、必須フィールド、データの鮮度をチェックする。ゴミを早期に発見するか、数カ月後にゴミが分析を台無しにしていることに気づくかだ。
スピード債務と無慈悲に戦う
分散システムは腐敗が早い。古くなったRedisキー、失敗したタスクキュー、孤立したワーカープロセスのクリーンアップを毎月スケジュールする必要があります。デッドURLは山積みになり、プロキシプールはブロックされたIPで汚染され、ワーカーのメモリリークは時間とともに悪化します。メンテナンスは華やかではありませんが、クローラーを健全に保ちます。クローラーの技術的負債は指数関数的に増大するので、システムが壊れる前に対処しましょう。
分散クロールのよくある落とし穴とその回避方法
分散型ウェブクローリングを使用する際に直面する一般的な落とし穴は数多くあり、多くのエンジニアがBright Dataのデータセットのような代替手段を求めるのはそのためです。これらの落とし穴には以下のようなものがあります:
単一障害点」の罠
1つのRedisインスタンスやマスターコーディネーターを中心にすべてを構築するのは悪い考えだ。このインスタンスが死ぬと、クロール全体が止まってしまう。
修正:Redis Clusterか複数のブローカーインスタンスを使う。コーディネータがいなくなるように設計し、ワーカーはブローカの停止に優雅に対処し、自動的に再接続する。
リトライの死のスパイラル
失敗したURLがすぐにメインキューに戻されると、無限ループが発生し、壊れたエンドポイントが叩かれ、パイプラインが詰まってしまう。
修正:指数関数的バックオフでリトライキューを分ける。最初は1分後、次に5分後、30分後に再試行。3回失敗したら、デッドレターキューに送り、手動でレビューする。
すべての労働者は平等の誤り
ラウンドロビンによるタスク分配は、すべてのワーカーが同じネットワーク速度、プロキシの品質、処理能力を持っていると仮定しています。現実はもっと厄介です。
修正:成功率、レイテンシ、スループットに基づいたワーカースコアリングを実装。ベストパフォーマーに、より難しいジョブを割り振ろう。
メモリ漏れの時限爆弾
再起動しないワーカーはメモリリークを蓄積します。特に、不正な HTML を解析するときや、大きなレスポンスを処理するときに顕著です。放っておくと、ワーカーがクラッシュするまで分散ウェブクローリングのパフォーマンスは低下します。
修正1000タスク処理後、または4時間ごとにワーカーを再起動。メモリ使用量を監視し、サーキットブレーカーを実装する。
結論
これで、数百万ページまでスケールする分散クローリングの青写真ができました。分散システムを支えるウェブクローリングの基礎について理解を深めるには、包括的なウェブクローラーの概要をお読みください。
アーキテクチャは単純だが、残酷な真実は90%のチームが分散ウェブクローリングシステムの検知防止の複雑さを過小評価しているために失敗しているということだ。何千ものプロキシを管理し、フィンガープリントを回転させ、CAPTCHAを処理することはフルタイムのエンジニアリングの悪夢となり、価値あるデータの抽出から注意をそらすことになる。
これこそが、Bright Data の Web Unlocker API が存在する理由です。毎週壊れるプロキシインフラを何ヶ月もかけて構築する代わりに、分散ワーカーは Web Unlocker の 99% 以上の成功率の API を通してリクエストをルーティングするだけです。
プロキシ管理も、フィンガープリントのローテーションも、CAPTCHAの解決も必要ありません。エンジニアリングチームはビジネスロジックの構築に集中し、Bright Dataはボット対策システムとの駆け引きを処理します。
計算するのは簡単です。自家製のアンチディテクションには何カ月ものエンジニアリング時間と継続的なメンテナンスの頭痛の種がかかりますが、Web Unlocker はエンタープライズグレードの信頼性を提供しながら、その何分の一かのコストで済みます。だから、車輪の再発明をやめて、洞察の抽出を始めましょう。今すぐ無料の Bright Data アカウントを取得して、分散型クローラーをメンテナンスの負担から競争上の優位に変えましょう。





