

このガイドでは、次について説明します。
- Cloudflareとは
- CloudflareのWAFソリューションでスクリプトのスクレイピングがやりにくくなる理由
- オールインワンソリューションを使用してCloudflare WAFを迂回する方法
- Cloudflareで主に利用されているボット対策への対処方法
さっそく始めましょう!
Cloudflareとは?
Cloudflareは、Web上で最大級のネットワークを運営するWebインフラよびセキュリティ企業です。Webサイトをより高速かつ安全にするための包括的なサービス一式を提供しています。
基本的には、Cloudflareは主にCDN(コンテンツ配信ネットワーク)として機能し、サイトのコンテンツをグローバルネットワークにキャッシュして読み込み時間を改善し、待ち時間を短縮します。さらに、DDoS(分散型サービス拒否)保護、WAF(Webアプリケーションファイアウォール)、ボット管理、DNSサービスなどの機能も提供しています。
Cloudflareのネットワークと統合することで、サイトのセキュリティを迅速に強化し、パフォーマンスを最適化できます。これにより、Cloudflareは世界中の何百万ものWebサイトにとって頼れるソリューションになりました。
Cloudflare WAFの概要
WAFはWebアプリケーションファイアウォールの略で、Webアプリケーションとインターネットの間のHTTPトラフィックをフィルタリングして監視するセキュリティシステムです。DDoS、クロスサイトスクリプティング(XSS)、SQLインジェクション、その他の悪意のあるアクティビティなどの攻撃からWebサイトを保護するのに役立ちます。
その中でもCloudflare WAFは、世界で最も広く使用されているWAFソリューションの1つです。その人気の理由は、CDNとしてCloudflareが広く採用されていることにあります。すでにCloudflare上にあるWebサイトの場合、WAFをデフォルト設定で有効にするには、数回クリックするだけでOKです。
Cloudflare WAFが実装している主なアンチボットテクノロジーとテクニックには、以下のようなものがあります。
- レート制限:DDoS攻撃を阻止し、ブルートフォース攻撃を防ぐために、一定時間内に単一のIPアドレスから送信できるリクエストの数を制限します。
- JavaScriptチャレンジ:訪問者がJavaScriptを実行できるか確認します。(実在するユーザーであれば一般的に実行できます)
- Turnstile CAPTCHA:ボットが疑われるものに対して、CAPTCHAを表示します。
- IPレピュテーション:レピュテーションデータベースを保守して、疑わしいIPアドレスを直ちにブロックします。
- 行動分析:訪問者の行動を監視して、自動化されたパターンや異常なアクティビティを検出します。
Cloudflare WAFで保護されたサイトでは、通常、自動リクエストをブロックするために1つ以上のアンチボットソリューションが採用されています。これらの防御の組み合わせが、Cloudflareで保護されたサイトのスクレイピングを特に難しくしているのです。
サイトのスクレイピング時にCloudflareブロックを迂回する最初のソリューション
Cloudflareで保護されたサイトでWebスクレイピングする際の、最初のアプローチに最適なソリューションとアイデアを見つけましょう。
Cloudflareの完全な迂回
CloudflareはCDNの役割を果たすことをお忘れなく。つまり、Cloudflareはサイトのコンテンツをキャッシングし、地理的に分散した複数のサーバーから配信します。そのため、Cloudflare経由で配信されたサイトには通常、CDNネットワーク内のサーバーを介してのみアクセスできます。
さて、CDNの背後にあるサイトサーバーのIPアドレスを発見できたとしたらどうでしょうか。そうすれば、Cloudflareを完全に迂回しながらサイトを操作できるようになります。結局のところ、Cloudflareはネットワークを通過するリクエストのみを審査できるからです。
これは、SecurityTrailsのようなDNS履歴参照ツールを使用して、元のサーバーのIPアドレスを明らかにする過去のDNSレコードを特定することで可能です。IPを取得したら、Cloudflareを迂回しながら直接サーバーにリクエストを送信してみることもできます。
問題は、サーバーがCloudflareのIP範囲からのリクエストのみを受け付けるように追加設定されている可能性があることです。そうなると、ブロックされずに直接サイトに接続することはほぼ不可能です。さらに、元のサーバーIPを見つけることは非常に難しく、可能性は低いでしょう。
無料のCloudflare解決ツール
オンラインでは、Cloudflareを迂回するように設計された無料のオープンソースライブラリがいくつか見つかります。特に人気があるのは、次のようなツールです。
- Cloudscraper:Cloudflareのアンチボットチャレンジを処理するPythonモジュール。
- Cfscrape:Cloudflareのアンチボットページを迂回するための軽量PHPモジュール。
- Humanoid:CloudflareのアンチボットJavaScriptチャレンジを迂回するためのNode.jsパッケージ。
これらの解決策は一時的には有効かもしれませんが、アンチスクレイピングはいたちごっこであることを忘れてはいけません。Cloudflareは保護メカニズムを継続的に更新しているため、今日機能している方法が明日も有効であるとは限りません。
ご想像通り、これらのプロジェクトのほとんどは何年もアップデートされていません。Cloudflareのアップデートに追いつくための際限のない戦いに、開発者が匙を投げてしまったからです。
有料のCloudflare解決ツール
Cloudflareで保護されたサイトをスクレイピングする最善の解決策は、ほとんどの場合、有料の製品を使用することです。有料であることで、スクレイピング分野の専門家による定期的な更新が可能になり、Cloudflareの防御に対抗する高い信頼性が維持されます。
それに加え、さらに、Bright Dataのような一流のプロバイダーは、24時間年中無休のテクニカルサポートも提供しており、あらゆる問題の解決を支援しています。プロフェッショナルなCloudflareスクレイピングソリューションをお探しの場合は、当社のスクレイピングブラウザをお試しください。
クラウドベースのスケーラブルなGUIブラウザとして、Playwright、Puppeteer、Selenium、その他のヘッドレスブラウザのライブラリと統合できます。Cloudflareに対する高い効果を保証するために、IPローテーション、CAPTCHA解決機能、ユーザーエージェントローテーションなどの機能が含まれています。
Cloudflareで保護されたサイトのスクレイピング:アンチボットを迂回するためのDIYアプローチ
Cloudflareを解決するのは困難です。特に、有料のオールインワンソリューションを使用しないのであれば。その困難な道を歩みたいのであれば、Cloudflareのボット対抗策をすべて考慮し、それを乗り越える方法を見つける必要があります。
このセクションでは、Cloudflareをすり抜け、WAFで保護されたサイトをスクレイピングするのに最も役立つ高レベルのテクニックをいくつか紹介します。詳細な手順については、「Cloudflareを迂回する方法」のガイドをご覧ください。
では始めましょう!
JavaScriptレンダリング
Cloudflareがボットの検出に使用する最も一般的な手法の1つは、JavaScriptチャレンジです。これらはWebページに埋め込まれたJavaScriptスクリプトで、レンダリング時にブラウザによって実行されます。ここでは、訪問者がボットである可能性を判断するために特定のチェックが行われます:

これらのチャレンジの結果に基づいてCloudflareがボットを疑った場合、CAPTCHAが表示されます。それがなければ、ページのコンテンツにアクセスできるでしょう。
したがって、Cloudflareで保護されているページをターゲットにするには、Playwright、Selenium、Puppeteerなどのブラウザ自動化ツールを使用する必要があります。これらのツールを使用すると、通常のユーザーのようにWebページとやりとりするようブラウザに指示することができます。詳細については、「Playwrightを使用したWebスクレイピング」のガイドをご覧ください。
問題は、ヘッドレスブラウザはアンチボット検出システムにさらされる可能性のあるデフォルト設定を使用していることです。これを迂回するには、ヘッドレスブラウザの活動を隠すのに役立つ、Playwright StealthやPuppeteer Stealth(Puppeteer Extra経由)などのライブラリを使用する必要があります。
CAPTCHA解決
Cloudflareにボットであると判断された場合、Turnstile CAPTCHAによるブロックが試みられます。

構成によっては、CAPTCHAは上のようなクリックベースの簡単なテストであったり、下のようなより複雑なパズルであったりします。

CAPTCHA解決の自動化は簡単ではありません。というのも、CAPTCHAはボットと人間の区別を念頭に設計されたテストだからです。お使いのヘッドレスブラウザでこのような問題が発生した場合は、「PythonでCAPTCHAを迂回する」のガイドで要約されているテクニックをお試しください。
スクレイピングスクリプトで使用している技術に関係なく機能する、より信頼性の高いソリューションをお探しなら、Bright DataのCloudflare Turnstile解決ツールをご検討ください。これにより、CloudflareのTurnstile CAPTCHAが迅速かつ自動的に解決されます。
レート制限迂回
短期間に同じIPから多数のリクエストを行うと、Cloudflareは一時的または永久にそのIPを禁止する可能性があります。こうなるとスクレイピング操作が停止し、IPレピュテーションが損なわれるため、問題となります。
DDoS攻撃や望ましくない自動リクエストを阻止するために使用される上記の手法は、レート制限と呼ばれます。IPは接続中のネットワークに関連付けられているため、簡単に変更できません。IPローテーションを実装して禁止を迂回する唯一の効果的な方法は、プロキシサービスを使用することです。
住宅用プロキシのようなソリューションを使用すると、スクリプトのリクエストが特定の場所にある現実のデバイスから送信されているように見せかけることができます。当社の住宅用プロキシ製品の詳細をご覧ください。
ブラウザスプーフィング
ブラウザは、ヘッドレスモードであっても大量のリソースを消費します。そのため、ブラウザの自動化ツールを使用して、Cloudflareで保護されたWebサイトを対象にスクレイピング操作を構築すると、リソースを大量に消費するプロセスとなる可能性があります。その場合、複数のサーバーと複雑なアーキテクチャが必要になる可能性があります。
そのような手間を避けるために、また、CloudflareのWAFの攻撃性が控えめに設定されている場合には、別のアプローチを試すこともできます。それは、実際のブラウザを模倣するHTTPクライアントから自動リクエストを行うものです。これはブラウザスプーフィングとして知られています。
目標は、HTTPリクエストを通常のブラウザからのリクエストにできるだけ近づけることです。User-Agentなどの特定のHTTPヘッダーを設定することでこれを達成できます。詳細については、「Webスクレイピングに最適なユーザーエージェント」のガイドをご覧ください。
もっと複雑なシナリオでは、そのトリックだけでは不十分かもしれません。TLSフィンガープリントにより、CloudflareはこうしたリクエストをブラウザではなくHTTPクライアントから送信されたものとして引き続き検出できます。
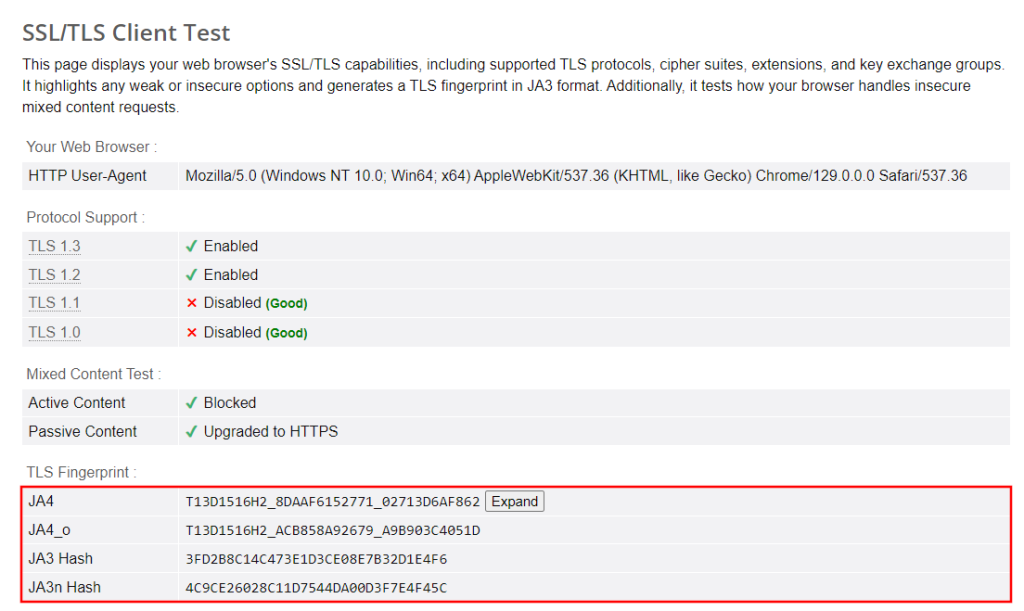
この概念に馴染みがない方のために説明すると、TLSフィンガープリンティングとは、TLS上で安全な接続を確立する方法に基づいてクライアントを識別するものです。ブラウザのTLSフィンガープリントの複製には、当社の専用チュートリアルで説明されているように、curl-impersonateのようなHTTPクライアントを使用できます。
まとめ
この記事では、Cloudflareで保護されたサイトをスクレイピングするためのヒントとコツをいくつかご紹介しました。Cloudflareは市場で最も人気の高いCDNサービスで、高度なアンチボットソリューションも提供しています。ここで学んだように、Cloudflareのスクレイピング対策を迂回することは簡単ではありませんが、不可能ではありません。
どのような方法を選択するにしても、次のようなプロフェッショナルで迅速かつ信頼性の高いスクレイピングソリューションを利用すれば、すべてがスムーズになることを心に留めておいてください。
- Web Unlocker:レート制限、フィンガープリント、その他のアンチボット制限を自律的に迂回し、パブリックWebデータのシームレスな収集を可能にします。
- CAPTCHA解決ツール:さまざまな種類のCAPTCHAを自動的に解決するので、手動操作なしで任意のWebページのコンテンツにアクセスしたり、インタラクションを完了することができます。
- スクレイピングブラウザ:Webサイトのブロック解除プロセスを自動化しながら、動的Webデータをスクレイピングできる完全ホストブラウザ。
Bright Dataの豊富なスクレイピングツールで、Cloudflareで保護されたサイトからのデータ抽出がかつてないほど簡単になりました。
今すぐ登録して、Bright Dataのどのソリューションがニーズに最適かを確認してください。今すぐ無料トライアルを開始しましょう!




