

このチュートリアルでは、以下のことを学びます:
- クラウドフレアとは
- そのWAFの仕組みに迫る。
- 技術的な観点から見たボット対策システムの仕組み。
- 標準的な自動化ツールを使ってCloudflareで保護されたサイトをターゲットにするとどうなるか。
- Cloudflareをバイパスするためのハイレベルなアプローチ。
- PythonでCloudflareのヒューマンチェックを回避する方法。
- Cloudflareを大規模にバイパスする方法。
さあ、飛び込もう!
Cloudflareとは?
Cloudflareは、ウェブ上で最大級のネットワークを運営するウェブインフラおよびセキュリティ企業である。ウェブサイトをより速く、より安全にするために設計された包括的なサービス群を提供している。
Cloudflareは、主にCDN(コンテンツ・デリバリー・ネットワーク)として機能し、サイトのコンテンツをグローバルネットワーク上にキャッシュすることで、ロード時間の短縮とレイテンシーの削減を実現します。その上、DDoS(分散型サービス拒否)保護、WAF(ウェブアプリケーションファイアウォール)、ボット管理、DNSサービスなどの機能も提供しています。
Cloudflareのネットワークと統合することで、サイトは強化されたセキュリティと最適化されたパフォーマンスを迅速に得ることができます。これにより、Cloudflareは世界中の何百万ものウェブサイトが利用するソリューションとなりました。
Cloudflareのアンチボット機構を理解する
Cloudflareの人気の理由のひとつは、WAF(Web Application Firewall)にある。これは、そのグローバルネットワークを通じて提供されるあらゆるウェブページで有効にすることができます。詳細には、スクレイパー、望ましくないクローラー、ボット全般に対する最も効果的なソリューションの1つです。
具体的には、Cloudflare WAFはお客様のウェブアプリケーションの前に設置されます。このWAFは、受信リクエストをリアルタイムで検査・フィルタリングし、攻撃や不要なトラフィックがサーバーに到達したり、ウェブページにアクセスしたりする前に阻止します。
多層防御戦略の一環として、Cloudflare WAFは独自のアルゴリズムを用いて悪意のあるボットを検知・ブロックします。これらのアルゴリズムは、以下のような受信トラフィックの特性を分析します:
- TLSフィンガープリント:HTTPクライアントやブラウザがどのようにTLSハンドシェイクを行うかを検査する。提供される暗号スイート、ネゴシエーションの順序、その他の低レベルの特徴などの詳細を調べます。ボットや非標準的なクライアントは、しばしばブラウザらしくないTLSシグネチャーを持っていることがあります。
- HTTPリクエストの詳細:HTTPヘッダー、クッキー、ユーザーエージェント文字列、その他の側面を調べます。ボットは、実際のブラウザで使用されているものとは異なるデフォルト設定や疑わしい設定を再利用することがよくあります。
- JavaScriptフィンガープリント:クライアントのブラウザでJavaScriptを実行し、環境に関する詳細な情報を収集します。これには、正確なブラウザのバージョン、オペレーティングシステム、インストールされているフォントや拡張機能、さらには微妙なハードウェアの特性などが含まれます。これらのデータポイントはフィンガープリントを形成し、実際のユーザーと自動スクリプトを区別するのに役立ちます。
- 行動分析:自動化されたトラフィックの最も強力な指標の1つは、不自然な挙動です。Cloudflareは、迅速なリクエスト、マウス操作の欠如、同一のクリックパス、アイドル時間などのパターンを監視します。機械学習を使用して、閲覧行動が人間とボットのどちらに一致するかを判断します。これは最も複雑なボット対策技術の1つです。
Cloudflareは通常、2種類の人的検証方法を提供しています:
- 人間検証の課題を常に示す
- 自動化された人間による検証チャレンジ(疑わしい活動が検出された場合のみ)
以下、両方の選択肢を探ってみよう!
モード1:常に人間検証チャレンジを表示する
最初のモードはあまり一般的ではないが、より強力な保護を提供する。この考え方は、サイトへの最初のアクセス時に常に人間による認証を要求することである。
例えば、この記事を書いている現在、StackOverflowはこのように動作している。シークレットモード(クッキーを使用しない新しいセッションを確保するため)でアクセスしてみると、たとえあなたが本当の人間であっても、Cloudflare Turnstileと呼ばれるCAPTCHAが表示されます:
注:この記事をお読みになる頃には、StackOverflowのボット対策は変更されているか、別の方法で動作しているかもしれません。
この場合、自動化スクリプトを作成するのであれば、唯一の選択肢は、人間のような方法でTurnstile CAPTCHAインタラクションを自動化することです。Turnstileは、舞台裏での行動分析やその他の独自のチェックに依存しているため、これは特に難しい。このようにして、ワンクリックであなたが人間であることを確認できるのだ。
モード#2:自動化された人間検証への挑戦
このモードでは、Cloudflareはリクエストがボットからのものであると疑われる場合にのみチャレンジを発行します。Cloudflareは、クライアントが正当なユーザーであることを確認するために、ブラウザ内で見えないように実行されるJavaScriptチャレンジを提示します:
このプロセスはシームレスで、通常のブラウザを使用している人間であれば、通常は自動的に完了する。パスした場合は、中断することなくサイトをナビゲートし続けることができます。これは通常のユーザーにとって最小限の混乱しか引き起こさないため、圧倒的に一般的なCloudflareモードです。
しかし、JavaScriptのチャレンジが失敗した場合(クライアントがボットである可能性が高いとCloudflareが判断した場合)、人間による認証のためにTurnstile CAPTCHAを表示するようにエスカレーションします:
これで、前のシナリオに戻ったことになる。このモードでは、人間のような指紋を提示するボットを使えば、最初の認証をパスするのに十分かもしれない。それでも、もしCAPTCHAが表示されたら、それに対処する方法が必要だ。
技術的観点から見たCloudflareの仕組みの詳細
ブラウザのシークニートモードでNopeCHAのCloudflareテストページを開いてみてください。このページはCloudflare WAFによって保護されているため、自動化されたJavaScriptベースの検証プロセスが直ちに開始されます。
バックグラウンドでは、一連のPOSTリクエストがCloudflareのエンドポイントと交換され、そのペイロード内に暗号化されたデータが送信されます:

これらのペイロードの正確な内容は公表されていません。しかし、Cloudflareの既知の検出戦略に基づけば、これらのペイロードには数種類のブラウザとシステムのフィンガープリントが含まれていると考えるのが妥当です。
あなたのブラウザとハードウェアの設定は正当なので、このチャレンジは自動的にパスするはずです。そうでない場合は、必要なユーザー操作(チェックボックスのクリックなど)を行ってください。
検証が成功すると、Cloudflareサーバーはcf_clearanceクッキーを発行し、この特定のユーザーセッションがウェブサイトへのアクセスを許可されていることを示します:
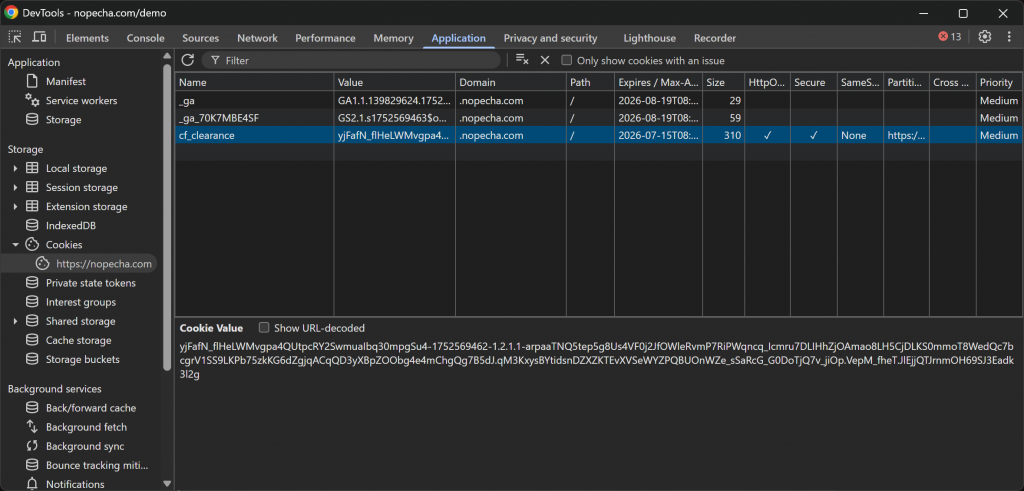
この場合、クッキーは 15 日間有効です。このことは、理論的には、自動化されたボットがターゲットサイトにアクセスするために、再度検証プロセスを解決することなく、2、3 週間再利用できることを意味します。
Cloudflareで保護されたサイトに接続しようとすると起こること
では、自動ボットがCloudflareで保護されたページを訪問しようとしたときに実際に何が起こるかを見てみましょう。
注:以下のサンプルスクリプトはPythonで書かれていますが、プログラミング言語、HTTPクライアント、ブラウザ自動化ツールに関係なく、同じ原則が適用されます。
このデモでは、ScrapingCourseのCloudflareチャレンジ・ページを使用する:
これは、Cloudflareの検証に合格する必要があるサイトです。チャレンジが成功すると、以下のページが表示されます:
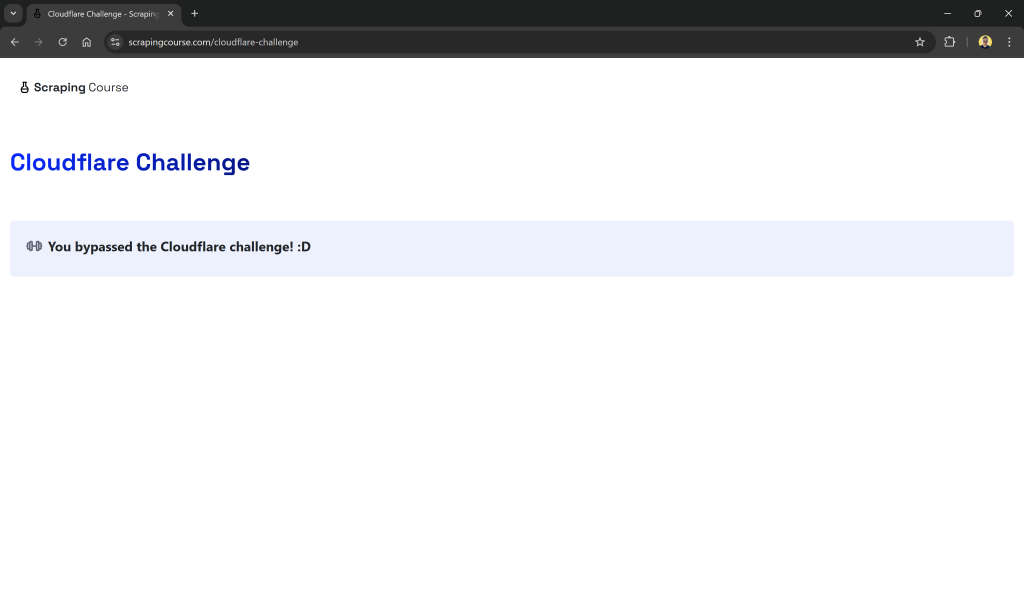
以下の例では、取得したページ・コンテンツに文字列が含まれているかどうかを具体的にチェックする:
"You bypassed the Cloudflare challenge! :D"これにより、検証プロセスが正常に完了したことが確認されます。
基本的なテストとして、上記のCloudflareで保護されたページに2つの異なるアプローチでアクセスした場合に何が起こるかを見てみましょう:
- RequestsのようなHTTPクライアントでは
- Playwrightのようなブラウザ自動化ツールを使って
Cloudflareで保護されたページをリクエストの対象とする
RequestがCloudflareの人的検証を自動的に回避できるかどうかを確認してください:
# pip install requests
import requests
# Connect to the target page
response = requests.get(
"https://www.scrapingcourse.com/cloudflare-challenge"
)
# Raise exceptions in case of HTTP error status codes
response.raise_for_status()
# Verify if you received the success page
html = response.text
print("Cloudflare Bypassed:", "You bypassed the Cloudflare challenge! :D" in html) スクリプトは最後のprint()文にさえ到達しないことに注意してください。その代わりに
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://www.scrapingcourse.com/cloudflare-challengeご覧のように、Cloudflareは自動化されたスクリプトからのリクエストと認識し、403 Forbiddenレスポンスでブロックしました。
PlaywrightでCloudflareで保護されたページを閲覧する
Playwrightのようなブラウザ自動化ソリューションを使ってみよう:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Go to the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# Wait for the desired text to be on the page
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)このスクリプトは、Chromiumブラウザにターゲット・ページにアクセスするよう指示する。その後、ロケータを使用して、必要なテキストを含む要素がページに表示されるかどうかをチェックし、自動的に待機する(デフォルトでは、Playwrightは最大30秒待機する)。
必要なインストール・コマンドを実行し、上記のスクリプトを実行する。以下の出力が表示されます:
Cloudflare Bypassed: Falseheadedモード(headless=False)で実行すると、スクリプトがCloudflareの検証ページでスタックすることがわかります。これはTurnstile CAPTCHAを表示し、手動で解決されるのを待ちます:

注: Turnstileチェックボックスのクリックを自動化しようとすると、検証は失敗します。これは、Cloudflareが、それが自動化されたものであり、実際の人間によるインタラクションではないことを検知するのに十分賢いためです。
Cloudflareを回避するためのハイレベルなアプローチ
自動化されたスクリプトでCloudflareの保護をバイパスするために使用できる3つのアプローチをご覧ください。
アプローチ#1: Cloudflareを完全にバイパスする
CloudflareはCDNとして機能し、地理的に分散した複数のサーバーにサイトのコンテンツをキャッシュし、配信することを忘れないでください。つまり、Cloudflare経由で配信されるサイトは、通常CDNネットワーク内のサーバーからのみアクセス可能です。
ここで、CDNの背後にあるサイトサーバーのIPアドレスを発見できたとしよう。その結果、Cloudflareを完全に迂回しながらサイトとやりとりできることになる。結局のところ、Cloudflareはそのネットワークを通過するリクエストしか評価できない。
これは、SecurityTrailsのようなDNS履歴検索ツールを使って、元のサーバーのIPアドレスを明らかにする過去のDNSレコードを特定することで可能です。一度IPを取得すれば、Cloudflareを回避してサーバに直接リクエストを送信することができます。
問題は、サーバーがCloudflareのIPレンジからのリクエストしか受け付けないように追加設定をしている可能性があることです。そうなると、ブロックされずにサイトに直接接続することはほぼ不可能になります。さらに、元のサーバーIPをうまく見つけるのはかなり難しく、可能性は低い。
アプローチその2:Cloudflareソルバーに頼る
オンラインでは、Cloudflareをバイパスするために設計されたフリーでオープンソースのライブラリをいくつか見つけることができます。代表的なものには以下のようなものがある:
- cloudscraper:Cloudflareのボット対策の課題を処理するPythonモジュール。
- Cfscrape:Cloudflareのアンチボットページをバイパスする軽量PHPモジュール。
- Humanoid:Cloudflareのボット対策JavaScript課題を回避するNode.jsパッケージ。
驚くなかれ、これらのプロジェクトのほとんどは何年も更新を受けていない。Cloudflareのアップデートに追いつくのに苦労し続けたため、開発者が諦めてしまったからだ。そのため、これらのツールは一般的に長くは使えない。
アプローチ#3:Cloudflareバイパス機能を備えた自動化ソリューションを使用する
ほとんどの場合、Cloudflareで保護されたサイトをスクレイピングするための最良のソリューションは、オールインワンの自動化ソリューションを使用することです。効果的であるためには、これらのライブラリやオンラインサービスは少なくとも以下の機能を提供する必要がある:
- JavaScriptレンダリングにより、CloudflareのJavaScriptチャレンジが適切に実行されます。
- TLS、HTTPヘッダー、ブラウザのフィンガープリントを偽装することで、実際のユーザーをシミュレートし、検知を回避する。
- TurnstileのCAPTCHAを解決する機能で、Cloudflareの人間認証が表示されたときに対応します。
- Bスプライン曲線に沿ってマウスを動かすなど、人間のようなインタラクションをシミュレートし、自然なユーザー行動を模倣。
さらに、プレミアムソリューションには、IPアドレスをローテーションし、ブロックされるリスクを軽減するための統合プロキシネットワークが含まれていることが多い。
以下の2つの章では、オープンソースと主にプレミアムソリューションの両方を実際に見ていく!
PythonでCloudflareのヒューマンチェックを回避する方法
Cloudflareをバイパスすると主張するオープンソースのソリューションのほとんどは、限られた期間しかバイパスできない。これは、本質的に猫とネズミのゲームであり、オープンソースの性質(Cloudflareのエンジニアが簡単にコードを研究できる)が助けにならないからです。
そのため、かつて機能した多くのツール(Puppeteer Stealthなど)がもはや目標を達成できないのは当然のことだ。それでも、この記事を書いている時点では、Cloudflareの保護を実際に回避できるソリューションが2つある:
- Camoufox:ボット検出を回避し、ウェブスクレイピングを可能にするために設計された、カスタマイズされたFirefoxビルドに基づくオープンソースのアンチ検出Pythonブラウザ。
- SeleniumBase:高度なウェブ自動化のためのオープンソースのプロ仕様のPythonツールキット。
両者がScrapingCourseのCloudflareチャレンジ・ページに対してどのように機能するか見てみよう!
CamoufoxでClouflareのターンテーブルを迂回する
まず、CamoufoxをPythonプロジェクトにインストールする:
pip install camoufox[geoip]次に、必要な追加依存関係を取得する:
python -m camoufox fetch詳しくは、オフィシャルインストールガイドをご参照ください。
Camoufox PythonライブラリはPlaywrightの上に構築されているので、そのAPIは非常に似ている。ターゲットサイトにアクセスし、Turnstileチャレンジが表示されるのを待ち、以下のロジックを使用して(実際に表示された場合)それを処理します:
# pip install camoufox[geoip]
# python -m camoufox fetch
from camoufox.sync_api import Camoufox
from playwright.sync_api import TimeoutError
with Camoufox(
headless=False,
humanize=True,
window=(1280, 720) # So that the Turnstile checkbox is on coordinate (210, 290)
) as browser:
page = browser.new_page()
# Visit the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
# Wait for the Cloudflare Turnstile to appear and load
page.wait_for_load_state(state="domcontentloaded")
page.wait_for_load_state("networkidle")
page.wait_for_timeout(5000) # 5 seconds
# Ckick the Turnstile checkbox (if it is present)
page.mouse.click(210, 290)
try:
# Wait for the desired text to appear
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
# The text did not appear
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)Turnstileの処理ロジックは少しトリッキーであることに注意してください。これは、1280×720のブラウザウィンドウ上で、ターンスタイルのチェックボックスがほぼ(210, 290)の座標に表示されるという仮定に依存しています。
上のスクリプトを実行すると、次のような結果が得られる:
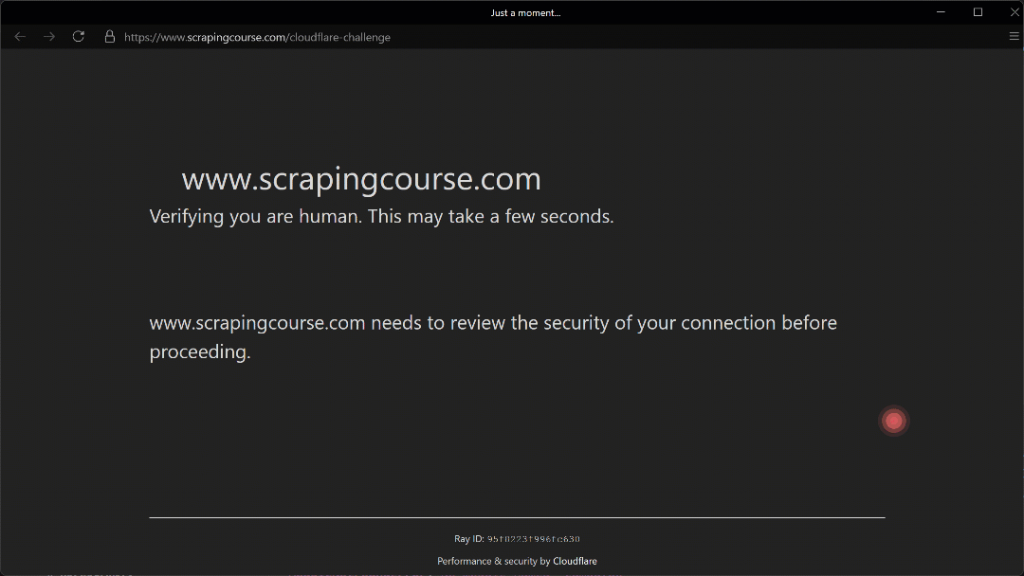
Humanize=Trueパラメータのおかげで、(210, 290)座標に向かう自動化されたマウスの動きがリアルに見える。
このように、Camoufoxはチェックボックスをクリックすることに成功した。その結果、ターミナルでは次のように出力される:
Cloudflare Bypassed: Trueミッション完了!
SeleniumBaseでClouflareを回避する
SeleniumBaseをインストールする:
pip install seleniumbaseそして、それを使ってCloudflareを処理する:
# pip install seleniumbase
from seleniumbase import Driver
from seleniumbase.common.exceptions import TextNotVisibleException
# Launch in undetected-chromedriver mode
driver = Driver(uc=True)
# Visit the target page
url = "https://www.scrapingcourse.com/cloudflare-challenge"
driver.uc_open_with_reconnect(url, 4)
# Click the Turnstile (if it is present) and reload the page
driver.uc_gui_click_captcha()
try:
# Wait for the desired text to appear
driver.wait_for_text("You bypassed the Cloudflare challenge! :D", "main")
challenge_bypassed = True
except TextNotVisibleException:
# The text did not appear
challenge_bypassed = False
# Close the browser and release its resources
driver.quit()
print("Cloudflare Bypassed:", challenge_bypassed) uc=Trueモード (これはフードの下でundetected-chromedriver を使用します) では、SeleniumBase は専用の uc_gui_click_captcha()メソッドを利用して、Turnstile CAPTCHA を処理することができます。つまり、今回はカスタムクリックロジックは必要ありません。
スクリプトを実行すると、こう表示されるはずだ:
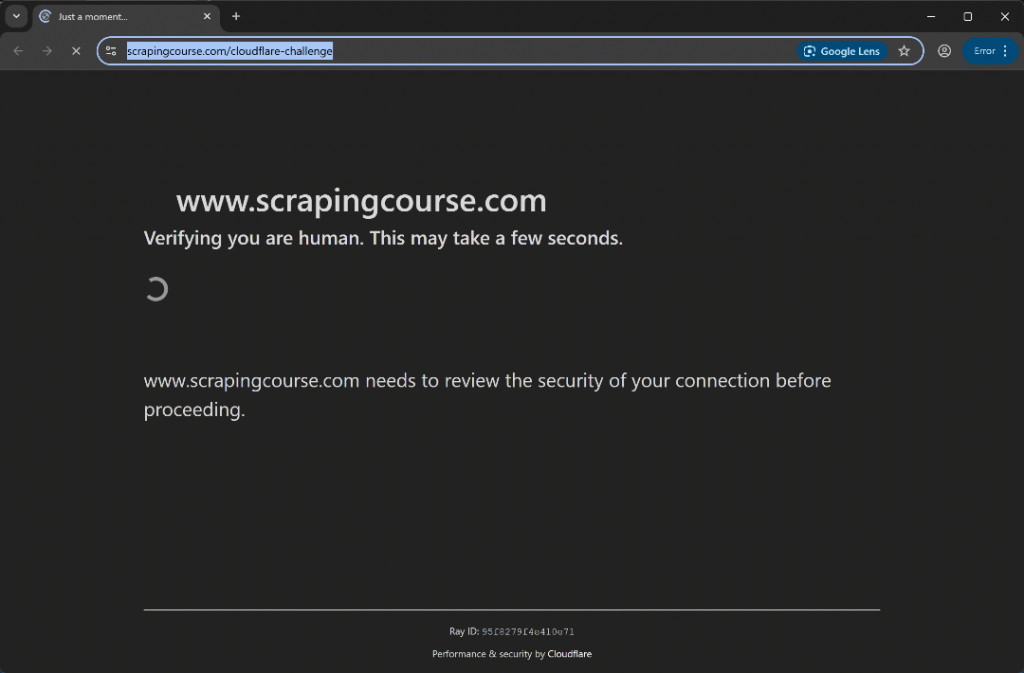
今回、自動化スクリプトはTurnstile CAPTCHAをトリガーすることなく、最初の検証段階をバイパスしている。いずれにせよ、uc_gui_click_captcha()メソッドは正常に処理できたでしょう。これはUCモードのおかげです。UCモードについてはSeleniumBaseスクレイピングガイドを参照してください。
ほらね!Cloudflareは再びバイパスされた。
Cloudflareを大規模にバイパスする方法
先に紹介した2つのライブラリは、単純なオートメーション・スクリプトには有効だが、3つの大きな欠点がある:
- 高い確率で効果的な結果を得るためには、ブラウザをヘッディングモードで実行する必要がある。これは多くのシステムリソースを消費し、スケーラビリティをより困難にする。
- これらのソリューションは一貫性がなく、Cloudflareが検出ロジックを更新すると一時的に動作しなくなる可能性があります。これらのソリューションはコミュニティが保守しているため、アップデートのリリースには数日から数週間かかることもあります。
- 公式サポートはない。オンラインリソースやコミュニティのヘルプに頼るしかない。
これらの理由から、Cloudflareバイパス機能を持つオープンソースライブラリは、プロダクションプロジェクトにはお勧めできません。よりスケーラブルで一貫した結果を得るためには、そして24時間365日対応のサポートチームのバックアップを得るためには、 Bright Dataが提供するようなプレミアム製品が必要です。
具体的には、以下の2つの解決策に焦点を当てる:
- ウェブアンロッカー:あらゆるサイトから HTML を取得するためのアンチボット・バイパス機能をすべて備えた、オールインワンのスクレイピング・エンドポイント。
- ブラウザAPI:あらゆる自動化ワークフローをサポートするために構築された、無限に拡張可能なクラウドブラウザ。Puppeteer、Selenium、Playwright、その他あらゆるブラウザ自動化ツールと統合できます。高度なフィンガープリント管理、ビルトインCAPTCHA解決、自動プロキシローテーションが含まれています。
Pythonでこれらのツールを自動化スクリプトに統合する方法をご覧ください(ただし、どのプログラミング言語にも対応しています)!
Web UnlockerでCloudflareを回避する
始める前に、公式ガイドに従って、Bright DataアカウントにWeb Unlockerを無料でセットアップしてください。また、Web Unlocker エンドポイントへのリクエストを認証するためのBright Data API キーを生成する必要があります。
ここでは、Web Unlockerゾーンの名前をweb_unlockerとします。
上記の手順が完了したら、この記事で使用したターゲットページに対してWeb Unlockerをテストしてください:
# pip install requests
import requests
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
data = {
"zone": "web_unlocker", # Replace with the name of your Web Unlocker zone
"url": "https://www.scrapingcourse.com/cloudflare-challenge",
"format": "raw"
}
# Perform a request to the Web Unlocker endpoint
response = requests.post(
"https://api.brightdata.com/request",
json=data,
headers=headers
)
# Get the response and check if Cloudflare was bypassed
html = response.text
print("Cloudflare Bypassed:", "You bypassed the Cloudflare challenge! :D" in html)Web UnlockerはCloudflareの検証ウォールの背後にあるページのHTMLコンテンツを返します。特に、html変数には次のようなコンテンツが含まれます:
<!doctype html>
<html lang="en"><head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Cloudflare Challenge - ScrapingCourse.com</title>
<!-- omitted for brevity ... -->
<main class="page-content py-4" id="main-content" data-testid="main-content" data-content="main">
<div class="container" id="content-container" data-testid="content-container" data-content="container">
<div class="cloudflareChallenge">
<h1 id="page-title" class="page-title text-4xl font-bold mb-2 text-left gradient-text highlight gradient-text leading-10" data-testid="page-title" data-content="title">
Cloudflare Challenge
</h1>
<div class="challenge-info bg-[#EDF1FD] rounded-md p-4 mb-8 mt-5" id="challenge-info" data-testid="challenge-info" data-content="challenge-info">
<div class="info-header flex items-center gap-2 pb-2" id="info-header" data-testid="info-header" data-content="info-header">
<img width="25" height="15" src="https://www.scrapingcourse.com/assets/images/challenge.svg" data-testid="challenge-image" data-content="challenge-image">
<h2 class="challenge-title text-xl font-bold" id="challenge-title" data-testid="challenge-title" data-content="challenge-title">
You bypassed the Cloudflare challenge! 😀
</h2>
</div>
</div>
</div>
</div>
</main>
<!-- omitted for brevity ... -->
</html>これはまさに、Cloudflareの人間検証ウォールの背後にあるページのHTMLコンテンツである。したがって、スクリプトの出力がこうなるのは当然だ:
Cloudflare Bypassed: Trueまた、無料トライアルもご利用いただけます!
ブラウザAPIでCloudflareを自動化する
前提として、Bright DataアカウントでBrowser API製品をセットアップします。ゾーンページで、Playwright CDP接続URLをコピーします:
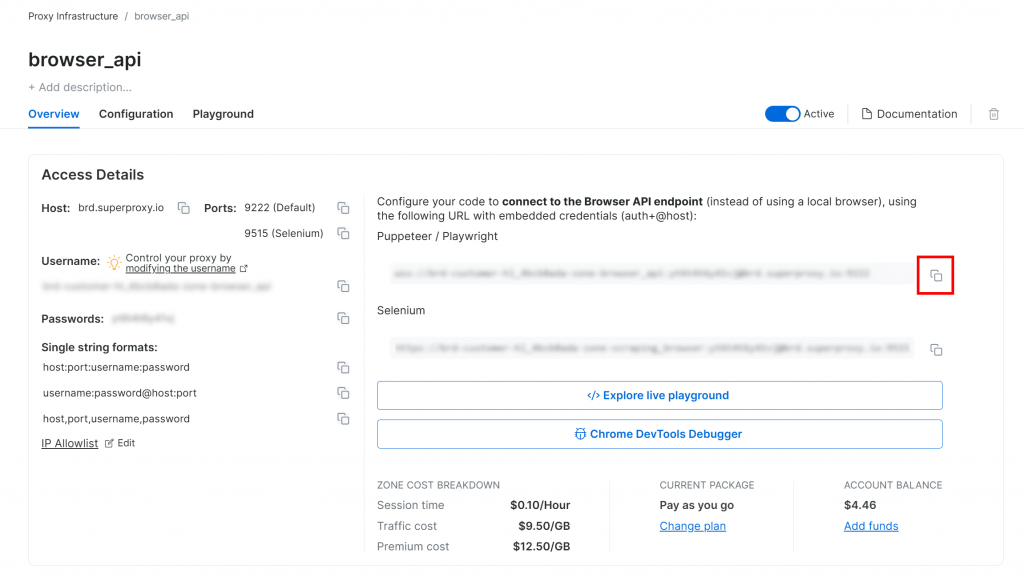
このURLにはあなたの認証情報が含まれ、リモートCDP(Chrome DevTools Protocol)をサポートするブラウザ自動化ソリューションにBright Data Browser APIへの接続を指示することができます。つまり、お客様の自動化ツールは、Bright Dataが管理するリモートホストされたブラウザインスタンス上で動作します。つまり、スケーラビリティとブラウザのメンテナンスはお客様に代わって行われます。
先に示したPlaywrightスクリプトを拡張して、CDP URL経由でBrowser APIに接続します:
# pip install playwright
# python install -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
BRIGHT_DATA_API_CDP_URL = "<YOUR_BRIGHT_DATA_API_CDP_URL>" # Replace with your Browser API Playwright CDP URL
with sync_playwright() as p:
# Connect to the remote Browser API
browser = p.chromium.connect_over_cdp(BRIGHT_DATA_API_CDP_URL)
page = browser.new_page()
# Go to the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# Wait for the desired text to be on the page
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)今回、スクリプトは、Browser APIの高度な機能のおかげで、Cloudflareの検証を回避することに成功した。ターミナルには次のような出力が表示される:
Cloudflare Bypassed: Trueよくやった!Cloudflareのバイパスはもう問題ありません。
結論
この記事では、Cloudflareがどのように機能するかを学び、自動化ワークフローでCloudflareをバイパスするための実用的なソリューションを探りました。ここで見たように、Cloudflareのスクレイピング防止策を回避することは困難ですが、確かに可能です。
どのようなアプローチを選んでも、プロフェッショナルで迅速かつ信頼性の高いソリューションがあれば、すべてが簡単になります:
- ウェブアンロッカー:レート制限、フィンガープリント、その他のボット対策制限を自動的に回避するエンドポイント。
- ブラウザAPI:あらゆるウェブページとのインタラクションを自動化できる、完全にホストされたブラウザ。
今すぐ無料登録して、ブライトデータのどのソリューションがお客様のニーズに最も適しているかをご確認ください!




