

端的に言えば、不良データとは、様々な理由によりデータ基盤に紛れ込む不完全、不正確、不整合、無関係、または重複したデータを指します。
本記事を読み終える頃には、以下の点が理解できるでしょう:
- 不良データとは何か
- 不良データの様々な種類
- 不良データが発生する原因
- その影響と予防策
それでは、さらに詳しく見ていきましょう:
不良データの異なる種類
データ品質と信頼性は、ビジネス分析からAIモデルトレーニングに至るまで、ほぼ全ての領域で不可欠です。低品質なデータは様々な形態で現れ、それぞれがデータの有用性と完全性に固有の課題を突きつけます。
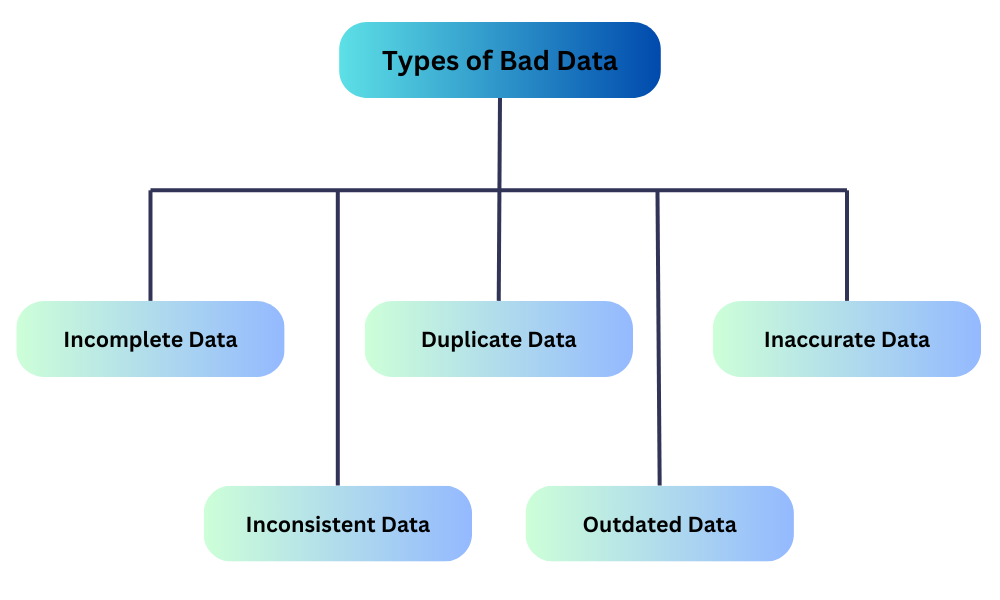
不完全なデータ
不完全データとは、正確な分析に必要な属性、フィールド、またはエントリが1つ以上欠落しているデータセットを指します。この欠落情報はデータセット全体の信頼性を損ない、場合によっては使用不能にさえします。
不完全なデータの一般的な原因には、特定のデータの意図的な省略、未記録の取引、部分的なデータ収集、データ入力時のミス、データ転送時の予期せぬ技術的問題などが含まれます。
例えば、顧客アンケートの連絡先詳細が欠落している状況を考えましょう。これにより、後述のように回答者へのフォローアップが不可能になります。
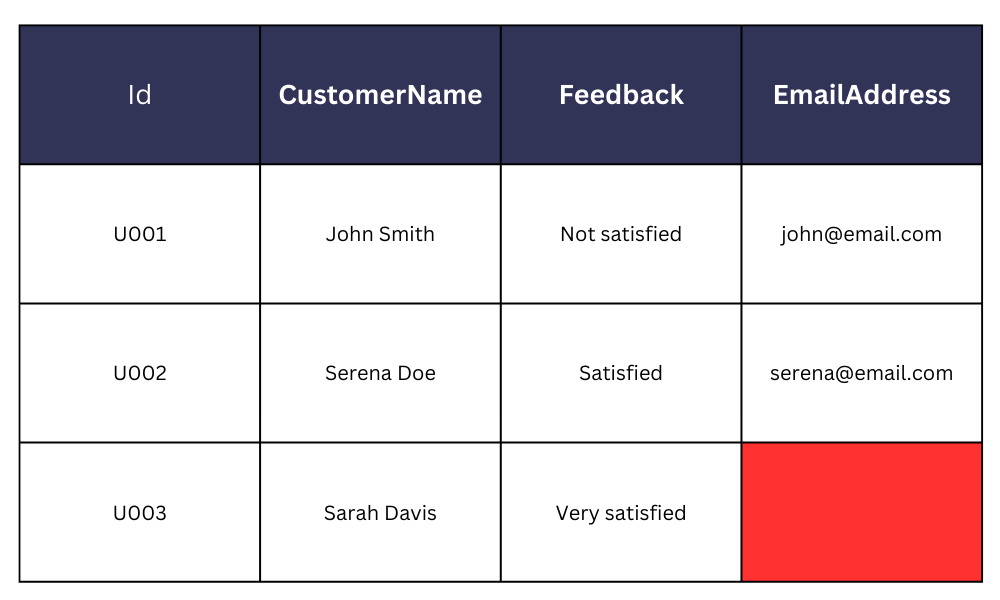
別の例として、アレルギーや既往歴などの重要な情報が欠落した患者の医療記録を含む病院データベースは、命に関わる事態を招く可能性さえあります。
重複データ
重複データとは、同一またはほぼ同一のデータ入力がデータベース内で複数回記録される現象です。この冗長性は分析結果の誤導や誤った結論を招き、場合によってはマージ操作の複雑化やシステム障害を引き起こします。重複データを含むデータセットから導出された統計は、意思決定において信頼性が低く非効率となります。
例:
- 顧客管理(CRM)データベースで同一顧客の記録が複数存在すると、分析後の情報(例:個別顧客数や顧客別売上高)が歪められる。
- 同一製品を異なるSKU番号で保管する在庫管理システムでは、在庫量の推定が不正確になります。
不正確なデータ
1つ以上のデータセットエントリ内に誤った情報が存在する場合、不正確なデータと認識されます。
タイプミスや意図しない見落としによるコードや数値の単純な誤りは、特にハイリスク領域での意思決定にデータが使用される場合、深刻な問題や損失を引き起こすほど重大な影響を及ぼす可能性があります。不正確なデータが存在すること自体が、データセット全体の信頼性と確実性を損ないます。
例:
- 配送先住所を誤って保存した運送会社のデータベースは、荷物を間違った場所(場合によっては別の国)に送付する結果となり、会社と顧客双方に多大な損失と遅延をもたらす可能性があります。
- 人事管理システム(HRMS)に誤った従業員給与情報が含まれる状況では、給与計算の不一致や潜在的な法的問題を引き起こす可能性があります。
不整合なデータ
組織内で異なる担当者やチームが同一データタイプに対し異なる単位や形式を使用することで生じる不整合データは、データ処理時に遭遇する混乱や非効率性の一般的な原因です。データの統一性と連続的な流れを阻害し、データ処理の誤りを招きます。
例:
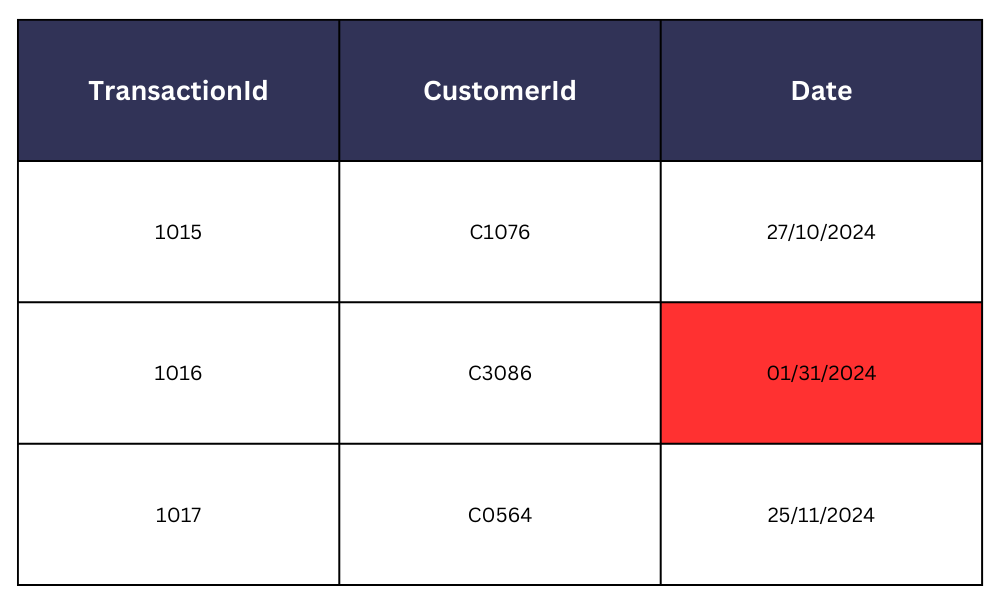
- 例えば、銀行システムにおいて複数のデータ入力で日付形式が不統一(MM/DD/YYYY 対 DD/MM/YYYY)な場合、データ集計や分析時に矛盾や問題を引き起こす可能性があります。
- 同一小売チェーンの2店舗が在庫データを異なる測定単位(ケース数 vs 個数)で入力すると、補充や配送時に混乱を招く可能性があります。
古いデータ
端的に言えば、古いデータとは、もはや最新ではなく、関連性や適用性を失った記録を指します。特に変化の速い分野では、継続的な急速な変化に伴い、古いデータが頻繁に発生します。状況によっては、10年前、1年前、あるいは1ヶ月前のデータでさえ、もはや有用ではなく、誤解を招く可能性さえあります。
例:
- 人は時間の経過とともに新たなアレルギーを発症することがあります。病院が患者のアレルギー情報を記録した古いデータに基づいて薬剤を処方すると、患者の安全が脅かされる可能性があります。
- 不動産会社が古いデータソースから物件情報を掲載している場合、既に売却済みまたは利用不可の物件に対して時間と労力を浪費している可能性があります。これは非生産的であり、会社の評判を損なう恐れがあります。
さらに、非準拠データ、無関係データ、非構造化データ、偏ったデータも不良データの一種であり、データエコシステム全体のデータ品質を損なう可能性があります。これらの様々な不良データタイプを理解することは、その根本原因とビジネスへの脅威を把握し、影響を軽減する戦略を立案するために不可欠です。
不良データの原因
不良データの種類について明確に理解したところで、その原因を理解することが重要です。そうすることで、データセット内でそのような事態が発生するのを防ぐための予防策を講じることができます。
不良データを引き起こす要因には以下のようなものがあります:
- データ入力時の人的ミス:不完全・不正確・重複データに関しては、これが最も一般的な原因であることは言うまでもありません。不十分なトレーニング、細部への注意不足、データ入力プロセスへの誤解、そして主にタイプミスなどの意図しないミスが、最終的に信頼性の低いデータセットや分析時の重大な問題を引き起こします。
- 不適切なデータ入力慣行と基準: 堅牢な基準体系は 、確固たる構造化された慣行を構築する鍵です。 例えば、国などのフィールドに自由入力形式を許可すると、ユーザーが同一の国に対して異なる名称(例:USA、United States、U.S.A.)を入力する可能性があり、同一値に対して非効率的に多様な応答が生じます。このような不整合や混乱は、適切に設定された基準がない結果として発生します。

- 移行時の問題:不良データは 必ずしも手動入力が原因とは限りません。データベース間のデータ移行時に発生することもあります。この問題により、レコードやフィールドの不整合、データ損失、さらにはデータ破損が生じ、長時間の検証と修正が必要になる場合があります。
- データ劣化: 顧客嗜好の変化から市場動向の変動まで、あらゆる 微小な変化が企業データを更新します。データベースがこれらの変化に常に対応して更新されない場合、データは陳腐化し、データ劣化を引き起こします。陳腐化したデータは意思決定や分析において実質的な価値を持たず、使用時には誤った情報を生む要因となります。
- 複数ソースからのデータ統合: 複数ソースからのデータを非効率的に 結合したり、データ統合に不備があると、不正確で一貫性のないデータが生じます。これは、統合される異なるデータソースが、異なる標準、形式、品質レベルでフォーマットされている場合に発生します。
不良データの影響
不良データを含むデータセットを処理すると、最終的な分析結果が危険に晒されます。実際、不良データは特にデータ駆動型ビジネスや分野において、長期的かつ壊滅的な影響をもたらす可能性があります。例えば:
- データ品質の低下は、誤解を招く情報に基づく誤った意思決定や投資のリスクを高め、ビジネスに悪影響を及ぼします。
- 不良データは、資源の浪費や収益の損失を含む多大な財務的コストを引き起こします。不良データが残した影響からの回復には、多額の資金と時間を要する場合があります。
- 不良データの蓄積は、手戻りの必要性増加、機会損失、生産性全体への悪影響を通じて、事業失敗さえ引き起こし得ます。
- 結果として、ビジネスの信頼性と確実性が低下し、顧客満足度と顧客維持に深刻な悪影響を及ぼします。企業側の不正確で不完全なデータは、顧客サービスの低下や一貫性のないコミュニケーションにつながります。
さらに、特に金融や医療分野では、不良データが重大なエラーを引き起こし、法的または生命に関わる問題へと発展する可能性があります。
例えば2020年、COVID-19パンデミックの最中、英国公衆衛生庁(PHE)は重大なデータ管理エラーを経験し、不良データにより15,841件のCOVID-19症例が報告されませんでした。 この問題は、PHEが使用していた旧式のExcelスプレッドシートに起因していました。このバージョンは最大65,000行までしか処理できず、実際には100万行以上を保持できるはずでした。検体検査を分析する第三者機関から提供された記録の一部が失われ、不完全なデータが生成されました。この技術的エラーにより、感染リスクのある濃厚接触者の約50,000件の追跡が漏れました。
さらに、2018年に発生したサムスンの入力ミス(ファットフィンガーエラー)は、株価を1日で約11%下落させ、約3億ドルの時価総額を消失させた。 この誤入力は、サムスン証券の従業員が、従業員持株制度に参加した社員に分配する金額を「28億ウォン」とすべきところを「28億株」(1050億ウォン相当)と誤って入力したことが原因であった。
したがって、誤ったデータの影響は軽視すべきではなく、リスクを排除するための適切な予防策を講じる必要がある。
不良データの防止
完璧なデータセットは存在しない。データには必ず誤りが存在する。不良データを防止する第一歩は、この現実を認識し、データ品質を確保するための必要な予防策を実施することである。
不良データを防止する具体的な手順には以下が含まれる:
- 堅牢なデータガバナンスの導入は、組織全体で責任体制と基準を確立する上で極めて重要です。データの管理、アクセス、維持に関する明確な方針と手順を設定し、不良データリスクを最小限に抑えるのに役立ちます。
- 定期的なデータ監査を実施し、問題が発生する前に不整合や古いデータを発見する。
- 組織全体で基準、データ検証ルール、標準フォーマットやテンプレートを設定し、データ入力プロセスを規制することで人的ミスを最小限に抑えます。
- 知識豊富な従業員はデータ処理・管理時のミスを最小限に抑えます。従って、標準プロセスを周知させるため定期的な研修と更新セッションが不可欠です。
- 予期せぬ事態によるデータ損失を防ぐため、定期的にデータをバックアップする。
- データの整合性と完全性を保証するため、データ検証専用に設計された高度なツールを活用しましょう。これらのツールはデータの正確性と完全性を確認し、潜在的なエラーを検出・修正します。
まとめ
本稿では、不良データとは何か、遭遇する可能性のある不良データの種類とその原因について考察しました。さらに、財務損失から事業失敗に至るまで、データ駆動型組織に不良データが及ぼす重大な悪影響を強調しました。これらの要因を理解することが、不良データを防止する第一歩です。
データ品質を確保するための予防策は複数存在しますが、原因に特化した信頼性の高いツールを導入すれば、負担を軽減できるでしょう。
信頼性が高くクリーンなデータセットを自動構築できるデータスクレイピングツールの利用を検討してください。これにより作業負荷が軽減され、クリーンで直接利用可能なデータが得られます。Bright DataのウェブスクレイピングAPIはその代表例です。スクレイピング自体に関心がない方へ:今すぐ登録して無料データセットサンプルをダウンロード!





