

このガイドでは、次の内容を扱います。
- Jsoupとは何か?
- 前提条件
- Jsoupを使用してウェブスクレイパーを作成する方法
- まとめ
Jsoupとは何か?
JsoupはJavaのHTMLパーサーです。言い換えれば、Jsoupは任意のHTML文書を解析できるJavaライブラリです。Jsoupを使えば、ローカルのHTMLファイルを解析したり、URLからリモートのHTMLドキュメントをダウンロードしたりできます。
Jsoupは、DOMを扱うための幅広い方法も提供しています。具体的には、CSSセレクタとJqueryのようなメソッドを使ってHTML要素を選択し、そこからデータを抽出できます。このため、Jsoupは初心者からプロフェッショナルまで、効果的なウェブスクレイピングJavaライブラリとなっています。
なお、Javaでウェブスクレイピングを実行するライブラリーはJsoupだけではありません。HtmlUnitもまた、ウェブスクレイピングで人気のあるJavaライブラリです。Javaでのウェブスクレイピングに関するHtmlUnitガイドをご覧ください。
前提条件
一行目のコードを書く前に、以下の前提条件を満たす必要があります。
- Java >= 8:Javaバージョン8以上であれば、どのバージョンでもかまいません。JavaのLTS(Long Term Support)バージョンをダウンロードしてインストールすることをお勧めします。このチュートリアルは、Java 17に基づいています。本稿執筆時点では、Java 17が最新のJava LTSバージョンです。
- MavenまたはGradle:どちらのJavaビルド自動化ツールを選択してもかまいません。具体的には、依存関係管理機能を持つMavenまたはGradleが必要です。
- Javaをサポートする高機能IDE:MavenやGradleでJavaをサポートするIDEであれば問題ありません。このチュートリアルは、おそらく利用可能な最高のJava IDEであるIntelliJ IDEAに基づいています。
上記のリンクから、すべての前提条件を満たすために必要なものをすべてダウンロードし、インストールしてください。Java、MavenまたはGradle、Java用のIDEの順にセットアップします。よくある問題やトラブルを避けるため、公式のインストールガイドに従ってください。
では、すべての前提条件を満たしていることを確認しましょう。
Javaが正しく構成されていることを確認する
ターミナルを開きます。Javaがインストールされ、Java PATHが正しく設定されたかどうかは、次のコマンドで確認できます。
java -versionこのコマンドで、次のような内容が表示されるはずです。
java version "17.0.5" 2022-10-18 LTS
Java(TM) SE Runtime Environment (build 17.0.5+9-LTS-191)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.5+9-LTS-191, mixed mode, sharing)MavenまたはGradleがインストールされていることを確認する
Mavenを選択した場合、ターミナルで次のコマンドを実行します。
mvn -v以下のように、構成したMavenのバージョンに関する情報が表示されるはずです。
Apache Maven 3.8.6 (84538c9988a25aec085021c365c560670ad80f63)
Maven home: C:Mavenapache-maven-3.8.6
Java version: 17.0.5, vendor: Oracle Corporation, runtime: C:Program FilesJavajdk-17.0.5
Default locale: en_US, platform encoding: Cp1252
OS name: "windows 11", version: "10.0", arch: "amd64", family: "windows"Gradleを選択した場合、ターミナルで次のコマンドを実行します。
gradle -v同様に、以下のようにインストールしたGradleのバージョンに関する情報が出力されるはずです。
------------------------------------------------------------
Gradle 7.5.1
------------------------------------------------------------
Build time: 2022-08-05 21:17:56 UTC
Revision: d1daa0cbf1a0103000b71484e1dbfe096e095918
Kotlin: 1.6.21
Groovy: 3.0.10
Ant: Apache Ant(TM) version 1.10.11 compiled on July 10 2021
JVM: 17.0.5 (Oracle Corporation 17.0.5+9-LTS-191)
OS: Windows 11 10.0 amd64素晴らしい!これで、Jsoupを使用してJavaでウェブスクレイピングを実行する方法を学ぶ準備が整いました!
Jsoupを使用してウェブスクレイパーを作成する方法
ここでは、Jsoupを使ってウェブスクレイピング用のスクリプトを作成する方法を説明します。このスクリプトを実行すると、ウェブサイトから自動的にデータを抽出できます。具体的なターゲットウェブサイトは、Quotes to Scrapeです。このプロジェクトをご存じない方のために説明すると、これはウェブスクレイピング用のサンドボックスに過ぎません。
Quotes to Scrapeは、以下のような外観を備えています。

ご覧のように、ターゲットウェブサイトには、ページ分割された引用のリストが含まれているだけです。Jsoupウェブスクレイパーの目標は、各ページをナビゲートしてすべての引用を取得し、そのデータをCSV形式で返すことです。
では、このステップバイステップのJsoupチュートリアルに従って、簡単なウェブスクレイパーの作成方法を学びましょう!
ステップ1:Javaプロジェクトをセットアップする
ここでは、IntelliJ IDEA 2022.2.3でJavaプロジェクトを初期化する方法を説明します。なお、他の任意のIDEを使用してかまいません。IntelliJ IDEAでは、何回かクリックするだけでJavaプロジェクトをセットアップできます。IntelliJ IDEAを起動し、ロードされるのを待ちます。次に、トップメニューの「ファイル > 新規 > プロジェクト...」オプションを選択します。

「新規プロジェクト」ポップアップで、以下のようにJavaプロジェクトを初期化します。

プロジェクト名と場所を指定し、プログラミング言語としてJavaを選択し、インストールしたビルドツールに応じてMavenかGradleを選択します。「作成」ボタンをクリックし、IntelliJ IDEAがJavaプロジェクトを初期化するのを待ちます。これで、以下のような空のJavaプロジェクトが表示されるはずです。

では、Jsoupをインストールして、ウェブデータのスクレイピングを開始しましょう!
ステップ2:Jsoupをインストールする
Mavenのユーザーであれば、pom.xmlファイルのdependenciesタグ内部に次の行を追加します。
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>Mavenのpom.xmlファイルは次のようになります。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.brightdata</groupId>
<artifactId>web-scraper-jsoup</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
</dependencies>
</project>あるいは、Gradleユーザーであれば、build.gradleファイルのdependenciesオブジェクトに次の行を追加します。
implementation "org.jsoup:jsoup:1.15.3"これで、プロジェクトの依存関係にjsoupを追加できました。いよいよインストールを実行します。IntelliJ IDEA上で、以下のGradle/Mavenリロードボタンをクリックします。

これにより、jsoupの依存関係がインストールされます。インストールプロセスが終了するまで待ちます。これで、Jsoupの機能すべてにアクセスできるようになりました。このimport行をMain.javaファイルの先頭に追加することで、Jsoupが正しくインストールされたことを確認できます。
import org.jsoup.*;IntelliJ IDEAからエラーが報告されなければ、JavaウェブスクレイピングスクリプトでJsoupを使用できます。
それでは、Jsoupを使ってウェブスクレイパーをコーディングしましょう!
ステップ3:ターゲットウェブページに接続する
Jsoupを使えば、1行のコードでターゲットウェブサイトに接続できます。
// downloading the target website with an HTTP GET request
Document doc = Jsoup.connect("https://quotes.toscrape.com/").get();Jsoupのconnect()メソッドのおかげで、ウェブサイトに接続できます。バックグラウンドで、Jsoupはパラメータとして指定されたURLにHTTP GETリクエストを行い、ターゲットサーバーから返されたHTMLドキュメントを取得して、doc Jsoup Documentオブジェクトに格納します。
なお、connect()が失敗した場合、JsoupはIOExceptionを発生させます。この発生については、いくつかの理由が考えられます。ただし、多くのウェブサイトでは、有効なUser-Agentヘッダーを伴わないリクエストがブロックされることに留意してください。馴染みがない方のために説明すると、User-Agentヘッダーは、リクエストの発信元のアプリケーションとOSのバージョンを識別する文字列値です。詳しくは、ウェブスクレイピングのためのUser-Agentを参照してください。
以下のように、User-AgentヘッダをJsoupで指定できます。
Document doc = Jsoup
.connect("https://quotes.toscrape.com/")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();具体的には、Jsoup userAgent()メソッドを使用して、User-Agentヘッダーを設定できます。なお、他のHTTPヘッダーはheader()メソッドで値を設定します。
これで、Main.javaクラスは以下のようになるはずです。
package com.brightdata;
import org.jsoup.*;
import org.jsoup.nodes.*;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// downloading the target website with an HTTP GET request
Document doc = Jsoup
.connect("https://quotes.toscrape.com/")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
}
}では、ターゲットウェブサイトの分析を開始し、そこからデータを抽出する方法を学びましょう。
ステップ4:HTMLページを検査する
HTML文書からデータを抽出する場合、まずウェブページのHTMLコードを分析する必要があります。まず、スクレイピングするデータを含むHTML要素を特定する必要があります。次に、これらのHTML要素を選択する方法を見つける必要があります。
これらはすべて、ブラウザの開発者ツールを使って実現できます。Google ChromeやChromiumベースのブラウザで、興味のあるデータを表示しているHTML要素を右クリックします。次に、「検査」を選択します。
現在、次の内容が表示されているはずです。
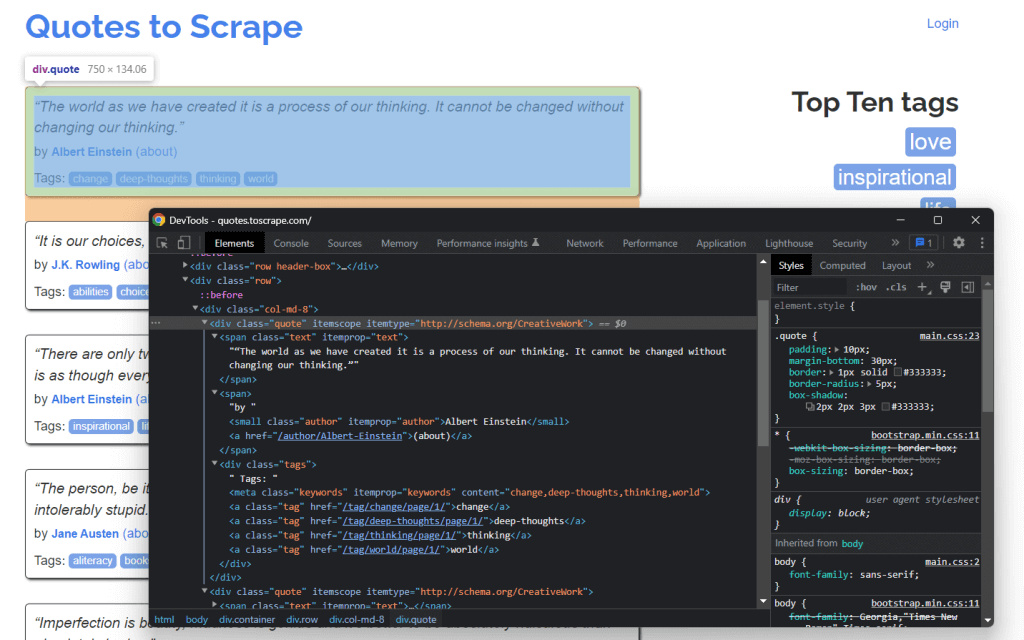
HTMLコードを掘り下げてみると、各引用が<div> HTMLでラップされていることがわかります。詳細には、この<div>要素には以下が含まれます。
- 引用のテキストを含む
<span>HTML要素 - 著者の名前を含む
<small>HTML要素 <div>要素と<a>HTML要素のリスト(引用に関連するタグを含む)。
では、これらのHTML要素で使われているCSSクラスを見てみましょう。これらのおかげで、DOMからHTML要素を抽出するために必要なCSSセレクタを定義できます。具体的には、以下の.quoteにCSSセレクタを適用することで、引用に関連するすべてのデータを取得できます。
.text.author.tags .tag
では、Jsoupでこれを行う方法を学びましょう。
ステップ5:JsoupでHTML要素を選択する
Jsoup Documentクラスを使用すると、さまざまな方法でDOMからHTML要素を選択できます。そのうち、最も重要なものを掘り下げてみましょう。
Jsoupを使用すると、タグに基づいてHTML要素を抽出できます。
// selecting all <div> HTML elements
Elements divs = doc.getElementsByTag("div");これは、DOMに含まれる<div> HTML要素のリストを返します。
同様に、HTML要素をクラスごとに選択することもできます。
// getting the ".quote" HTML element
Elements quotes = doc.getElementsByClass("quote");id属性に基づいて単一のHTML要素を取得したい場合は、次のようにします。
// getting the "#quote-1" HTML element
Element div = doc.getElementById("quote-1");HTML要素を属性で選択することもできます。
// selecting all HTML elements that have the "value" attribute
Elements htmlElements = doc.getElementsByAttribute("value");また、特定のテキストを含むものを選択することもできます。
// selecting all HTML elements that contain the word "for"
Elements htmlElements = doc.getElementsContainingText("for");これらはほんの一例です。Jsoupには、ウェブページからHTML要素を選択するための異なるアプローチが20以上用意されていることを覚えておいてください。そのすべてがこちらに掲載されています。
すでに説明したように、CSSセレクタはHTML要素を選択するための効果的な方法です。JsoupでCSSセレクタを適用して、select()メソッド経由で要素を取得できます。
// selecting all quote HTML elements
Elements quoteElements = doc.getElementsByClass(".quote");ElementsはArrayListを拡張するため、これを反復処理してすべてのJsoup Elementを取得できます。なお、すべてのHTML選択メソッドを単一のElementに適用することも可能です。これにより、選択ロジックが選択されたHTML要素の子要素に制限されます。
そこで、以下のように、それぞれの.quote上で目的のHTML要素を選択できます。
for (Element quoteElement: quoteElements) {
Element text = quoteElement.select(".text").first();
Element author = quoteElement.select(".author").first();
Elements tags = quoteElement.select(".tag");
}では、これらのHTML要素からデータを抽出する方法を学びましょう。
ステップ6:Jsoupでウェブページからデータを抽出する
まず、スクレイピングしたデータを格納できるJavaクラスが必要です。Quote.javaファイルをメインパッケージに作成して、以下のように初期化します。
package com.brightdata;
package com.brightdata;
public class Quote {
private String text;
private String author;
private String tags;
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getTags() {
return tags;
}
public void setTags(String tags) {
this.tags = tags;
}
}次に、前のセクションの最後で紹介したスニペットを拡張してみましょう。選択したHTML要素から目的のデータを抽出し、以下のようにQuoteオブジェクト内に格納します。
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// retrieving the list of product HTML elements
// selecting all quote HTML elements
Elements quoteElements = doc.select(".quote");
// iterating over the quoteElements list of HTML quotes
for (Element quoteElement : quoteElements) {
// initializing a quote data object
Quote quote = new Quote();
// extracting the text of the quote and removing the
// special characters
String text = quoteElement.select(".text").first().text()
.replace("“", "")
.replace("”", "");
String author = quoteElement.select(".author").first().text();
// initializing the list of tags
List<String> tags = new ArrayList<>();
// iterating over the list of tags
for (Element tag : quoteElement.select(".tag")) {
// adding the tag string to the list of tags
tags.add(tag.text());
}
// storing the scraped data in the Quote object
quote.setText(text);
quote.setAuthor(author);
quote.setTags(String.join(", ", tags)); // merging the tags into a "A, B, ..., Z" string
// adding the Quote object to the list of the scraped quotes
quotes.add(quote);
}各引用には複数のタグが含まれることがあり、それらをすべてJava Listに格納できます。次に、String.join()メソッドを使って文字列のリストを縮小して、1つの文字列にできます。最後に、この文字列をquoteオブジェクトに格納できます。
forループの最後に、quotesはターゲットウェブサイトのホームページから抽出したすべての引用データを格納します。ただし、ターゲットウェブサイトは多数のページで構成されています!
Jsoupを使ってウェブサイト全体をクローリングする方法を学びましょう。
ステップ7:Jsoupでウェブサイト全体をクローリングする方法
Quotes to Scrapeのホームページをよく見ると、「次へ →」ボタンがあります。ブラウザの開発者ツールでこのHTML要素を検査します。その上で右クリックして、「検査」を選択します。
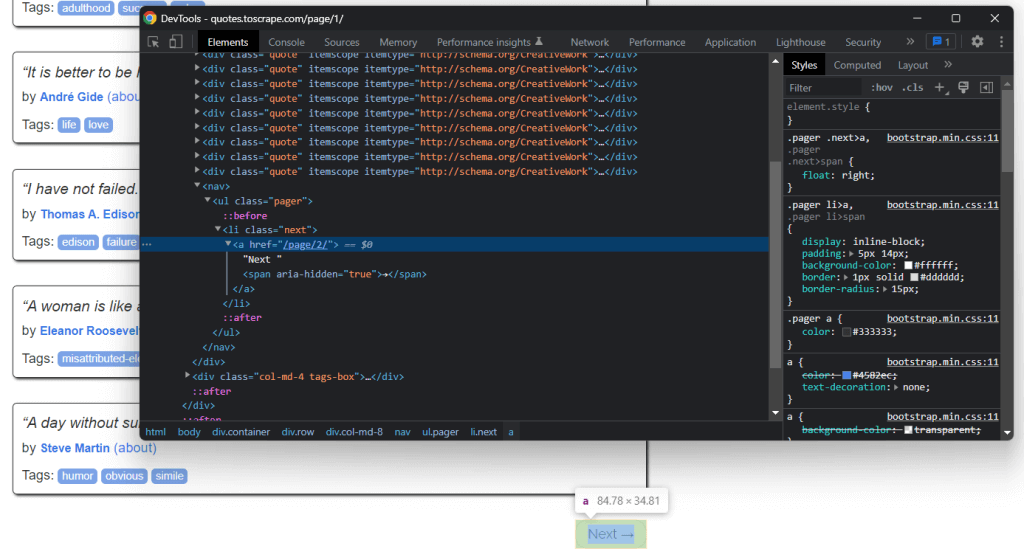
ここで、「次へ →」ボタンは<li> HTML要素であることがわかります。これには、次のページへの相対URLを格納する<a> HTML要素が含まれています。なお、「次へ →」ボタンは、ターゲットウェブサイトの最終ページを除くすべてのページにあります。ほとんどのページ分割されたウェブサイトは、この種のアプローチに従っています。
その<a> HTML要素に格納されているリンクを抽出することで、次のページを取得してスクレイピングできます。ウェブサイト全体をスクレイピングしたい場合は、以下のロジックに従います。
.nextHTML要素を検索する- 存在する場合、
<a>の子に含まれる相対URLを抽出して、2.に進む - もし存在しない場合、これが最後のページでここで停止できます。
- 存在する場合、
<a>/HTML要素によって抽出された相対URLを、ウェブサイトのベースURLと連結する
- 完全なURLを使用して、新しいページに接続する
- 新しいページからデータをスクレイピングする
- 1.に進む
これが、ウェブクローリングというものです。Jsoupでページ分割されたウェブサイトをクローリングするには、次のようにします。
// the URL of the target website's home page
String baseUrl = "https://quotes.toscrape.com";
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// retrieving the home page...
// looking for the "Next →" HTML element
Elements nextElements = doc.select(".next");
// if there is a next page to scrape
while (!nextElements.isEmpty()) {
// getting the "Next →" HTML element
Element nextElement = nextElements.first();
// extracting the relative URL of the next page
String relativeUrl = nextElement.getElementsByTag("a").first().attr("href");
// building the complete URL of the next page
String completeUrl = baseUrl + relativeUrl;
// connecting to the next page
doc = Jsoup
.connect(completeUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// scraping logic...
// looking for the "Next →" HTML element in the new page
nextElements = doc.select(".next");
}ご覧のように、上で説明したクローリングロジックは、単純なwhileサイクルで実装できます。ほんの数行のコードで済みます。具体的には、do ... whileの手法に従う必要があります。
おめでとうございます!これでサイト全体をクローリングできるようになりました。あとは、スクレイピングしたデータをより有用な形式に変換する方法を学ぶだけです。
ステップ8:スクレイピングしたデータをCSVにエクスポートする
スクレイピングしたデータは、以下の方法でCSVファイルに変換できます。
// initializing the output CSV file
File csvFile = new File("output.csv");
// using the try-with-resources to handle the
// release of the unused resources when the writing process ends
try (PrintWriter printWriter = new PrintWriter(csvFile)) {
// iterating over all quotes
for (Quote quote : quotes) {
// converting the quote data into a
// list of strings
List<String> row = new ArrayList<>();
// wrapping each field with between quotes
// to make the CSV file more consistent
row.add(""" + quote.getText() + """);
row.add(""" +quote.getAuthor() + """);
row.add(""" +quote.getTags() + """);
// printing a CSV line
printWriter.println(String.join(",", row));
}
}このスニペットは引用をCSV形式に変換し、output.csvファイルに格納します。ご覧のとおり、これを達成するために追加の依存関係は必要ありません。すべきことは、CSVファイルをFileで初期化するだけです。次に、PrintWriterで、各quoteをCSV形式の行としてoutput.csvファイルに出力します。
なお、PrintWriterは、必要なくなったら必ず閉じてください。具体的には、上記のtry-with-resourcesは、PrintWriterインスタンスがtryステートメントの最後にクローズされることを保証します。
ウェブサイトをナビゲートすることから始めて、すべてのデータをスクレイピングしてCSVファイルに保存できるようになりました。それでは、Jsoupウェブスクレイパー全体を見てみましょう。
すべてを統合する
これが、JavaによるJsoupウェブスクレイピングスクリプトの完成形です。
package com.brightdata;
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.io.PrintWriter;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// the URL of the target website's home page
String baseUrl = "https://quotes.toscrape.com";
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// downloading the target website with an HTTP GET request
Document doc = Jsoup
.connect(baseUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// looking for the "Next →" HTML element
Elements nextElements = doc.select(".next");
// if there is a next page to scrape
while (!nextElements.isEmpty()) {
// getting the "Next →" HTML element
Element nextElement = nextElements.first();
// extracting the relative URL of the next page
String relativeUrl = nextElement.getElementsByTag("a").first().attr("href");
// building the complete URL of the next page
String completeUrl = baseUrl + relativeUrl;
// connecting to the next page
doc = Jsoup
.connect(completeUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// retrieving the list of product HTML elements
// selecting all quote HTML elements
Elements quoteElements = doc.select(".quote");
// iterating over the quoteElements list of HTML quotes
for (Element quoteElement : quoteElements) {
// initializing a quote data object
Quote quote = new Quote();
// extracting the text of the quote and removing the
// special characters
String text = quoteElement.select(".text").first().text();
String author = quoteElement.select(".author").first().text();
// initializing the list of tags
List<String> tags = new ArrayList<>();
// iterating over the list of tags
for (Element tag : quoteElement.select(".tag")) {
// adding the tag string to the list of tags
tags.add(tag.text());
}
// storing the scraped data in the Quote object
quote.setText(text);
quote.setAuthor(author);
quote.setTags(String.join(", ", tags)); // merging the tags into a "A; B; ...; Z" string
// adding the Quote object to the list of the scraped quotes
quotes.add(quote);
}
// looking for the "Next →" HTML element in the new page
nextElements = doc.select(".next");
}
// initializing the output CSV file
File csvFile = new File("output.csv");
// using the try-with-resources to handle the
// release of the unused resources when the writing process ends
try (PrintWriter printWriter = new PrintWriter(csvFile, StandardCharsets.UTF_8)) {
// to handle BOM
printWriter.write('ufeff');
// iterating over all quotes
for (Quote quote : quotes) {
// converting the quote data into a
// list of strings
List<String> row = new ArrayList<>();
// wrapping each field with between quotes
// to make the CSV file more consistent
row.add(""" + quote.getText() + """);
row.add(""" +quote.getAuthor() + """);
row.add(""" +quote.getTags() + """);
// printing a CSV line
printWriter.println(String.join(",", row));
}
}
}
}ここに示すように、Javaでは100行未満のコードでウェブスクレイパーを実装できます。Jsoupのおかげで、ウェブサイトに接続して、その全体をクローリングし、すべてのデータを自動的に抽出できます。そして、スクレイピングしたデータをCSVファイルに書き出すことができます。このJsoupウェブスクレイパーで実行できるのは、このことです。
IntelliJ IDEAで、以下のボタンをクリックしてウェブスクレイピングJsoupスクリプトを起動します。

IntelliJ IDEAはMain.javaファイルをコンパイルし、Mainクラスを実行します。スクレイピングプロセスの最後に、プロジェクトのルートディレクトリにoutput.csvファイルが生成されます。それを開くと、以下のデータが入っているはずです。
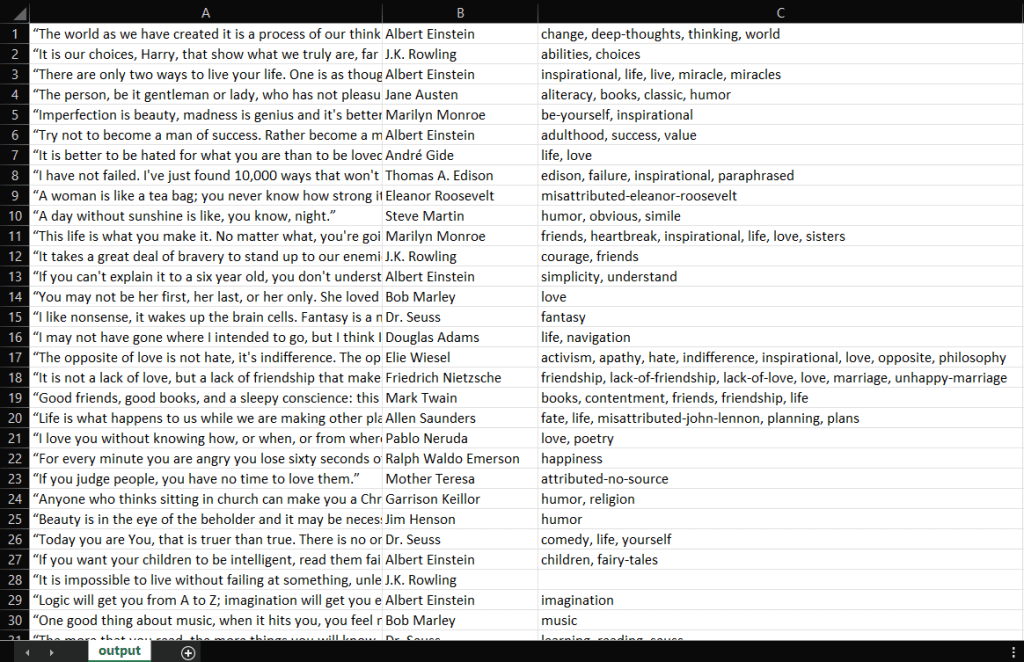
よくできました!これで、Quotes to Scrapeの100の引用をすべて含むCSVファイルができました!つまり、Jsoupを使ってウェブスクレイパーを構築する方法を学ぶだけです!
まとめ
このチュートリアルでは、ウェブスクレイパーの作成を始めるために必要なこと、Jsoupとは何か、ウェブからデータをスクレイピングするためにJsoupをどのように使用できるかを学びました。具体的には、Jsoupを使ってウェブスクレイピングアプリケーションを作成する方法を、実際の例を通して見てきました。すでに学んだように、JavaのJsoupを使ったウェブスクレイピングには、それほどのコード行を必要としません。
しかし、ウェブスクレイピングはそれほど簡単ではありません。というのも、直面しなければならない課題がいくつかあるからです。ボット対策やスクレイピング対策の技術は、かつてないほど普及していることを忘れないでください。必要なのは、Bright Dataが提供する、強力で完全な機能を備えたウェブスクレイピングツールだけです。スクレイピングは一切せずに済ませたいですか?当社のデータセットをご検討ください。
ブロックを回避する方法について詳しく知りたい場合は、Bright Dataで利用可能な多くのプロキシサービスの中から、自社のユースケースに基づいたプロキシを採用できます。





