

ほとんどのウェブスクレイピングデータは、Amazon、YouTube などの動的ウェブサイトから取得されます。これらのウェブサイトは、ユーザーの入力に基づき、インタラクティブで応答性の高いユーザーエクスペリエンスを提供します。例えば、YouTubeのアカウントにアクセスすると、表示される動画コンテンツは入力内容に合わせたものになります。その結果、ユーザーのインタラクションによってデータが常に変更されるため、動的サイトのウェブスクレイピングがより困難になる可能性があります。
動的なサイトからデータをスクレイピングするには、ユーザーのウェブサイトとの対話をシミュレートし、JavaScriptによって生成された特定のコンテンツに移動して選択し、AJAX(Asynchronous JavaScript and XML)リクエストを処理する高度な技術を使用する必要があります。
このガイドでは、SeleniumというオープンソースのPythonライブラリを使用して、動的ウェブサイトからデータをスクレイピングする方法を説明します。
Seleniumを使用して動的ウェブサイトからデータをスクレイピングする
動的サイトからデータのスクレイピングを開始する前に、使用するPythonパッケージであるSeleniumについて理解する必要があります。
Seleniumとは?
SeleniumはオープンソースのPythonパッケージであり、動的ウェブサイト上でさまざまな操作やタスクを実行可能にする自動テストフレームワークです。これらのタスクには、ダイアログの開閉、YouTubeでの特定のクエリの検索、フォームへの入力などが含まれ、すべてをお好みのウェブブラウザで行うことができます。
SeleniumをPythonで利用すると、Selenium Pythonパッケージを使用して数行のPythonコードを記述するだけで、ウェブブラウザを制御し、動的ウェブサイトからデータを自動的に抽出できます。
Seleniumの仕組みがわかったところで、さっそく始めましょう。
新しいPythonプロジェクトを作成する
最初に、新しいPythonプロジェクトを作成する必要があります。data_scraping_projectというディレクトリを作成します。ここに、収集したデータとソースコードのファイルがすべて格納されます。このディレクトリには2つのサブディレクトリがあります。
scriptsには、動的ウェブサイトからデータを抽出および収集するすべてのPythonスクリプトが含まれます。dataには、動的ウェブサイトから抽出されたすべてのデータが格納されます。
Pythonパッケージをインストールする
data_scraping_projectディレクトリを作成した後、動的ウェブサイトからデータをスクレイピング、収集、保存できるように、以下のPythonパッケージをインストールする必要があります。
- Webdriver Manager
- pandas
ターミナルで以下のpipコマンドを実行して、Selenium Pythonパッケージをインストールできます。
pip install selenium
Seleniumは、バイナリドライバを使用して、選択したウェブブラウザを制御します。このPythonパッケージは、サポートされているウェブブラウザ(Chrome、Chromium、Brave、Firefox、IE、Edge、Opera)用のバイナリドライバを提供します。
次に、ターミナルで以下のpip コマンドを実行して、webdriver-managerをインストールします。
pip install webdriver-manager
pandasをインストールするには、次のpipコマンドを実行します。
pip install pandas
何をスクレイピングするか
この記事では、Programming with MoshというYouTubeチャンネルとHacker Newsという2つの異なる場所からデータをスクレイピングします。
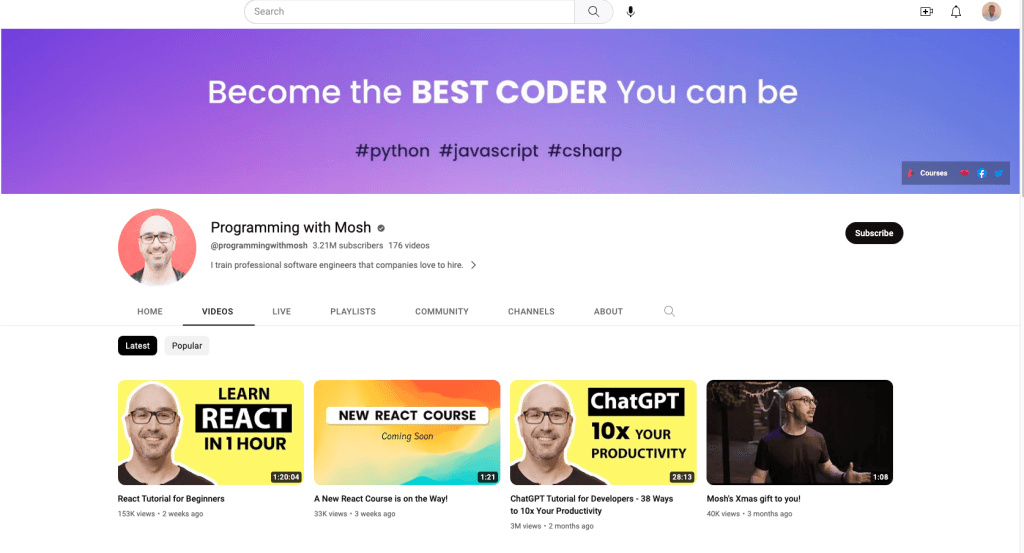
Programming with Mosh YouTubeチャンネルから、以下の情報をスクレイピングします。
- 動画のタイトル。
- 動画のリンクまたはURL。
- 画像のリンクまたはURL。
- 特定の動画の再生回数。
- 動画の公開時期。
- 特定のYouTube動画URLからのコメント。
Hacker Newsからは以下のデータを収集します。
- 記事のタイトル。
- 記事へのリンク。

何をスクレイピングするかがわかったので、新しいPythonスクリプト(つまり data_scraping_project/scripts/youtube_videos_list.py)を作成しましょう。
Pythonパッケージをインポートする
まず、データのスクレイピング、収集、CSVファイルへの保存に使用するPythonパッケージをインポートする必要があります。
# import libraries
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pandas as pd
Webdriverをインスタンス化する
Webdriverをインスタンス化するには、Seleniumが使用するブラウザ(この例ではChrome)を選択し、バイナリドライバをインストールする必要があります。
Chromeには、ウェブページのHTMLコードを表示し、スクレイピングしてデータを収集するためのHTML要素を特定する開発者向けツールがあります。HTMLコードを表示するには、Chromeウェブブラウザでウェブページを右クリックし、要素の検査を選択する必要があります。
Chrome用のバイナリドライバをインストールするには、以下のコードを実行します。
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
Chrome用のバイナリドライバがマシンにインストールされ、自動的にWebdriverがインスタンス化されます。
Seleniumを使ってデータをスクレイピングする
Selenium でデータをスクレイピングするには、簡単なPython変数(つまり、url)でYouTube URLを定義する必要があります。このリンクから、特定のYouTube URLからのコメントを除く、前述のデータをすべて収集します。
# Define the URL
url = "https://www.youtube.com/@programmingwithmosh/videos"
# load the web page
driver.get(url)
# set maximum time to load the web page in seconds
driver.implicitly_wait(10)
Seleniumは、YouTubeリンクをChrome ブラウザに自動的に読み込みます。さらに、ウェブページ(すべてのHTML要素を含む)の完全な読み込みを確保するために、時間枠(つまり10秒)を指定します。これは、JavaScriptによってレンダリングされたデータをスクレイピングするのに役立ちます。
IDとタグを使ってデータをスクレイピングする
Seleniumの利点の1つは、IDやタグなど、ウェブページ上に提示されたさまざまな要素を使ってデータを抽出できることです。
例えば、ID要素(つまり、post-title)またはタグ(つまり、h1とp)を使ってデータをスクレイピングできます。
<h1 id ="post-title">Introduction to data scrapping using Python</h1>
<p>You can use selenium python package to collect data from any dynamic website</p>
あるいは、YouTubeのリンクからデータをスクレイピングする場合は、ウェブページに提示されたIDを使用する必要があります。YouTube URLをウェブブラウザで開き、右クリックして検査を選択してIDを特定します。次に、マウスを使ってページを表示し、チャンネルで紹介されているビデオのリストを保持しているIDを特定します。
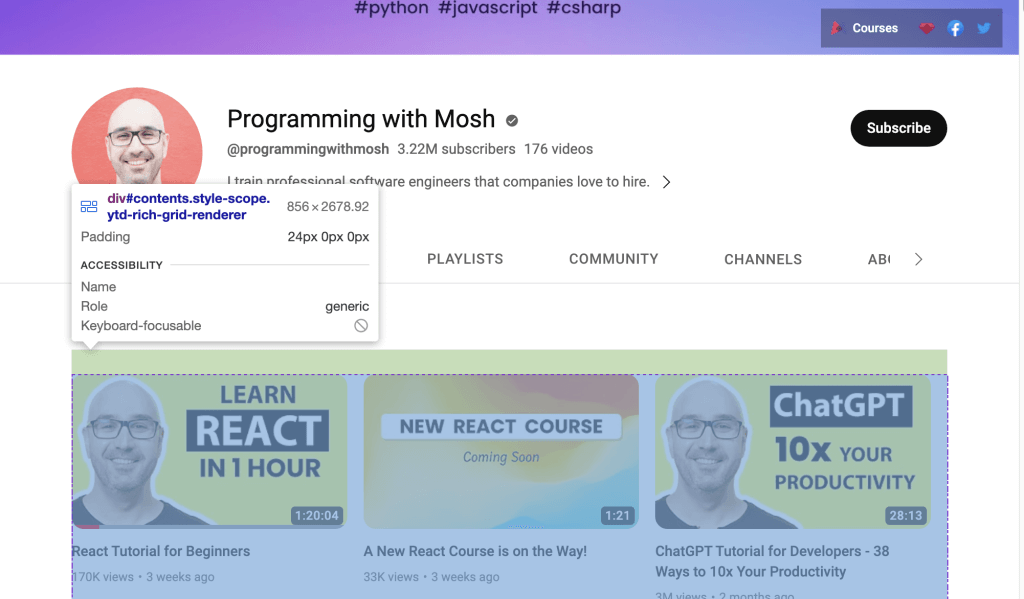
Webdriverを使用して、特定されたID内のデータをスクレイピングします。ID属性でHTML要素を見つけるには、find_element() Seleniumメソッドを呼び出し、第1引数としてBy.IDを、第2引数としてIDを渡します。
各ビデオのビデオタイトルとビデオリンクを収集するためには、video-title-link ID属性を使用する必要があります。このID属性を持つ複数のHTML要素を収集するため、find_elements()メソッドを使用する必要があります。
# collect data that are withing the id of contents
contents = driver.find_element(By.ID, "contents")
#1 Get all the by video tite link using id video-title-link
video_elements = contents.find_elements(By.ID, "video-title-link")
#2 collect title and link for each youtube video
titles = []
links = []
for video in video_elements:
#3 Extract the video title
video_title = video.get_attribute("title")
#4 append the video title
titles.append(video_title)
#5 Extract the video link
video_link = video.get_attribute("href")
#6 append the video link
links.append(video_link)
このコードは以下のタスクを実行します。
- コンテンツのID属性内にあるデータを収集します。
- WebElementコンテンツオブジェクトから、
video-title-linkのID属性を持つすべてのHTML要素を収集します。 - タイトルとリンクを追記するための2つのリストを作成します。
get_attribute()メソッドを使用して動画のタイトルを抽出し、そのtitleを渡します。- タイトルリストで動画のタイトルを追記します。
get_atribute()メソッドを使用して動画のリンクを抽出し、引数としてhrefを渡します。- リンクリストで動画のリンクを追記します。
この時点で、すべてのビデオのタイトルとリンクは、titlesとlinksという2つのPythonリストに含まれます。
次に、YouTube動画リンクをクリックして動画を視聴する前に、ウェブページで利用可能な画像のリンクをスクレイピングする必要があります。この画像リンクをスクレイピングするには、find_elements() Seleniumメソッドを呼び出し、第1引数にBy.TAG_NAMEを、第2引数にタグの名前を渡して、すべてのHTML要素を見つける必要があります。
#1 Get all the by Tag
img_elements = contents.find_elements(By.TAG_NAME, "img")
#2 collect img link and link for each youtube video
img_links = []
for img in img_elements:
#3 Extract the img link
img_link = img.get_attribute("src")
if img_link:
#4 append the img link
img_links.append(img_link)
このコードは、contentsと呼ばれるWebElementオブジェクトからimgタグ名を持つすべてのHTML要素を収集します。また、画像リンクを追記するためのリストを作成し、get_attribute()メソッドでそれを抽出し、引数としてsrcを渡します。最後に、画像リンクをimg_linksリストに追記します。
また、IDとタグ名を使用して、各YouTube動画のより多くのデータをスクレイピングできます。YouTube URLのウェブページでは、ページに掲載されている各動画の再生回数と公開時間を確認できるはずです。このデータを抽出するには、IDがmetadata-lineのHTML要素をすべて収集し、次にspanタグ名を持つHTML要素からデータを収集する必要があります。
#1 find the element with the specific ID you want to scrape
meta_data_elements = contents.find_elements(By.ID, 'metadata-line')
#2 collect data from span tag
meta_data = []
for element in meta_data_elements:
#3 collect span HTML element
span_tags = element.find_elements(By.TAG_NAME, 'span')
#4 collect span data
span_data = []
for span in span_tags:
#5 extract data for each span HMTL element.
span_data.append(span.text)
#6 append span data to the list
meta_data.append(span_data)
# print out the scraped data.
print(meta_data)
このコードブロックは、 WebElement contents オブジェクトからID属性が metadata-line であるすべてのHTML要素を収集し、再生回数と公開時間を含む span タグのデータを追記するリストを作成します。
また、タグ名がspanであるすべてのHTML要素をmeta_data_elementsと呼ばれるWebElementオブジェクトから収集し、このspanデータを含むリストを作成します。次に、span HTML要素からテキストデータを抽出し、span_data listに追記します。最後に、span_dataリストのデータをmeta_dataに追記します。
span HTML要素から抽出されたデータは、次のようになります。

次に、Pythonのリストを2つ作成し、再生回数と公開時間を別々に保存する必要があります。
#1 Iterate over the list of lists and collect the first and second item of each sublist
views_list = []
published_list = []
for sublist in meta_data:
#2 append number of views in the views_list
views_list.append(sublist[0])
#3 append time published in the published_list
published_list.append(sublist[1])
ここでは、meta_dataからデータを抽出するPythonのリストを2つ作成し、各サブリストの閲覧数をview_listに、各サブリストの公開時間をpublished_listに追記します。
この時点で、動画のタイトル、動画ページのURL、画像のURL、閲覧回数、動画の公開時刻をスクレイピングしました。このデータは、pandas Pythonパッケージを使用して、pandas DataFrameに保存できます。以下のコードを使用して、titles、links、img_links、views_list、published_list のリストのデータをpandas DataFrameに保存します。
# save in pandas dataFrame
data = pd.DataFrame(
list(zip(titles, links, img_links, views_list, published_list)),
columns=['Title', 'Link', 'Img_Link', 'Views', 'Published']
)
# show the top 10 rows
data.head(10)
# export data into a csv file.
data.to_csv("../data/youtube_data.csv",index=False)
driver.quit()
スクレイピングしたデータは、pandas DataFrameでは次のように表示されます。

この保存されたデータは、to_csv()を使用して、pandasからyoutube_data.csvというCSVファイルにエクスポートされます。
これで、youtube_videos_list.pyを実行して、すべてが正しく動作することを確認できます。
CSSセレクタを使用してデータをスクレイピングする
Seleniumは、ウェブページ上のCSSセレクタを使用して、HTML要素の特定のパターンに基づいてデータを抽出することもできます。CSSセレクタは、ID、タグ名、クラスなどの属性に応じて、特定の要素をターゲットとするために適用されます。
例えば、以下のHTMLページにはいくつかのdiv要素があり、そのうちの1つに「inline-code」というクラス名が付けられています。
<html>
<body>
<p>Hello World!</p>
<div>Learn Data Scraping</div>
<div class="inline-code"> data scraping with Python code</div>
<div>Saving</div>
</body>
</html>
CSSセレクタを使って、タグ名がdivでクラス名が「inline-code」であるウェブページ上のHTML要素を見つけることができます。これと同じアプローチで、YouTube動画のコメントセクションからコメントを抽出できます。
では、CSSセレクタを使って、このYouTube動画に投稿されたコメントを収集してみましょう。
YouTubeのコメントセクションには、以下のタグとクラス名でアクセスできます。
<ytd-comment-thread-renderer class="style-scope ytd-item-section-renderer">...</tyd-comment-thread-renderer>
新しいスクリプト(つまりdata_scraping_project/scripts/youtube_video_
comments.py)を作成しましょう。前と同様に必要なパッケージをすべてインポートし、以下のコードを追加してChromeウェブブラウザを自動的に起動して、YouTube動画のURLを参照し、CSSセレクタを使用してコメントをスクレイピングします。
#1 instantiate chrome driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#2 Define the URL
url = "https://www.youtube.com/watch?v=hZB5bHDCmeY"
#3 Load the webpage
driver.get(url)
#4 define the CSS selector
comment_section = 'ytd-comment-thread-renderer.ytd-item-section-renderer’
#5 wait until element matching the given criteria to be found
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, comment_section))
)
except:
driver.quit()
#6. collect HTML elements within the CSS selector
comment_blocks = driver.find_elements(By.CSS_SELECTOR,comment_section)
このコードは、Chromeドライバをインスタンス化し、投稿されたコメントをスクレイピングするためのYouTube動画リンクを定義します。次に、ブラウザでウェブページを読み込み、CSSセレクタに一致するHTML要素が利用可能になるまで10秒間待機します。
次に、ytd-comment-thread-renderer.ytd-item-section-rendererというCSSセレクタを使用してすべてのcomment HTML要素を収集し、すべてのコメント要素をcomment_blocks WebElementオブジェクトに保存します。
次に、comment_blocks WebElementオブジェクト内の各コメントからID author-textを使用して各作成者の名前を抽出し、ID content-textを使用してコメントテキストを抽出できます。
#1 specify the id attribute for author and comment
author_id = 'author-text'
comment_id = 'content-text'
#2 Extract the text value for each comment and author in the list
comments = []
authors = []
for comment_element in comment_blocks:
#3 collect author for each comment
author = comment_element.find_element(By.ID, author_id)
#4 append author name
authors.append(author.text)
#5 collect comments
comment = comment_element.find_element(By.ID, comment_id)
#6 append comment text
comments.append(comment.text)
#7 save in pandas dataFrame
comments_df = pd.DataFrame(list(zip(authors, comments)), columns=['Author', 'Comment'])
#8 export data into a CSV file.
comments_df.to_csv("../data/youtube_comments_data.csv",index=False)
driver.quit()
このコードは、作成者とコメントのIDを指定します。次に、作成者名とコメントテキストを追記するための2つのPythonリストを作成します。指定されたID属性を持つ各HTML要素をWebElementオブジェクトから収集し、そのデータをPythonリストに追加します。
最後に、スクレイピングしたデータをpandas DataFrameに保存し、そのデータをyoutube_comments_data.csvというCSVファイルにエクスポートします。
最初の10行の作成者とコメントは、pandas DataFrameでは次のようになります。

クラス名を使用してデータをスクレイピングする
CSSセレクタを使ったデータのスクレイピングに加え、特定のクラス名を元にデータを抽出することもできます。Seleniumを使用してクラス名属性でHTML要素を見つけるには、find_element()メソッドを呼び出し、第1引数としてBy.CLASS_NAMEを渡し、第2引数としてクラス名を見つける必要があります。
このセクションでは、クラス名を使って、Hacker Newsに投稿された記事のタイトルとリンクを収集します。このウェブページでは、(ウェブページのコードからわかるように)各記事のタイトルとリンクを持つHTML要素に、titlelineというクラス名が付いています。
<span class="titleline"><a href="https://mullvad.net/en/browser">The Mullvad Browser</a><span class="sitebit comhead"> (<a href="from?site=mullvad.net"><span class="sitestr">mullvad.net</span></a>)</span></span></td></tr><tr><td colspan="2"></td><td class="subtext"><span class="subline">
<span class="score" id="score_35421034">302 points</span> by <a href="user?id=Foxboron" class="hnuser">Foxboron</a> <span class="age" title="2023-04-03T10:11:50"><a href="item?id=35421034">2 hours ago</a></span> <span id="unv_35421034"></span> | <a href="hide?id=35421034&auth=60e6bdf9e482441408eb9ca98f92b13ee2fac24d&goto=news" class="clicky">hide</a> | <a href="item?id=35421034">119 comments</a> </span>
新しいPythonスクリプト(つまりdata_scraping_project/scripts/hacker_news.py)を作成し、必要なパッケージをすべてインポートして、以下のPythonコードを追加し、Hacker Newsページに投稿された各記事のタイトルとリンクをスクレイピングします。
#1 define url
hacker_news_url = 'https://news.ycombinator.com/'
#2 instantiate chrome driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 load the web page
driver.get(hacker_news_url)
#4 wait until element matching the given criteria to be found
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'titleline'))
)
except:
driver.quit()
#5 Extract the text value for each title and link in the list
titles= []
links = []
#6 Find all the articles on the web page
story_elements = driver.find_elements(By.CLASS_NAME, 'titleline')
#7 Extract title and link for each article
for story_element in story_elements:
#8 append title to the titles list
titles.append(story_element.text)
#9 extract the URL of the article
link = story_element.find_element(By.TAG_NAME, "a")
#10 appen link to the links list
links.append(link.get_attribute("href"))
driver.quit()
このコードは、ウェブページのURLを定義し、Chromeウェブブラウザを自動的に起動して、Hacker NewsのURLをブラウズします。CLASS NAMEに一致するHTML要素が利用できるようになるまで10秒待ちます。
そして、各記事のタイトルとリンクを追記する2つのPythonリストを作成します。また、WebElementドライバオブジェクトからtitlelineクラス名を持つ各HTML要素を収集し、story_elements WebElementオブジェクトで表される各記事のタイトルとリンクを抽出します。
最後に、このコードは記事のタイトルをタイトルリストに追加し、タグ名aを持つHTML要素をstory_elementオブジェクトから収集します。get_attriubute()メソッドを使用してリンクを抽出し、そのリンクをリンクリストに追記します。
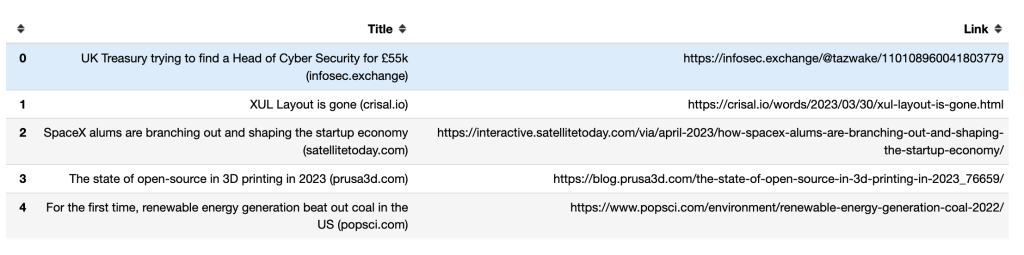
次に、pandasのto_csv()メソッドを使用してスクレイピングしたデータをエクスポートする必要があります。タイトルとリンクの両方をCSVファイルhacker_news_data.csvにエクスポートし、そのデータをディレクトリに保存します。
# save in pandas dataFrame
hacker_news = pd.DataFrame(list(zip(titles, links)),columns=['Title', 'Link'])
# export data into a csv file.
hacker_news.to_csv("../data/hacker_news_data.csv",index=False)
以下に、最初の5行のタイトルとリンクが、pandas DataFrameにどのように表示されるかを示します。
無限スクロールの扱い方
動的ウェブページの中には、ページの下までスクロールすると、追加のコンテンツが読み込まれるものがあります。一番下まで移動しない場合、Seleniumは画面に表示されているデータしかスクレイピングしない可能性があります。
より多くのデータをスクレイピングするには、ページの一番下までスクロールし、新しいコンテンツが読み込まれるまで待ってから、必要なデータを自動的にスクレイピングするよう、Seleniumに指示する必要があります。例えば、以下のPythonスクリプトは、Python書籍の最初の40件の結果をスクロールして、そのリンクを抽出します。
#1 import packages
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
#2 Instantiate a Chrome webdriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 Navigate to the webpage
driver.get("https://example.com/results?search_query=python+books")
#4 instantiate a list to keep links
books_list = []
#5 Get the height of the current webpage
last_height = driver.execute_script("return document.body.scrollHeight")
#6 set target count
books_count = 40
#7 Keep scrolling down on the web page
while books_count > len(books_list):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
#8 Wait for the page to load
time.sleep(5)
#9 Calculate the new height of the page
new_height = driver.execute_script("return document.body.scrollHeight")
#10 Check if you have reached the bottom of the page
if new_height == last_height:
break
last_height = new_height
#11 Extract the data
links = driver.find_elements(By.TAG_NAME, "a")
for link in links:
#12 append extracted data
books_list.append(link.get_attribute("href"))
#13 Close the webdriver
driver.quit()
このコードは、使用するPythonパッケージをインポートし、Chromeをインスタンス化して開きます。次にウェブページに移動し、検索結果ごとにリンクを追記するPythonリストを作成します。
return document.body.scrollHeightスクリプトを実行して現在のページの高さを取得し、収集するリンクの数を設定します。その後、変数book_countの値がbook_listの長さより大きい限り下にスクロールし続け、5秒待ってからページを読み込みます。
return document.body.scrollHeightスクリプトを実行してウェブページの新しい高さを計算し、ページの下部に達したかどうかをチェックします。ページ下部に達した場合はループを終了します。そうでない場合はlast_heightを更新してスクロールダウンを継続します。最後に、WebElementオブジェクトからタグ名aを持つHTML要素を収集し、リンクを抽出してリンクリストに追記します。リンクを収集した後、Webdriverを閉じます。
注記: ページが無限スクロールする場合、スクリプトをある時点で終了するには、スクレイピングするアイテムの総数を設定する必要があります。さもないと、コードが実行され続けてしまいます。
Bright Dataを使用したウェブスクレイピング
Seleniumのようなオープンソースのスクレイパーでデータをスクレイピングすることは可能ですが、どうしてもサポートが不足がちです。また、プロセスが煩雑で時間がかかることもあります。強力で信頼性の高いウェブスクレイピングソリューションをお探しであれば、Bright Dataを検討されることをお勧めします。
Bright Dataは、ウェブスクレイピングソリューション、プロキシ、収集済みデータセットを含むさまざまなツールやサービスを提供することで、公開されたウェブデータのスクレイピングを可能にするウェブデータプラットフォームです。また、ホストされたWeb Scraper IDEを使用して、JavaScriptコーディング環境で独自のスクレイパーを設計することも可能です。
Web Scraper IDEは Indeedスクレイパー、Walmartスクレイパーのテンプレートなど、さまざまな人気のある動的ウェブサイト向けの構築済みスクレイピング機能とコードテンプレートも搭載しています。つまり、開発のスピードアップや迅速な拡張が容易なのです。
Bright Dataは、JSON、NDJSON、CSV、Microsoft Excelなど、データをフォーマットするための幅広いオプションを提供します。また、さまざまなプラットフォームと統合されているため、スクレイピングしたデータを簡単に配信できます。
まとめ
動的ウェブサイトからデータをスクレイピングするには、労力と計画が必要です。Seleniumを使えば、どんな動的ウェブサイトとも自動的に対話処理を行い、データを収集できます。
Seleniumを使用してデータをスクレイピングすることは可能ですが、時間がかかり、複雑です。そのため、動的ウェブサイトのスクレイピングにはWeb Scraper IDEを使用することをお勧めします。構築済みのスクレイピング機能とコードテンプレートを使用して、すぐにデータの抽出を開始できます。




