

このガイドでは以下を学びます:
- CloudScraperとは何か、その有用性
- CloudScraperにプロキシを統合すべき理由
- ステップバイステップガイドでの設定方法
- – CloudScraperでのプロキシローテーション実装方法
- 認証プロキシの扱い方
- Bright Dataのようなプレミアムプロキシプロバイダーの利用方法
さっそく始めましょう!
CloudScraperとは?
CloudScraperは、Cloudflareのアンチボットページ(通称「I’m Under Attack Mode」またはIUAM)を回避するために設計されたPythonモジュールです。内部では、最も人気のあるPython HTTPクライアントの一つであるRequestsを使用して実装されています。
このライブラリは、Cloudflareで保護されたウェブサイトのスクレイピングやクロールに特に有用です。現在のアンチボットページはクライアントがJavaScriptをサポートしているかどうかを確認しますが、Cloudflareは将来的に追加の対策を導入する可能性があります。
Cloudflareは定期的にボット対策ソリューションを更新するため、本ライブラリも機能を維持するために定期的に更新されます。
CloudScraperでプロキシを使用する理由
Cloudflareはリクエスト数が多すぎるとIPをブロックする可能性があります。同様に、CloudScraperのようなツールでも回避が困難な高度な防御策を発動させる場合もあります。これを軽減するには、IPアドレスを確実にローテーションする方法が必要です。
ここでプロキシサーバーが役立ちます。プロキシはスクレイパーと対象サイトの間で仲介役となり、実際のIPアドレスをプロキシサーバーのIPで隠蔽します。あるIPがブロックされても、新しいプロキシに素早く切り替えられるため、アクセスが途切れることはありません。
CloudScraperによるウェブスクレイピングにおいて、プロキシには2つの主要な利点があります:
- セキュリティと匿名性の強化:リクエストをプロキシ経由でルーティングすることで、真の身元が隠され、検出リスクが低減されます。
- ブロックと中断の回避:プロキシによりIPアドレスを動的にローテーションできるため、ブロックやレートリミッターを回避できます。
プロキシをCloudScraperなどのツールと組み合わせることで、リスクを最小限に抑え効率を最大化する堅牢なウェブスクレイピング環境を構築できます。この二重の対策により、高度な反スクレイピング対策を施したサイトからも、安全かつシームレスなデータ抽出が保証されます。
CloudScraperでプロキシを設定する:ステップバイステップガイド
このガイドセクションで、CloudScraperでのプロキシ使用方法を学びましょう!
ステップ #1: CloudScraper のインストール
以下のコマンドでcloudscraper pipパッケージ経由にCloudScraperをインストールできます:
pip install -U cloudscraper
Cloudflareはボット対策エンジンを継続的に更新しています。そのため、パッケージインストール時には-Uオプションを指定し、最新版を取得するようにしてください。
ステップ #2: Cloudscraper の初期化
まず CloudScraper をインポートします:
import cloudscraper
次に、create_scraper()メソッドを使用してCloudScraperインスタンスを作成します:
スクレイパー = cloudscraper.create_scraper()
このスクレイパーオブジェクトは、requestsライブラリのSession オブジェクトと同様に動作します。特に、Cloudflareのボット対策機能を回避しながらHTTPリクエストを実行できるようにします。
ステップ #3: プロキシの統合
CloudScraperはRequestsの上に構築されているため、プロキシの統合はrequestsと同様の方法で行います。その手順に慣れていない場合は、Requestsでのプロキシ設定に関するチュートリアルをお読みください。
CloudScraperでプロキシを使用するには、以下の通りproxies辞書を定義し、get()メソッドに渡す必要があります:
proxies = {
"http": "<YOUR_HTTP_PROXY_URL>",
"https": "<YOUR_HTTPS_PROXY_URL>"
}
# 指定したプロキシ経由でリクエストを実行
response = scraper.get("<YOUR_TARGET_URL>", proxies=proxies)
get()メソッドのproxiesパラメータはRequestsに渡されます。これにより、HTTPクライアントはターゲットURLのプロトコルに応じて、指定されたHTTPまたはHTTPSプロキシサーバーを経由してリクエストをルーティングします。
ステップ #4: CloudScraper プロキシ統合設定のテスト
デモ目的で、HTTPBinプロジェクトの/ipエンドポイントをターゲットとします。このエンドポイントは呼び出し元のIPアドレスを返します。正常に動作すれば、レスポンスにはプロキシサーバーのIPアドレスが表示されるはずです。
設定テストには、無料プロキシリストからプロキシサーバーのIPを取得できます。
警告: 無料プロキシは信頼性が低く、データ収集目的で使用される場合があり、特に市場で評価の高いプロキシプロバイダー以外のものはセキュリティ上のリスクを伴う可能性があります。教育目的でのみご利用ください。
プロキシサーバーのURLが以下の場合を想定します:
http://202.159.35.121:443
CloudScraperに統合する方法は以下の通りです:
import cloudscraper
# CloudScraperスクレイパーインスタンスを作成
scraper = cloudscraper.create_scraper()
# プロキシを指定
proxies = {
"http": "http://202.159.35.121:443",
"https": "http://202.159.35.121:443"
}
# プロキシ経由でリクエストを送信
response = scraper.get("https://httpbin.io/ip", proxies=proxies)
# "/ip" エンドポイントからのレスポンスを出力
print(response.text)
正しく設定されていれば、以下のようなレスポンスが表示されるはずです:
{
"origin": "202.159.35.121:1819"
}
レスポンス内のIPが、期待通りプロキシサーバーのIPと一致していることに注目してください。
注: 無料プロキシサーバーは短命な場合が多いです。そのため、以下の例で使用しているプロキシは、この記事を読んでいる時点では既に機能していない可能性があります。
よくできました! CloudScraperへのプロキシ統合が完了しました。
プロキシローテーションの実装方法
Cloudscraperでプロキシを使用するとIPアドレスを隠蔽できます。ただし、対象サイトは依然としてIPをブロックする可能性があります。これは、自身のIPであれプロキシのIPであれ、同一アドレスから過剰なリクエストが送信された場合に発生します。
IP禁止を回避するには、プロキシIPを定期的にローテーションすることが不可欠です。リクエストを複数のIPアドレスに分散させることで、トラフィックが異なるユーザーから発信されているように見せかけられます。これにより検知される可能性が低減します。
プロキシローテーションを実装するには、まず信頼できるプロバイダーからプロキシのリストを取得します。それらを配列に保存します:
proxy_list = [
{"http": "<YOUR_PROXY_URL_1>", "https": "<YOUR_PROXY_URL_1>"},
# ...
{"http": "<YOUR_PROXY_URL_n>", "https": "<YOUR_PROXY_URL_n>"},
]
次に、random.choice() メソッドを使用してリストからランダムにプロキシを選択します:
random_proxy = random.choice(proxy_list)
Python標準ライブラリからrandomをインポートすることを忘れないでください:
import random
その後、get()リクエストでランダムに選択されたプロキシを設定します:
response = scraper.get("<YOUR_TARGET_URL>",プロキシ=random_プロキシ)
正しく設定されていれば、リクエストは実行ごとにリスト内の異なるプロキシを使用します。完全なコードは以下の通りです:
import cloudscraper
import random
# Cloudscraperスクレイパーのインスタンスの作成
scraper = cloudscraper.create_scraper()
# プロキシURLのリスト(実際のプロキシURLに置き換えてください)
proxy_list = [
{"http": "<YOUR_PROXY_URL_1>", "https": "<YOUR_PROXY_URL_1>"},
# ...
{"http": "<YOUR_PROXY_URL_n>", "https": "<YOUR_PROXY_URL_n>"},
]
# リストからランダムにプロキシを選択
random_proxy = random.choice(proxy_list)
# ランダムに選択したプロキシを使用してリクエストを送信
# (実際のターゲットURLに置き換えてください)
response = scraper.get("<YOUR_TARGET_URL>", proxies=random_proxy)
おめでとうございます!これでCloudscraperにプロキシローテーションを統合できました。
CloudScraperで認証プロキシを使用する
ほとんどのプロバイダーは認証済みプロキシサーバーを提供しており、有料ユーザーのみがアクセスできます。通常、これらのプロキシサーバーにアクセスするにはユーザー名とパスワードを指定する必要があります。
CloudScraperでプロキシを認証するには、必要な認証情報をプロキシURLに直接含める必要があります。ユーザー名とパスワードによる認証の形式は次の通りです:
<プロキシプロトコル>://<ユーザー名>:<パスワード>@<プロキシIPアドレス>:<プロキシポート>
この形式を使用すると、CloudScraperのプロキシ設定は次のようになります:
import cloudscraper
# Cloudscraperインスタンスの作成
scraper = cloudscraper.create_scraper()
# 認証済みプロキシを定義
proxies = {
"http": "<PROXY_PROTOCOL>://<YOUR_USERNAME>:<YOUR_PASSWORD>@<PROXY_IP_ADDRESS>:<PROXY_PORT>",
"https": "<PROXY_PROTOCOL>://<YOUR_USERNAME>:<YOUR_PASSWORD>@<PROXY_IP_ADDRESS>:<PROXY_PORT>"
}
# 指定された認証済みプロキシ経由でリクエストを実行
response = scraper.get("<YOUR_TARGET_URL>", proxies=proxies)
素晴らしい!Cloudflareでプレミアムプロキシを使用する方法を確認する準備が整いました。
Cloudscraperへのプレミアムプロキシ統合
本番環境でのスクレイピングで信頼性の高い結果を得るには、Bright Dataのようなトップクラスのプロバイダーのプロキシを使用すべきです。Bright Dataは195カ国に1億5000万以上のIPアドレスを擁する高品質ネットワークを有し、主要4種類のプロキシすべてをサポートしています:
- データセンタープロキシ
- レジデンシャルプロキシ
- ISPプロキシ
自動IPローテーション、100%稼働率、固定IPセッションなどの機能により、Bright Dataは市場をリードするプロキシプロバイダーとしての地位を確立しています。
CloudScraperにBright Dataのプロキシを統合するには、アカウントを作成またはログインしてください。ダッシュボードにアクセスし、テーブル内の「Residential」ゾーンをクリックします:
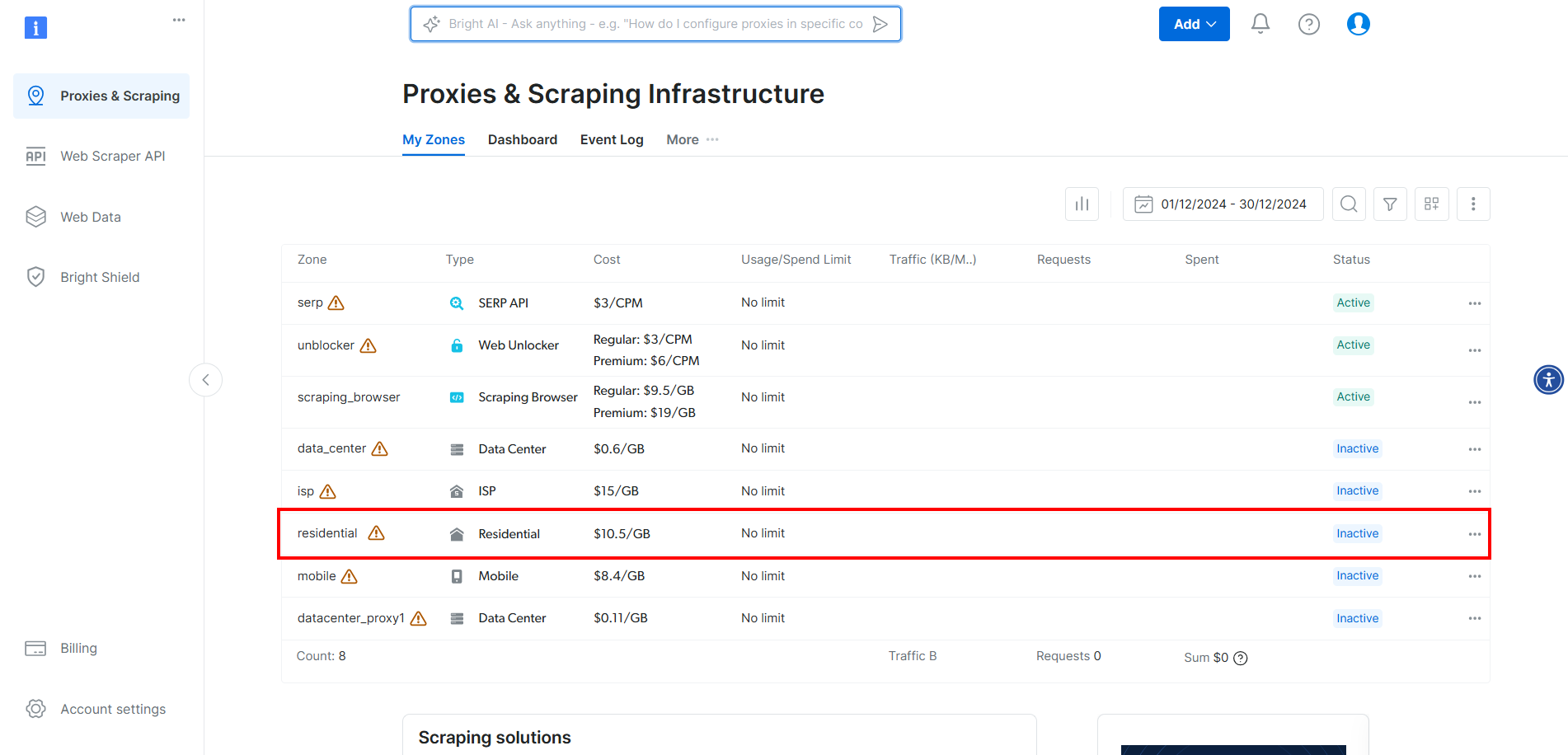
ここでトグルをクリックしてプロキシを有効化します:
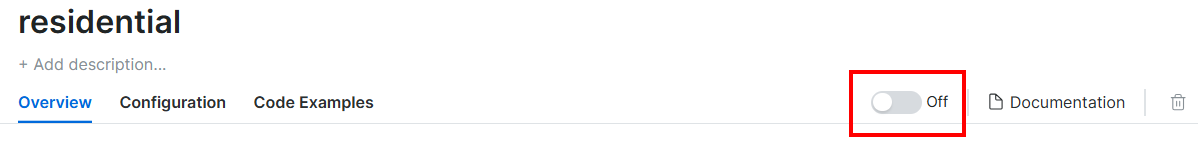
表示される画面は以下の通りです:

「アクセス詳細」セクションで、プロキシホスト、ユーザー名、パスワードをコピーします:
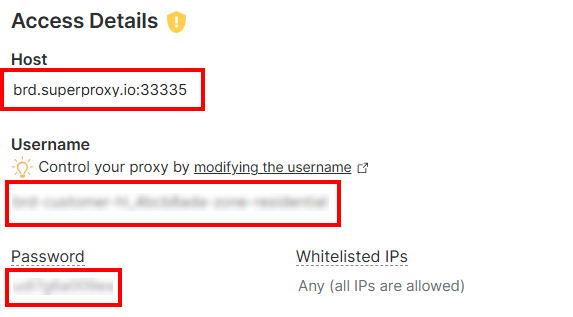
Bright DataプロキシURLは以下のような形式になります:
http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335
次に、プロキシをCloudscraperに以下のように統合します:
import cloudscraper
# CloudScraperインスタンスの作成
scraper = cloudscraper.create_scraper()
# Bright Dataプロキシの定義
proxies = {
"http": "http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335",
"https": "http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335"
}
# プロキシを使用してリクエストを実行
response = scraper.get("https://httpbin.io/ip", proxies=proxies)
# レスポンスを出力
print(response.text)
Bright Dataのレジデンシャルプロキシは自動的にローテーションされる点にご注意ください。スクリプトを実行するたびに異なるIPが割り当てられます。
これで完了です!CloudScraperプロキシ統合が完了しました。
まとめ
このチュートリアルでは、プロキシを活用してCloudscraperの効果を最大化する方法を学びました。Python版Cloudflareバイパスツールへのプロキシ統合の基本に加え、プロキシローテーションなどの高度なテクニックも探求しました。
Bright Dataのような一流プロバイダーの高品質プロキシサーバーを利用すれば、より良い結果を得ることが格段に容易になります。
Bright Dataは世界最高峰のプロキシサーバーを管理し、フォーチュン500企業を含む20,000社以上の顧客にサービスを提供しています。そのグローバルプロキシネットワークは以下の通りです:
- データセンター・プロキシ – 77万以上のデータセンターIP
- レジデンシャルプロキシ– 195ヶ国以上で1億5000万以上のレジデンシャルIP。
- ISPプロキシ – 70万以上のISP IPアドレス。
全体として、これは利用可能な最大規模かつ最も信頼性の高いプロキシネットワークの一つです。
Bright Dataの無料アカウントを作成し、プロキシサーバーをお試しください。





