

ウェブスクレイピングとは、様々なツールやプログラムを用いてウェブサイトから大量のデータを抽出・収集する自動化された技術です。HTMLテーブル(データが列と行で構成されているもの)の抽出に一般的に使用されます。収集されたデータは分析や研究に活用できます。詳細なガイドについては、HTMLウェブスクレイピングに関するこちらの記事をご覧ください。
このチュートリアルでは、Pythonを使用してウェブサイトからHTMLテーブルをスクレイピングする方法を学びます。
前提条件
チュートリアルを始める前に、Pythonバージョン3.8以降をインストールし、仮想環境を作成する必要があります。Pythonによるウェブスクレイピングが初めての方は、こちらの記事が役立つ出発点となります。
環境作成後、以下のPythonパッケージをインストールしてください:
- Requests
- Beautiful Soup
- pandas
以下のコマンドでパッケージをインストールできます:
pip install requests beautifulsoup4 pandas
ウェブページの構造を理解する
このチュートリアルでは、Worldometerウェブサイトのデータをウェブスクレイピングします。このウェブページには、2024年時点の各国人口を含む、世界各国の最新データが掲載されています:
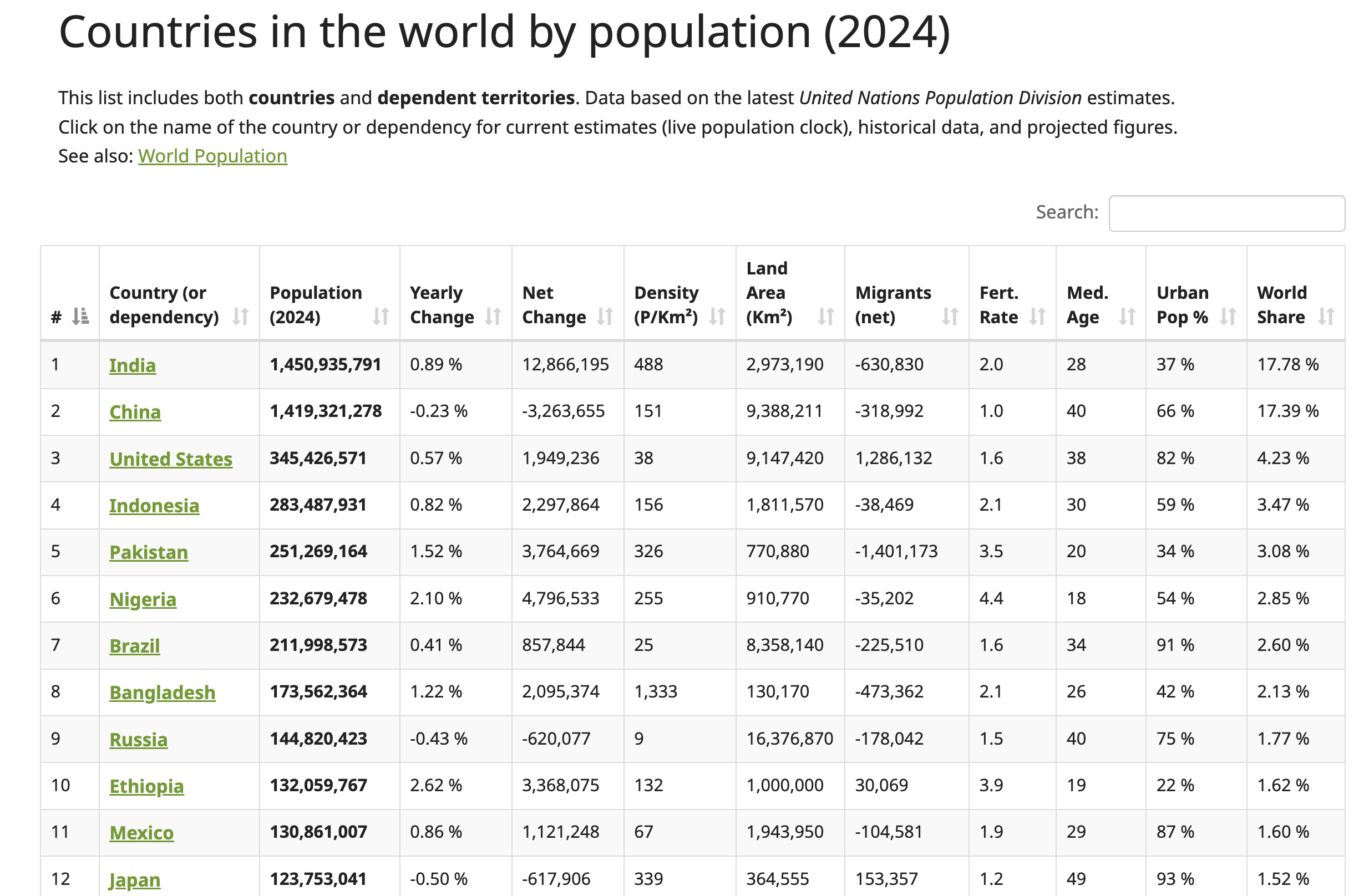
HTMLテーブル構造を確認するには、テーブル(前述のスクリーンショット参照)を右クリックし、「要素を検査」を選択します。これにより開発者ツールパネルが開き、ページのHTMLコードが表示され、選択した要素がハイライトされます:
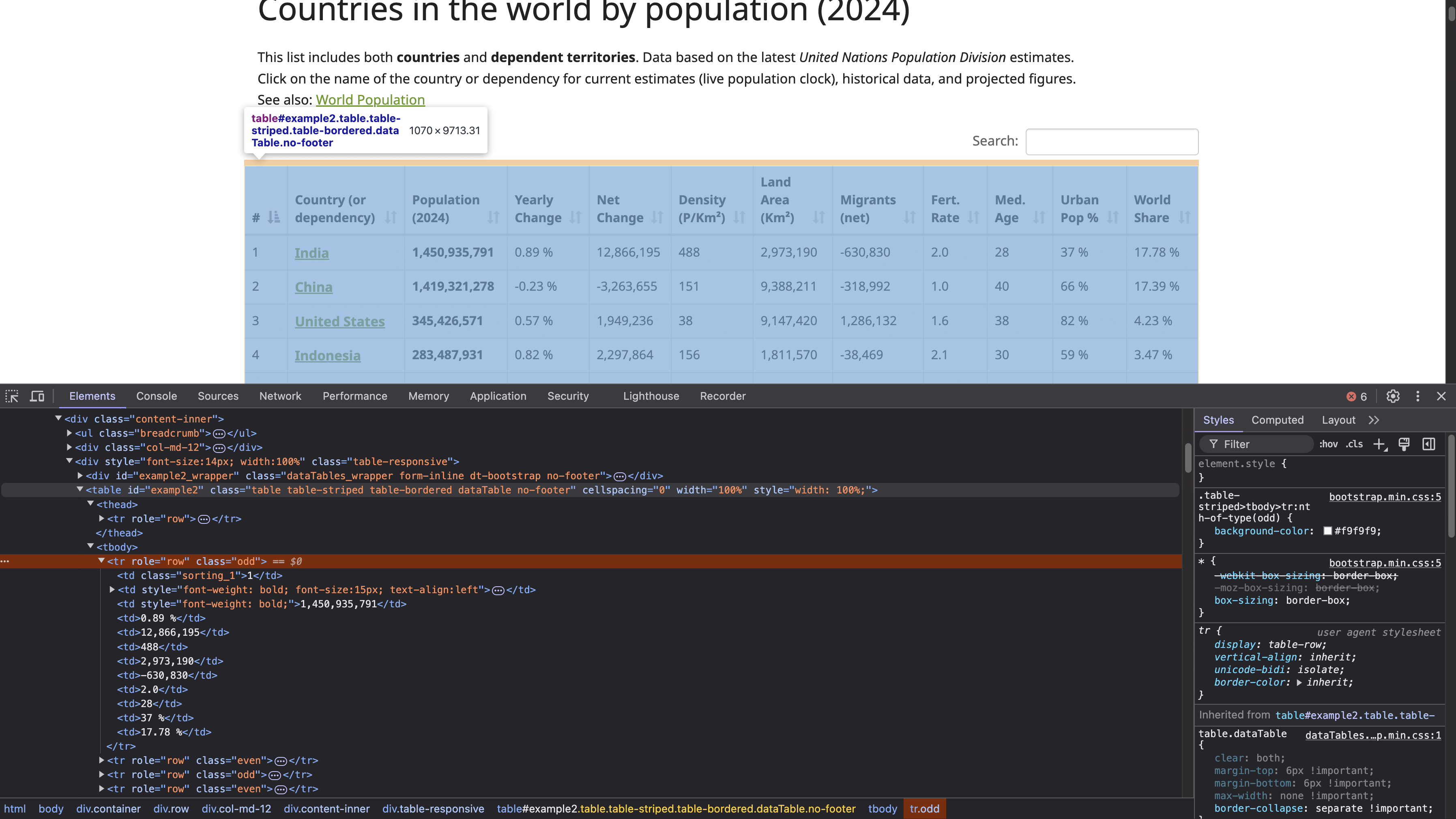
IDがexample2の <table>タグがテーブル構造の開始を定義します。このテーブルには<th>タグでヘッダーが定義され、各<tr>タグがテーブル内の新しい水平行を表す<tr>タグで行が定義されます。各<tr>内では、<td>タグがその行内の個々のセルを作成し、各セルに表示されるデータを保持します。
注意: スクラッピングを行う前に、データ使用や自動アクセスに関するすべての制限事項を遵守するため、必ずウェブサイトのプライバシーポリシーと利用規約を確認し、それに従ってください。
ウェブページにアクセスするためのHTTPリクエスト送信
HTTPリクエストを送信してウェブページにアクセスするには、Pythonファイル(例: html_table_scraper.py)を作成し、requests、BeautifulSoup、pandasパッケージをインポートします:
# パッケージのインポート
import requests
from bs4 import BeautifulSoup
import pandas as pd
次に、スクレイピング対象のウェブページのURLを定義し、https://www.worldometers.info/world-population/population-by-country/を使用してそのページにGETリクエストを送信します:
# ページコンテンツ取得のためサイトへリクエスト送信
url = 'https://www.worldometers.info/world-population/population-by-country/'
レスポンスが成功したかどうかを確認するには、Requestsのget()メソッドを使用してリクエストを送信します:
# URLのコンテンツを取得
response = requests.get(url)
# レスポンスの状態を確認
if response.status_code == 200:
print("リクエスト成功!")
else:
print(f"エラー: {response.status_code} - {response.text}")
このコードは指定されたURLにGETリクエストを送信し、レスポンスの状態を確認します。200レスポンスはリクエストが成功したことを示します。
ターミナルでPythonスクリプトを実行するには、次のコマンドを使用します:
python html_table_scraper.py
出力は次のようになります:
Request was successful!
GETリクエストが成功したため、HTMLテーブルを含むウェブページ全体のHTMLコンテンツを取得できました。
Beautiful Soup を使用した HTML のパース
Beautiful Soupは、ウェブページをスクレイピングする際に頻繁に遭遇する、不適切なフォーマットや破損したHTMLコンテンツを処理できます。ここでは、Beautiful Soupパッケージを使用して以下のことを行います:
- ウェブページからHTMLコンテンツをパースし、人口データを表示するテーブルを見つけます。
- テーブルのヘッダーを収集します。
- テーブルの行に表示されている全データを収集する。
収集したコンテンツをパースするには、Beautiful Soupオブジェクトを作成します:
# BeautifulSoupでHTMLコンテンツをパース
soup = BeautifulSoup(response.content, 'html.parser')
次に、HTML内でid属性 "example2"を持つテーブル要素を特定します。このテーブルには2024年の各国人口が記載されています:
# 人口データを含むテーブルを検索
table = soup.find('table', attrs={'id': 'example2'})
テーブルヘッダーの収集
テーブルのヘッダーは<thead>と<th>タグ内にあります。BeautifulSoupパッケージのfind()メソッドで<thead>タグ内のデータを抽出し、find_all()メソッドですべてのヘッダーを収集します:
# テーブルからヘッダーを収集
headers = []
# <thead>タグ内のヘッダー行を特定
header_row = table.find('thead').find_all('th')
for th in header_row:
# ヘッダーテキストをheadersリストに追加
headers.append(th.text.strip())
このコードは空のPythonリスト`headers`を作成し、<thead> HTMLタグを特定して<th> HTMLタグ内の全ヘッダーを検索し、収集した各ヘッダーを`headers`リストに追加します。
テーブル行データの収集
各行のデータを収集するには、スクレイピングしたデータを格納する空のPythonリストdataを作成します:
# データを格納する空のリストを初期化
data = []
次に、find_all() メソッドを使用してテーブルの各行のデータを抽出し、Python リストに追加します:
# ヘッダー行をスキップしてテーブルの各行をループ処理
for tr in table.find_all('tr')[1:]:
# 現在の行のデータをリスト化
row = []
# 現在の行にある全てのデータセルを検索
for td in tr.find_all('td'):
# セルのテキスト内容を取得し余分なスペースを除去
cell_data = td.text.strip()
# クリーンアップしたセルデータを行リストに追加
row.append(cell_data)
# 現在の行の全セル取得後、行をデータリストに追加
data.append(row)
# 収集データを扱いやすいpandas DataFrameに変換
df = pd.DataFrame(data, columns=headers)
# DataFrameを出力し行数・列数を確認
print(df.shape)
このコードは、表内のすべての<tr> HTMLタグを、ヘッダー行をスキップして2行目から開始して反復処理します。各行(<tr>)に対して、その行のセルデータを格納するための空のリストrowを作成します。row内部では、find_all()メソッドを使用して個々のデータセルを表すすべての<td> HTMLタグを検索します。
各<td> HTMLタグに対して、コードは.text属性を使用してテキストコンテンツを抽出し、.strip()メソッドを適用してテキストの先頭または末尾の空白を削除します。クリーンアップされたセルデータは行リストに追加されます。現在の行のすべてのセルを処理した後、行全体がデータリストに追加されます。 最後に、収集したデータをpandas DataFrameに変換し、ヘッダーリストで定義された列名で構成します。その後、データの形状を表示します。
完全なPythonスクリプトは以下のようになります:
# パッケージのインポート
import requests
from bs4 import BeautifulSoup
import pandas as pd
# ウェブサイトのページコンテンツ取得リクエスト送信
url = 'https://www.worldometers.info/world-population/population-by-country/'
# URLのコンテンツ取得
response = requests.get(url)
# リクエストが成功したか確認
if response.status_code == 200:
# Beautiful SoupでHTMLコンテンツをパース
soup = BeautifulSoup(response.content, 'html.parser')
# IDで人口データを含むテーブルを検索
table = soup.find('table', attrs={'id': 'example2'})
# テーブルからヘッダーを収集
headers = []
# <thead> HTMLタグ内のヘッダー行を特定
header_row = table.find('thead').find_all('th')
for th in header_row:
# ヘッダーテキストをheadersリストに追加
headers.append(th.text.strip())
# データを格納する空のリストを初期化
data = []
# ヘッダー行を除き、テーブルの各行をループ処理
for tr in table.find_all('tr')[1:]:
# 現在の行のデータをリスト化
row = []
# 現在の行にある全てのデータセルを検索
for td in tr.find_all('td'):
# セルのテキスト内容を取得し余分なスペースを除去
cell_data = td.text.strip()
# クリーンアップしたセルデータを行リストに追加
row.append(cell_data)
# この行の全セル取得後、行をデータリストに追加
data.append(row)
# 収集したデータを扱いやすいpandas DataFrameに変換
df = pd.DataFrame(data, columns=headers)
# DataFrameを出力して収集データを確認
print(df.shape)
else:
print(f"エラー: {response.status_code} - {response.text}")
ターミナルでPythonスクリプトを実行するには以下のコマンドを使用:
python html_table_scraper.py
出力は次のようになります:
(234,12)
ここまでで、HTMLテーブルから234行12列のデータを正常に抽出できました。
次に、pandasのhead()メソッドとprint()を使用して、抽出されたデータの最初の10行を表示します:
print(df.head(10))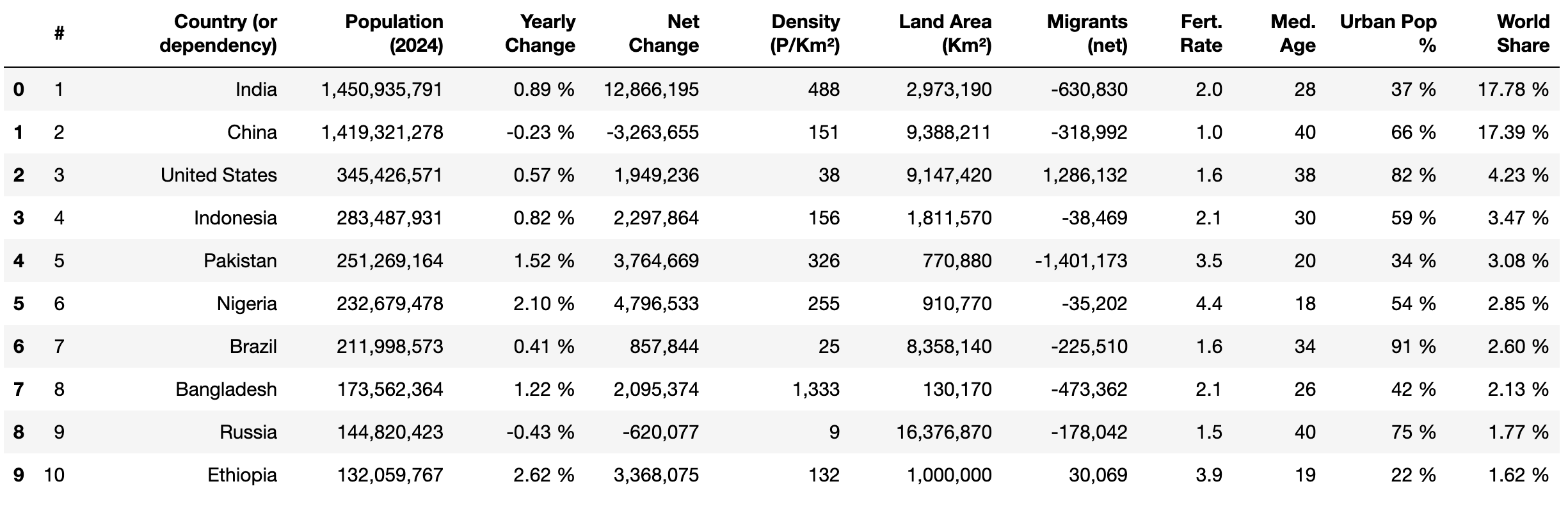
データのクリーニングと構造化
HTMLテーブルからデータをスクレイピングする際は、分析のための一貫性、正確性、適切な利用可能性を確保するために、データをクリーニングすることが重要です。HTMLテーブルから抽出された生のデータには、欠損値、書式の問題、不要な文字、誤ったデータ型など、さまざまな問題が含まれている可能性があります。これらの問題は、不正確な分析や信頼性の低い結果につながる可能性があります。適切なクリーニングは、データセットを標準化し、分析の意図した構造に合致させるのに役立ちます。
このセクションでは、以下のデータクリーニング作業を実施します:
- 列名の変更
- 行データに存在する欠損値の置換
- カンマの除去とデータ型の正しい形式への変換
- パーセント記号(%)の削除とデータ型の正しい形式への変換
- 数値列のデータ型を変更する
列名の変更
pandasにはrename()というメソッドがあり、特定の列名を任意の名前に変更できます。このメソッドは、列名が説明的でない場合や、列名を扱いやすくしたい場合に便利です。
特定の列名を変更するには、列パラメータに辞書を渡し、キーとして現在の列名を、値として割り当てたい新しい名前を指定します。以下の列名を変更するためにこのメソッドを適用します:
#→順位年次変化→年次変化率World Share→World Share %
# 列名変更
df.rename(columns={'#': 'Rank'}, inplace=True)
df.rename(columns={'Yearly Change': 'Yearly Change %'}, inplace=True)
df.rename(columns={'World Share': 'World Share %'}, inplace=True)
# 最初の5行を表示
print(df.head())
列は次のようになります:

欠損値の置換
データ内の欠損値は、平均や合計などの計算に影響を与え、不正確な結果や誤った洞察につながる可能性があります。データセットで計算や分析を行う前に、欠損値を削除、置換、または特定の値で埋める必要があります。
現在、 都市人口比率(%)列にはN.A.とラベル付けされた欠損値が含まれています。 pandasのreplace()メソッドを使用して、N.A. を0%で置換します:
# 'Urban Pop %'列の'N.A.'を'0%'に置換
df['Urban Pop %'] = df['Urban Pop %'].replace('N.A.', '0%')
パーセンテージ記号の削除とデータ型の変換
列「Yearly Change %」、「Urban Pop %」、「World Share %」には数値の後にパーセント記号が付いています(例: 37.0%)。これにより、平均値、最大値、標準偏差などの計算といった分析のための数学的操作が妨げられます。
これを修正するには、replace() メソッドで% 記号を削除し、astype() メソッドで分析用に浮動小数点データ型に変換します:
# '%'記号を削除しfloatに変換
df['Yearly Change %'] = df['Yearly Change %'].replace('%', '', regex=True).astype(float)
df['Urban Pop %'] = df['Urban Pop %'].replace('%', '', regex=True).astype(float)
df['World Share %'] = df['World Share %'].replace('%', '', regex=True).astype(float)
# 最初の5行を表示
df.head()
このコードは、replace()メソッドと正規表現を使用して、列「年次変化率(%)」、「都市人口比率(%)」、「世界シェア比率(%)」の値から%記号を削除します。その後、astype(float)を使用してクリーンアップされた値をfloatデータ型に変換します。最後に、df.head()を使用してDataFrameの最初の5行を表示します。
出力は次のようになります:

カンマの除去とデータ型の変換
現在、Population (2024)、Net Change、Density (P/Km²)、Land Area (Km²)、Migrants (net) 列の数値にはカンマが含まれています(例: 1,949,236)。これにより、分析のための数学的演算が不可能になります。
これを修正するには、replace() とastype() を適用してカンマを削除し、数値を整数データ型に変換します:
# カンマ除去と整数型変換
columns_to_convert = [
'Population (2024)', 'Net Change', 'Density (P/Km²)', 'Land Area (Km²)',
'Migrants (net)'
]
for column in columns_to_convert:
# まず列が文字列として扱われるようにする
df[column] = df[column].astype(str)
# カンマを削除
df[column] = df[column].str.replace(',', '')
# 整数に変換
df[column] = df[column].astype(int)
このコードは、処理が必要な列の名前を含むリストcolumns_to_convert を定義します。リスト内の各列について、astype(str) を使用して列の値が文字列として扱われるようにします。次に、str.replace(',', '') を使用して値からカンマを削除し、astype(int) でクリーンアップされた値を整数に変換します。これにより、値は数学演算に適したものになります。
数値列のデータ型を変更する
列Rank、Med. Age、Fert. Rate はオブジェクトデータ型で保存されているが数値を含むデータを保持しています。これらの列のデータを整数または浮動小数点データ型に変換し、数学演算を可能にします:
# 整数または浮動小数点データ型に変換
df['Rank'] = df['Rank'].astype(int)
df['Med. Age'] = df['Med. Age'].astype(int)
df['Fert. Rate'] = df['Fert. Rate'].astype(float)
このコードは、Rank列とMed. Age列の値を整数データ型に、Fert. Rate列の値を浮動小数点データ型に変換します。
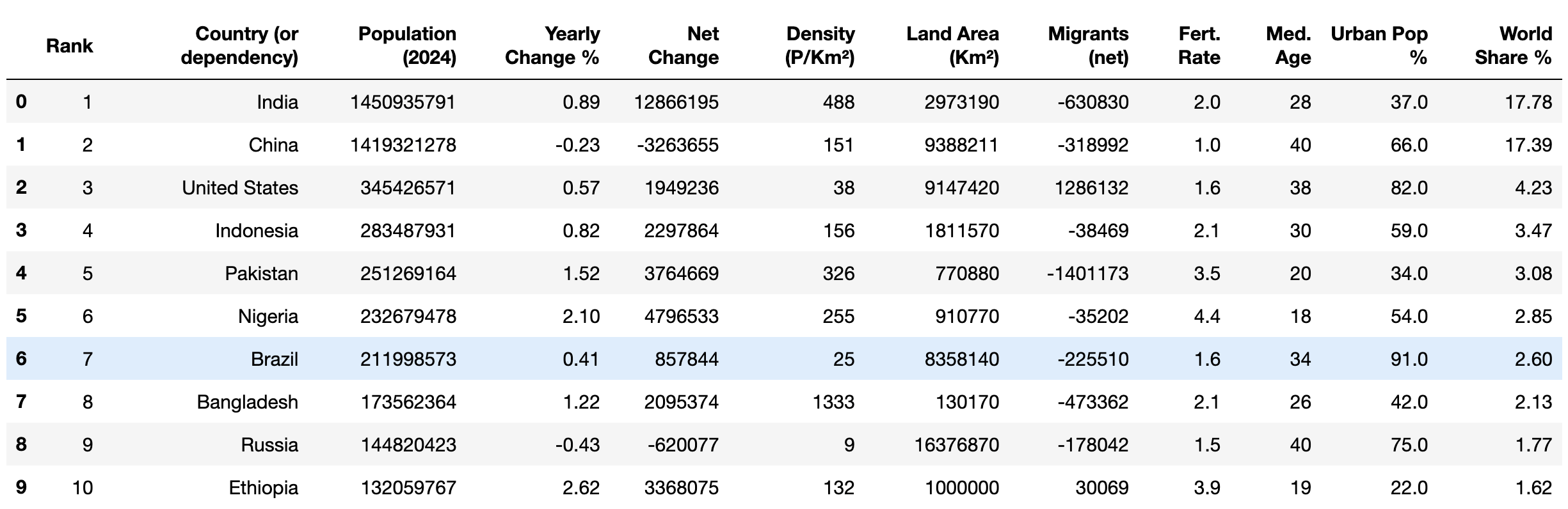
最後に、head()メソッドを使用して、クリーニング後のデータが正しいデータ型であることを確認します:
print(df.head(10))
出力は次のようになります:
データがクリーンアップされたので、平均や最頻値などの数学的操作や、相関などの分析手法を適用してデータを調査できます。
クリーンアップしたデータのCSVエクスポート
データクリーニング後は、将来の使用や分析のためにクリーニング済みデータを保存することが重要です。クリーニング済みデータをCSVファイルにエクスポートすることで、他者との共有や、各種対応ツール・ソフトウェアを用いたさらなる処理/分析を容易に行えます。
pandasのto_csv()メソッドを使用すると、DataFrameからworld_population_by_country.csvという名前のCSVファイルにデータをエクスポートできます:
# データをファイルに保存
filename = 'world_population_by_country.csv'
df.to_csv(filename, index=False)
結論
Beautiful Soup Pythonパッケージを使用すると、HTMLドキュメントをパースし、HTMLテーブルからデータを抽出することが可能になります。本記事では、データのスクレイピング、クリーニング、CSVファイルへのエクスポート方法を学びました。
このチュートリアルは単純でしたが、複雑なウェブサイトからのデータ抽出は困難で時間がかかる場合があります。例えば、ページ分割されたHTMLテーブルや、親要素と子要素にデータが埋め込まれたネスト構造を扱うには、レイアウトを理解するための慎重な分析が必要です。さらに、ウェブサイトの構造は時間とともに変化する可能性があるため、コードとインフラストラクチャの継続的なメンテナンスが必要となります。
時間を節約し作業を容易にするため、Bright DataウェブスクレイパーAPIの利用をご検討ください。この強力なツールは事前構築済みのウェブスクレイピングソリューションを提供し、最小限の技術知識で複雑なウェブサイトからデータを抽出できます。APIはデータ収集を自動化し、動的コンテンツ、JavaScriptでレンダリングされたページ、CAPTCHA認証といった課題に対処します。
今すぐ登録して、WebスクレイパーAPIの無料トライアルを開始しましょう!





