

TL;DR: このチュートリアルでは、Rubyでサイトからデータを抽出する方法と、Rubyがスクレイピングに最も効果的な言語の1つである理由を学びます。
本ガイドでは、以下について説明します。
- Rubyはウェブスクレイピングに適しているか?
- 最高のRubyウェブスクレイピング用gem
- Rubyでウェブスクレイパーを構築する
Rubyはウェブスクレイピングに適しているか?
Rubyは、関数型、オブジェクト指向型、および手続き型の開発をサポートする、インタープリタ式でオープンソースの動的型付けプログラミング言語です。シンプルで、書きやすく、自然に読めるエレガントな構文になるよう設計されています。生産性に重点を置いているため、ウェブスクレイピングを含むいくつかの用途で人気があります。
特に、Rubyはサードパーティ製のライブラリが充実しているため、スクレイピングに最適です。これは「gem」と呼ばれ、ほとんどすべてのタスクに存在します。ウェブ上の情報をプログラムで取得する場合、ページをダウンロードしてHTMLコンテンツを解析し、そこらからデータを抽出するためのgemが存在します。
まとめると、Rubyでのウェブスクレイピングは、利用可能な数多くのライブラリのおかげで、実行可能なだけでなく、簡単でもあります。どれが一番人気なのか調べてみましょう!
最高のRubyウェブスクレイピング用gem
ここでは、Rubyに最適なウェブスクレイピングライブラリを3つ紹介します。
- Nokogiri(鋸):HTML/XMLドキュメントを走査して操作するための完全なAPIを備えた堅牢かつ柔軟なHTML/XML解析ライブラリ。これを使って、ドキュメントから関連データを簡単に抽出できます。
- Mechanize:ウェブサイトとの対話処理を自動化するための高レベルなAPIを提供する、ヘッドレスブラウザ機能を備えたライブラリ。Cookieの保存と送信、リダイレクトの処理、リンクの追跡、フォームの送信などを実行できます。また、訪問したサイトを把握するための履歴も提供します。
- Selenium:ウェブページで自動テストを実行するための最も人気のあるフレームワークのRubyバインディング。人間のユーザーと同じようにウェブサイトと対話処理を行うよう、ブラウザに指示することができます。この技術は、ボット対策ソリューションを回避したり、データのレンダリングや取得にJavaScriptを使用しているサイトをスクレイピングしたりする上で重要な役割を果たします。
前提条件
コードを記述する前に、お使いのマシンにRubyをインストールする必要があります。お使いのオペレーティングシステムに応じ、以下のガイドに従ってください。
macOSにRubyをインストールする
macOSには、2015年にリリースされたバージョン10.11(El Capitan)以降、Rubyがデフォルトで搭載されています。macOSがネイティブでRubyに依存して一部の機能を提供していることを考えると、Rubyに手を加えるべきではありません。brew install rubyやupdate ruby macでネイティブRubyのバージョンを更新することは、一部の組み込み機能が壊れる可能性があるため、推奨されません。
WindowsにRubyをインストールする
RubyInstallerパッケージをダウンロードして起動し、インストールウィザードに従ってRubyをセットアップします。システムの再起動が必要になる場合があります。Windows 10以降の場合はWindows Subsystem for Linuxを使用して、以下の手順でRubyをインストールすることもできます。
LinuxにRubyをインストールする
LinuxでRubyの環境をセットアップする一番良い方法は、パッケージマネージャーを介してインストールすることです。
DebianとUbuntuでは、次のように起動します。
sudo apt-get install ruby-full他のディストリビューションでは、実行するターミナルコマンドが異なります。サポートされるすべてのパッケージ管理システムを確認するには、公式サイトのガイドを参照してください。
OSに関係なく、Rubyが動作していることを次の方法で確認できます。
ruby -vこれにより、以下のように出力されるはずです。
ruby 3.2.2 (2023-03-30 revision e51014f9c0)素晴らしい!これで、Rubyによるウェブスクレイピングを始める準備が整いました!
Rubyでウェブスクレイパーを構築する
このセクションでは、Rubyウェブスクレイパーを作成する方法を説明します。この自動化スクリプトは、Bright Dataのホームページからデータを取得します。具体的には以下の通りです。
- ターゲットサイトに接続する
- DOMから目的のHTML要素を選択する
- それらからデータを抽出する
- スクレイピングしたデータをCSVやJSONなどの探索しやすい形式に変換する
この記事の執筆時点では、ユーザーがターゲットウェブページにアクセスすると、以下のような表示になります。
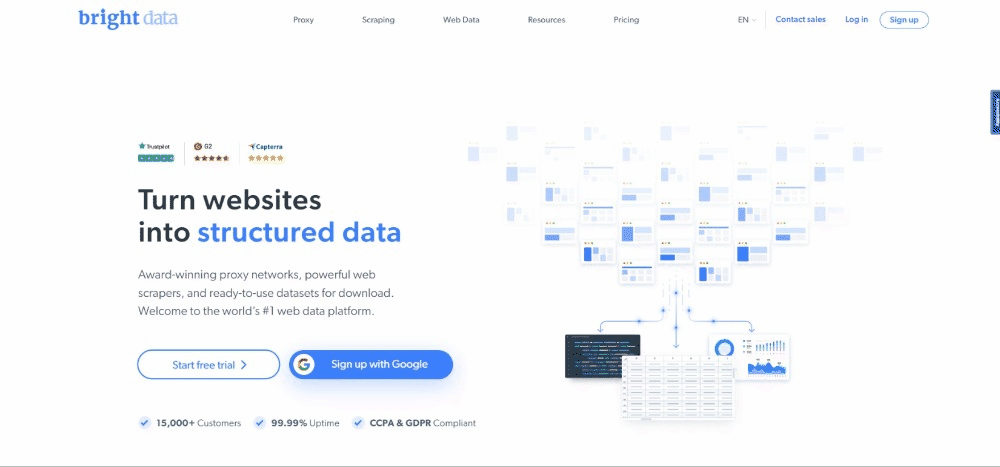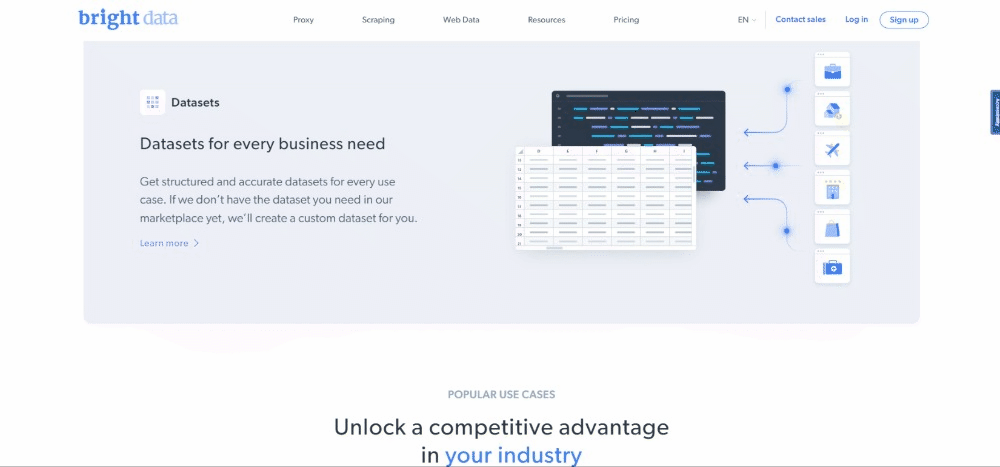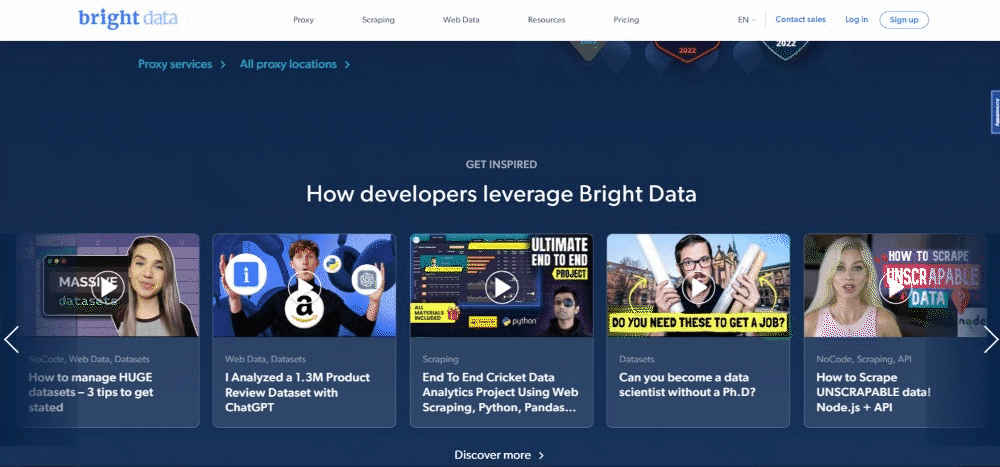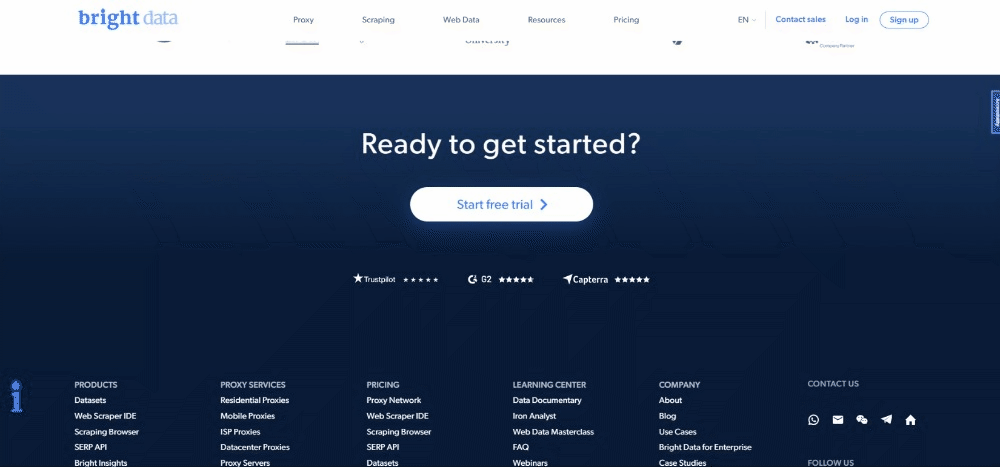
なお、BrightDataのホームページは頻繁に変更されるため、この記事をお読みになっている時点では表示が代わっている可能性があります。
スクレイピングの具体的目標は、以下のカードに含まれるユースケース情報を取得することです。
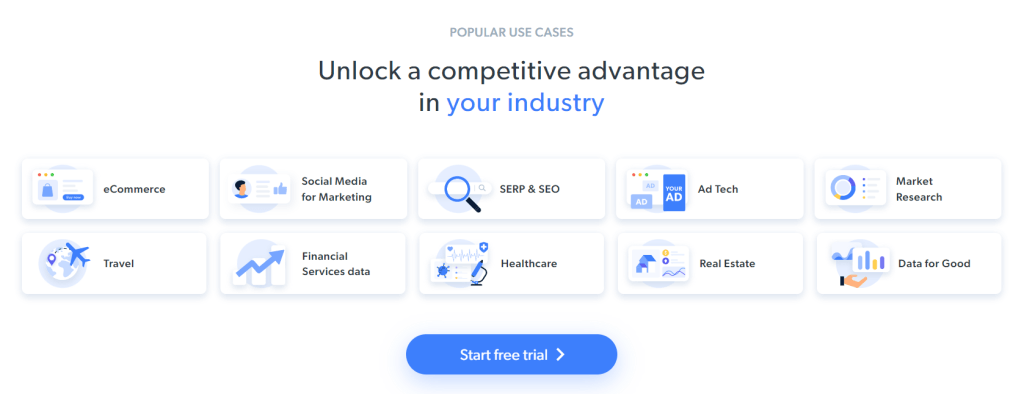
以下のステップバイステップのチュートリアルに沿って、Rubyでウェブスクレイピングを行う方法を学びましょう!
ステップ1:Rubyプロジェクトを初期化する
始める前に、Rubyプロジェクトをセットアップする必要があります。ターミナルを起動し、次のように入力してプロジェクトフォルダを作成し、その中に入ります。
mkdir ruby-web-scraper
cd ruby-web-scraperruby-web-scraperディレクトリにスクレイパーが入ります。
次に、プロジェクトフォルダ内のscraper.rbファイルを以下の内容で初期化します。
puts "Hello, World!"上のスニペットは、最も簡単なRubyスクリプトです。
ターミナルで実行して、動作することを確認します。
ruby scraper.rb次のメッセージが出力されるはずです。
Hello, World!プロジェクトをIDEにインポートして、高度なRubyスクレイピングロジックの定義を始めましょう!このガイドでは、Ruby開発用にVisual Studio Code(VS Code)をセットアップする方法を説明します。または、他のRuby IDEも使用してもかまいません。
VS CodeはRubyをネイティブにサポートしていないため、まずRubyの拡張機能を追加する必要があります。Visual Studio Codeを起動し、左バーの「拡張機能」アイコンをクリックし、上部の検索入力に「Ruby」と入力します。
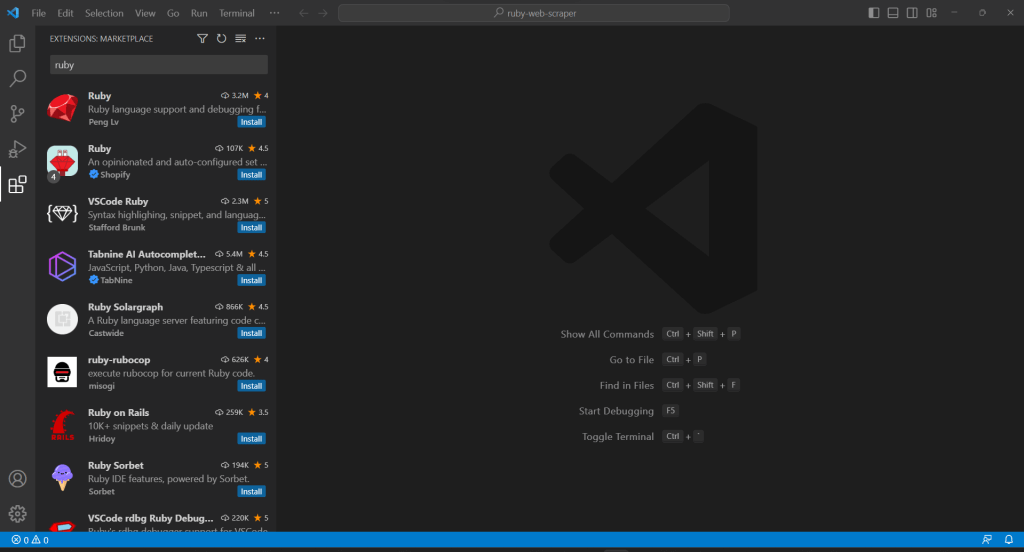
最初の要素の「インストール」ボタンをクリックすると、VS CodeにRubyのハイライト機能が追加されます。IDEにプラグインが追加されるまで待ちます。次に、「ファイル」、「フォルダを開く…」で、ruby-web-scraperフォルダを開きます。
「エクスプローラー」バーの下にあるscraper.rbファイルをクリックして、ファイルの編集を開始します。
ステップ2:スクレイピングライブラリを選択する
Rubyでウェブスクレイパーを構築する場合、適切なライブラリがあれば簡単です。そのため、先に紹介したgemの1つを採用します。どのウェブスクレイピングRubyライブラリが自分の目的に最も合うかを判断するには、時間をかけてターゲットサイトを分析する必要があります。
そのため、ブラウザでターゲットページにアクセスし、背景の何もないところで右クリックして、「検査」オプションをクリックします。これにより、ブラウザの開発者ツールが起動します。Chromeで「ネットワーク」タブを表示し、「Fetch/XHR」セクションを調べます。
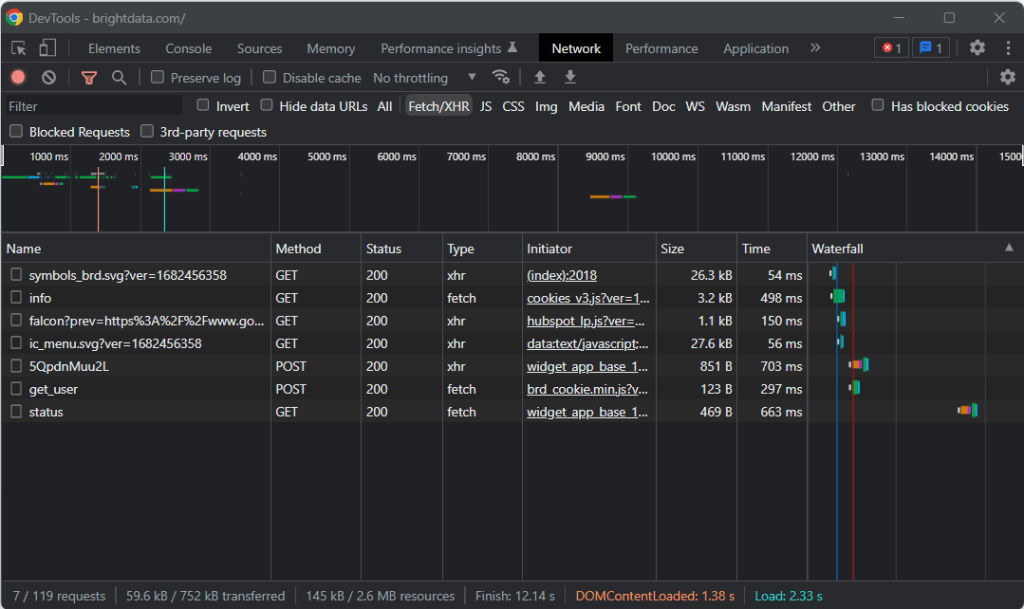
上のスクリーンショットでわかるように、AJAXリクエストは7つしかありません。それぞれのXHR呼び出しを詳しく調べてみると、意味のあるデータを一切含んでいないことがわかります。これは、ターゲットページがレンダリング時にコンテンツを取得しないことを意味します。したがって、サーバーから返されるHTMLドキュメントには、ユーザーに表示する全データがすでに含まれていることになります。
これは、ターゲットのウェブページがデータの取得やレンダリングの目的でJavaScriptを使用していないことを証明するものです。つまり、ウェブスクレイピングを行うのに、ヘッドレスブラウザ機能を備えたgemは必要ありません。それでもMechanizeやSeleniumを使うことはできますが、パフォーマンスのオーバーヘッドがいくらか増えるだけでしょう。結局、バックグラウンドでブラウザのインスタンスを動かしているので、リソースを消費します。
結局のところ、NokogiriのようなシンプルなHTML/XMLパーサーを選ぶとよいでしょう。以下のように、nokogiri gem経由でインストールします。
gem install nokogiri次に、scraper.rbファイルの先頭に以下の行を追加することで、ライブラリをインポートできます。
require "nokogiri"Ruby IDEがエラーを報告していないことを確認してください。これで、Rubyで一部のデータをスクレイピングできるようになりました!
ステップ3:HTTPartyを使用してターゲットページを取得する
ターゲットページのHTMLドキュメントを解析するには、まずHTTP GETリクエストを通じてダウンロードする必要があります。RubyにはNet::HTTPという組み込みのHTTPクライアントが付属していますが、その構文は少し複雑で直感的ではありません。代わりにHTTPartyを使うべきです。これはHTTPリクエストを実行するための最も一般的なRubyライブラリです。
httparty gemを使ってインストールします。
gem install httparty
Then, import it in the scraper.rb file:
require "httparty"
Use HTTParty to connect to the target page with:
response = HTTParty.get("https://brightdata.com/")get()メソッドを使用すると、パラメータとして渡されたURLに対してGETリクエストを実行できます。response.bodyフィールドには、サーバーから返されたHTMLドキュメントが含まれます。
なお、get()経由でのHTTPリクエストは失敗することがあります。その場合、HTTPartyは例外を発生させ、エラーでスクリプトの実行を停止します。失敗の背後にある理由はさまざまですが、通常、ターゲットサイトが採用しているアンチボット技術が、自動化されたリクエストを傍受してブロックしたことが原因です。最も基本的なアンチスクレイピングシステムは、有効なUser-Agent HTTPヘッダーがないリクエストをフィルタリングで除外する傾向があります。詳しくは、ウェブスクレイピング用のUser-Agentに関する記事をご覧ください。
他のHTTPクライアントと同様に、HTTPartyはプレースホルダーUser-Agentを使用します。通常、これは一般的なブラウザで使用されるエージェントとは大きく異なるため、ボット対策ソリューションでそのリクエストを簡単に発見できます。それが原因でブロックされるのを避けるために、以下のようにHTTPartyで有効なUser-Agentを指定できます。
response = HTTParty.get("https://brightdata.com/", {
headers: { "User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"},
})このget()で実行されたリクエストは、Google Chrome 112から来たものとしてサーバーに表示されます。
現在のscraper.rbの内容は以下の通りです。
require "nokogiri"
require "httparty"
# get the target page
response = HTTParty.get("https://brightdata.com/", {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
},
})
# scraping logic...
ステップ4:Nokogiriを使用してHTMLドキュメントを解析する
ターゲットウェブページに関連付けられたHTMLドキュメントを解析するには、そのコンテンツをNokogiri HTML()関数に渡します。
doc = Nokogiri::HTML(response.body)これで、doc変数を通じて提供されるDOM操作と探索APIを使用できます。特に、HTML要素を選択する方法として、最も重要なものは次の2つです。
どちらのアプローチも有効ですが、通常はCSSクエリが探しているものを表現する最も簡単な方法です。
ステップ5:対象のHTML要素用のCSSセレクタを定義する
ターゲットページ上で目的のHTML要素を選択する方法を理解するには、DOMを分析する必要があります。ブラウザでBright Dataホームページにアクセスし、興味のあるカードを右クリックして、「検査」を選択します。
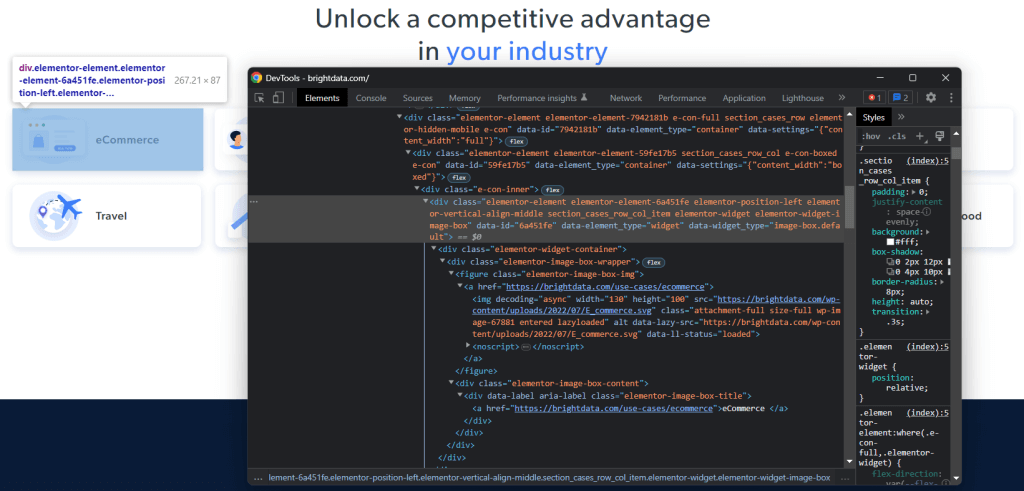
時間を取って、DevToolsのセクションのHTMLコードを調べてください。各ユースケースカードは
- 業界に関連付けられた画像を表示する<img> HTML要素と、業界ページのURLを含む<a>要素を持つ<figure>。
- <a>タグ内に業界名を格納した<div> HTML要素。
Rubyスクレイパーのデータ抽出目標は、各カードから画像URL、ページURL、業界名を取得することです。
適切なCSSセレクタを定義するには、対象となるDOMノードに割り当てられたCSSクラスに注目してください。以下のCSSセレクタを使用すると、すべてのユースケースカードを取得できることがわかります。
.section_cases_row_col_itemカードを指定したら、以下を使用して、その<figure>と<div>の子から関連データを格納しているノードを選択できます。
- figure img
- figure a
- .elementor-image-box-content a
ステップ6:Nokogiriを使用してウェブページからデータをスクレイピングする
次に、Nokogiriを使って、ターゲットHTMLウェブページから目的のデータを取得する必要があります。
データスクレイピングのロジックに入る前に、収集したデータを格納するためのデータ構造が必要であることを忘れてはなりません。そのために、Structを使用して1行でUseCaseクラスを定義できます。
UseCase = Struct.new(:image, :url, :name)Rubyでは、Structを使って、1つ以上の属性を同じデータクラス内にバンドルできます。上記の構造体には、各ユースケースカードから取得する情報に対応する3つの属性があります。
UseCaseの空の配列を初期化し、それに入力するためのスクレイピングロジックを実装します。
# initialize the list of objects
# that will store all retrieved data
use_cases = []
# select all use case HTML elements
use_case_cards = doc.css(".section_cases_row_col_item")
# iterate over the HTML cards
use_case_cards.each do |use_case_card|
# extract the data of interest
image = use_case_card.at_css("figure img").attribute("data-lazy-src").value
url = use_case_card.at_css("figure a").attribute("href").value
name = use_case_card.at_css(".elementor-image-box-content a").text
# instantiate an UseCase object with the
# collected data
use_case = UseCase.new(url, image, name)
# add the UseCase instance to the array
# of scraped objects
use_cases.push(use_case)
end上記のスニペットは、すべてのユースケースカードを選択し、それらを反復処理します。次に、at_css()を使用して、各カードから画像URL、業界ページURL、名前をスクレイピングします。これは、CSSクエリに一致する最初の要素を返すNokogiri関数で、次のショートカットを表します。
image = use_case_card.css("figure img").first.attribute("data-lazy-src").value最後に、取得したデータを使って新しいUseCaseオブジェクトをインスタンス化し、リストに追加します。
Nokogiriを使ったRubyによるウェブスクレイピングは、とても簡単です。attribute()を使うと、現在のHTML要素から属性を選択できます。次に、値フィールドを使用してその値を取得できます。同様に、テキストフィールドは、現在のHTMLノードに含まれるすべてのテキストをプレーン文字列として直接返します。
ここで、さらに進んで、ユースケースの業界ページもスクレイピングできます。ここで発見したリンクをたどって、それに合わせた新しいスクレイピングロジックを実装できます。ウェブクローリングとウェブスクレイピングの世界へようこそ!
素晴しいです!これで、Rubyを使用してスクレイピングの目標を達成する方法を学ぶことができました。ただし、学ぶべきことはまだいくつかあります。
ステップ7:スクレイピングしたデータをエクスポートする
each()ループの後、use_casesにはRubyオブジェクトでスクレイピングされたデータが格納されます。これは、他のチームにデータを提供するのに最適なフォーマットではありません。幸い、RubyにはCSVやJSONに変換する機能が組み込まれています。取得したデータをCSVやJSONにエクスポートする方法を説明します。
CSVにエクスポートする場合は、次のgemをインポートします。
import "csv"これはRuby標準APIの一部で、CSVファイルやデータを扱うための完全なインターフェースを提供します。
これを利用して、以下のようにuse_casesの配列をoutput.csvファイルにエクスポートできます。
# populate the CSV output file
CSV.open("output.csv", "wb") do |csv|
# write the CSV header
csv << ["url", "image", "name"]
# transfrom each use case scraped info to a
# CSV record
use_cases.each do |use_case|
csv << use_case
end
end上記のスニペットでは、output.csvファイルが作成されます。次にそれを開き、ヘッダーレコードで初期化します。次に、use_cases配列を反復処理して、CSVファイルに追記します。<<演算子を使用すると、Rubyは組み込みCSVクラスの要求に応じて、各use_caseインスタンスを文字列の配列に自動的に変換します。
次のコマンドを使用してスクリプトを実行してみます。
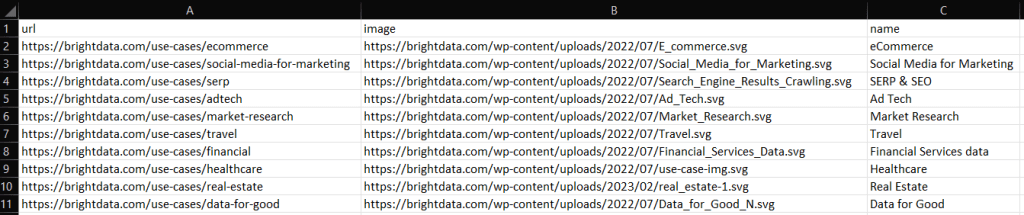
ruby scraper.rbプロジェクトのルートディレクトリに、以下のデータを含むoutput.csvファイルが生成されます。
同様に、use_casesをoutput.jsonにエクスポートできます。
# propulate the JSON output file
File.open("output.json", "wb") do |json|
json << JSON.pretty_generate(use_cases.map { |u| Hash[u.each_pair.to_a] })
endこれにより、以下のJSONファイルが生成されます。
[
{
"image": "https://brightdata.com/use-cases/ecommerce",
"url": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"name": "eCommerce "
},
// ...
{
"image": "https://brightdata.com/use-cases/data-for-good",
"url": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"name": "Data for Good"
}
]はい、できました!これで、Rubyで構造体の配列をCSVやJSONに変換する方法がわかりました!
ステップ8:すべてをまとめる
Rubyスクレイパーの完全なコードは以下の通りです。
# scraper.rb
require "nokogiri"
require "httparty"
require "csv"
# get the target page
response = HTTParty.get("https://brightdata.com/", {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
},
})
# parse the HTML document retrieved with the GET request
doc = Nokogiri::HTML(response.body)
# define a class where to keep the scraped data
UseCase = Struct.new(:image, :url, :name)
# initialize the list of objects
# that will store all retrieved data
use_cases = []
# select all use case HTML elements
use_case_cards = doc.css(".section_cases_row_col_item")
# iterate over the HTML cards
use_case_cards.each do |use_case_card|
# extract the data of interest
image = use_case_card.at_css("figure img").attribute("data-lazy-src").value
url = use_case_card.at_css("figure a").attribute("href").value
name = use_case_card.at_css(".elementor-image-box-content a").text
# instantiate an UseCase object with the
# collected data
use_case = UseCase.new(url, image, name)
# add the UseCase instance to the array
# of scraped objects
use_cases.push(use_case)
end
# populate the CSV output file
CSV.open("output.csv", "wb") do |csv|
# write the CSV header
csv << ["url", "image", "name"]
# transfrom each use case scraped info to a
# CSV record
use_cases.each do |use_case|
csv << use_case
end
end
# propulate the JSON output file
File.open("output.json", "wb") do |json|
json << JSON.pretty_generate(use_cases.map { |u| Hash[u.each_pair.to_a] })
end50行程度のコードで、Rubyによるデータスクレイピングスクリプトを作成できます!
まとめ
このチュートリアルでは、Rubyがインターネットのスクレイピングに最適な言語であることを理解できました。また、ウェブスクレイピングに最適なRuby gemライブラリは何か、およびその理由と、それらが提供する機能を確認することもできました。次に、NokogiriとRubyの標準APIを使って、実世界のターゲットをスクレイピングできるRubyスクレイパーを構築する方法を学びました。ご覧いただいた通り、Rubyを使用したデータクレイピングには、ほんの数行のコードしか必要としません。
しかし、ウェブページからデータを抽出する場合、既存の課題を軽視しないでください。というのも、データを保護するためにボット対策やスクレイピング対策のシステムを導入するサイトが増えているためです。これらの技術により、スクレイピングRubyスクリプトが実行するリクエストを検出し、サイトへのアクセスを防止することができます。幸い、Bright Dataの次世代Web Scraper IDEを使えば、これらのブロックを回避するウェブスクレイパーを構築できます。
ウェブスクレイピングに取り組むつもりは一切ないとしても、ウェブデータには興味がおありですか?すぐに利用できる当社のデータセットをご検討ください。






