このガイドでは以下を学びます:
- LinkedInスクレイパーとは何か
- LinkedInのウェブスクレイピングとAPI経由のデータ取得の比較
- LinkedInのログイン壁を回避する方法
- PythonでLinkedInスクレイピングスクリプトを構築する方法
- よりシンプルで効果的な解決策でLinkedInデータを取得する方法
さあ、始めましょう!
LinkedInスクレイパーとは?
LinkedInスクレイパーとは、LinkedInページから自動的にデータを抽出するツールです。通常、プロフィール、求人情報、企業ページ、記事などの人気ページを対象とします。
スクレイパーはこれらのページから重要な情報を収集し、CSVやJSONなどの有用な形式で提供します。このデータは、リードジェネレーション、求人検索、競合分析、市場トレンドの特定など、様々な用途で価値があります。
LinkedInウェブスクレイピング vs LinkedIn API
LinkedInは公式APIを提供しており、開発者はプラットフォームと連携して一部のデータを取得できます。では、なぜLinkedInのウェブスクレイピングを検討すべきなのでしょうか?その答えはシンプルで、4つの重要なポイントに関わっています:
- APIが返すデータはLinkedInが定義したサブセットに限定され、ウェブスクレイピングで取得可能なデータ量より大幅に少ない場合があります。
- APIは時間の経過とともに変更される可能性があり、アクセス可能なデータに対する制御が制限される。
- LinkedInのAPIは主にマーケティングや営業の連携を目的としており、特に無料ユーザー向けです。
- LinkedIn APIは月額数十ドルの費用がかかるにもかかわらず、取得可能なデータやプロファイル数に厳しい制限が課されています。
LinkedInデータ取得の2つの手法を比較した結果、以下の要約表が得られます:
| 項目 | LinkedIn API | Linkedinウェブスクレイピング |
|---|---|---|
| データ可用性 | LinkedInが定義するデータサブセットに限定 | サイト上のすべての公開データへのアクセス |
| データ管理 | LinkedInが提供するデータを管理 | 取得したデータに対する完全な管理権限 |
| 焦点 | 主にマーケティングおよび営業統合向け | LinkedIn上の任意のページをターゲットに可能 |
| 費用 | 月額数十ドルかかる場合あり | 直接的な費用は発生しない(インフラコストを除く) |
| 制限事項 | 月間プロファイル数とデータ量に制限あり | 厳格な制限なし |
詳細については、ウェブスクレイピングとAPIの比較ガイドをご覧ください。
LinkedInからスクレイピングすべきデータ
LinkedInからスクレイピング可能なデータの一例:
- プロフィール:個人情報、職務経歴、学歴、コネクションなど
- 企業情報:会社概要、従業員リスト、求人情報など
- 求人情報:職務内容、応募方法、選考基準など
- 求人ポジション:職種、企業名、勤務地、給与など
- 記事:公開投稿、ユーザー執筆記事など
- LinkedIn Learning:コース、認定資格、学習パスなど
LinkedInのログイン壁を回避する方法
Google検索後、シークレットモード(またはログアウト状態)でLinkedIn求人ページに直接アクセスすると、以下のような画面が表示されます:
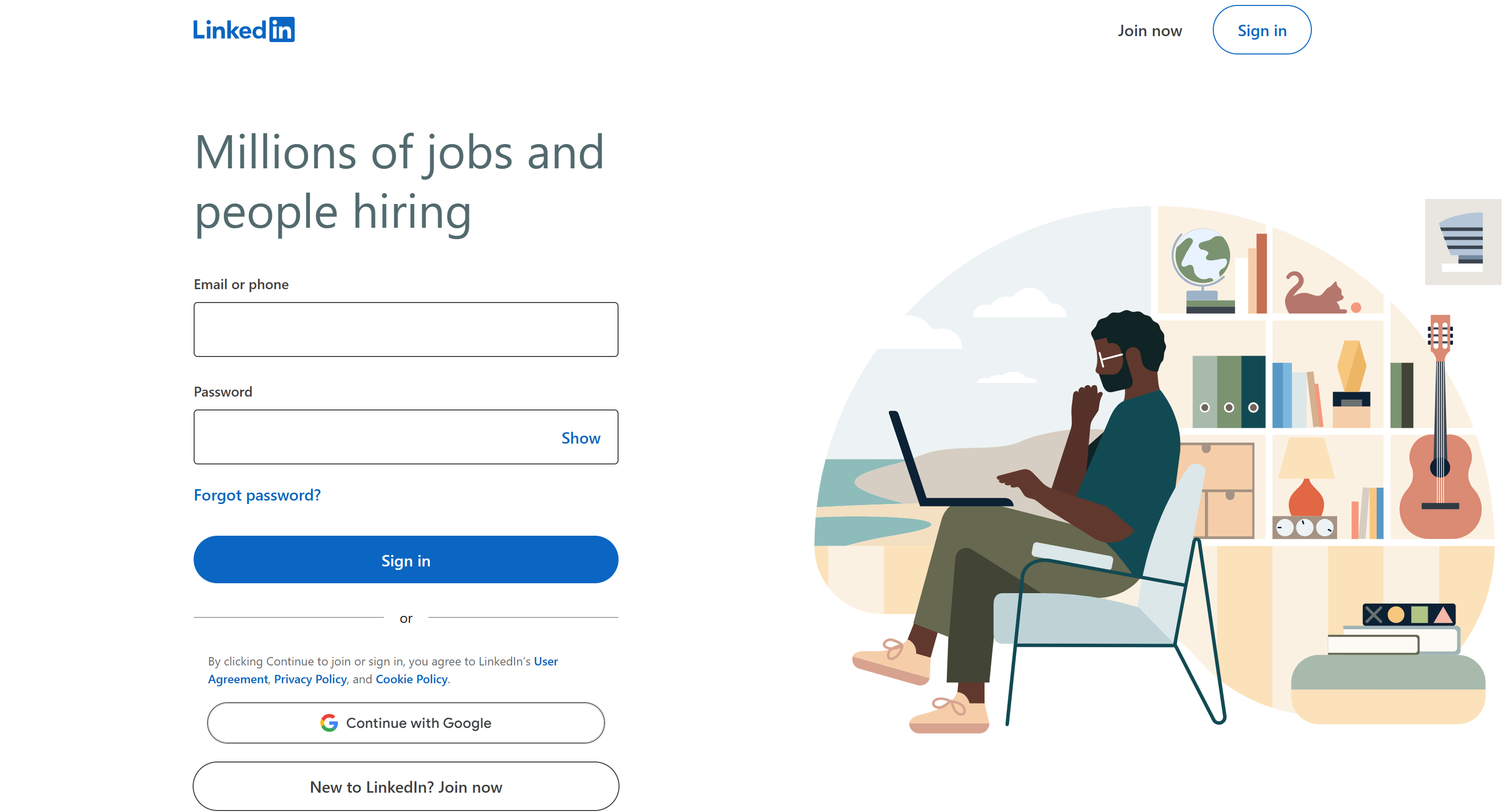
上記ページは、LinkedInでの求人検索がログイン後にしかできないと誤解させる可能性があります。ログイン壁の背後にあるデータをスクレイピングすると、LinkedInの利用規約違反となり法的問題を招く恐れがあるため、避けるべきです。
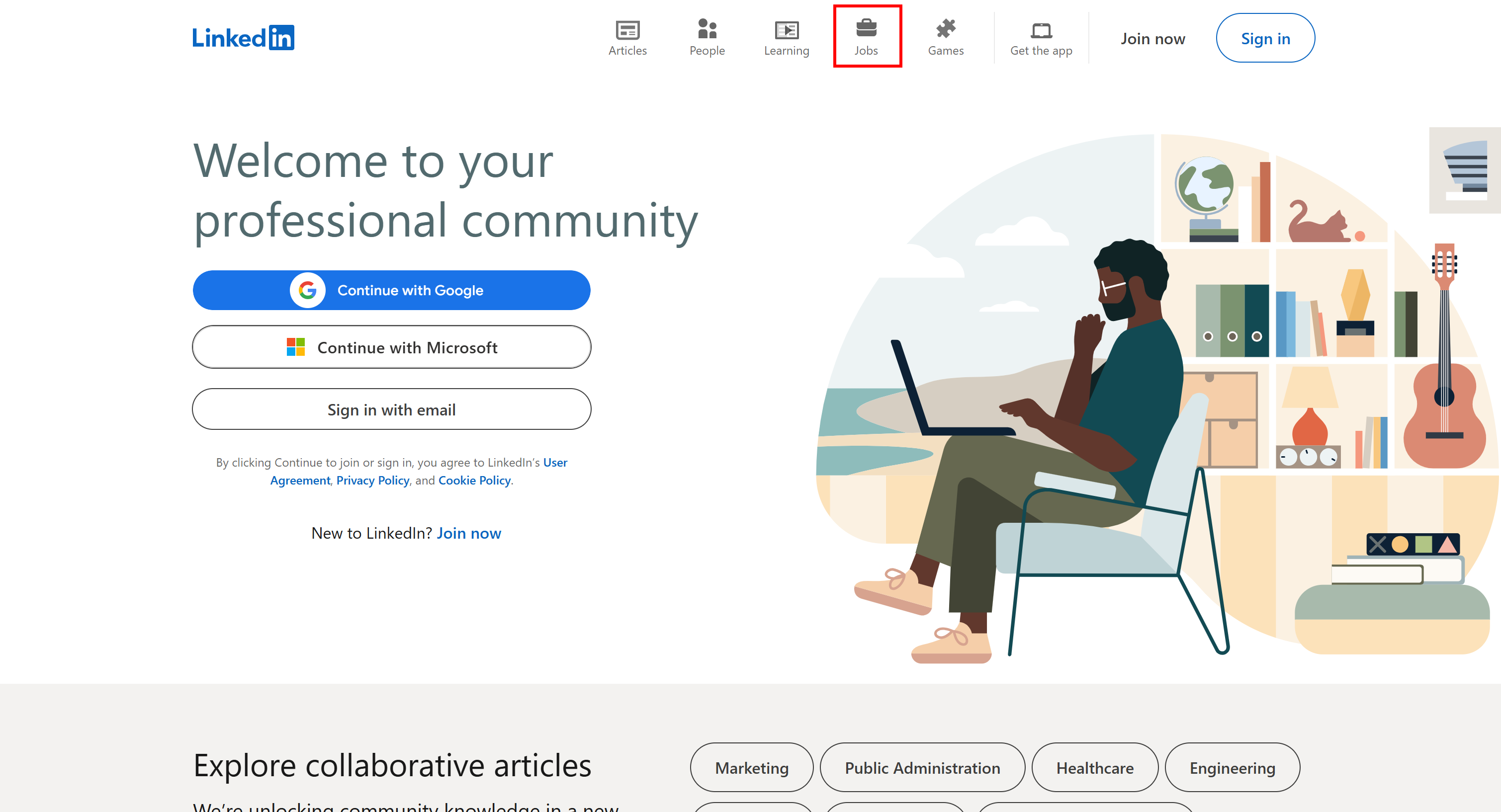
幸い、ブロックされずに求人ページにアクセスする簡単な回避策があります。LinkedInのホームページにアクセスし、「Jobs」タブをクリックするだけです:
すると、求人検索ページにアクセスできます:
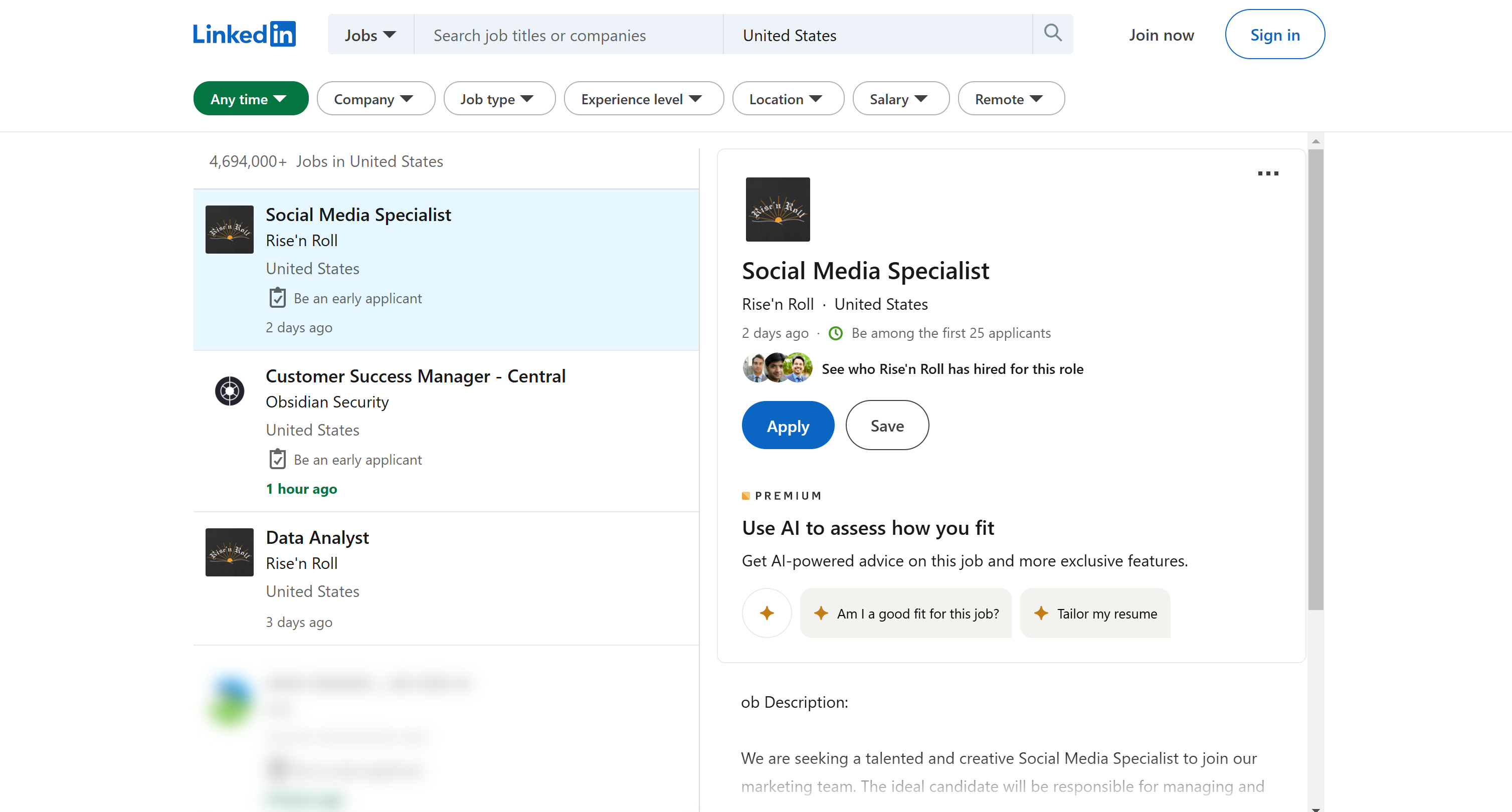
ブラウザのURLバーで確認できるように、今回はブラウザのURLに特別なクエリパラメータが含まれています:
https://www.linkedin.com/jobs/search?trk=guest_homepage-basic_guest_nav_menu_jobs&position=1&pageNum=0
特に、trk=guest_homepage-basic_guest_nav_menu_jobs という引数が、LinkedInがログイン壁を強制するのを防ぐ鍵となっているようです。
ただし、これはLinkedInの全データにアクセスできることを意味しません。一部のセクションでは依然としてログインが必要です。しかし、これから見ていくように、これはLinkedInのウェブスクレイピングにおいて大きな制約にはなりません。
LinkedInウェブスクレイピングスクリプトの作成:ステップバイステップガイド
このチュートリアルセクションでは、LinkedInからニューヨークのソフトウェアエンジニア職の求人情報をスクレイピングする方法を学びます:
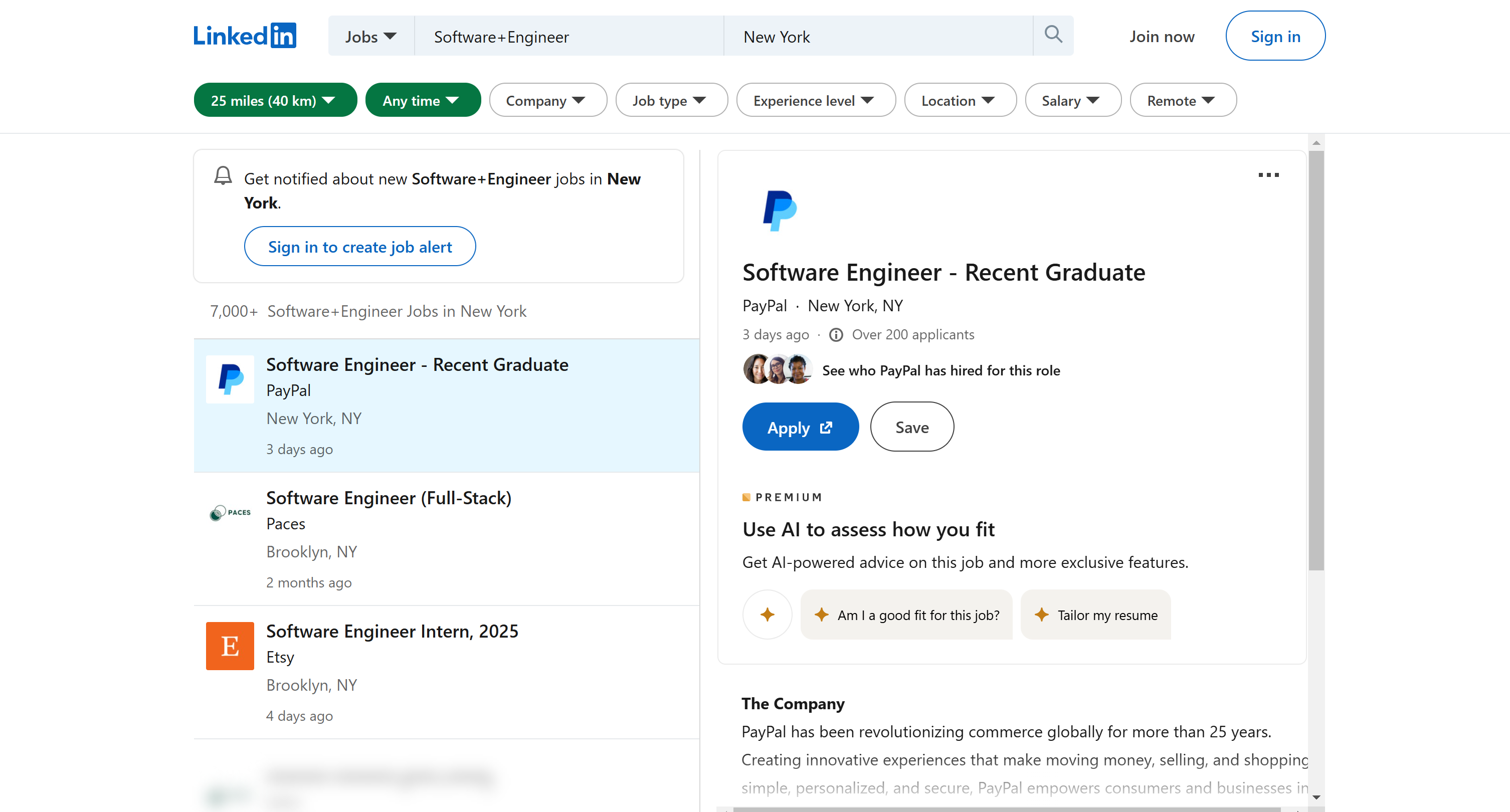
検索結果ページから開始し、求人リストのURLを自動取得した後、詳細ページからデータを抽出します。LinkedInスクレイパーは、ウェブスクレイピングに最適なプログラミング言語の一つであるPythonで記述します。
PythonでLinkedInデータスクレイピングを実行しましょう!
ステップ #1: プロジェクト設定
開始前に、お使いのマシンにPython 3がインストールされていることを確認してください。インストールされていない場合は、ダウンロードしてインストールウィザードに従ってください。
次に、以下のコマンドでスクレイピングプロジェクト用のフォルダを作成します:
mkdir linkedin-スクレイパー
linkedin-scraper は Python による LinkedIn スクレイパーのプロジェクトフォルダを表します。
そのフォルダに移動し、仮想環境を初期化します:
cd linkedin-スクレイパー
python -m venv venv
お好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio CodeやPyCharm Community Editionが適しています。
プロジェクトフォルダ内にscraper.py ファイルを作成します。ファイル構造は以下の通りです:
現時点ではscraper.py は空の Python スクリプトですが、すぐに必要なスクレイピングロジックが含まれるようになります。
IDEのターミナルで仮想環境をアクティブ化します。LinuxまたはmacOSでは、次のコマンドを実行してください:
./env/bin/activate
Windowsでは同等の操作として以下を実行します:
env/Scripts/activate
素晴らしい!これでウェブスクレイピング用のPython環境が整いました。
ステップ #2: スクラッピングライブラリの選択とインストール
コーディングに取り掛かる前に、対象サイトを分析し、作業に適したスクレイピングツールを決定する必要があります。
まず、前述の手順に従い、LinkedIn Jobsの検索ページをシークレットモードで開きます。シークレットモードを使用することで、ログアウト状態が保たれ、キャッシュされたデータがスクレイピングプロセスに干渉するのを防ぎます。
表示される画面は以下の通りです:
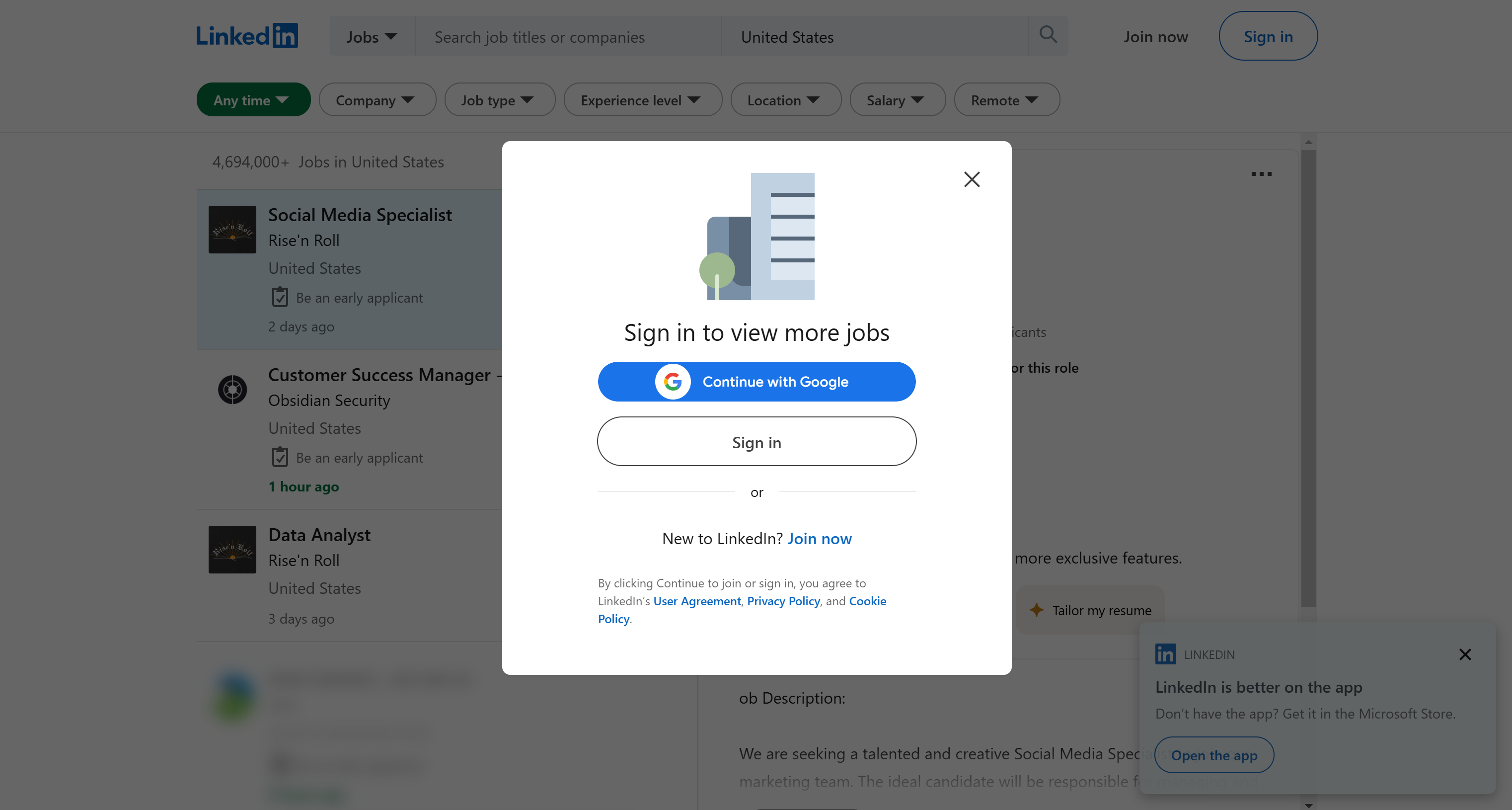
LinkedInはブラウザに複数のポップアップを表示します。SeleniumやPlaywrightのようなブラウザ自動化ツールを使用する際、これらは扱いにくい場合があります。
幸いなことに、サーバーから返されるページのHTMLソースコードを検査すると、ページ上のデータの大半が既に含まれていることがわかります:
同様に、DevToolsの「ネットワーク」タブを確認すると、ページが重要な動的API呼び出しに依存していないことがわかります:
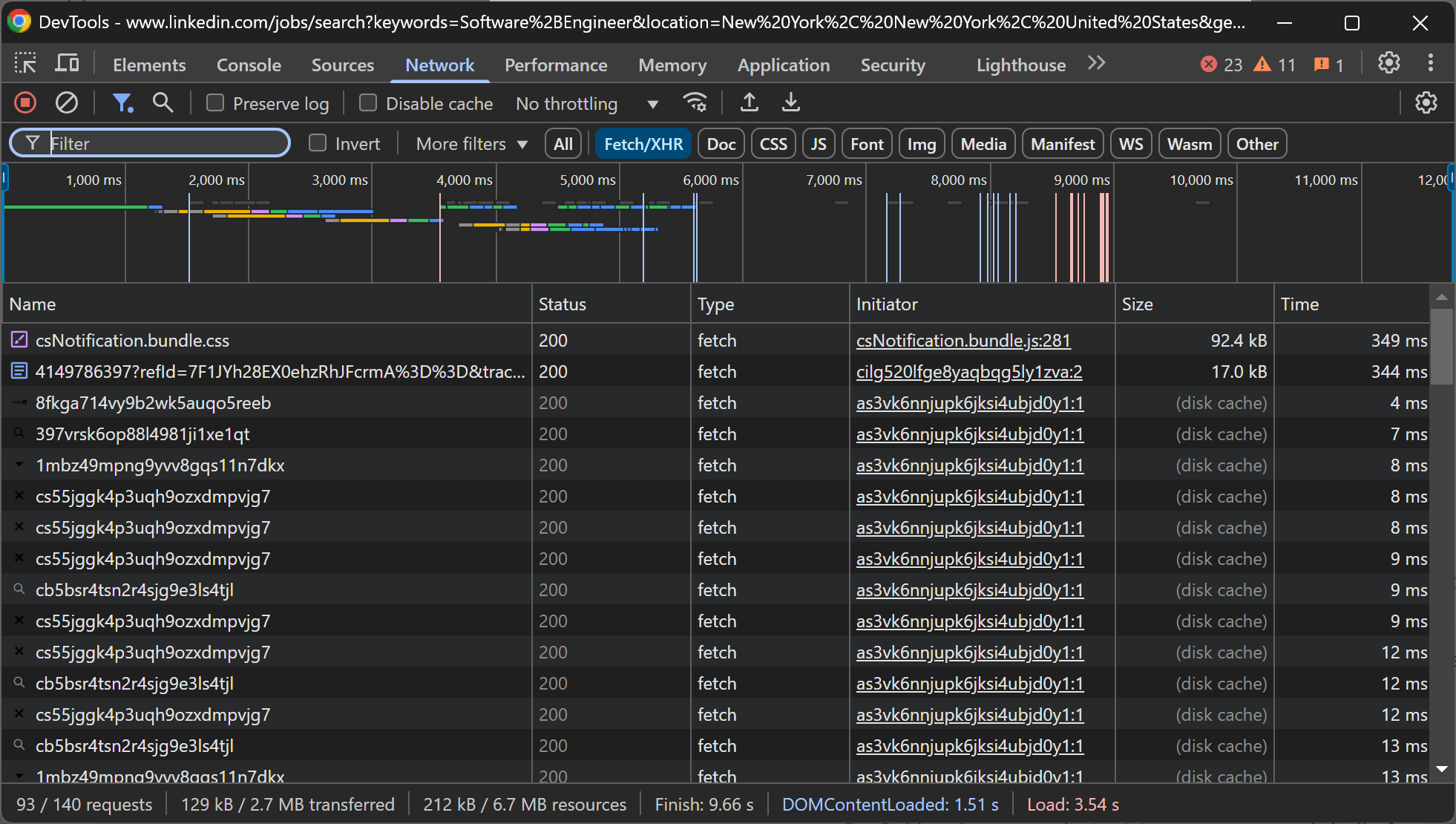
つまり、LinkedInの求人ページの大部分は静的コンテンツです。これは、LinkedInのスクレイピングにブラウザ自動化ツールが不要であることを意味します。HTTPクライアントとHTMLパーサーを組み合わせれば、求人データを取得するのに十分です。
したがって、LinkedInの求人情報をスクレイピングするために2つのPythonライブラリを使用します:
- Requests: GETリクエストの送信やウェブページコンテンツの取得を行うシンプルなHTTPライブラリ。
- Beautiful Soup: ウェブページからデータを簡単に抽出できる強力なHTMLパーサー。
アクティブな仮想環境で、以下のコマンドで両ライブラリをインストールします:
pip install requests beautifulsoup4
次に、スクレイパー.py でインポートします:
from bs4 import BeautifulSoup
import requests
これでLinkedInのスクレイピングを開始する準備が整いました。
ステップ #3: スクラッピングスクリプトの構造化
このセクションの冒頭で説明した通り、LinkedInスクレイパーは主に2つのタスクを実行します:
- LinkedIn求人検索ページから求人ページのURLを取得する
- 各求人ページから詳細情報を抽出する
スクリプトを整理するために、スクレイパー.pyファイルを2つの関数で構成します:
def retrieve_job_urls(job_search_url):
pass
# 実装予定...
def scrape_job(job_url):
pass
# 実装予定...
# 関数呼び出しとデータエクスポートロジック...
以下は2つの関数の役割です:
retrieve_job_urls(job_search_url): 求人検索ページのURLを受け取り、求人ページURLのリストを返します。scrape_job(job_url): 求人ページURLを受け取り、タイトル、企業名、勤務地、説明などの求人詳細を抽出します。
スクリプトの最後でこれらの関数を呼び出し、スクレイピングした求人データを保存するためのデータエクスポートロジックを実装します。さあ、そのロジックを実装しましょう!
ステップ #4: 求人検索ページへの接続
`retrieve_job_urls()`関数内で、引数として渡されたURLを使用して対象ページを取得するため、requestsライブラリを使用します:
response = requests.get(job_url)
内部では、ターゲットページへのHTTP GETリクエストを実行し、サーバーから返されたHTMLドキュメントを取得します。
レスポンスからHTMLコンテンツにアクセスするには、.text属性を使用します:
html = response.text
素晴らしい!これでHTMLをパースし、求人URLの抽出を開始する準備が整いました。
ステップ #5: 求人URLを取得する
先に取得したHTMLをパースするには、Beautiful Soupコンストラクタに渡します:
soup = BeautifulSoup(html, "html.parser")
2番目の引数で使用するHTMLパーサーを指定します。html.parserはPython標準ライブラリに含まれるデフォルトのパーサーです。
次に、LinkedInの求人検索ページ上の求人カード要素を調査します。いずれかのカード上で右クリックし、ブラウザのデベロッパーツールで「要素を検査」を選択します:
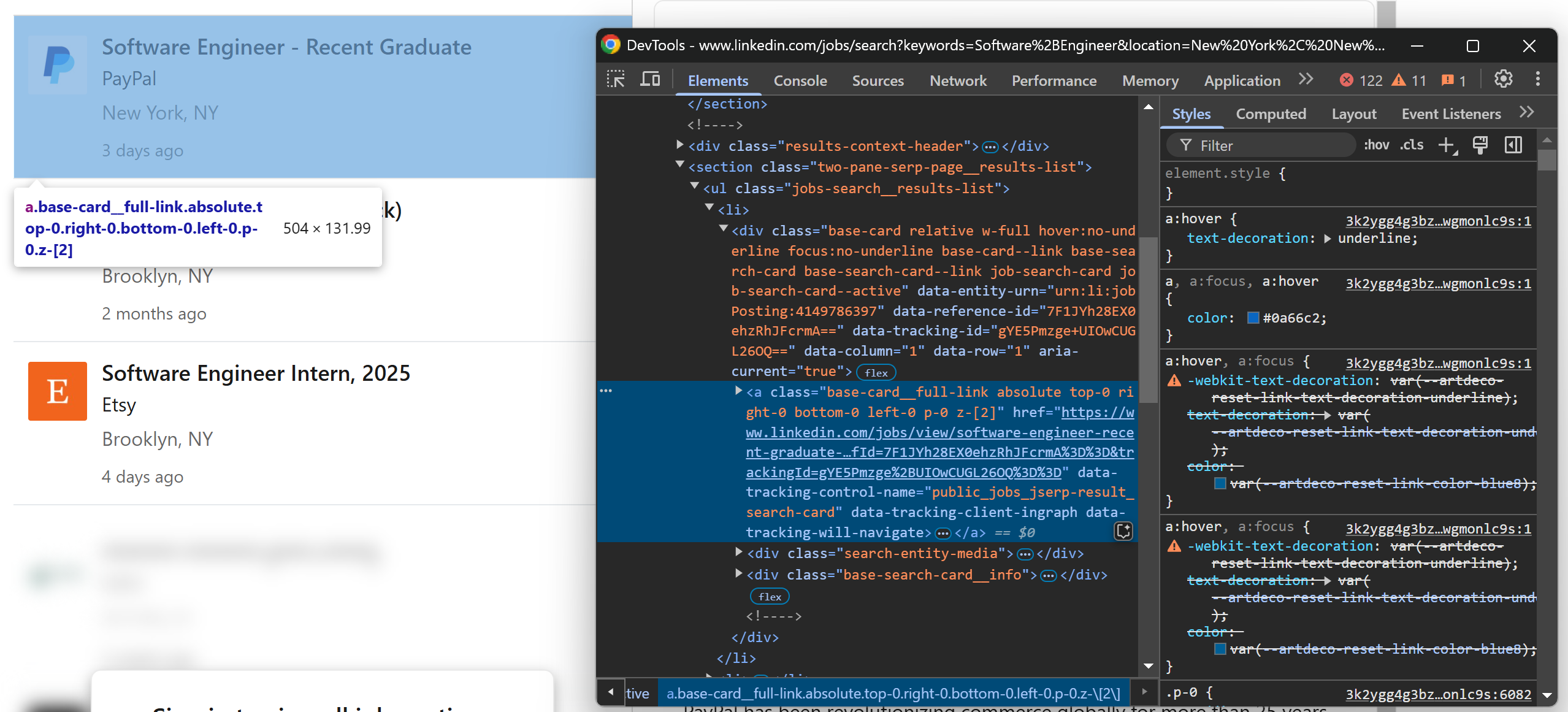
求人カードのHTMLコードからわかるように、求人URLは以下のCSSセレクタを使用して抽出できます:
[data-tracking-control-name="public_jobs_jserp-result_search-card"]
注:ウェブスクレイピングでノード選択にdata-*属性を使用するのは理想的です。これらはテストや内部トラッキングに頻繁に使用されるため、時間の経過とともに変更される可能性が低くなります。
さて、ページを確認すると、ログイン招待要素の背後にぼやけて表示される求人カードがあることに気づくでしょう:
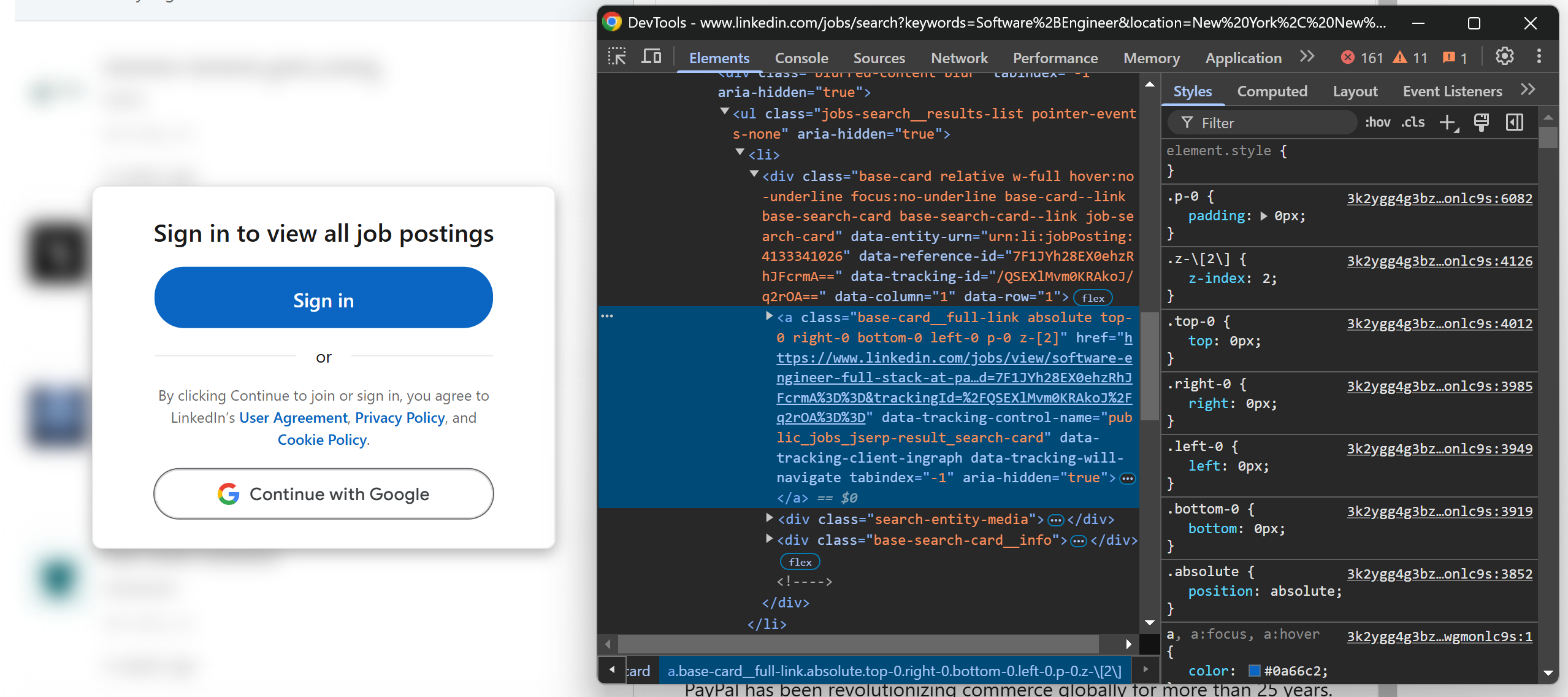
心配無用です。これは単なるフロントエンド効果です。基盤となるHTMLには求人ページのURLが依然として含まれているため、ログインせずにこれらのURLを取得できます。
LinkedIn Jobsページから求人投稿URLを抽出するロジックは以下の通りです:
job_urls = []
job_url_elements = soup.select("[data-tracking-control-name="public_jobs_jserp-result_search-card"]")
for job_url_element in job_url_elements:
job_url = job_url_element["href"]
job_urls.append(job_url)
select() は指定された CSS セレクタに一致する全要素(求人リンクを含む)を返します。その後、スクリプトは:
- これらの要素を反復処理します
hrefHTML属性(求人ページURL)にアクセス- それを
job_urlsリストに追加します
上記のロジックに不慣れな場合は、Beautiful Soup ウェブスクレイピングガイドを参照してください。
このステップ終了時、`retrieve_job_urls()`関数は以下のようになります:
def retrieve_job_urls(job_search_url):
# ページのHTMLを取得するHTTP GETリクエストを実行
response = requests.get(job_search_url)
# HTMLにアクセスしてパース
html = response.text
soup = BeautifulSoup(html, "html.parser")
# スクレイピングしたデータの保存先
job_urls = []
# スクレイピングロジック
job_url_elements = soup.select("[data-tracking-control-name="public_jobs_jserp-result_search-card"]")
for job_url_element in job_url_elements:
# 求人ページURLを抽出しリストに追加
job_url = job_url_element["href"]
job_urls.append(job_url)
return job_urls
対象ページでこの関数を以下のように呼び出せます:
public_job_search_url = "https://www.linkedin.com/jobs/search?keywords=Software%2BEngineer&location=New%20York%2C%20New%20York%2C%20United%20States&geoId=102571732&trk=public_jobs_jobs-search-bar_search-submit&position=1&pageNum=0"
job_urls = retrieve_job_urls(public_job_search_url)
よくできました!これでLinkedInスクレイパーの最初のタスクが完了しました。
ステップ #6: 求人データスクレイピングタスクの初期化
次に、scrape_job()関数に注目します。以前と同様に、requestsライブラリを使用して指定されたURLから求人ページのHTMLを取得し、Beautiful Soupでパースします:
response = requests.get(job_url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
LinkedInの求人データをスクレイピングするには様々な情報を抽出する必要があるため、プロセスを簡素化するために2つのステップに分けます。
ステップ #7: 求人データ取得 — パート1
LinkedInデータスクレイピングに着手する前に、求人詳細ページを調査し、どのようなデータが含まれていて、どのように取得するかを理解する必要があります。
そのためには、シークレットモードで求人ページを開き、開発者ツール(DevTools)を使用してページを検査します。求人掲載ページの上部セクションに注目してください:
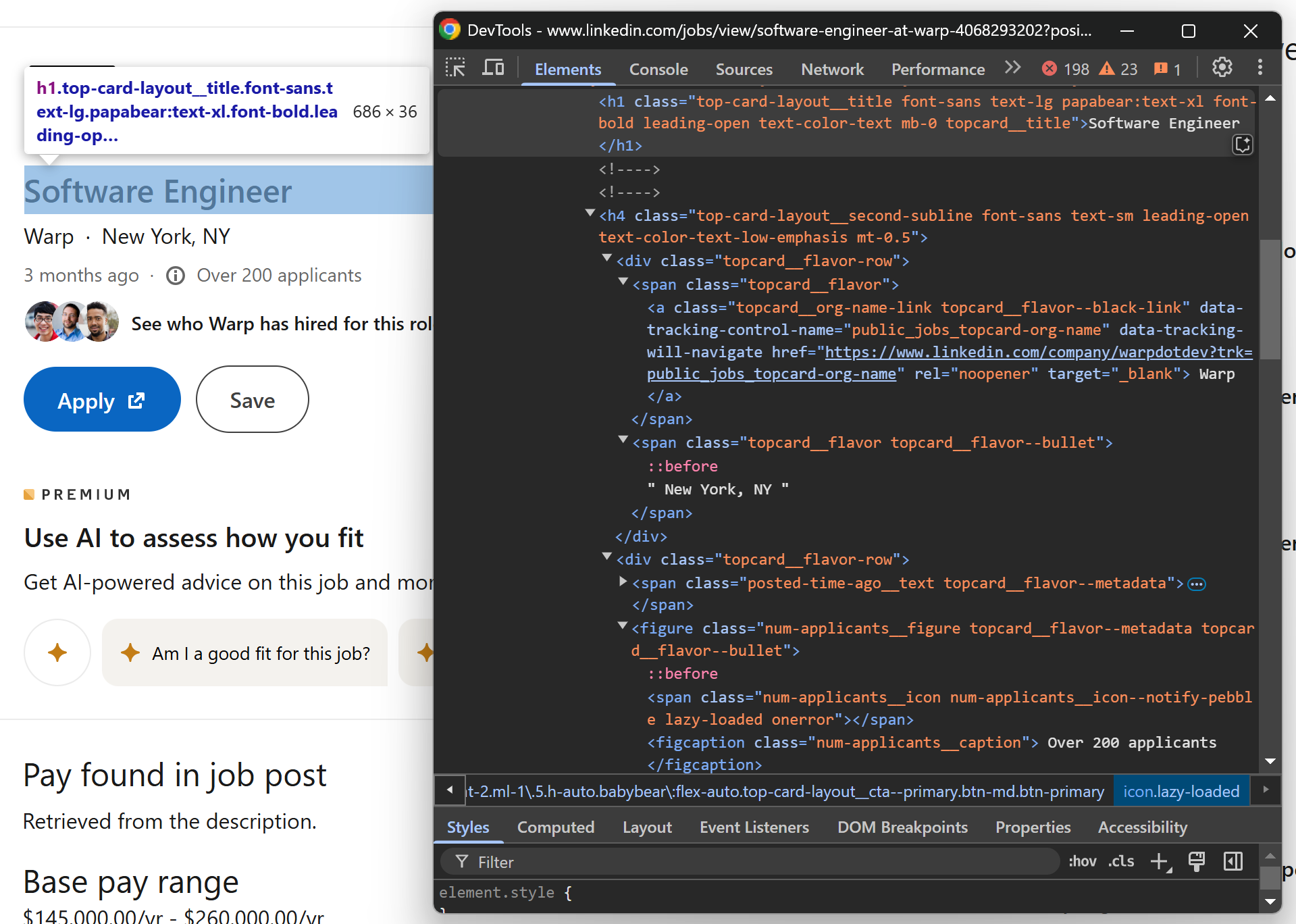
以下のデータを抽出できることに注意してください:
- –
<h1>タグ内の求人タイトル [data-tracking-control-name="public_jobs_topcard-org-name"]要素から取得する求人掲載企業名.topcard__flavor--bulletからの所在地情報.num-applicants__captionノードから応募者数
scrape_job()関数内でHTMLをパースした後、以下のロジックでこれらのフィールドを抽出します:
title_element = soup.select_one("h1")
title = title_element.get_text().strip()
company_element = soup.select_one("[data-tracking-control-name="public_jobs_topcard-org-name"]")
company_name = company_element.get_text().strip()
company_url = company_element["href"]
location_element = soup.select_one(".topcard__flavor--bullet")
location = location_element.get_text().strip()
applicants_element = soup.select_one(".num-applicants__caption")
applicants = applicants_element.get_text().strip()
strip()関数は、スクレイピングしたテキストから先頭または末尾の空白を削除するために必要です。
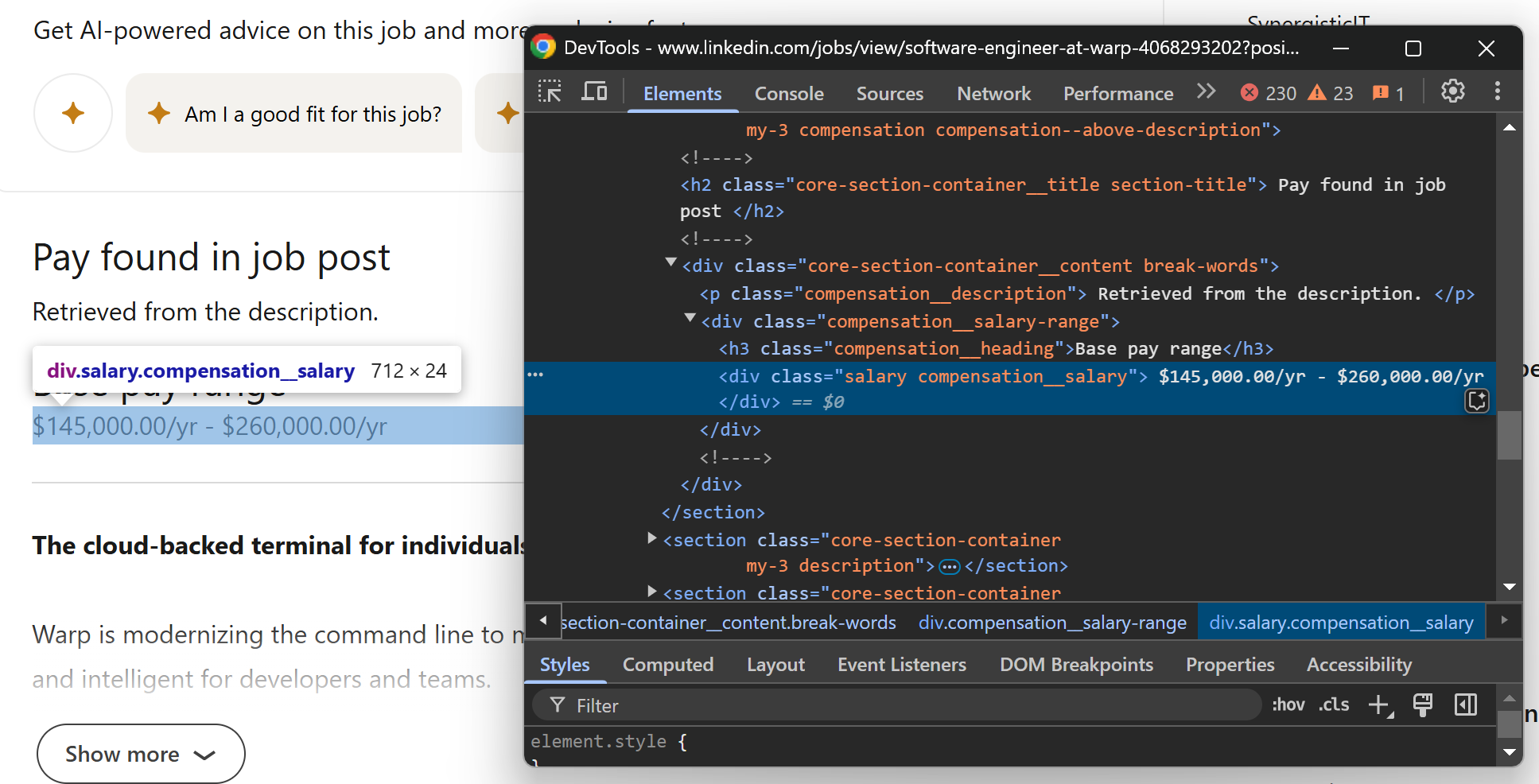
次に、ページの給与セクションに注目します。
この情報は.salary CSS セレクタで取得できます。すべての職種にこのセクションがあるわけではないため、HTML要素がページに存在するかどうかを確認する追加ロジックが必要です:
salary_element = soup.select_one(".salary")
if salary_element is not None:
salary = salary_element.get_text().strip()
else:
salary = None
.salaryがページ上に存在しない場合、select_one() はNoneを返し、salary変数はNoneに設定されます。
素晴らしい!これでLinkedInの求人ページからデータの一部を抽出できました。
ステップ #8: 求人データの取得 — パート2
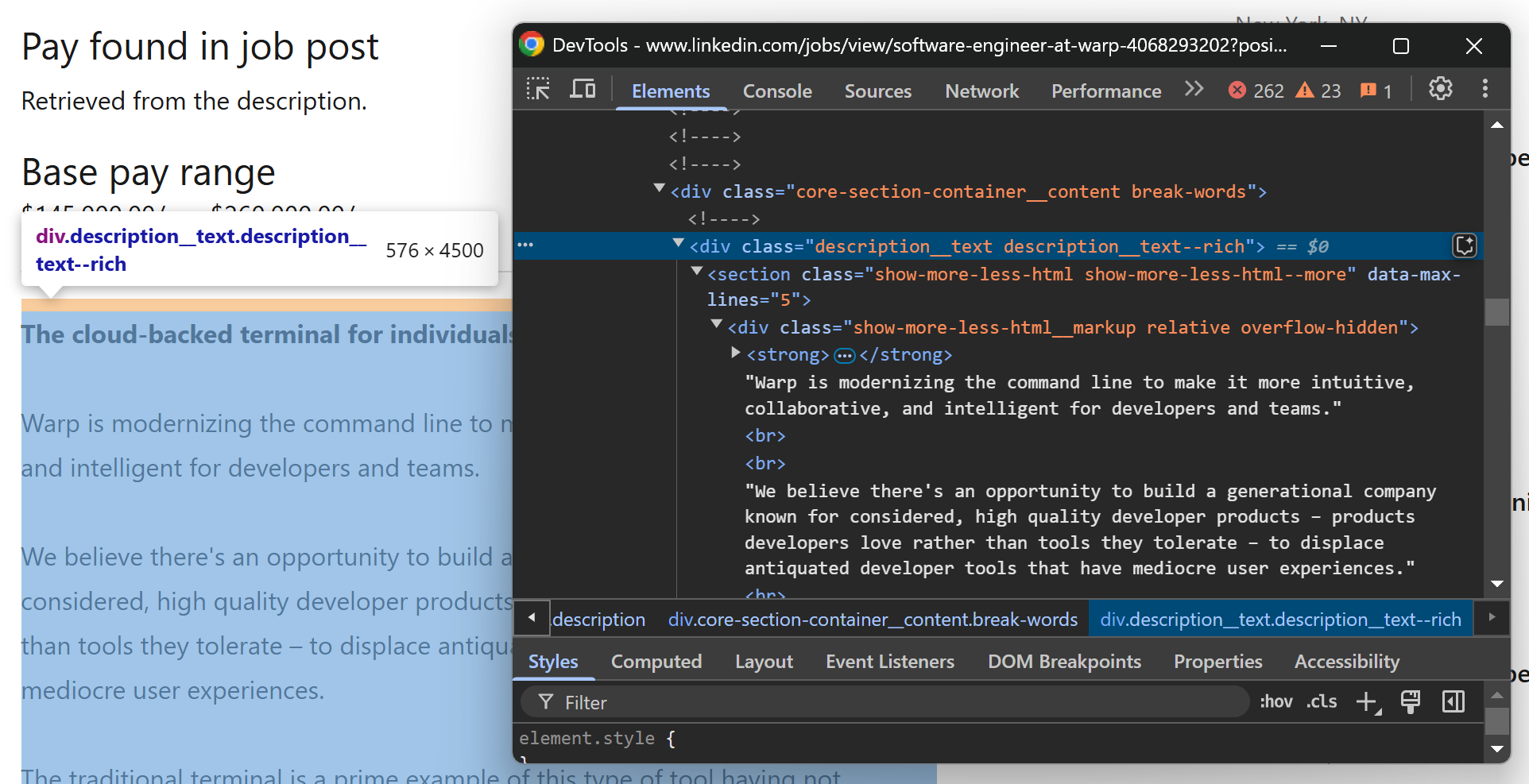
次に、LinkedInの求人ページ下部、職務内容から始めましょう:
以下のコードで、.description__text .show-more-less-html 要素から職務内容テキストにアクセスできます:
description_element = soup.select_one(".description__text .show-more-less-html")
description = description_element.get_text().strip()
最後に、LinkedInウェブスクレイピングで最も難しいのは条件セクションの処理です:
この場合、ページ上にどのようなデータが存在するかを正確に予測することはできません。したがって、各項目を<名前, 値>のペアとして扱う必要があります。条件データをスクレイピングするには:
.description__job-criteria-list liCSSセレクタで<ul>要素を選択- 選択した要素を反復処理し、各要素に対して以下を実行:
.description__job-criteria-subheaderから項目名を取得.description__job-criteria-textから項目値をスクレイピング- スクレイピングしたデータを辞書として配列に追加する
以下のコード行で、条件セクションのLinkedInスクレイピングロジックを実装する:
criteria = []
criteria_elements = soup.select(".description__job-criteria-list li")
for criteria_element in criteria_elements:
name_element = criteria_element.select_one(".description__job-criteria-subheader")
name = name_element.get_text().strip()
value_element = criteria_element.select_one(".description__job-criteria-text")
value = value_element.get_text().strip()
criteria.append({
"name": name,
"value": value
})
完璧です!求人データのスクレイピングに成功しました。次のステップは、スクレイピングしたLinkedInデータをすべてオブジェクトに収集し、それを返すことです。
ステップ #9: スクレイピングしたデータの収集
前の2ステップでスクレイピングしたデータを使用して、求人オブジェクトを作成し、関数から返します:
job = {
"url": job_url,
"title": title,
"company": {
"name": company_name,
"url": company_url
},
"location": location,
"applications": applicants,
"salary": salary,
"description": description,
"criteria": criteria
}
return job
前述の3つのステップを完了すると、scrape_job() は以下のようになります:
def scrape_job(job_url):
# HTTP GETリクエストを送信しページHTMLを取得
response = requests.get(job_url)
# レスポンスからHTMLテキストを取得しパース
html = response.text
soup = BeautifulSoup(html, "html.parser")
# スクラッピングロジック
title_element = soup.select_one("h1")
title = title_element.get_text().strip()
company_element = soup.select_one("[data-tracking-control-name="public_jobs_topcard-org-name"]")
company_name = company_element.get_text().strip()
company_url = company_element["href"]
location_element = soup.select_one(".topcard__flavor--bullet")
location = location_element.get_text().strip()
applicants_element = soup.select_one(".num-applicants__caption")
applicants = applicants_element.get_text().strip()
salary_element = soup.select_one(".salary")
if salary_element is not None:
salary = salary_element.get_text().strip()
else:
salary = None
description_element = soup.select_one(".description__text .show-more-less-html")
description = description_element.get_text().strip()
criteria = []
criteria_elements = soup.select(".description__job-criteria-list li")
for criteria_element in criteria_elements:
name_element = criteria_element.select_one(".description__job-criteria-subheader")
name = name_element.get_text().strip()
value_element = criteria_element.select_one(".description__job-criteria-text")
value = value_element.get_text().strip()
criteria.append({
"name": name,
"value": value
})
# スクレイピングしたデータを収集して返す
job = {
"url": job_url,
"title": title,
"company": {
"name": company_name,
"url": company_url
},
"location": location,
"applications": applicants,
"salary": salary,
"description": description,
"criteria": criteria
}
return job
求人データを収集するには、retrieve_job_urls()が返す求人URLを反復処理してこの関数を呼び出します。その後、スクレイピングしたデータをjobs配列に追加します:
jobs = []
for job_url in job_urls:
job = scrape_job(job_url)
jobs.append(job)
素晴らしい!LinkedInデータスクレイピングのロジックが完成しました。
ステップ #10: JSON へのエクスポート
LinkedInから抽出した求人データは、オブジェクトの配列として保存されています。これらのオブジェクトはフラットではないため、JSONのような構造化された形式でエクスポートするのが合理的です。
Pythonでは追加の依存関係なしでデータをJSONにエクスポートできます。以下のロジックを使用します:
file_name = "jobs.json"
with open(file_name, "w", encoding="utf-8") as file:
json.dump(jobs, file, indent=4, ensure_ascii=False)
open() 関数はjobs.json出力ファイルを作成し、json.dump()でデータを書き込む。indent=4は可読性を高めるためのインデントを、ensure_ascii=Falseは非ASCII文字の正しいエンコードを保証する。
コードを動作させるには、Python標準ライブラリからjsonをインポートすることを忘れないでください:
import json
ステップ #11: スクラッピングロジックの最終調整
これでLinkedInスクレイピングスクリプトは基本的に完成しました。ただし、以下の改善が可能です:
- スクレイピング対象のジョブ数を制限する
- スクリプトの進捗を監視するためのログ記録を追加
最初の点が重要な理由は:
- LinkedInスクレイパーからの過剰なリクエストで対象サーバーに負荷をかけないようにするため
- 1ページに表示される求人数が不明であるため
したがって、以下のようにスクレイピングするジョブ数を制限するのが合理的です:
scraping_limit = 10
jobs_to_scrape = job_urls[:scraping_limit]
jobs = []
for job_url in jobs_to_scrape:
# ...
これにより、スクレイピングされるページは最大10ページに制限されます。
次に、スクリプトの実行中に動作を確認するためのprint()文を追加します:
public_job_search_url = "https://www.linkedin.com/jobs/search?keywords=Software%2BEngineer&location=New%20York%2C%20New%20York%2C%20United%20States&geoId=102571732&trk=public_jobs_jobs-search-bar_search-submit&position=1&pageNum=0"
print("LinkedIn検索URLからの求人取得を開始します...")
job_urls = retrieve_job_urls(public_job_search_url)
print(f"取得した求人URL: {len(job_urls)}件")
scraping_limit = 10
jobs_to_scrape = job_urls[:scraping_limit]
print(f"スクレイピング対象の求人: {len(jobs_to_scrape)}件...n")
jobs = []
for job_url in jobs_to_scrape:
print(f"「{job_url}」のデータを抽出開始します")
job = scrape_job(job_url)
jobs.append(job)
print(f"ジョブをスクレイピングしました")
print(f"nスクレイピングした{len(jobs)}件のジョブをJSONにエクスポートします")
file_name = "jobs.json"
with open(file_name, "w", encoding="utf-8") as file:
json.dump(jobs, file, indent=4, ensure_ascii=False)
print(f"ジョブを "{file_name}" に正常に保存しましたn")
ロギングロジックはスクレイパーの進捗を追跡するのに役立ちます。複数のステップを経ることを考慮すると、これは不可欠です。
ステップ #12: 全てを統合する
LinkedInスクレイピングスクリプトの最終コードは以下の通りです:
from bs4 import BeautifulSoup
import requests
import json
def retrieve_job_urls(job_search_url):
# ページのHTMLを取得するHTTP GETリクエストを実行
response = requests.get(job_search_url)
# HTMLにアクセスしてパース
html = response.text
soup = BeautifulSoup(html, "html.parser")
# スクレイピングしたデータの保存先
job_urls = []
# スクレイピング処理
job_url_elements = soup.select("[data-tracking-control-name="public_jobs_jserp-result_search-card"]")
for job_url_element in job_url_elements:
# 求人ページのURLを抽出しリストに追加
job_url = job_url_element["href"]
job_urls.append(job_url)
return job_urls
def scrape_job(job_url):
# ページHTMLを取得するHTTP GETリクエストを送信
response = requests.get(job_url)
# レスポンスからHTMLテキストを取得しパース
html = response.text
soup = BeautifulSoup(html, "html.parser")
# スクレイピング処理
title_element = soup.select_one("h1")
title = title_element.get_text().strip()
company_element = soup.select_one("[data-tracking-control-name="public_jobs_topcard-org-name"]")
company_name = company_element.get_text().strip()
company_url = company_element["href"]
location_element = soup.select_one(".topcard__flavor--bullet")
location = location_element.get_text().strip()
applicants_element = soup.select_one(".num-applicants__caption")
applicants = applicants_element.get_text().strip()
salary_element = soup.select_one(".salary")
if salary_element is not None:
salary = salary_element.get_text().strip()
else:
salary = None
description_element = soup.select_one(".description__text .show-more-less-html")
description = description_element.get_text().strip()
criteria = []
criteria_elements = soup.select(".description__job-criteria-list li")
for criteria_element in criteria_elements:
name_element = criteria_element.select_one(".description__job-criteria-subheader")
name = name_element.get_text().strip()
value_element = criteria_element.select_one(".description__job-criteria-text")
value = value_element.get_text().strip()
criteria.append({
"name": name,
"value": value
})
# スクレイピングしたデータを収集して返す
job = {
"url": job_url,
"title": title,
"company": {
"name": company_name,
"url": company_url
},
"location": location,
"applications": applicants,
"salary": salary,
"description": description,
"criteria": criteria
}
return job
# LinkedIn求人検索ページの公開URL
public_job_search_url = "https://www.linkedin.com/jobs/search?keywords=Software%2BEngineer&location=New%20York%2C%20New%20York%2C%20United%20States&geoId=102571732&trk=public_jobs_jobs-search-bar_search-submit&position=1&pageNum=0"
print("LinkedIn検索URLからの求人取得を開始します...")
# ページ上の各求人に対する個別のURLを取得
job_urls = retrieve_job_urls(public_job_search_url)
print(f"取得した求人URL数: {len(job_urls)}")
# ページから最大10件までスクレイピング
scraping_limit = 10
jobs_to_scrape = job_urls[:scraping_limit]
print(f"スクレイピング対象求人数: {len(jobs_to_scrape)}件...n")
# 各求人ページのデータをスクレイピング
jobs = []
for job_url in jobs_to_scrape:
print(f"「{job_url}」のデータを抽出開始します")
job = scrape_job(job_url)
jobs.append(job)
print(f"求人スクレイピング完了")
# スクレイピングしたデータをCSVにエクスポート
print(f"n{len(jobs)}件のスクレイピング済み求人をJSONにエクスポート中")
file_name = "jobs.json"
with open(file_name, "w", encoding="utf-8") as file:
json.dump(jobs, file, indent=4, ensure_ascii=False)
print(f"ジョブを "{file_name}" に正常に保存しましたn")
以下のコマンドで実行:
python スクレイパー.py
LinkedInスクレイパーは以下の情報をログに記録します:
LinkedIn検索URLからの求人取得を開始...
60件の求人URLを取得
10件の求人をスクレイピング中...
"https://www.linkedin.com/jobs/view/software-engineer-recent-graduate-at-paypal-4149786397?position=1&pageNum=0&refId=nz9sNo7HULREru1eS2L9nA%3D%3D&trackingId=uswFC6EjKkfCPcv0ykaojw%3D%3D"
求人データをスクレイピングしました
# 簡略化のため省略...
"https://www.linkedin.com/jobs/view/software-engineer-full-stack-at-paces-4090771382?position=2&pageNum=0&refId=UKcPcvFZMOsZrn0WhZYqtg%3D%3D&trackingId=p6UUa6cgbpYS1gDkRlHV2g%3D%3D"
求人情報を取得しました
取得した10件の求人情報をJSON形式でエクスポート中
求人情報を「jobs.json」に正常に保存しました
スクリプトは最大60ページ分の求人ページを検出しましたが、実際にスクレイピングされたのは10件のみです。したがって、スクリプトが生成するjobs.json出力ファイルには、正確に10件の求人ポジションが含まれます:
[
{
"url": "https://www.linkedin.com/jobs/view/software-engineer-recent-graduate-at-paypal-4149786397?position=1&pageNum=0&refId=UKcPcvFZMOsZrn0WhZYqtg%3D%3D&trackingId=UzOyWl8Jipb1TFAGlLJxqw%3D%3D",
"title": "ソフトウェアエンジニア - 新卒",
"company": {
"name": "PayPal",
"url": "https://www.linkedin.com/company/paypal?trk=public_jobs_topcard-org-name"
},
"location": "ニューヨーク州ニューヨーク",
"applications": "応募者数 200名以上",
"salary": null,
"description": "簡略化のため省略...",
"criteria": [
{
"name": "経験年数",
"value": "該当なし"
},
{
"name": "雇用形態",
"value": "正社員"
},
{
"name": "職務内容",
"value": "エンジニアリング"
},
{
"name": "業界",
"value": "ソフトウェア開発、金融サービス、テクノロジー・情報・インターネット"
}
]
},
// その他の8職種...
{
"url": "https://www.linkedin.com/jobs/view/software-engineer-full-stack-at-paces-4090771382?position=2&pageNum=0&refId=UKcPcvFZMOsZrn0WhZYqtg%3D%3D&trackingId=p6UUa6cgbpYS1gDkRlHV2g%3D%3D",
"title": "ソフトウェアエンジニア(フルスタック)",
"company": {
"name": "Paces",
"url": "https://www.linkedin.com/company/pacesai?trk=public_jobs_topcard-org-name"
},
"location": "ブルックリン, NY",
"applications": "応募者数 200名以上",
"salary": "$150,000.00/年 - $200,000.00/年",
"description": "簡略化のため省略...",
"criteria": [
{
"name": "経験年数",
"value": "未経験~初級"
},
{
"name": "雇用形態",
"value": "正社員"
},
{
"name": "職務内容",
"value": "エンジニアリングおよび情報技術"
},
{
"name": "業界",
"value": "ソフトウェア開発"
}
]
},
]
さあ、これで完了です!PythonでLinkedInのウェブスクレイピングはそれほど難しくありません。
LinkedInデータスクレイピングの効率化
構築したスクリプトはLinkedInスクレイピングを単純な作業のように見せますが、実際はそうではありません。ログイン壁やデータ難読化技術は、特にスクレイピング規模を拡大するにつれ、すぐに課題となります。
さらに、LinkedInは自動スクリプトによる過剰なリクエストをブロックするレート制限メカニズムを導入しています。一般的な回避策はPythonでIPアドレスをローテーションさせることですが、追加の労力が必要です。
さらに、LinkedInは絶えず進化しているため、スクレイパーのメンテナンス作業とコストは無視できないことを念頭に置いてください。LinkedInは求人情報から記事まで、様々な形式のデータの宝庫です。このすべての情報を取得するには、異なるスクレイパーを構築し、それらをすべて管理する必要があります。
BrightDataのLinkedInスクレイパーAPIを使えば、こうした煩わしさは不要です。この専用ツールは必要なLinkedInデータをすべてスクレイピングし、ノーコード統合や、任意のHTTPクライアントで呼び出せるシンプルなエンドポイントを通じて提供します。
スクラッピングアーキテクチャ全体を管理する必要なく、LinkedInプロフィール、投稿、企業、求人などを数秒でスクレイピングできます。
まとめ
このステップバイステップチュートリアルでは、LinkedInスクレイパーの定義と取得可能なデータの種類を学びました。さらにPythonスクリプトを作成し、LinkedInの求人情報をスクレイピングしました。
課題は、LinkedInが自動スクリプトをブロックするためにIP禁止やログイン壁を使用していることです。当社のLinkedInスクレイパーでこれらの問題を回避しましょう。
ウェブスクレイピングは不要だがデータには興味がある場合は、すぐに使えるLinkedInデータセットをご覧ください!
今すぐBright Dataの無料アカウントを作成し、スクレイパーAPIをお試しいただくか、データセットをご覧ください。