

このガイドでは、Scrapy Splashについて学びます:
- スクラップ・スプラッシュとは
- PythonでScrapy Splashを使用する方法をステップバイステップのチュートリアルで説明します。
- ScrapyのSplashを使った高度なスクレイピングテクニック
- このツールでウェブサイトをスクレイピングする際の制限事項
さあ、飛び込もう!
Scrapy Splashとは?
Scrapy Splashとは、これら2つのツールの統合を指す:
- Scrapy:ウェブサイトから必要なデータを抽出するためのPythonオープンソースクローリングフレームワークライブラリ。
- Splash: JavaScript を多用するウェブページのレンダリング用に設計された、軽量のヘッドレスブラウザ。
Scrapyのような強力なツールがなぜSplashを必要とするのか不思議に思うかもしれない。ScrapyはHTMLの解析機能(特にParsel)に依存しているため、静的なサイトしか扱えないからだ。しかし、動的なウェブサイトをスクレイピングする場合は、JavaScriptのレンダリングに対処する必要があります。一般的な解決策は、自動化されたブラウザを使うことであり、これこそが Splash が提供するものだ。
Scrapy Splashでは、SplashRequestと呼ばれる特別なリクエストをSplashサーバに送信することができます。このサーバーはJavaScriptを実行することでページを完全にレンダリングし、処理されたHTMLを返します。そのため、Scrapy Spiderは動的なページからデータを取得することができます。
要するに、Scrapy Splashが必要なのは次のような場合だ:
- Scrapyだけではスクレイピングできないような、JavaScriptを多用するウェブサイトを扱っている。
- Seleniumや Playwrightに比べて軽量なソリューションを好む。
- スクレイピングのためにフルブラウザを実行するオーバーヘッドは避けたい。
Scrapy Splashがお客様のニーズに合わない場合は、以下の選択肢をご検討ください:
- Selenium:JavaScriptを多用するウェブサイトをスクレイピングするための本格的なブラウザ自動化機能で、Selenium Wireのような興味深い拡張機能を提供する。
- Playwright:オープンソースのブラウザ自動化ツールで、複数のプログラミング言語をサポートし、一貫したクロスブラウザ自動化と堅牢なAPIを提供します。
- Puppeteer:オープンソースのNode.jsライブラリで、DevToolsプロトコル経由でChromeを自動化・制御するためのハイレベルAPIを提供する。
PythonでScrapy Splash:ステップバイステップのチュートリアル
このセクションでは、ウェブサイトからデータを取得するためにScrapy Splashを使用する方法を理解します。対象となるページは、人気のある “Quotes to Scrape“サイトの特別なJavaScriptレンダリングバージョンです:

これは通常の “Quotes to Scrape “と同じだが、無限スクロールを使い、JavaScriptをトリガーとするAJAXリクエストによって動的にデータをロードする。
必要条件
PythonでScrapy Splashを使用してこのチュートリアルを再現するには、システムが以下の要件に一致する必要があります:
- Python 3.10.1以上。
- Docker 27.5.1以上。
この2つのツールがマシンにインストールされていない場合は、上記のリンクをたどってください。
前提条件、依存関係、および Splash との統合
プロジェクトのメインフォルダをscrapy_splash/と呼ぶとします。このステップの最後に、フォルダは次のような構造になります:
scrapy_splash/
└── venv/venv/には仮想環境が含まれます。venv/ 仮想環境ディレクトリは次のように作成します:
python -m venv venvアクティベートするには、ウィンドウズで以下を実行する:
venvScriptsactivate同様に、macOSとLinuxでは、以下を実行する:
source venv/bin/activateアクティベートされた仮想環境で、以下の方法で依存関係をインストールする:
pip install scrapy scrapy-splash最後の前提条件として、Docker経由でSplashイメージをプルする必要がある:
docker pull scrapinghub/splashそれからコンテナをスタートさせる:
docker run -it -p 8050:8050 --rm scrapinghub/splash詳細については、OSベースのDocker統合の説明に従ってください。
Docker コンテナを起動したら、Splash サービスが以下のメッセージをログに記録するまで待ちます:
Server listening on http://0.0.0.0:8050このメッセージは、Splashがhttp://0.0.0.0:8050。ブラウザでそのURLにアクセスすると、以下のページが表示されるはずです:
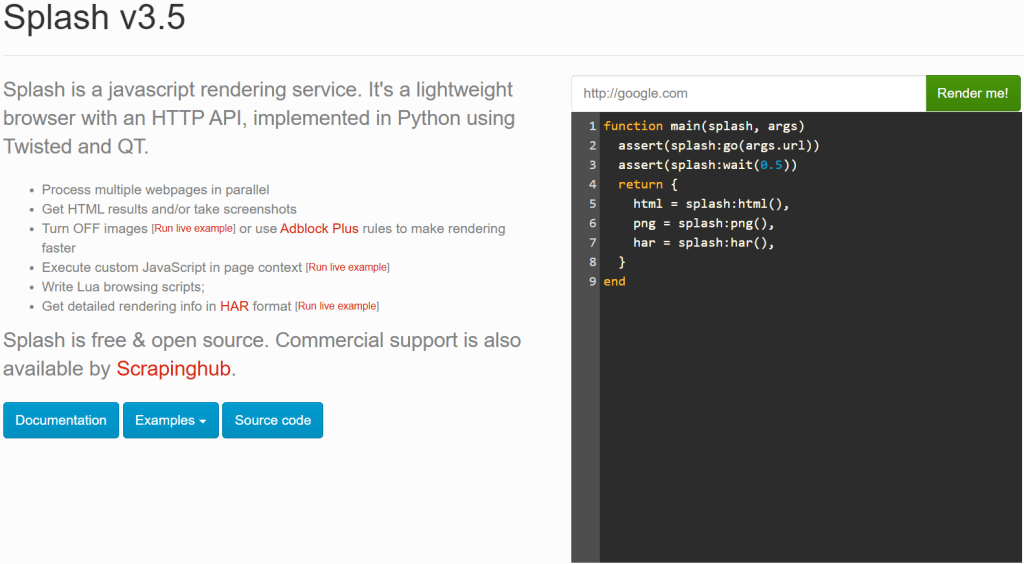
設定によっては、http://0.0.0.0:8050URL に従っても Splash サービスが動作しない場合があります。この場合は、代わりに次のいずれかを使用してみてください:
http://localhost:8050http://127.0.0.1:8050
注意: Scrapy-Splashを使用している間は、Splashサーバへの接続を開いたままにしておく必要があることを忘れないでください。つまり、CLIを使用してDockerコンテナを実行した場合は、そのターミナルを開いたままにしておき、この手順の次のステップでは別のターミナルを使用してください。
素晴らしい!これでScrapy Splashでウェブページをスクレイピングするのに必要なものが揃った。
ステップ #1: 新しいScrapyプロジェクトを開始する
scrapy_splash/mainフォルダの中で、以下のコマンドを入力し、新しいScrapyプロジェクトを起動します:
scrapy startproject quotesこのコマンドで、Scrapyはquotes/フォルダを作成します。その中に、必要なすべてのファイルを自動的に生成します。これが結果のフォルダ構造です:
scrapy_splash/
├── quotes/
│ ├── quotes/
│ │ ├── spiders/
│ │ ├── __init__.py
│ │ ├── items.py
│ │ ├── middlewares.py
│ │ ├── pipelines.py
│ │ └── settings.py
│ │
│ └── scrapy.cfg
└── venv/ 完璧だ!あなたは新しいScrapyプロジェクトを始めた。
ステップ2:スパイダーの生成
ターゲットウェブサイトをクロールする新しいスパイダーを生成するには、quotes/フォルダに移動します:
cd quotesそして、新しいスパイダーを生成する:
scrapy genspider words https://quotes.toscrape.com/scroll次のような結果が得られる:
Created spider 'words' using template 'basic' in module:
quotes.spiders.wordsお分かりのように、Scrapyは自動的にspiders/フォルダの中にwords.pyファイルを作成しました。words.pyファイルには以下のコードが含まれています:
import scrapy
class WordsSpider(scrapy.Spider):
name = "words"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["https://quotes.toscrape.com/scroll"]
def parse(self, response):
passこれにはすぐに、動的ターゲット・ページから必要なスクレイピング・ロジックが含まれる。
万歳!ターゲットのウェブサイトをスクレイピングするためにスパイダーを発生させたのだ。
ステップ3: ScrapyがSplashを使うように設定する
ScrapyがSplashサービスを使用できるように設定する必要があります。そのためには、settings.pyに以下の設定を追加します:
# Set the Splash local server endpoint
SPLASH_URL = "http://localhost:8050"
# Enable the Splash downloader middleware
DOWNLOADER_MIDDLEWARES = {
"scrapy_splash.SplashCookiesMiddleware": 723,
"scrapy_splash.SplashMiddleware": 725,
"scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware": 810,
}
# Enable the Splash deduplication argument filter
SPIDER_MIDDLEWARES = {
"scrapy_splash.SplashDeduplicateArgsMiddleware": 100,
}上記のコンフィグでは
SPLASH_URLは、ローカルのSplashサーバのエンドポイントを設定します。ここで Scrapy は JavaScript レンダリングのリクエストを送信します。DOWNLOADER_MIDDLEWARESは、特定のミドルウェアが Splash とやりとりできるようにします。特に:Polylang プレースホルダは
SPIDER_MIDDLEWARESは、同じ Splash 引数を持つリクエストが重複しないことを保証します。 これは、不要な負荷を減らし、効率を改善するために有用です。
これらの設定の詳細については、Scrapy-Splashの公式ドキュメントを参照してください。
良いことだ!これで Scrapy は Splash に接続し、JavaScript のレンダリングにプログラムで使用できるようになった。
ステップ4:JavaScriptレンダリング用Luaスクリプトの定義
Scrapy は Splash と統合して、このガイドの対象ページのように JavaScript に依存するウェブページをレンダリングできるようになった。カスタムレンダリングとインタラクションロジックを定義するには、Luaスクリプトを使用する必要があります。なぜならSplash は、JavaScript を介してウェブページと対話し、ブラウザの動作をプログラムで制御するためにLua スクリプトに依存しているからです。
具体的には、以下のLuaスクリプトをwords.pyに追加します:
script = """
function main(splash, args)
splash:go(args.url)
-- custom rendering script logic...
return splash:html()
end
"""上のスニペットでは、script変数に Splash がサーバー上で実行する Lua ロジックが含まれています。特に、このスクリプトは Splash に次のように指示します:
- メソッド
splash:go()で定義された URL に移動します。 - メソッド
splash:html()でレンダリングされた HTML コンテンツを返します。
上記のLuaスクリプトをWordsSpiderクラス内のstart_requests()関数で使用します:
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script}
)上記のstart_requests()メソッドは、Scrapy のデフォルトのstart_requests() をオーバーライドします。こうすることで、Scrapy SplashはLuaスクリプトを実行し、JavaScriptでレンダリングされたページのHTMLを取得することができます。Luaスクリプトの実行は、SplashRequest()メソッドの"lua_source": script引数を介して行われます。また、"execute"Splash エンドポイントを使用していることにも注意してください (詳細は後ほど説明します)。
Scrapy Splash からSplashRequest をインポートすることを忘れないでください:
from scrapy_splash import SplashRequestこれで、words.pyファイルには、ページ上のJavaScriptでレンダリングされたコンテンツにアクセスするための正しいLuaスクリプトが装備されました!
ステップ#5:データ解析ロジックの定義
始める前に、ターゲットページの引用HTMLエレメントを検査し、パース方法を理解する:

.quoteで見積もり要素を選択することができます。引用があれば、次のようになります:
.textからの引用テキスト。.authorからの引用者。.tagsの引用タグ。
ターゲット・ページからすべての引用を取得するスクレイピング・ロジックは、以下のparse()メソッドで定義できる:
def parse(self, response):
# Retrieve CSS selectors
quotes = response.css(".quote")
for quote in quotes:
yield {
"text": quote.css(".text::text").get(),
"author": quote.css(".author::text").get(),
"tags": quote.css(".tags a.tag::text").getall()
}parse() は、Splash が返すレスポンスを処理します。詳細には
- CSS セレクタ
".quote"を使って、quoteクラスを持つすべてのdiv要素を抽出します。 各クォート要素を繰り返し処理し、各クォートの名前、作者、タグを抽出します。
とても良い!Scrapy Splashのスクレイピング・ロジックは完成した。
ステップ6:すべてをまとめてスクリプトを実行する
これが最終的なwords.pyファイルです:
import scrapy
from scrapy_splash import SplashRequest
# Lua script for JavaScript rendering
script = """
function main(splash, args)
splash:go(args.url)
return splash:html()
end
"""
class WordsSpider(scrapy.Spider):
name = "words"
start_urls = ["https://quotes.toscrape.com/scroll"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script}
)
def parse(self, response):
quotes = response.css(".quote")
for quote in quotes:
yield {
"text": quote.css(".text::text").get(),
"author": quote.css(".author::text").get(),
"tags": quote.css(".tags a.tag::text").getall()
}このコマンドでスクリプトを実行する:
scrapy crawl wordsこれが予想された結果だ:
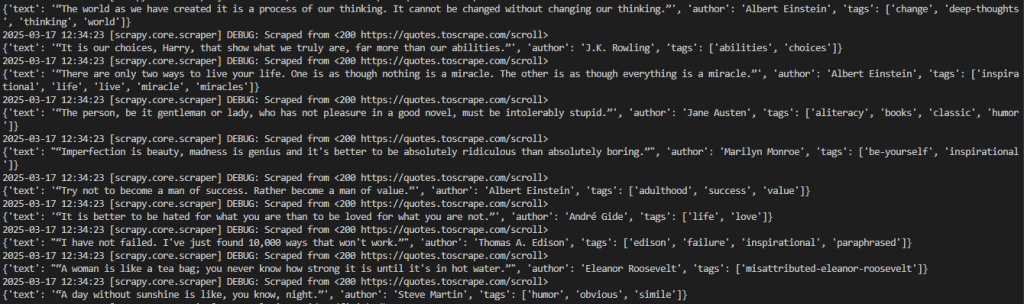
望ましい結果は、このように視覚化することができる:
2026-03-18 12:21:55 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/scroll>
{'text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”', 'author': 'Albert Einstein', 'tags': ['change', 'deep-thoughts', 'thinking', 'world']}
2026-03-18 12:21:55 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/scroll>
{'text': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”', 'author': 'J.K. Rowling', 'tags': ['abilities', 'choices']}
# omitted for brevity...
2026-03-18 12:21:55 [scrapy.core.engine] INFO: Closing spider (finished)出力には目的のデータが含まれていることに注意。
Words``Spiderクラスからstart_requests()メソッドを削除すると、Scrapyはデータを返さないことに注意してください。これは、SplashなしではJavaScriptを必要とするページをレンダリングできないからです。
とても良い!最初のScrapy Splashプロジェクトが完成しました。
スプラッシュについて
Splash は HTTP で通信するサーバーです。このため、Splash のエンドポイントを呼び出すことで、任意の HTTP クライアントを使用してウェブページをスクレイピングできます。Splash が提供するエンドポイントは次のとおりです:
- を
実行する:カスタムLuaレンダリングスクリプトを実行し、その結果を返す。 render.html:javascriptでレンダリングされたページのHTMLを返します。render.png:javascriptでレンダリングされたページの画像(PNG形式)を返します。render.jpeg:javascriptでレンダリングされたページの画像(JPEG形式)を返します。render.har:Splash とウェブサイトのやりとりに関する情報を HAR 形式で返します。render.json:javascriptでレンダリングされたウェブページに関する情報をJSONエンコードした辞書を返します。渡された引数に基づいて、HTML、PNG、その他の情報を含むことができます。
これらのエンドポイントがどのように機能するかをより理解するために、render.htmlエンドポイントを考えてみよう。次のPythonコードでエンドポイントに接続します:
# pip install requests
import requests
import json
# URL of the Splash endpoint
url = "http://localhost:8050/render.html"
# Sending a POST request to the Splash endpoint
payload = json.dumps({
"url": "https://quotes.toscrape.com/scroll" # URL of the page to render
})
headers = {
"content-type": "application/json"
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)このスニペットはこう定義している:
render.htmlエンドポイントを呼び出す URL として、localhost 上の Splash インスタンスを指定します。ペイロード内でスクレイピングするターゲットページ。
上記のコードを実行すると、ページ全体のレンダリングされたHTMLが得られる:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Quotes to Scrape</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>SplashはJavaScriptでレンダリングされたHTMLを単独で扱うことができるが、Scrapy SplashとSplashRequestを使うことで、ウェブスクレイピングがより簡単になる。
Scrapy Splash:高度なスクレイピング・テクニック
前の段落では、Splashを統合した基本的なScrapyチュートリアルを完了しました。Scrapy Splashを使った高度なスクレイピングテクニックを試してみましょう!
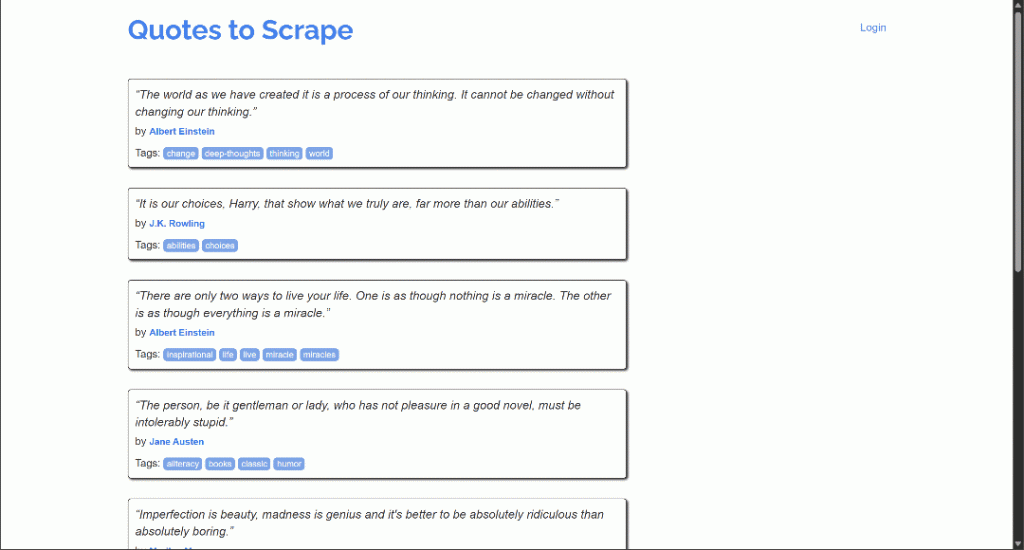
高度なスクロールの管理
ターゲット・ページには、無限スクロールのおかげでAJAX経由で動的にロードされる相場が含まれている:
無限スクロールとのインタラクションを管理するには、Luaスクリプトを以下のように変更する必要がある:
script = """
function main(splash, args)
local scroll_delay = 1.0 -- Time to wait between scrolls
local max_scrolls = 10 -- Maximum number of scrolls to perform
local scroll_to = 1000 -- Pixels to scroll down each time
splash:go(args.url)
splash:wait(scroll_delay)
local scroll_count = 0
while scroll_count < max_scrolls do
scroll_count = scroll_count + 1
splash:runjs("window.scrollBy(0, " .. scroll_to .. ");")
splash:wait(scroll_delay)
end
return splash:html()
end
"""この修正スクリプトは、これらの変数に依存している:
max_scrollsはスクロールの最大回数を定義します。この値は、ページからスクレイピングしたいコンテンツの量に応じて変更する必要があるかもしれません。scroll_toは、毎回スクロールダウンするピクセル数を指定します。この値は、ページの動作によって調整する必要があるかもしれません。splash:runjs()は、window.scrollBy()JavaScript関数を実行し、指定したピクセル数だけページをスクロールさせます。splash:wait()は、スクリプトが新しいコンテンツをロードする前に待機することを保証します。待つ時間 (秒単位) はscroll_delay変数で定義します。
簡単に言うと、上記のLuaスクリプトは、無限スクロールのウェブページのシナリオで定義されたスクロール数をシミュレートします。
words.pyファイルのコードは次のようになります:
import scrapy
from scrapy_splash import SplashRequest
# Lua script for infinite scrolling
script = """
function main(splash, args)
local scroll_delay = 1.0 -- Time to wait between scrolls
local max_scrolls = 10 -- Maximum number of scrolls to perform
local scroll_to = 1000 -- Pixels to scroll down each time
splash:go(args.url)
splash:wait(scroll_delay)
local scroll_count = 0
while scroll_count < max_scrolls do
scroll_count = scroll_count + 1
splash:runjs("window.scrollBy(0, " .. scroll_to .. ");")
splash:wait(scroll_delay)
end
return splash:html()
end
"""
class WordsSpider(scrapy.Spider):
name = "words"
start_urls = ["https://quotes.toscrape.com/scroll"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script}
)
def parse(self, response):
# Retrieve CSS selectors
quotes = response.css("div.quote")
for quote in quotes:
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("span small.author::text").get(),
"tags": quote.css("div.tags a.tag::text").getall()
}以下のコマンドを使ってスクリプトを実行する:
scrapy crawl wordsクローラーは、max_scrolls変数で一貫してスクレイピングされたすべての引用を表示します。これが期待される結果です:
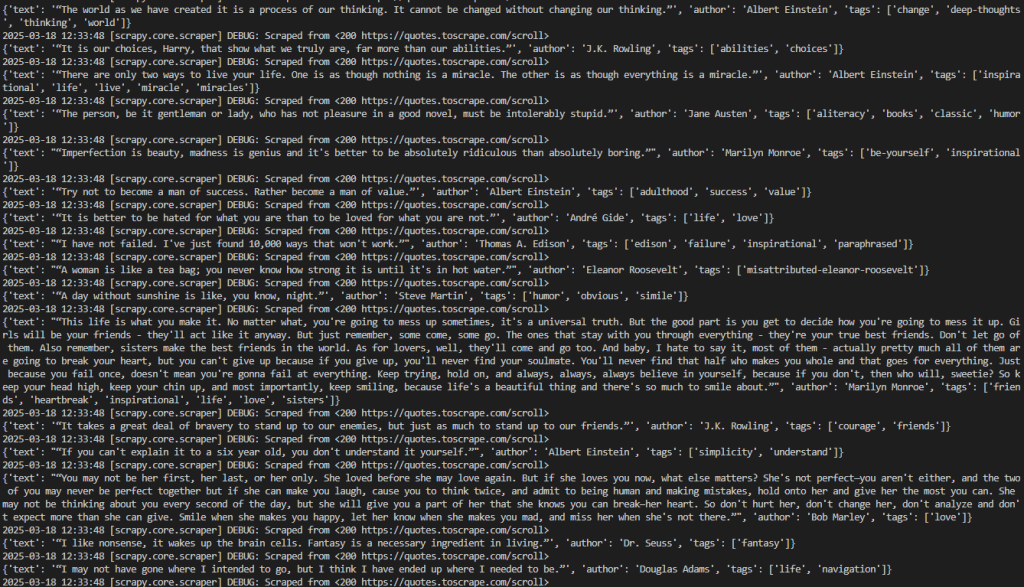
出力には、以前よりもかなり多くの引用が含まれていることに注意してください。これは、ページが正常にスクロールダウンされ、新しいデータがロードされ、スクレイピングされたことを示している。
完璧だ!これでScrapy Splashで無限スクロールを管理する方法を学んだことになる。
エレメントを待つ
ウェブページは動的にデータを取得したり、ブラウザでノードをレンダリングしたりすることができる。これは、最終的なDOMのレンダリングに時間がかかる可能性があることを意味します。ウェブサイトからデータを取得する際のエラーを避けるためには、要素がページに読み込まれるのを常に待ってから、その要素を操作する必要があります。
この例では、待機する要素は最初の引用文のテキストになる:

待機ロジックを実装するには、以下のようにLuaスクリプトを書く:
script = """
function main(splash, args)
splash:go(args.url)
while not splash:select(".text") do
splash:wait(0.2)
print("waiting...")
end
return { html=splash:html() }
end
"""このスクリプトは、text要素がページ上にあるかどうかを0.2秒間待つwhileループを作成します。.text要素がページ上にあるかどうかを確認するには、splash:select()メソッドを使用します。
時を待つ
動的コンテンツのウェブページは読み込みとレンダリングに時間がかかるので、HTMLコンテンツにアクセスする前に数秒間待つことができます。これは、splash:wait() というメソッドで実現できます:
script = """
function main(splash, args)
splash:wait(args.wait)
splash:go(args.url)
return { html=splash:html() }
end
"""この場合、スクリプトが待機しなければならない秒数は、SplashRequest()メソッドでLuaスクリプトの 引数で表現される。
例えば、"wait" : 2.0とすると、Luaスクリプトに2秒待つように指示する:
import scrapy
from scrapy_splash import SplashRequest
script = """
function main(splash, args)
splash:wait(args.wait)
splash:go(args.url)
return { html=splash:html() }
end
"""
class WordsSpider(scrapy.Spider):
name = "words"
start_urls = ["https://quotes.toscrape.com/scroll"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script, "wait": 2.0} # Waiting for 2 seconds
)
# ...注:ハードウェイト(splash:wait())は、ページが確実にロードされてから処理を進めるので、ローカルテストには便利です。なぜなら、不必要な遅延が発生し、 パフォーマンスやスケーラビリティに悪影響を及ぼすからです。さらに、事前に適切な待ち時間を知ることはできません。
よくやった!あなたはScrapy Splashで一定時間待つ方法を学んだ。
Scrapy Splashを使用する際の制限
このチュートリアルでは、Scrapy Splashを使ってさまざまなシナリオでウェブからデータを抽出する方法を学びました。この統合は簡単ですが、いくつかの欠点があります。
例えば、Splash をセットアップするには、Docker を使って別の Splash サーバを実行する必要があり、スクレイピング・インフラに複雑さを加えることになる。さらに、SplashのLuaスクリプトAPIは、PuppeteerやPlaywrightのような最新のツールに比べるとやや限定的だ。
しかし、他のヘッドレス・ブラウザと同様、最大の制限はブラウザ自体にある。スクレイピング防止技術は、ブラウザが通常使用されているのではなく、自動化されていることを検知し、スクリプトをブロックすることができる。
スクレイピング・ブラウザは、無限のスケーラビリティのために設計されたクラウドベースのスクレイピング専用ブラウザです。CAPTCHA解決、ブラウザフィンガープリント管理、アンチボットバイパスを備えているので、ブロックされる心配はありません。
結論
この記事では、Scrapy Splashとは何か、どのように動作するのかを学びました。基本的なことから始めて、より複雑なスクレイピングシナリオを探りました。
また、このツールの限界、特にアンチボットやアンチスクレイピングシステムに対する脆弱性も発見されたことでしょう。これらの課題を克服するために、Scraping Browserは優れたソリューションです。これは、あなたが試すことができる多くのBright Dataスクレイピングソリューションの一つに過ぎません:
- プロキシ・サービス:1億5,000万以上の家庭用IPを含む、ロケーション制限を回避する4種類のプロキシ
- ウェブスクレーパーAPI:100以上の人気ドメインから新鮮で構造化されたウェブデータを抽出するための専用エンドポイント。
- SERP API:SERPのすべての継続的なロック解除管理を処理し、1つのページを抽出するAPI
今すぐBright Dataに登録し、無料トライアルを開始してスクレイピングソリューションをお試しください。






