

Webスクレイピングに興味をお持ちの方には、 Crawlee がお役に立つこと間違いなしです。これは、データサイエンティストや開発者、研究者などがウェブデータの収集に使用する、高速でインタラクティブなスクレイピングエンジンです。Crawleeは、設定が非常に簡単で、 プロキシローテーション や セッション処理などの機能を提供しています。これらの機能は、IPアドレスがブロックされることなく動的または大規模なウェブサイトをスクレイピングするために不可欠であり、スムーズで中断されることのないデータ収集を可能にします。
このチュートリアルでは、Crawleeを使用したWebスクレイピング方法を学びます。基本的なWebスクレイピング例の学習から始め、セッション管理や動的ページのスクレイピングなど、より高度なコンセプトへと進みます。
Crawleeを使用したWebスクレイピングの方法
チュートリアルを始める前に、使用中の機器に以下の前提条件がインストールされていることをご確認ください:
- Node.js
- npm: これは通常Node.jsに付属しています。ターミナルで
node -vまたはnpm -vを実行することにより、インストール状況が確認できます。 - お好みのコードエディター: このチュートリアルでは Visual Studio Codeを使用します。
Crawleeを使用した基本的なWebスクレイピング
前提条件がすべて揃ったら、 Books to Scrape ウェブサイトをスクレイピングすることから始めましょう。このサイトはシンプルなHTML構造を提供しているため、学習に最適です。
ターミナルまたはシェルを開き、次のコマンドでNode.jsプロジェクトを初期化します。
mkdir crawlee-tutorial
cd crawlee-tutorial
npm init -y
初期化が完了したら、次のコマンドでCrawleeライブラリをインストールします。
npm install crawlee
ウェブサイトのデータを効果的にスクレイピングするには、スクレイピングを希望するウェブページの検証を行い、サイトのHTMLタグの詳細を取得する必要があります。このためにはブラウザでウェブサイトを開き、ウェブページの任意の場所を右クリックすることにより、 デベロッパーツール に移動します。次に、 Inspect(検証) または Inspect Element(要素を検証)をクリックします。
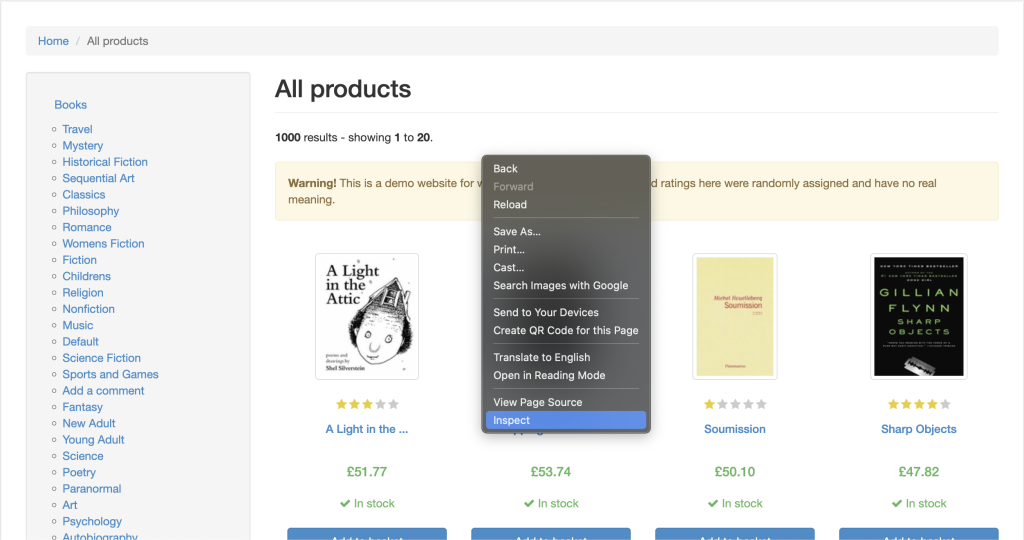
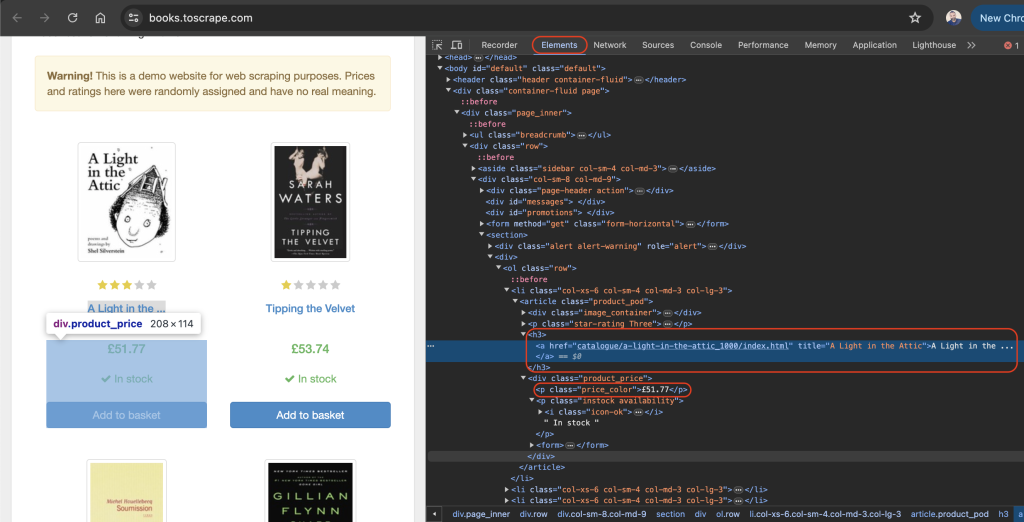
Elements(検証) タブがデフォルトでアクティブになっているはずです。このタブはウェブページのHTMLレイアウトを表しています。この事例では、表示されるすべての書籍が article HTMLタグに product_podのクラス名で配置されています。各記事の h3 タグ内に、書籍のタイトルが含まれています。書籍の実際のタイトルは、 h3 要素内にある a タグの title 属性に含まれています。書籍の価格は、 price_colorのクラス名で p タグの中に配置されています。
プロジェクトのルートディレクトリに scrape.js という名前のファイルを作成し、次のコードを追加します。
const { CheerioCrawler } = require('crawlee');
const crawler = new CheerioCrawler({
async requestHandler({ request, $ }) {
const books = [];
$('article.product_pod').each((index, element) => {
const title = $(element).find('h3 a').attr('title');
const price = $(element).find('.price_color').text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(['https://books.toscrape.com/']);
このコードでは、 crawlee の CheerioCrawler を使用し、 https://books.toscrape.com/から書籍のタイトルと価格をスクレイピングします。クローラーはHTMLコンテンツを取得した後、jQueryのような構文を使用して
要素からデータを抽出し、その結果をコンソールに記録します。
scrape.js ファイルに前のコードを追加すると、次のコマンドでコードを実行することができます。
node scrape.js
これにより、書籍のタイトルと価格の配列がターミナルに出力されます。
…output omitted…
{
title: 'The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics',
price: '£22.60'
},
{ title: 'The Black Maria', price: '£52.15' },
{
title: 'Starving Hearts (Triangular Trade Trilogy, #1)',
price: '£13.99'
},
{ title: "Shakespeare's Sonnets", price: '£20.66' },
{ title: 'Set Me Free', price: '£17.46' },
{
title: "Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)",
price: '£52.29'
},
…output omitted…
Crawleeを使用したプロキシローテーション
プロキシは、コンピュータとインターネットの仲介者の役割を果たします。プロキシを使用すると、ウェブリクエストがプロキシサーバーに送信され、プロキシサーバーはそれらを対象ウェブサイトに転送します。次にプロキシサーバーはウェブサイトからのレスポンスを返し、プロキシはユーザーのIPアドレスを隠すことにより、レート制限やIPの禁止措置を回避します。
Crawleeには、再試行やエラーを効率的に処理するプロキシ処理が組み込まれているため、プロキシの実装が簡単になります。Crawleeでは、ローテーションプロキシを実装するためのプロキシ構成も多種サポートされています。
次のセクションではまず、有効なプロキシを取得することにより、プロキシの設定を行います。次に、リクエストがプロキシを経由していることを確認します。
プロキシの設定
無料のプロキシは、低速で安全性が低く、機密性の高いウェブタスクに必要となるサポートが提供されない可能性があるため、一般的には推奨されていません。プロキシサービスをお探しなら、安全性と安定性、そして信頼性の高い Bright Dataの使用を検討しましょう。無料トライアルも提供されているため、購入の前に機能をテストすることができます。
Bright Dataを使用するには、 ホームページ から 無料トライアルを開始 ボタンをクリックし、必要な情報を入力してアカウントを作成します。
アカウントの作成が完了したら、Bright Dataダッシュボードにログインし、 プロキシおよびスクレイピングインフラストラクチャに移動後、 住宅用プロキシを選択して新しいプロキシを追加します。
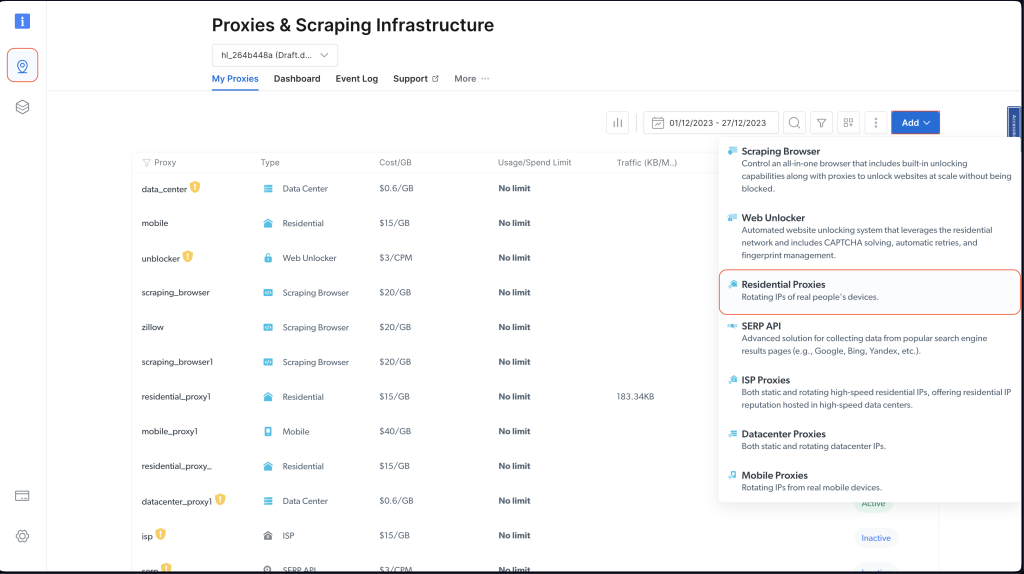
追加をクリックし、デフォルト設定を保持した状態で住宅用プロキシの作成を完了します。
証明書のインストールを求められたら、 証明書なしで続行を選択します。ただし、実稼働環境や実際のユースケースでは、プロキシ情報が公開された場合に悪用されないよう、証明書の設定を行う必要があります。
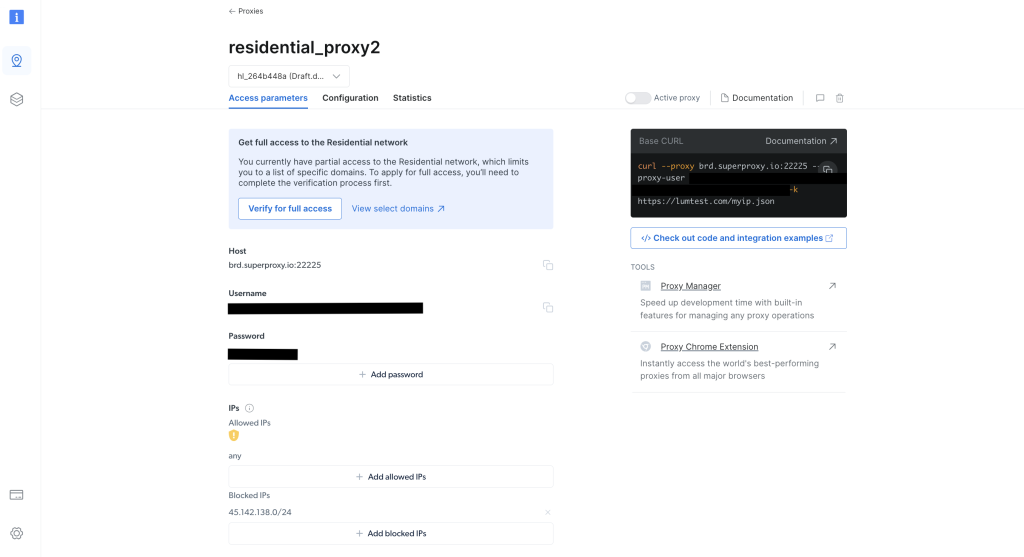
作成が完了したら、プロキシ資格情報(ホスト、ポート、ユーザー名、パスワードなど)をメモします。これらは次のステップで必要になります。
プロジェクトのルートディレクトリより、次のコマンドを実行して axios ライブラリをインストールします。
npm install axios
axiosライブラリを使用して http://lumtest.com/myip.jsonにGETリクエストを送信すると、スクリプトを実行する度に使用中のプロキシの詳細が返されます。
次に、プロジェクトのルートディレクトリに scrapeWithProxy.js という名前のファイルを作成し、次のコードを追加します。
const { CheerioCrawler } = require("crawlee");
const { ProxyConfiguration } = require("crawlee");
const axios = require("axios");
const proxyConfiguration = new ProxyConfiguration({
proxyUrls: ["http://USERNAME:PASSWORD@HOST:PORT"],
});
const crawler = new CheerioCrawler({
proxyConfiguration,
async requestHandler({ request, $, response, proxies }) {
// Make a GET request to the proxy information URL
try {
const proxyInfo = await axios.get("http://lumtest.com/myip.json", {
proxy: {
host: "HOST",
port: PORT,
auth: {
username: "USERNAME",
password: "PASSWORD",
},
},
});
console.log("Proxy Information:", proxyInfo.data);
} catch (error) {
console.error("Error fetching proxy information:", error.message);
}
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(["https://books.toscrape.com/"]);
注:必ず
HOST(ホスト)、PORT(ポート)、USERNAME(ユーザー名)、およびPASSWORD(パスワード)をご本人の資格情報に置き換えてください。
このコードでは、 crawlee の CheerioCrawler を使用し、指定されたプロキシにより https://books.toscrape.com/ の情報をスクレイピングします。 プロキシ構成からプロキシの構成を行い、GETリクエストを使用してプロキシの詳細を取得した後、 http://lumtest.com/myip.jsonに記録します。最後に、CheerioのjQueryのような構文を使用して書籍のタイトルと価格を抽出し、スクレイピングされたデータをコンソールに記録します。
これにより、コードを実行してテストし、プロキシが機能していることを確認することができます。
node scrapeWithProxy.js
以前と同様の結果が表示されますが、今回のリクエストはBright Dataプロキシ経由によりルーティングされます。コンソールに記録されているプロキシの詳細も表示されます。
Proxy Information: {
country: 'US',
asn: { asnum: 21928, org_name: 'T-MOBILE-AS21928' },
geo: {
city: 'El Paso',
region: 'TX',
region_name: 'Texas',
postal_code: '79925',
latitude: 31.7899,
longitude: -106.3658,
tz: 'America/Denver',
lum_city: 'elpaso',
lum_region: 'tx'
}
}
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
{ title: 'Soumission', price: '£50.10' },
{ title: 'Sharp Objects', price: '£47.82' },
{ title: 'Sapiens: A Brief History of Humankind', price: '£54.23' },
{ title: 'The Requiem Red', price: '£22.65' },
…output omitted..
scrapingWithBrightData.jsのノードでスクリプトを再度実行すると、Bright Dataのプロキシサーバーにより使用されている別のIPアドレスが表示されるはずです。これにより、スクレイピングスクリプトを実行する度にBright Dataが位置情報とIPをローテーションしていることが検証されます。このローテーションは、対象ウェブサイトからのブロックやIP禁止措置を回避するにあたり、重要となります。
注:
プロキシ構成にて異なるプロキシIPを渡すこともできますが、Bright Dataの場合はIPが自動的に指定されるため、手動で指定を行う必要がありません。
Crawleeにおけるセッション管理
セッションは複数のリクエストにおける状態維持を可能にするため、Cookieまたはログインセッションを使用するウェブサイトで役立ちます。
セッションを管理するには、プロジェクトのルートディレクトリに scrapeWithSessions.js という名前のファイルを作成し、次のコードを追加します。
const { CheerioCrawler, SessionPool } = require("crawlee");
(async () => {
// Open a session pool
const sessionPool = await SessionPool.open();
// Ensure there is a session in the pool
let session = await sessionPool.getSession();
if (!session) {
session = await sessionPool.createSession();
}
const crawler = new CheerioCrawler({
useSessionPool: true, // Enable session pool
async requestHandler({ request, $, response, session }) {
// Log the session information
console.log(`Using session: ${session.id}`);
// Extract book data and log it (for demonstration)
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
// First run
await crawler.run(["https://books.toscrape.com/"]);
console.log("First run completed.");
// Second run
await crawler.run(["https://books.toscrape.com/"]);
console.log("Second run completed.");
})();
この例では、 crawlee の CheerioCrawler と SessionPool を使用し、 https://books.toscrape.com/からデータをスクレイピングしています。セッションプールを初期化し、セッションを利用するためにクローラーの構成を行います。 requestHandler 関数はセッション情報を記録し、jQueryのようなCheerioのセレクタを使用して書籍のタイトルと価格を抽出します。このコードは2回連続でスクレイピングを実行し、その度にセッションIDを記録します。
コードを実行してテストすることにより、別のセッションが利用されていることを確認します。
node scrapeWithSessions.js
以前と同様の結果が表示されますが、今回は各実行分のセッションIDも表示されます。
Using session: session_GmKuZ2TnVX
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…output omitted…
Using session: session_lNRxE89hXu
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…output omitted…
コードを再度実行すると、別のセッションIDが使用されていることが確認できるはずです。
Crawleeにおける動的コンテンツの処理
動的ウェブサイト ( JavaScriptによって埋め込まれたコンテンツを含むウェブサイト)を扱う場合、データにアクセスするにはJavaScriptをレンダリングする必要があるため、Webスクレイピングは非常に困難になります。このような状況に対処するため、Crawleeは Puppeteer(JavaScriptをレンダリングし、対象ウェブサイトと人間のようにインタラクションすることができるヘッドレスブラウザ)との統合が可能です。
機能の実証のため、 このYouTubeページからコンテンツをスクレイピングしてみましょう。いつも通り、スクレイピングの前にはページに適用される ルールと利用規約 を確認します。
利用規約を確認したら、プロジェクトのルートディレクトリにて scrapeDynamicContent.js という名前のファイルを作成し、次のコードを追加します。
const { PuppeteerCrawler } = require("crawlee");
async function scrapeYouTube() {
const crawler = new PuppeteerCrawler({
async requestHandler({ page, request, enqueueLinks, log }) {
const { url } = request;
await page.goto(url, { waitUntil: "networkidle2" });
// Scraping first 10 comments
const comments = await page.evaluate(() => {
return Array.from(document.querySelectorAll("#comments #content-text"))
.slice(0, 10)
.map((el) => el.innerText);
});
log.info(`Comments: ${comments.join("n")}`);
},
launchContext: {
launchOptions: {
headless: true,
},
},
});
// Add the URL of the YouTube video you want to scrape
await crawler.run(["https://www.youtube.com/watch?v=wZ6cST5pexo"]);
}
scrapeYouTube();
追加が完了したら、次のコマンドによりコードを実行します。
node scrapeDynamicContent.js
このコードでは、Crawleeライブラリの PuppeteerCrawler を使用し、YouTube動画のコメントをスクレイピングします。まず、クローラーの初期化を行います。次に、クローラーが特定のYouTube動画のURLに移動し、ページが完全に読み込まれるのを待ちます。ページが読み込まれると、コードは最初のコメント10件を抽出するために、指定されたCSSセレクタ #comments #content-textを使用して要素を選択し、ページのコンテンツ評価を行います。次に、コメントがコンソールに記録されます。
これにより、選択した動画に関連する最初の10件のコメントが出力されるはずです。
INFO PuppeteerCrawler: Starting the crawler.
INFO PuppeteerCrawler: Comments: Who are you rooting for?? US Marines or Ex Cons
Bro Mateo is a beast, no lifting straps, close stance.
ex convict doing the pushups is a monster.
I love how quick this video was, without nonsense talk and long intros or outros
"They Both have combat experience" is wicked
That military guy doing that deadlift is really no joke.. ...
One lives to fight and the other fights to live.
Finally something that would test the real outcome on which narrative is true on movies
I like the comradery between all of them. Especially on the Bench Press ... Both team members quickly helped out on the spotting to protect from injury. Well done.
I like this style, no youtube funny business. Just straight to the lifts
…output omitted…
このチュートリアルで使われたすべてのコードは、 GitHubにて見つけることができます。
まとめ
今回の記事では、Crawleeを使用したWebスクレイピングの方法と、Crawleeの使用がスクレイピングの効率性と信頼性の向上にどれだけ役立つかということについて学びました。
データをスクレイピングするときは、常に対象ウェブサイトの robots.txt ファイルと利用規約を尊重しましょう。
プロレベルのデータやツール、そしてプロキシを使用し、Webスクレイピングをレベルアップする準備はできましたか? Bright Dataの包括的なWebスクレイピングプラットフォームを利用し、すぐに使えるデータセットと高度なプロキシサービスによって、データ収集作業を効率化しましょう。
今すぐサインアップして無料トライアルを始めましょう!





