

このガイドで、あなたは学ぶだろう:
- 静的コンテンツと動的コンテンツの違いを知るべき理由
- 静的コンテンツとは何か、どのようにそれを検出するか、どのツールを使ってそれをスクレイピングするか、そしてそれに伴う課題。
- ダイナミックコンテンツとは何か、どのように識別するか、どのツールがスクレイピングに最適か、そして遭遇する可能性のある障害とは?
- ウェブ・スクレイピングにおける静的コンテンツと動的コンテンツの比較表
さあ、飛び込もう!
ウェブ・スクレイピングにおける静的コンテンツと動的コンテンツ入門
ウェブスクレイピングに関しては、抽出したいコンテンツが静的か動的かによってアプローチに大きな違いがあります。この違いは、データの解析、処理、抽出の処理方法に大きく影響します。
経験則として、SEOのために最適化されたセクションやページは静的である傾向があります。代わりに、非常にインタラクティブなセクションやライブ更新が必要なセクションは、一般的に動的である。しかし、ほとんどの場合、現実はもっと複雑です。
最近のウェブページは、静的コンテンツと動的コンテンツの両方を含むハイブリッド型であることが多い。したがって、ページ全体を単に「静的」または「動的」とラベリングすることは、通常不正確です。ページ内の特定のコンテンツが静的か動的か、と言った方が正確です。
さらに問題を複雑にするのは、あるサイトのあるページが静的であっても、同じサイトの別のページが動的であるかもしれないということです。1つのウェブページに両方のタイプのコンテンツが含まれることがあるように、ウェブサイトは静的なページと動的なページの両方のコレクションになり得ます。
ということを念頭に置いて、以下の静的コンテンツと動的コンテンツの比較を掘り下げてみる準備をしよう!
静的コンテンツ
ウェブページの静的コンテンツとそれをスクレイピングする方法について知っておくべきことをすべて説明しよう。
スタティック・コンテンツとは何か?
静的コンテンツとは、サーバーから返されるHTMLドキュメントに直接埋め込まれた、ウェブページ上のすべての要素を指します。言い換えれば、クライアント側のレンダリングや、ブラウザによる追加のデータ検索を必要としません。したがって、最初のHTMLレスポンスにすべてがすでに存在しています。
これには通常、UI要素やテキスト、画像など、サーバー側のソースコードが更新されない限り変化しないコンテンツが含まれます。クライアントへ送信するHTMLドキュメントを生成する前に、サーバーがデータベースやAPIから動的にデータをフェッチしたとしても、クライアントの視点からは、そのコンテンツは静的なものとみなされます。ブラウザでそれ以上の処理が必要ないからです。
ウェブページが静的コンテンツを使用しているかどうかを見分ける方法
冒頭で述べたように、現代のウェブサイトが100%静的であることは稀である。結局のところ、ほとんどのウェブページは、ある程度のクライアントサイドのインタラクティブ性を含んでいます。ですから、本当の問題は、ページが完全に静的か動的かではなく、ページのどの部分に静的なコンテンツが使われているかということです。
コンテンツの一部が静的かどうかを判断するには、サーバーから返された生のHTMLドキュメントを検査する必要がある。これは、ブラウザで見るものとは違うことに注意してほしい。ブラウザはレンダリングされたDOMを表示しますが、これはページがロードされた後にJavaScriptによって変更される可能性があります。
ページが静的コンテンツを使用しているかどうかを確認し、どの要素が静的であるかを特定する簡単な方法が2つあります:
- ページのソースを見る
- HTTPクライアントを使用する
最初の方法を適用するには、ページの空白領域を右クリックし、「ページソースを表示」オプションを選択する:

結果はサーバーから返されたオリジナルのHTMLになる:

例えば、この場合、quote要素がすでにこのHTMLに存在していることがわかる。したがって、これらは静的なものだと考えて差し支えない。
2つ目の方法は、HTTPクライアントを使い、ページのURLに単純なGETリクエストを行う方法である:

繰り返しますが、これはサーバーから返された生のHTMLを示しています。HTTPクライアントはJavaScriptを実行できないので、DOMの変更を心配する必要はありません。しかし、これから説明するように、あなたのリクエストはボット対策のためにサーバーによってブロックされるかもしれません。したがって、”View page source “メソッドを使用することをお勧めします。
静的コンテンツをスクレイピングするツール
静的コンテンツのスクレイピングは、ページのHTMLソースに直接埋め込まれるため、簡単だ。以下にプロセスの基本的な概要を示す:
- 単純なHTTPクライアントを使用してページのURLにGETリクエストを実行し、HTMLドキュメントを取得します。
- HTMLパーサーを使ってレスポンスを解析する。
- CSSセレクタ、XPath、またはHTMLパーサーが提供する同様の戦略を使って、必要な要素を抽出する。
コンテンツスクレイピングに使用するツールをお探しの場合は、以下の詳細ガイドをご覧ください:
Pythonを使ったWebスクレイピングのチュートリアルで、”Quotes to Scrape “サイトに関連する完全な例(HTMLは前のセクションで示した)を見ることができます。
静的コンテンツを取得するための一般的なスクレイピング・スタックには、以下のようなものがある:
- Python:Requests + Beautiful Soup, HTTPX + Beautiful Soup, AIOHTTP + Beautiful Soup
- JavaScript:Axios + Cheerio、Node Fetch + Cheerio、Fetch API + Cheerio
- PHP: cURL + DomCrawler, Guzzle + DomCrawler, cURL + Simple HTML DOM Parser
- C#:HttpClient + HtmlAgilityPack、HttpClient + AngleSharp
“BeautifulSoupはSeleniumよりも高速で、メモリ使用量も少ない。JavaScriptを実行したり、HTMLを解析してDOMを操作する以外のことはしない。”– Redditでの議論
静的コンテンツ・スクレイピングの課題
静的コンテンツのスクレイピングにおける主な課題は、HTMLドキュメントを取得するための正しいHTTPリクエストを行うことにある。多くのサーバーは実際のブラウザにのみコンテンツを提供するように設定されているため、特定のヘッダーが欠けていたり、TLSフィンガープリントのチェックに失敗したりすると、リクエストをブロックする可能性があります。
このような問題を避けるには、ウェブスクレイピング用の適切なHTTPヘッダーを手動で設定する必要がある。あるいは、cURL Impersonateのような、ブラウザの動作をシミュレートできる高度なHTTPクライアントを使う。
そうでなければ、コードの厄介なトリックや回避策に頼らないプロフェッショナルなソリューションとして、Web Unlockerの使用を検討してください。これは、サーバーが実装している防御メカニズムに関係なく、あらゆるウェブページのHTMLを返すエンドポイントです。
さらに、同じIPアドレスからあまりに多くのリクエストを送信すると、レート制限やIP禁止を引き起こす可能性があります。これを防ぐには、複数のIPにリクエストを分散させるローテーションプロキシを統合してください。プロキシを使用してIP禁止を回避する方法については、ガイドを参照してください。
ダイナミック・コンテンツ
この静的コンテンツと動的コンテンツの比較ガイドの続きとして、動的コンテンツがどのようにウェブページに読み込まれ、レンダリングされるのか、そしてそれをどのようにスクレイピングするのかを探ってみよう。
ダイナミック・コンテンツとは何か?
ウェブページでは、動的コンテンツとは、最初のページロード時またはユーザーとのインタラクションの後に、クライアント側でロードまたはレンダリングされるコンテンツを指します。これには、AJAXや WebSocketのような技術によって取得されたデータや、JavaScript内に埋め込まれ、ブラウザの実行時にレンダリングされるコンテンツが含まれます。
特に動的コンテンツは、サーバーから返される元のHTML文書の一部ではない。JavaScriptの実行後にページに追加されるからだ。つまり、JavaScriptを実行できる唯一のツールであるブラウザでページがレンダリングされない限り、それは表示されない。
Webページが動的コンテンツを使用しているかどうかを見分ける方法
ページが動的かどうかを見分ける最も簡単な方法は、静的コンテンツを検出するために使用される逆のアプローチに従うことです。サーバーから返されたHTMLドキュメントに、あなたがページで見ているコンテンツが含まれていない場合、クライアントでそのコンテンツを動的に取得またはレンダリングするメカニズムが存在します。
その逆は必ずしもうまくいかない。サーバーから返されたHTMLにコンテンツがあったとしても、そのページが完全に静的であるとは限らない。そのコンテンツは古く、ページがロードされた後、クライアントが一度だけ、あるいは定期的に動的に更新する可能性があります。例えば、ライブ・アップデートを表示するページでは、このようなケースがよくあります。
一般的に、ページに動的コンテンツが含まれているかどうかを確認するには、ページをリロードするか、ブラウザのDevToolsで「Network」セクションを検査しながら、コンテンツを表示させるユーザーアクションを繰り返します:
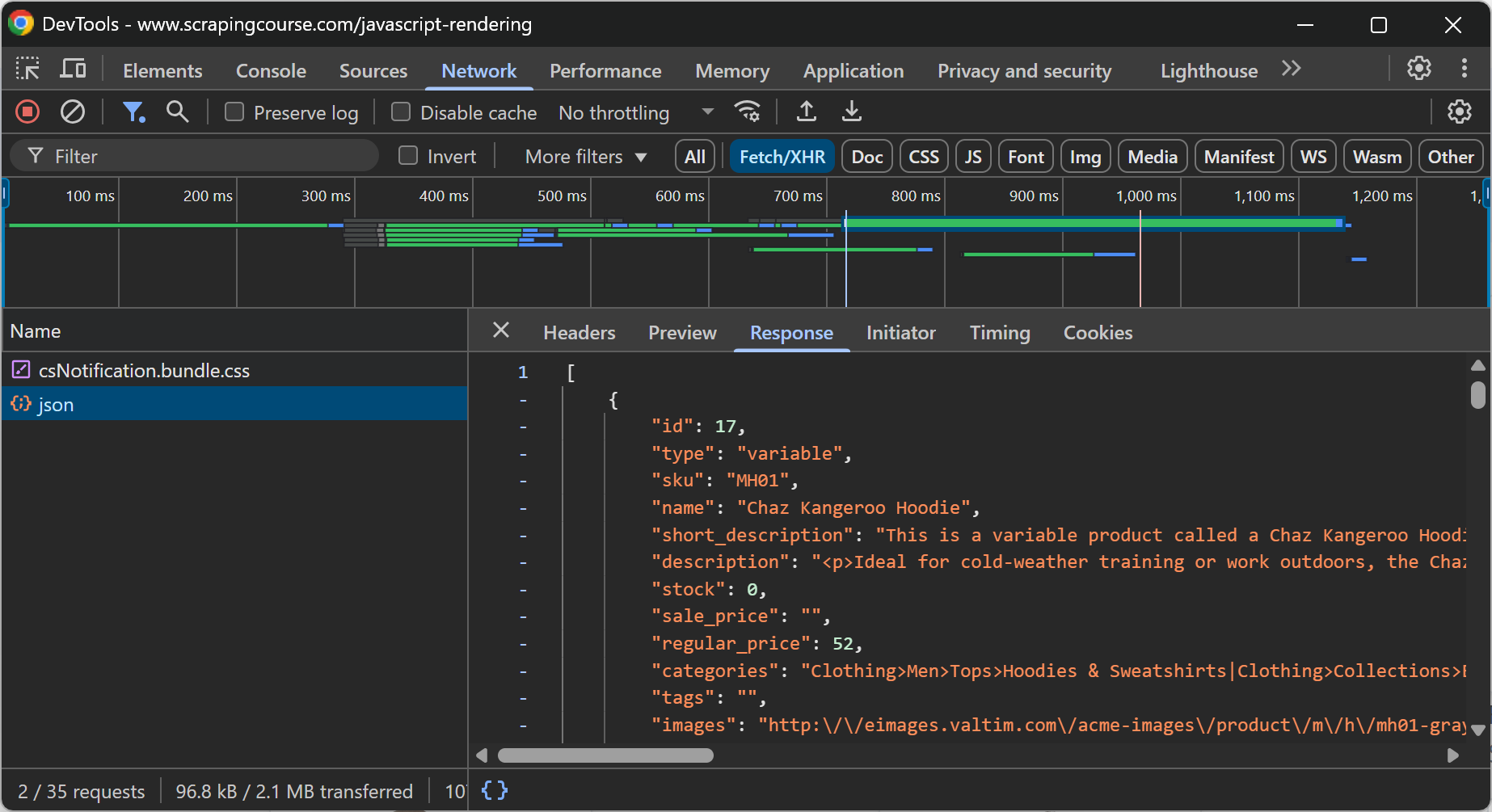
例えば、上記のウェブページでは、eコマース・データがAJAXを介して実行されるAPIコールによってクライアントで動的に取得されていることが明らかである。
動的コンテンツのもうひとつのソースとして考えられるのは、SPA(シングル・ページ・アプリケーション)として構築されたウェブ・アプリケーションだ。これらは、JavaScriptのレンダリングに大きく依存するReactのようなフロントエンド技術によって動かされる。そのため、DevToolsで表示されるDOMがサーバーから返されるHTMLと大きく異なる場合、そのページは動的です。
動的コンテンツをスクレイピングするツール
動的コンテンツのレンダリングや取得にはJavaScriptの実行が必要です。JavaScriptを実行できるのはブラウザだけなので、動的コンテンツをスクレイピングするための選択肢は、一般的にPlaywright、Selenium、Puppeteerのようなブラウザ自動化ツールに限られる。
これらのツールは、実際のブラウザをプログラムで制御できるAPIを公開している。その結果、ダイナミックコンテンツのウェブスクレイピングには、以下の3つのステップが必要となる:
- ブラウザに目的のページに移動するよう指示する。
- 特定の動的コンテンツがページに表示されるのを待つ。
- 彼らが提供するノード選択とデータ抽出APIを使用して、そのコンテンツを選択し、抽出する。
より詳しいガイダンスについては、Pythonで動的なウェブサイトをスクレイピングする方法の記事を読んでください。
動的コンテンツ・スクレイピングの課題
動的コンテンツのスクレイピングは、静的コンテンツのスクレイピングよりも本質的にずっと難しい。まず、コンテンツにアクセスするために必要な全てのアクションを再現するために、コード内でユーザーのインタラクションをシミュレートする必要があるかもしれないからだ。これは、複雑なナビゲーションを持つサイトを扱う際に問題となる。
第二に、動的なウェブページには、CAPTCHA、JavaScriptチャレンジ、ブラウザフィンガープリントなどの高度なスクレイピング対策やボット対策が実装されていることが多いからだ。
また、ブラウザ自動化ツールは、ブラウザを制御するためにブラウザをインストルメンテーションする必要があることを覚えておいてください。ブラウザの設定を変更するだけで、高度なアンチボットシステムにボットとして検知される可能性があります。これは、リソースを節約するためにヘッドレスモードでブラウザを制御する場合に特に当てはまります。
これらの問題に対するオープンソースの回避策は、SeleniumBase、Undetected ChromeDriver、Playwright Stealth、またはPuppeteer Stealthのような、ボット回避防止機能が組み込まれたブラウザ自動化ライブラリを使用することである。
しかし、これらのソリューションは氷山の一角にしか対応しておらず、IP禁止、IPレピュテーションの問題など、静的コンテンツスクレイピングで浮き彫りにされたすべての問題の影響を受けます。最も効果的なアプローチは、Bright DataのScraping Browserのようなソリューションを使用することです:
- Puppeteer、Playwright、Selenium、その他のブラウザ自動化ツールとの統合
- クラウド上で動作し、無限に拡張可能
- 1億5,000万以上のIPからなるプロキシネットワークで動作
- ヘッドレス検出を避けるため、ヘッドフルモードで動作
- CAPTCHA解決機能内蔵
- 一流のアンチボット・バイパス機能を搭載
ウェブスクレイピングのための静的コンテンツと動的コンテンツ:比較表
これは、ウェブスクレイピングにおける静的コンテンツと動的コンテンツの比較表である:
| アスペクト | 静的コンテンツ | ダイナミック・コンテンツ |
|---|---|---|
| 定義 | サーバーからの最初のHTMLレスポンスに直接埋め込まれたコンテンツ | ページがロードされた後にJavaScriptによってロードまたはレンダリングされたコンテンツ |
| HTMLの可視性 | サーバーから返された生のHTMLドキュメントに表示される。 | 最初のHTML文書では表示されない |
| レンダリング場所 | サーバー側レンダリング | クライアント側レンダリング |
| 検出方法 | – ページソースを見る」オプション – HTTPクライアントでHTMLを検査する |
– ソースHTMLとレンダリングされたDOMの違いをチェックする – DevToolsの “Network “タブを調べる |
| 一般的な使用例 | – SEO重視のコンテンツ – シンプルな情報リスト |
– ライブアップデート – ユーザー別ダッシュボード – SPAコンテンツ |
| スクレイピングの難易度 | 簡単 | ミディアムからハードまで |
| スクレイピング・アプローチ | HTTPクライアント + HTMLパーサー | ブラウザ自動化ツール |
| パフォーマンス | JSレンダリングが不要で高速。 | ブラウザでページをレンダリングし、要素の読み込みを待つため、時間がかかる。 |
| スクレイピングの主な課題 | – TLSフィンガープリンティング – レート制限 – IP禁止 |
– キャプチャ – 複雑なナビゲーション/インタラクションフロー – JSの課題 |
| ブロックを避けるための推奨ツール | プロキシ, ウェブアンロッカー | スクレイピング・ブラウザ |
| スタック例 | リクエスト+美しいスープ | Playwright、Selenium、またはPuppeteer |
両方のシナリオをカバーする特定のプログラミング言語のスクレイピングツールのリストについては、以下のガイドをご覧ください:
- 最高のJavaScriptウェブスクレイピング・ライブラリ
- 最高のPythonウェブスクレイピング・ライブラリ
- PHP ウェブスクレイピング・ライブラリ トップ7
- トップ7 C#ウェブスクレイピング・ライブラリ
結論
この記事では、ウェブスクレイピングに焦点を当てて、ウェブページ上の静的コンテンツと動的コンテンツの違いを理解しました。この2つのタイプのコンテンツが何であるか、どのように違うか、そしてウェブデータを解析するときに両方をどのように扱うかを学びました。
静的コンテンツ、動的コンテンツに関わらず、スクレイピング対策やボット対策が複雑になることがあります。そこでBright Dataは、スクレイピングのあらゆるニーズに対応する包括的なツール群を提供します:
- プロキシサービス:地理的制限を回避するための数種類のプロキシは、150M以上のIPを備えています[1]。
- スクレイピング・ブラウザ:ロック解除機能を内蔵したPlayright、Selenium、Puppeter互換ブラウザ。
- ウェブスクレーパーAPI:100以上の主要ドメインから構造化データを抽出するための設定済みAPI。
- ウェブアンロッカー:ボット対策が施されたサイトのロック解除を行うオールインワンAPI。
- SERP API:検索エンジンの結果をアンロックし、すべての主要検索エンジンから完全なSERPデータを抽出する特別なAPI[2]。
Bright Dataのアカウントを作成し、無料トライアルでスクレイピング製品をお試しください!





