

この記事では、以下の事項を説明します。
- フロントエンドJavaScriptを使ったウェブスクレイピング
- 前提条件
- Node.js用ウェブスクレイピングライブラリ
- まとめ
フロントエンドJavaScriptを使ったウェブスクレイピング
ウェブスクレイピングに関しては、フロントエンドJavaScriptは限定的なソリューションです。まず、ブラウザのコンソールからJavaScriptのウェブスクレイピングスクリプトを直接実行する必要があるためです。これはプログラムで実行できる操作ではありません。
具体的には、コンソールからページ内のデータを以下のようにスクレイピングできます。

次に、他のウェブページからデータをスクレイピングしたい場合は、AJAXを使ってダウンロードする必要があります。しかし、ウェブブラウザはAJAXに対して同一オリジンポリシーを適用することを忘れてはなりません。つまり、フロントエンドJavaScriptでは、同じオリジン内のウェブページにしかアクセスできません。
これが何を意味するか、簡単な例で理解しましょう。brightdata.comのページを閲覧していると仮定しましょう。この場合、フロントエンドJavaScriptのウェブスクレイピングスクリプトは、brightdata.comドメイン内のウェブページのみをダウンロードできます。
ただし、これはJavaScriptがウェブクローリングに適した技術でないことを意味するものではありません。実際には、Node.jsを使うことでサーバー上でJavaScriptを実行し、上記の2つの制約を回避できます。
それでは、Node.jsを使ってJavaScriptウェブスクレイパーを構築する方法を見ていきましょう。
前提条件
Node.jsのウェブスクレイピングアプリを作成する前に、以下の前提条件を満たす必要があります。
- Node.js 18+およびnpm 8+:npmを含む、Node.js 18+のLTS(Long Term Support)バージョンであれば問題ありません。このチュートリアルでは、執筆時点で最新のNode.js LTSバージョンであるNode.js 18.12とnpm 8.19に基づいています。
- JavaScriptをサポートするIDE:このチュートリアルでは、IntelliJ IDEA Community EditioniをIDEとして選択しましたが、JavaScriptおよびNode.jsをサポートする他のIDEでも問題ありません。
上記のリンクをクリックし、インストールウィザードに従って、必要なものをすべてセットアップしてください。ターミナルで以下のコマンドを実行することで、Node.jsが正しくインストールされたことを確認できます。
node -vこれにより、以下が返されます。
v18.12.1同様に、npmが正しくインストールされたことを、次のように確認します
npm -v これにより、以下の文字列が返されます。
8.19.2上記の2つのコマンドは、それぞれ、マシンでグローバルに利用可能なNode.jsとnpmのバージョンを示しています。
素晴しいです!これで、Node.jsでJavaScriptウェブスクレイピングを行う方法を学ぶ準備ができました!
Node.jsに最適なJavaScriptウェブスクレイピングライブラリ
Node.jsでウェブスクレイピングを行うのに最適なJavaScriptライブラリを見ていきましょう。
- Axios:JavaScriptでHTTPリクエストを行うのに適した、使い勝手の良いライブラリ。Axiosは、ブラウザとNode.jsの両方で使用できる、最も人気のあるJavaScript HTTPクライアントの1つです。
- Cheerio:HTMLやXMLドキュメントを探索するためのjQueryライクなAPIを提供する軽量ライブラリ。Cheerioを使ってHTMLドキュメントを解析し、HTML要素を選択し、それらからデータを抽出できます。つまり、Cheerioは高度なウェブスクレイピングAPIを提供しています。
- Selenium:ウェブアプリケーションの自動テストを構築するために使用できる、複数のプログラミング言語をサポートするライブラリ。また、ウェブスクレイピング目的でヘッドレスブラウザ機能を利用することもできます。
- Playwright:Microsoftが開発したウェブアプリケーション用の自動テストスクリプトを作成するツール。ブラウザに特定の動作を実行するよう指示する方法を提供します。そのため、Playwrightをヘッドレスブラウザのソリューションとして、ウェブスクレイピングに使用できます。
- Puppeteer:Googleが開発したウェブアプリケーションのテストを自動化するためのツール。Puppeteerは、Chrome DevToolsプロトコルの上に構築されています。SeleniumやPlaywrightと同様に、人間のユーザーが行うようにブラウザとプログラムでやり取りできます。SeleniumとPuppeteerの違いについて、詳しくはこちらをご覧ください。
Node.jsでJavaScriptウェブスクレイパーを構築する
ここでは、ウェブサイトから自動的にデータを抽出できるJavaScriptウェブスクレイパーをNode.jsで構築する方法を学びます。具体的には、Bright Dataのホームページをターゲットのウェブページとします。Node.jsウェブスクレイピングプロセスの目的は、ページから関心のあるHTML要素を選択し、そこからデータを取得し、スクレイピングされたデータをより有用な形式に変換することです。
執筆時点では、Bright Dataのトップページは以下のようになっています。

このように、Bright Dataのホームページには、テキストの説明から画像まで、さまざまな形式のデータや情報がたくさん含まれています。また、多くの有用なリンクが含まれています。これらのデータをすべて取得する方法を学びます。
それでは、ステップバイステップのチュートリアルで、Node.jsを使ってデータをスクレイピングする方法を見ていきましょう!
ステップ1:Node.jsプロジェクトをセットアップする
まず、以下のコマンドでNode.jsウェブスクレイピングプロジェクトを格納するフォルダを作成します。
mkdir web-scraper-nodejsこれで、空のweb-scraper-nodejsディレクトリができました。なお、プロジェクトフォルダには好きな名前を付けることができます。以下のコマンドでフォルダ内に移動します。
cd web-scraper-nodejs次に、以下のコマンドでnpmプロジェクトを初期化します。
npm init -yこのコマンドで新しいnpmプロジェクトがセットアップされます。なお、-yフラグは、npmが対話的なプロセスを経ずにデフォルトのプロジェクトを初期化するために必要です。-yフラグを省略すると、ターミナルにいくつかの質問が表示されます。
web-scraper-nodejsには、次のようなpackage.jsonが含まれているはずです。
{
"name": "web-scraper-nodejs",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo "Error: no test specified" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}次に、プロジェクトのルートフォルダにindex.jsファイルを作成し、以下のように初期化します。
// index.js
console.log("Hello, World!")このJavaScriptファイルには、Node.jsウェブスクレイピングロジックが含まれます。
package.jsonファイルを開き、scriptsセクションに以下のスクリプトを追加します。
"start": "node index.js"これで、ターミナルで以下のコマンドを実行して、Node.jsスクリプトを起動できます。
npm run start以下が返されるはずです。
Hello, World!これは、Node.jsアプリが正しく動作していることを意味します。IDEでプロジェクトを開き、Node.jsでスクレイピングロジックを書く準備をしましょう!
IntelliJ IDEAのユーザーであれば、以下のように表示されるはずです。

ステップ2:AxiosとCheerioのインストール
Node.jsでウェブスクレイパーを実装するために必要な依存関係をインストールする時が来ました。どのJavaScriptウェブスクレイピングライブラリを採用すべきかを判断するには、対象となるウェブページにアクセスし、空白のセクションを右クリックして「検査」オプションを選択します。これでブラウザのDevToolsウィンドウが開くはずです。「ネットワーク」タブの「Fetch/XHR」セクションを確認します。

上記は、対象のウェブページにより実行されるAJAXリクエストを示しています。ウェブサイトにより実行される3つのXHRリクエストを開くと、それらは興味深いデータを返さないことがわかります。言い換えれば、欲しいデータはウェブページのソースコードに直接埋め込まれています。これは、サーバーサイドでレンダリングされるウェブサイトで通常起こることです。
ターゲットのウェブページは、データの取得やレンダリングをするのにJavaScriptに依存していません。したがって、ブラウザ上でJavaScriptを実行するツールは必要ありません。つまり、ヘッドレスブラウザのライブラリを使って、ターゲットのウェブページからデータを抽出する必要はないのです。そのようなライブラリを使用することは可能ですが、必須ではありません。
ヘッドレスブラウザ機能を提供するライブラリは、ブラウザでウェブページを開くため、オーバーヘッドが発生します。これは、ブラウザが重いアプリケーションであるためです。AxiosとCheerioを選択することで、このオーバーヘッドを簡単に回避できます。
そのため、cheerioとaxiosを以下のコマンドでインストールします。
npm install cheerio axios次に、index.jsに以下の2行のコードを追加して、cheerioとaxiosをインポートします。
// index.js
const cheerio = require("cheerio")
const axios = require("axios")それでは、CheerioとAxiosを使用してウェブスクレイピングを行うNode.jsウェブスクレイピングスクリプトを作成しましょう!
ステップ3:ターゲットのウェブサイトをダウンロードする
以下のコード行を使用し、Axiosでターゲットのウェブサイトに接続します。
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com",
})Axios request()メソッドのおかげで、任意のHTTPリクエストを実行できます。具体的には、あるウェブページのソースコードをダウンロードしたい場合、そのURLに対してHTTP GETリクエストを実行する必要があります。通常、AxiosはすぐにPromiseを返します。awaitキーワードを使うと、Promiseを待ち、その値を同期的に取得できます。
なお、request()が失敗すると、Errorがスローされます。これは、無効なURLやサーバーが一時的に使用できないなど、いくつかの理由で発生する可能性があります。また、ウェブサイトによってはウェブスクレイピング対策を実施していることも忘れてはなりません。最も一般的なものは、有効なUser-Agent HTTPヘッダーを持たないリクエストをブロックするというものです。ウェブスクレイピングのためのUser-Agentについては、こちらをご覧ください。
デフォルトでは、Axiosは以下のUser-Agentを使用します。
axios <axios_version>これは、ブラウザが使用するUser-Agentのようには見えません。そのため、アンチスクレイピング技術により、Node.jsのウェブスクレイパーが検出およびブロックされてしまう可能性があります。
Axiosで有効なUser-Agentヘッダーを設定するには、request()に渡されるオブジェクトに以下の属性を追加します。
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}headers属性を使用すると、Axiosで任意のHTTPヘッダーを設定できます。
これで、index.jsファイルは以下のようになるはずです。
// index.js
const cheerio = require("cheerio")
const axios = require("axios")
async function performScraping() {
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
})
}
performScraping()awaitは、asyncのマークの付いた関数内でのみ使用できることに留意してください。このため、JavaScriptウェブスクレイピングロジックをasync performScraping()関数に埋め込む必要があります。
それでは、ウェブスクレイピング戦略を定義するために、対象のウェブページを分析していきましょう。
ステップ4:HTMLページを検査する
Bright Dataのホームページを見ると、Bright Dataを活用できる業種が一覧表示されています。これはスクレイピングするのに興味深いデータです。
これらのHTML要素の1つを右クリックして、「検査」を選択します。
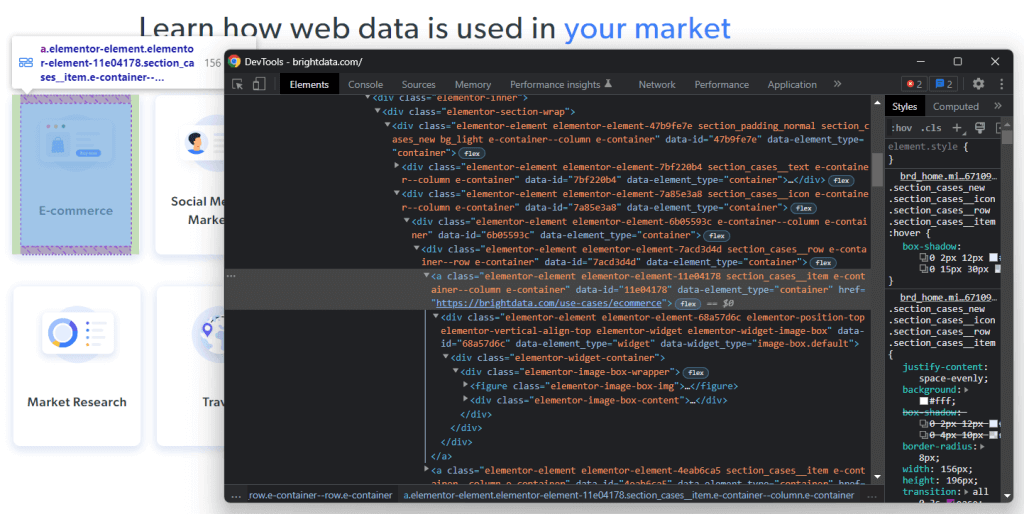
選択したノードのHTMLコードを分析すると、カードが<a> HTML要素であることがわかります。具体的には、この<a>には以下が含まれます。
- industryフィールドに関連する画像を含む
<figure>HTML要素 - industryフィールドの名前を含む
<div>HTML要素
これで、これらのHTML要素を特徴付けるCSSクラスに注目してください。それらを使って、DOMからこれらのHTML要素を選択するために必要なCSSセレクタを定義できます。具体的には、.e-containerカードが.elementor-element-7a85e3a8 <div>に含まれていることに留意してください。そして、カードが指定されれば、以下のCSSセレクタを使って、その関連データをすべて抽出できます。
.elementor-image-box-img img.elementor-image-box-content .elementor-image-box-title
同様に、同じロジックを適用して、以下を実行するのに必要なCSSセレクタを定義できます。
- Bright Dataが業界のリーダーである理由を抽出します。
- Bright Dataが市場で最高のカスタマーエクスペリエンスを提供する理由を選択します。
言い換えれば、対象のウェブページには、3つのスクレイピング目標があります。
- Bright Dataを活用できる業界に関するデータ。
- Bright Dataが業界のリーダーである理由に関するデータ。
- Bright Dataが業界で最高のカスタマーエクスペリエンスを提供する理由に関するデータ。
ステップ5:CheerioでHTML要素を選択する
Cheerioは、ウェブページからHTML要素を選択する方法をいくつか用意しています。しかし、まず次のようにCheerioを初期化する必要があります。
// parsing the HTML source of the target web page with Cheerio
const $ = cheerio.load(axiosResponse.data)Cheerioのload()メソッドは、文字列形式のHTMLコンテンツを受け入れます。Axiosレスポンスオブジェクトは、HTTPリクエストで返されたデータをdata属性内に含むことに留意してください。この場合、dataはサーバーから返されたウェブページのHTMLソースコードを格納します。そのため、axiosResponse.dataをload()に渡してCheerioを初期化します。
Cheerio変数を$を呼ぶべきです。なぜなら、Cheerioは基本的にjQueryと同じ構文を共有しているからです。これにより、インターネットからjQueryのスニペットをコピーできるようになります。
CheerioでHTML要素を選択するには、そのクラスを使用します。
const htmlElement = $(".elementClass")同様に、IDでHTML要素を取得できます。
const htmlElement = $("#elementId")具体的には、jQueryで行うように、$に任意の有効なCSSセレクタを渡すことで、HTML要素を選択できます。また、find()メソッドで選択ロジックを連結することもできます。
// retrieving the list of industry cards
const industryCards = $(".elementor-element-7a85e3a8").find(".e-container")find()は、現在のHTML要素の子孫をCSSセレクタでフィルタリングしてアクセスできます。そして、以下のようにeach()メソッドを使って、Cheerioノードのリストを反復処理できます。
// iterating over the list of industry cards
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// scraping logic...
})では、注目のHTML要素からデータを抽出するためにCheerioをどのように使用するかを学びましょう。
ステップ6:Cheerioを使って対象のウェブページからデータをスクレイピングする
先に示したロジックを発展させて、以下のようにして、選択したHTML要素から目的のデータを抽出できます。
// initializing the data structure
// that will contain the scraped data
const industries = []
// scraping the "Learn how web data is used in your market" section
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// extracting the data of interest
const pageUrl = $(element).attr("href")
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const name = $(element).find(".elementor-image-box-content .elementor-image-box-title").text()
// filtering out not interesting data
if (name && pageUrl) {
// converting the data extracted into a more
// readable object
const industry = {
url: pageUrl,
image: image,
name: name
}
// adding the object containing the scraped data
// to the industries array
industries.push(industry)
}
})このウェブスクレイピングNode.jsスニペットは、Bright Dataのホームページからすべての業界カードを選択します。次に、すべてのHTMLカード要素を反復処理します。各カードについて、カードに関連するウェブページのURL、画像、業界名をスクレイピングします。Cheerioのattr()およびtext()メソッドを使用して、HTMLの属性値とテキストをそれぞれ取得することができます。最後に、スクレイピングされたデータをオブジェクトに格納し、industries配列に追加します。
each()ループの最後に、industriesは最初のスクレイピング目標に関連するすべての興味深いデータを含みます。では、残りの2つの目標もどのように達成するか見てみましょう。
同様に、Bright Dataが業界のリーダーである理由を裏付けるデータを、以下のようにスクレイピングできます。
const marketLeaderReasons = []
// scraping the "What makes Bright Data
// the undisputed industry leader" section
$(".elementor-element-ef3e47e")
.find(".elementor-widget")
.each((index, element) => {
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const title = $(element).find(".elementor-image-box-title").text()
const description = $(element).find(".elementor-image-box-description").text()
const marketLeaderReason = {
title: title,
image: image,
description: description,
}
marketLeaderReasons.push(marketLeaderReason)
})最後に、Bright Dataが素晴らしい顧客体験を提供できる理由に関するデータを、以下のようにスクレイピングできます。
const customerExperienceReasons = []
// scraping the "The best customer experience in the industry" section
$(".elementor-element-288b23cd .elementor-text-editor")
.find("li")
.each((index, element) => {
const title = $(element).find("strong").text()
// since the title is part of the text, you have
// to remove it to get only the description
const description = $(element).text().replace(title, "").trim()
const customerExperienceReason = {
title: title,
description: description,
}
customerExperienceReasons.push(customerExperienceReason)
})おめでとうございます!Node.jsのウェブスクレイピングの3つの目標をすべて達成する方法を学ぶことができました!
現在のページで発見したリンクをたどることで、他のウェブページからデータをスクレイピングできることに留意してください。これが、ウェブクローリングというものです。このようにして、それらのページからデータを抽出するためのウェブスクレイピングロジックを定義できます。
industries、marketLeaderReasons、customerExperienceReasonsは、スクレイピングしたデータをすべてJavaScriptオブジェクトに格納します。それをより便利な形式に変換する方法を学びましょう。
ステップ7:抽出したデータをJSONに変換する
JSONは、JavaScriptに関して最も優れたデータ形式の1つです。これは、JSONがJavaScriptから派生し、APIがデータを受け取ったり返したりする際に一般的に使用される形式だからです。そのため、JavaScriptのスクレイピングデータをJSONに変換することが必要な場合があります。以下のロジックでこれを簡単に達成できます。
// trasforming the scraped data into a general object
const scrapedData = {
industries: industries,
marketLeader: marketLeaderReasons,
customerExperience: customerExperienceReasons,
}
// converting the scraped data object to JSON
const scrapedDataJSON = JSON.stringify(scrapedData)まず、すべてのスクレイピングデータを含むJavaScriptオブジェクトを作成する必要があります。次に、JSON.stringify()を使って、そのJavaScriptオブジェクトをJSONに変換できます。
scrapedDataJSONには、以下のJSONデータが含まれます。
{
"industries": [
{
"url": "https://brightdata.com/use-cases/ecommerce",
"image": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"name": "E-commerce"
},
// ...
{
"url": "https://brightdata.com/use-cases/data-for-good",
"image": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"name": "Data for Good"
}
],
"marketLeader": [
{
"title": "Most reliable",
"image": "https://brightdata.com/wp-content/uploads/2022/01/reliable.svg",
"description": "Highest quality data, best network uptime, fastest output "
},
// ...
{
"title": "Most efficient",
"image": "https://brightdata.com/wp-content/uploads/2022/01/efficient.svg",
"description": "Minimum in-house resources needed"
}
],
"customerExperience": [
{
"title": "You ask, we develop",
"description": "New feature releases every day"
},
// ...
{
"title": "Tailored solutions",
"description": "To meet your data collection goals"
}
]
}おめでとうございます!ウェブサイトに接続するところから始めて、そのデータをスクレイピングし、JSONに変換することができました。これで、完成したウェブスクレイピングNode.jsスクリプトを見る準備が整いました。
すべてを統合する
Node.jsのウェブスクレイパーは次のようになります。
// index.js
const cheerio = require("cheerio")
const axios = require("axios")
async function performScraping() {
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com/",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
})
// parsing the HTML source of the target web page with Cheerio
const $ = cheerio.load(axiosResponse.data)
// initializing the data structures
// that will contain the scraped data
const industries = []
const marketLeaderReasons = []
const customerExperienceReasons = []
// scraping the "Learn how web data is used in your market" section
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// extracting the data of interest
const pageUrl = $(element).attr("href")
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const name = $(element).find(".elementor-image-box-content .elementor-image-box-title").text()
// filtering out not interesting data
if (name && pageUrl) {
// converting the data extracted into a more
// readable object
const industry = {
url: pageUrl,
image: image,
name: name
}
// adding the object containing the scraped data
// to the industries array
industries.push(industry)
}
})
// scraping the "What makes Bright Data
// the undisputed industry leader" section
$(".elementor-element-ef3e47e")
.find(".elementor-widget")
.each((index, element) => {
// extracting the data of interest
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const title = $(element).find(".elementor-image-box-title").text()
const description = $(element).find(".elementor-image-box-description").text()
// converting the data extracted into a more
// readable object
const marketLeaderReason = {
title: title,
image: image,
description: description,
}
// adding the object containing the scraped data
// to the marketLeaderReasons array
marketLeaderReasons.push(marketLeaderReason)
})
// scraping the "The best customer experience in the industry" section
$(".elementor-element-288b23cd .elementor-text-editor")
.find("li")
.each((index, element) => {
// extracting the data of interest
const title = $(element).find("strong").text()
// since the title is part of the text, you have
// to remove it to get only the description
const description = $(element).text().replace(title, "").trim()
// converting the data extracted into a more
// readable object
const customerExperienceReason = {
title: title,
description: description,
}
// adding the object containing the scraped data
// to the customerExperienceReasons array
customerExperienceReasons.push(customerExperienceReason)
})
// trasforming the scraped data into a general object
const scrapedData = {
industries: industries,
marketLeader: marketLeaderReasons,
customerExperience: customerExperienceReasons,
}
// converting the scraped data object to JSON
const scrapedDataJSON = JSON.stringify(scrapedData)
// storing scrapedDataJSON in a database via an API call...
}
performScraping()ここで示されているように、Node.jsでは100行未満のコードでウェブスクレイパーを構築できます。CheerioとAxiosを使って、HTMLウェブページをダウンロードし、それを解析して、すべてのデータを自動的に取得できます。その後、スクレイピングしたデータを簡単にJSONに変換できます。これがNode.jsによるウェブスクレイピングです。
次のようにして、Node.jsでウェブスクレイパーを起動します。
npm run startはい、できました!これで、Node.jsでJavaScriptウェブスクレイピングを行う方法を学ぶことができました!
まとめ
このチュートリアルでは、JavaScriptを使ったフロントエンドでのウェブスクレイピングが限定的なソリューションであり、Node.jsがより良い選択肢である理由を説明しました。また、Node.jsのウェブスクレイピングスクリプトを作成するために必要なものや、JavaScriptでウェブからデータをスクレイピングする方法も見てきました。具体的には、CheerioとAxiosを使用して、実際の例に基づいたNode.jsのJavaScriptウェブスクレイピングアプリケーションを作成する方法を学びました。Node.jsでウェブスクレイピングを行うには、数行のコードで済むことがおわかりいただけたと思います。
とはいえ、ウェブスクレイピングは必ずしも簡単ではないことを心に留めておいてください。というのも、対処しなければならないさまざまな課題があるためです。具体的には、スクレイピング対策やボット対策が一般的になってきていることが挙げられます。幸いなことに、Bright Dataが提供する次世代型の高度なウェブスクレイピングツールを使えば、これらの問題を簡単に回避できます。ウェブスクレイピングに取り組みたくありませんか?当社のデータセットをご確認ください。
ブロックを回避する方法について詳しくお知りになりたい場合は、Bright Dataで利用可能な複数のプロキシサービスの中からウェブプロキシを採用するか、高度なWeb Unlockerの使用を開始してください。
どの製品を選べばいいかわからないですか?営業部に連絡して、あなたに合ったウェブスクレイピングの解決策を見つけましょう




