この記事では、以下の事項を詳述します。
- Excel のウェブクエリツールを使用して「テーブル データ」を収集する
- Excelを使用したウェブデータ分析
- Excel でデータを出力する自動データ収集ツール
Excel のウェブクエリツールを使用して「テーブル データ」を収集する
たとえば、Excel でデータを収集するのは、Python でスクレイピングするよりもずっとシンプルです。今回取り上げる方法は、行と列で構成されているウェブデータ(テーブル)をターゲティングしている場合に最適です。
ここでは、ターゲットのウェブデータを収集し、Excel ワークブックに直接インポートして、ソート、フィルタリング、分析を開始するための具体的な手順を紹介します。
ステップ1:新規ワークブックを開く
データポイントは、空のワークスペースにインポートする必要があるため、Excel で完全に新しいワークブックファイルを開くか、既存のファイルの下部にある [シート] タブに新しい「ワークシート」を追加します。
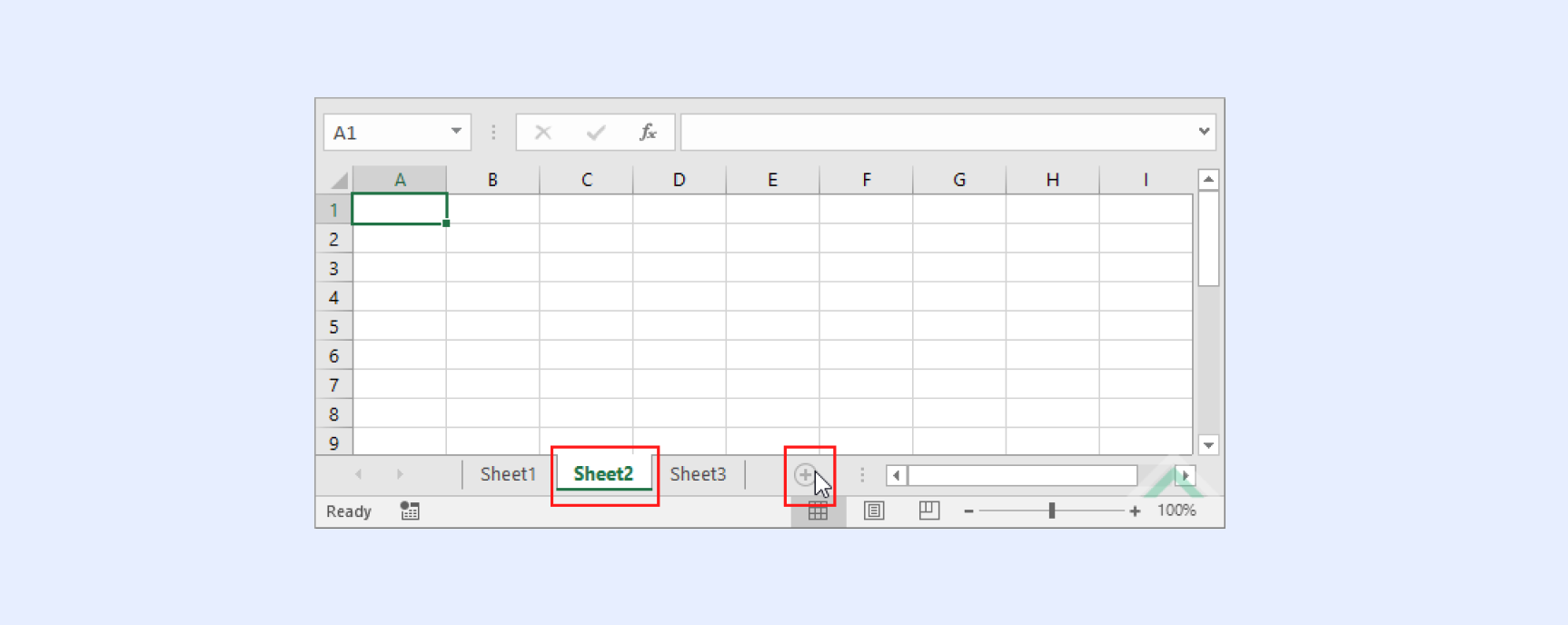
ステップ2:ウェブデータクエリーを実行する
Microsoft Excel のワークシートの上部にある [データ] タブで、左側の [データの取得] ボタンを押し、[他のソースから] をクリックして、最後に [Web から] をクリックすると、新しいウェブベースのクエリーを実行できます。

ステップ3:ターゲット URL を追加する
新しいウェブクエリーダイアログが開きます。収集したいテーブルの中に、ターゲットデータを含むターゲット URL を挿入します。次に [インポート] をクリックします。
重要な注記:Excel は、ターゲット URL に表示されるテーブルを自動的に識別します。ウェブサイトやダイアログボックスのさまざまなテーブルの横に、小さな黄色い矢印が表示されます。データを収集したいテーブルの横にある矢印をクリックすると、緑色のチェックマークに変わります。対象のテーブルすべてについてこの作業を終えたら、[インポート] をクリックします。

ステップ4:データのインポート先を決定する
Excel に、[データのインポート] ダイアログボックスと呼ばれる一連のダイアログボックスの中で次のものが表示されます。ここで、新しく開いて保存したワークシートを [既存のワークシート] オプションで選択するか、まったく [新しいワークシート] を開くことを選択して、[OK] をクリックします。

ステップ5:Excel がターゲットデータをインポートするのを待つ
ターゲットサイトや、収集およびインポートするデータポイントの数にもよりますが、数秒から数分程度で完了します。

Excelを使用したウェブデータ分析
これで、データの操作を開始して、データから有用なインサイトを抽出できます。たとえば、Excel ネイティブの「ピボット」と「回帰」モデルを使用してターゲットデータを分析できます。
ピボットを使用すると、データ分析の実行、データモデルの作成、データセットの相互参照を行い、収集した情報から有用なインサイトを導き出すことができます。また、データセットやインサイトを円グラフや棒グラフで表示することができるため、データの傾向をより簡単に同僚に伝えることができます。

ピボット機能を使ったデータセットの分析については、詳細なHubspot チュートリアルをご覧ください。
回帰分析により、さまざまな入力と出力の関係を把握できます。たとえば、アイテムのコストと、広告費とコンバージョン率との相関関係があります。これにより、どの広告チャネルが最も収益性が高いか(つまり、マーケティング予算を集中させる価値があるか)などの戦略的意思決定を行うことができます。

Excel でデータを出力する自動データ収集ツール
世界中に広がる匿名プロキシとプロキシ IP ロケーションは、データ収集を行う際に有用ですが、ビジネスのデータ収集操作を完全に自動化することには大きなメリットがあります。
Web Scraper IDE は、データスクレイピングの自動化を目的とした業界をリードするツールです。情報収集が必要な専門家は、Web Scraper IDEを使用して、目的のウェブサイトを容易に選択できます。情報の配置や構成にかかわらず、ユーザーが望む形式でデータを取得することが可能です。その形式には以下が含まれます:
- JSON
- CSV
- HTML
- Microsoft Excel
上記で述べたExcelの強力なデータ分析ツールを利用したい方にとって、ボタンをクリックするだけで直接 Excel スプレッドシートにデータを出力できることは非常に便利です。これは1つのウェブサイトに対しても、1,000サイトに対しても設定可能で、Web Scraper IDE はビジネスのニーズに基づいて操作を拡大または縮小できます。また、必要に応じてデータポイントを頻繁にも稀にも収集するようにプログラムすることができます(毎時?毎日?毎週?毎月?毎年?)。
ターゲットデータをチームの Microsoft Excel ワークブックに直接配信する準備はできていますか?