

TL;DR: このチュートリアルでは、C++ で Web サイトからデータを抽出する方法と、C++ がスクレイピングに最も効率的な言語の 1 つである理由を説明します。
このガイドでは、次の内容について説明します。
- C++ は Web スクレイピングに適した言語か
- 最もお勧めの C++ Web スクレイピングライブラリ
- C++ で Web スクレイパーをビルドする方法
C++ は Web スクレイピングに適した言語か
C++ は、高性能アプリケーションの開発に広く使用されている静的型付けプログラミング言語です。その理由は、C++ が速度、効率、メモリ管理機能において高く評価されているためです。C++ は汎用性の高い言語で、Web スクレイピングを含む幅広い用途に便利です。
C++ はコンパイラ言語であり、本質的に Python などのインタプリタ言語よりも高速です。そのため、高速スクレーパーのビルドに最適です。しかし、C++ は Web 開発用に設計されておらず、Web スクレイピングに利用できるライブラリは多くありません。サードパーティ製のパッケージもいくつかありますが、Python、Ruby、Java ほど選択肢は多くありません。
要するに、C++ での Web スクレイピングは可能で効率的ではあるものの、他の言語に比べて多少のプログラミングが必要になります。そこで、どのようなツールを使えばこのプロセスが簡単になるか、見ていきましょう!
最もお勧めの C++ Web スクレイピングライブラリ
C++ 用の一般的な Web スクレイピングライブラリは、次のとおりです。
- CPR: Python Requests プロジェクトに触発された最新の C++ HTTP クライアントライブラリです。これは libcurl のラッパーであり、わかりやすいインターフェイスと組み込みの認証機能を提供し、非同期呼び出しをサポートしています。
- libxml2: もともと Gnome 用に開発された、XML および HTML ドキュメントを解析するための、強力で完全な機能が揃ったライブラリです。XPath セレクターによる DOM 操作をサポートしています。
- Lexbor: 完全に C で記述された、CSS セレクターをサポートする高速かつ軽量な HTML 解析ライブラリです。Linux でのみ利用可能です。
何年もの間、C++ で最も広く使われていた HTML パーサーは Gumbo でした。このパーサーは 2016 年からメンテナンスされておらず、公式の README でも使用しないよう勧告されています。
前提条件
コーディングを始める前に、次の作業が必要になります。
- C++ コンパイラのインストール
vcpkgC++ パッケージマネージャーのセットアップ- CMake のインストール
これらの前提条件を満たすには、以下の中からご使用のオペレーティングシステムに対応するガイドに従ってください。
macOS での C++ のセットアップ
macOS で最も一般的な C、C++、Objective-C コンパイラは、Clang です。多くの Mac には Clang がプリインストールされています。確認するには、ターミナルを開いて以下のコマンドを実行します。
clang --version
Command not found: clang エラーが発生する場合は、Clang がインストールされていないか、正しく構成されていないことを意味します。その場合、Xcode コマンドラインツールを使ってインストールできます。
xcode-select --install
これには時間がかかる場合があるので、しばらくお待ちください。
vcpkg をセットアップするには、まず macOS 開発者ツールが必要です。以下のコマンドで Mac に追加します。
xcode-select --install
次に、vcpkg をグローバルにインストールする必要があります。/dev フォルダを作成し、ターミナルに入力して、実行します。
git clone https://github.com/microsoft/vcpkg
これでディレクトリにソースコードが含まれます。次のコマンドでパッケージマネージャーをビルドします。
./vcpkg/bootstrap-vcpkg.sh
このコマンドを実行するには、上位の権限が必要な場合があります。
最後に、このガイドに従って /dev/vcpkg を $PATH に追加します。
CMake をインストールするには、公式サイトからインストーラーをダウンロードして起動し、インストールウィザードに従います。
Windows での C++ のセットアップ
MinGW-x64 インストーラーを MSYS2 からダウンロードして起動し、指示に従います。このパッケージは、GCC、Mingw-w64、その他の便利な C++ ツールとライブラリの最新のネイティブビルドを提供します。
インストールプロセスの最後に開く MSYS2 ターミナルで、以下のコマンドを実行して MinGW-w64 ツールチェーンをインストールします。
pacman -S --needed base-devel mingw-w64-x86_64-toolchain
プロセスが終了するのを待ってから、こちらの説明に従って、MinGW を PATH env に追加します。
次に、vcpkg をグローバルにインストールする必要があります。C:/dev フォルダを作成し、PowerShell で開いて実行します。
git clone https://github.com/microsoft/vcpkg
vcpkg サブフォルダに含まれているパッケージマネージャーのソースコードを次のコマンドでビルドします。
./vcpkg/bootstrap-vcpkg.bat
次に、前回と同じように C:/dev/vcpkg を PATH に追加します。
あとは CMake のインストールだけです。インストーラーをダウンロードしてダブルクリックし、セットアップ中に以下のオプションを確認します。

Linux での C++ のセットアップ
Debian ベースのディストリビューションでは、GCC (GNU コンパイラコレクション)、CMake、その他の開発に役立つパッケージを次のコマンドでインストールします。
sudo apt install build-essential cmake
これには時間がかかる場合があるので、しばらくお待ちください。
次に、vcpkg をグローバルにインストールする必要があります。/dev ディレクトリを作成してターミナルで開き、次のように入力します。
git clone https://github.com/microsoft/vcpkg
これで vcpkg サブディレクトリにパッケージマネージャーのソースコードが含まれます。次のコマンドでツールをビルドします。
./vcpkg/bootstrap-vcpkg.sh
このコマンドには管理者権限が必要な場合があります。
次に、このガイドに従って、/dev/vcpkg を $PATH 環境変数に追加します。
完璧です!これで、C++ で Webスクレイピングを始めるために必要なものがすべて揃いました!
C++ で Web スクレイパーをビルドする方法
この章では、C++ Web スパイダーのコーディング方法を解説します。ターゲットサイトは Bright Data のホームページで、スクリプトは次の処理を行います。
- Web ページへの接続
- DOM からの対象の HTML 要素の選択
- それらからのデータの取得
- スクレイピングしたデータの CSV へのエクスポート
現在ターゲットページにアクセスすると次のように表示されます。

Bright Data のホームページは頻繁に変更されます。そのため、この記事を読む頃には変わっているかもしれません。
このページから抽出できる興味深いデータには、これらのカードに含まれている業界情報があります。
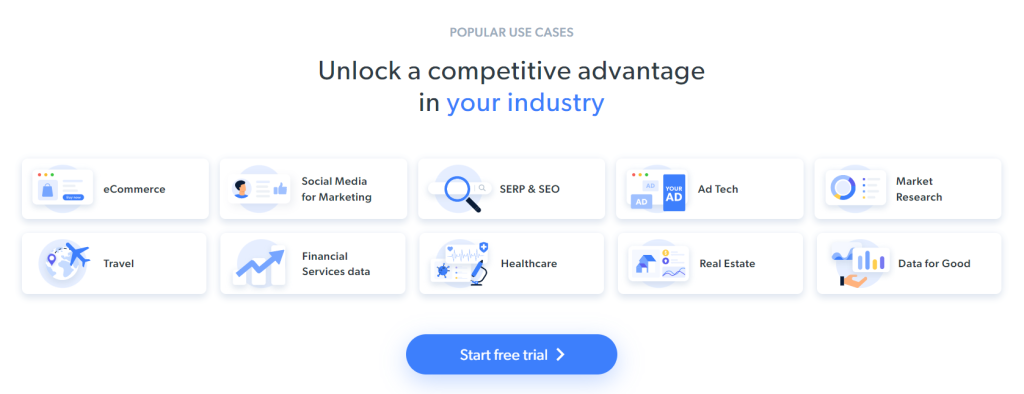
このステップバイステップチュートリアルでは、それらをスクレイピングの目的とします。それでは、C++ で Web スクレイピングを行う方法を見てみましょう!
ステップ 1: C++ スクレイピングプロジェクトを初期化する
まず、C++ プロジェクトを格納するフォルダが必要です。ターミナルを開き、次のコマンドでプロジェクトディレクトリを作成します。
mkdir c++-web-scraper
このディレクトリにはスクレイピングスクリプトが含まれます。
C++ でソフトウェアをビルドするには、Visual Studio IDE をお勧めします。それでは、vcpkg をパッケージマネージャーとする C++ での開発に向けて Visual Studio Code (VS Code) をセットアップする方法を詳しくご説明します。他の C++ IDE にも同様の手順を使用できます。
VS Code は C++ のサポートが組み込まれていないため、はじめに C/C++ プラグインを追加する必要があります。Visual Studio Code を起動し、左のバーの [拡張機能] アイコンをクリックして、最上部の検索フィールドに「C++」と入力します。
最初の要素の [インストール] ボタンをクリックして、VS Code に C++ 開発機能を追加します。拡張機能がセットアップされるのを待ってから、[ファイル] > [フォルダを開く...] で c++-web-scraper フォルダを開きます。
エクスプローラーセクションを右クリックして、[新規ファイル…] を選択し、scraper.cpp ファイルを以下のように初期化します。
#include <iostream>
int main()
{
std::cout << "Hello World" << std::endl;
}
これで C++ プロジェクトが準備できました!
ステップ 2: スクレイピングライブラリをインストールする
C++ の扱いにくい構文と Web 機能の制限は、Web スクレイパーをビルドする際の障害となる可能性があります。すべてを簡単に行えるよう、いくつかの Web スクレイピング C++ ライブラリの使用をお勧めします。前述のように、選択肢はかなり限られています。そこで、最も人気のある cpr と libxml2 をお勧めします。
Windows には、vcpkg で次のコマンドを使用してインストールできます。
vcpkg install cpr libxml2 --triplet=x64-windows
macOS では、トリプレットオプションを x64-osx に置き換えます。Linux では、x64-linux を使用します。
Visual Studio Code ターミナルでは、プロジェクトのルートディレクトリで次のコマンドを実行する必要もあります。
vcpkg integrate install
これにより、vcpkg パッケージをプロジェクトにリンクできるようになります。
VS Code を再起動すると、#include でインストール済みのライブラリをインポートできるようになります。ここで、scraper.cpp ファイルの最上部に次の 3 行を追加します。
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
IDE がエラーを報告しないことを確認してください。
ステップ 3: C++ プロジェクトの初期化を完了する
C++ スクレイピングスクリプトをビルドしてプロジェクトの初期化プロセスを完了するには、CMake Tools 拡張機能を VS Code に追加する必要があります。
プロジェクトに .vscode フォルダがない場合は、作成します。VS Code はこのフォルダを検索して、現在のプロジェクトに関連する構成を見つけます。
次のように .vscode フォルダ内に settings.json ファイルを作成して、vcpkg をツールチェーンとして使用するよう CMake ツールを構成します。
{
"cmake.configureSettings": {
"CMAKE_TOOLCHAIN_FILE": "c:/dev/vcpkg/scripts/buildsystems/vcpkg.cmake"
}
}
macOS と Linux では、vcpkg をインストールしたパスに従って CMAKE_TOOLCHAIN_FILE フィールドを修正します。上記のセットアップガイドに従った場合は、/dev/vcpkg/scripts/buildsystems/vcpkg.cmake になります。
VS Code のメイン検索バーに「>cmake」と入力し、[CMake: Configure] オプションを選択します。

これにより、ターゲットのコンパイラプラットフォームを選択できるようになります。Windows では、「Visual Studio Build Tools 2019 Release – x86_amd64」を選択します。

CMakeLists.txt ファイルをプロジェクトのルートフォルダに追加して、CMake をセットアップします。
cmake_minimum_required(VERSION 3.0.0)
project(main VERSION 0.1.0)
INCLUDE_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/include
)
LINK_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/lib
)
add_executable(main scraper.cpp)
target_compile_features(main PRIVATE cxx_std_20)
find_package(cpr CONFIG REQUIRED)
target_link_libraries(main PRIVATE cpr::cpr)
find_package(LibXml2 REQUIRED)
target_link_libraries(main PRIVATE LibXml2::LibXml2)
前の手順でインストールした 2 つのパッケージが使用されます。必ず INCLUDE_DIRECTORIES と LINK_DIRECTORIES を vcpkg のインストールフォルダに従って更新してください。
Visual Studio Code で C++ プログラムを実行できるようにするには、起動構成ファイルが必要です。.vscode フォルダで、launch.json を以下のように初期化します。
{
"configurations": [
{
"name": "C++ Launch (Windows)",
"type": "cppvsdbg",
"request": "launch",
"program": "${workspaceFolder}/build/Debug/main.exe",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": []
}
]
}
これで、実行またはデバッグコマンドを起動すると、VS Code が CMake によって生成された program パスでファイルを実行するようになります。macOS と Linux では .exe ファイルにはならないので注意してください。
構成の準備が整いました!
アプリをデバッグまたはビルドするたびに、最上部の入力フィールドに「>cmake: Build」と入力し、「CMake: Build」オプションを選択します。

ビルドプロセスが終了するのを待ってから、「実行とデバッグ」セクションから、または F5 キーを押して、コンパイル済みのプログラムを実行します。VSC デバッグコンソールにアプリケーションの結果が表示されます。
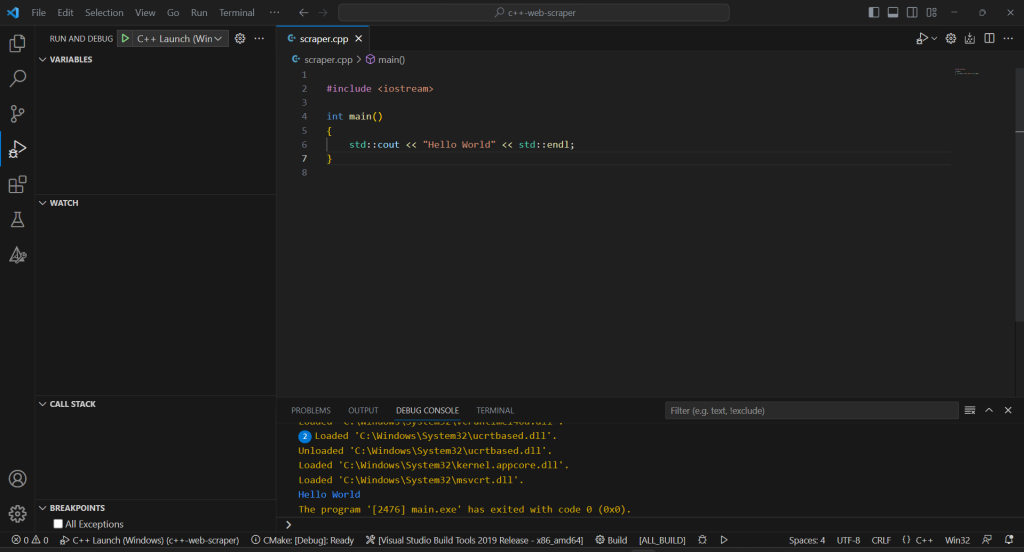
ここまで順調です!それでは C++ でデータスクレイピングを始めましょう!
ステップ 4: CPR でターゲットページをダウンロードする
ページからデータを抽出するには、まず HTTP GET 要求を使用して HTML ドキュメントを取得する必要があります。
CPR で次のコマンドを使用してターゲットページをダウンロードします。
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"});
舞台裏では、Get() メソッドがパラメーターとして渡された URL に対し、GET 要求を実行します。response.text には、サーバーから返された HTML コードの文字列表現が含まれます。
自動 HTTP 要求を実行すると、ボット対策テクノロジーがトリガーされる可能性があります。これにより、要求がインターセプトされ、スクリプトがターゲットサイトにアクセスできなくなる場合があります。具体的に言うと、最も基本的なスクレイピング対策ソリューションは、受信した要求に有効な User-Agent HTTP ヘッダーがないと、ブロックします。詳細は、Web スクレイピングにおける User-Agent に関するガイドをご覧ください。
他の HTTP クライアントと同様に、CPR も User-Agent にプレースホルダー値を使用します。これは一般的なブラウザで使用されているエージェントとは大きく異なるため、ボット対策システムが簡単に検出できます。このような理由でブロックされないようにするには、CPR で次のように有効な User-Agent を設定できます。
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/121.21.21.da/31/3das/32/1"}, headers);
これで、その Get() を介して行われた HTPP 要求は、Google Chrome 113 から送信されたものとして認識されるようになります。
scraper.cpp には現在次のようになっています。
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
int main()
{
// define the user agent for the GET request
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// make the HTTP request to retrieve the target page
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// scraping logic...
}
ステップ 5: libxml2 で HTML コンテンツを解析する
サーバーから返された HTML ドキュメントを簡単に閲覧できるようにするには、まずそのドキュメントを解析する必要があります。
C 文字列表現を libxml2 の HTMLReadMemory() 関数に渡すと、次のようになります。
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
これで、doc 変数が、libxml2 の提供する DOM 閲覧 API を公開するようになります。XPath セレクターを使用してページ上の HTML 要素を詳細に取得できます。この記事の執筆時点では、libxml2 は CSS セレクターをサポートしていません。
ステップ 6: 目的の HTML 要素を取得する XPath セレクターを定義する
対象の HTML ノードに効果的な XPath 選択戦略を定義するには、ターゲットページの DOM を分析する必要があります。ブラウザで Bright Data のホームページを開き、業界カードのいずれかを右クリックして、[検証] を選択します。これにより、開発ツールセクションが開きます。
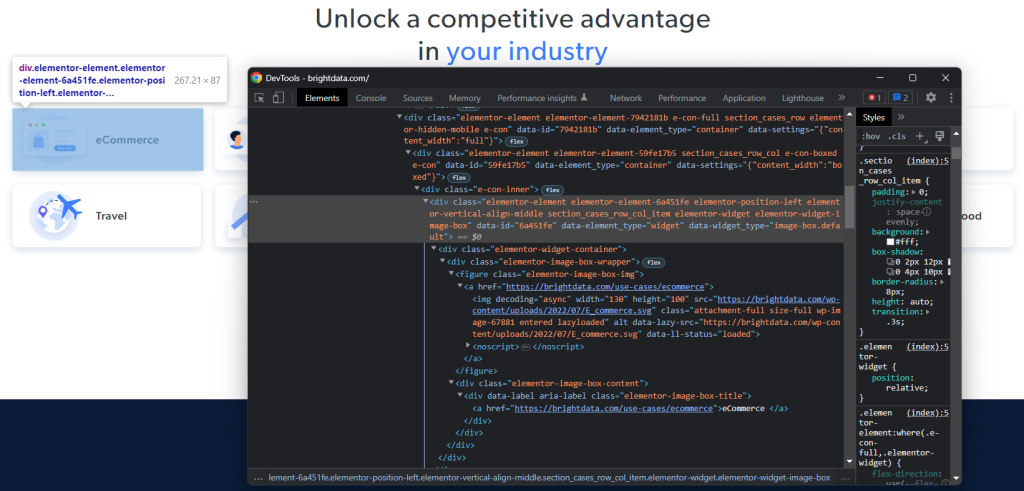
HTML コードを調べてみると、それぞれの業界カードが <div> 要素で、次のものが含まれていることがわかります。
- 業界の画像を表す
<img>を含む<figure>要素と、業界のページへの URL が含まれている<a>。 <a>に業界名を格納している<div>HTML 要素。
C++ スクレイパーの目標は、それぞれのカードから次の情報を抽出することです。
- 業界画像の URL
- 業界ページの URL
- 業界名
適切な XPath セレクターを定義するには、対象の要素の DOM 構造に注目します。以下の XPath セレクターですべての業界カードを取得できます。
//div[contains(@class, 'section_cases_row_col_item')]
確信が持てない場合は、ブラウザコンソールで $x() を使って XPath コマンドをテストできます。
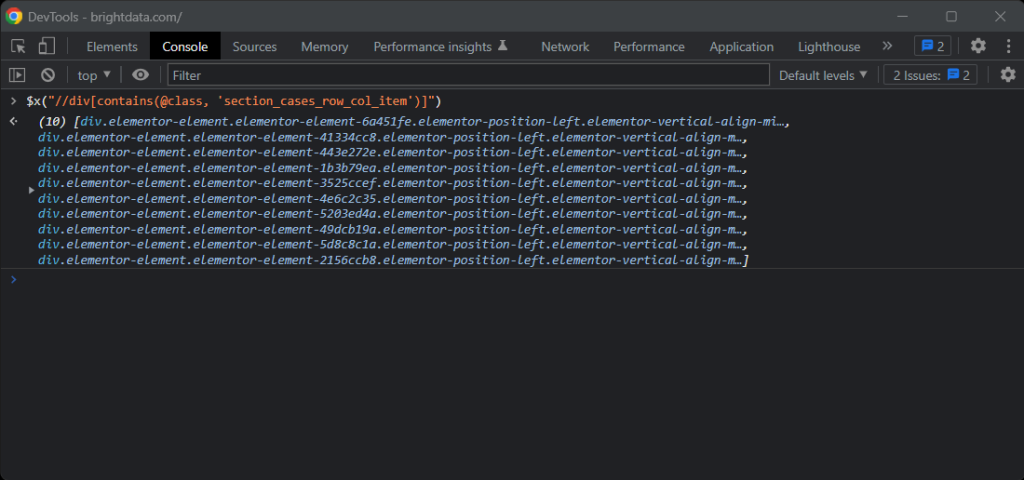
カードを取得したら、次のコマンドで目的のノードを取得できます。
.//figure/a/img.//figure/a.//div[contains(@class, 'elementor-image-box-title')]/a
ステップ 7: libxml2 で Web ページからデータをスクレイピングする
これで、libxml2 を使用して前の手順で定義した XPath セレクターを適用し、ターゲット HTML Web ページから必要なデータを取得できます。
はじめに、インスタンスにスクレイピングされたデータを格納するデータ構造が必要です。
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
C++ では、struct を使用すると、複数のデータ属性を同じ名前でメモリブロックにバンドルできます。
次に、main() 関数内の IndustryCard の配列を初期化します。
std::vector<IndustryCard> industry_cards;
これにより、すべてのスクレイピングデータオブジェクトが格納されます。
このベクターに次の C++ Web スクレイピングロジックを入力します。
// define an array to store all retrieved data
std::vector<IndustryCard> industry_cards;
// set the libxml2 context to the current document
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// select all industry card HTML elements
// with an XPath selector
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// iterate over the list of industry card elements
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// get the current element of the loop
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// set the libxml2 context to the current element
// to limit the XPath selectors to its children
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// instantiate an IndustryCard struct with the collected data
IndustryCard industry_card = {image, url, name};
// add the object with the scraped data to the vector
industry_cards.push_back(industry_card);
}
// free up the resource allocated by libxml2
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
上のスニペットは、xmlXPathEvalExpression() で先に定義した XPath セレクターを適用して、業界カードを選択します。その後この作業を繰り返し、同様のアプローチを使用して、それぞれのカードから対象の子要素を取得します。次に、それらから業界画像の URL、ページの URL、業界名をスクレイピングします。最後に、libxml2 によって割り当てられたリソースを解放します。
ご覧のとおり、libxml2 を使用した C++ での Web スクレイピングはそれほど複雑ではありません。xmlGetProp() と xmlNodeGetContent() を使用することで、HTML 属性の値とノードのコンテンツをそれぞれ取得できます。
C++ でのデータスクレイピングの仕組みを理解したことで、さらに一歩進んで業界ページもスクレイピングするためのツールも手に入れました。この記事で紹介したリンクをたどって、新しいスクレイピングロジックを考案するだけです。これで存分に Web クローリングや Web スクレイピングが可能です!
やりました!目標達成です。しかし、このチュートリアルはまだ終わりではありません。
ステップ 7: スクレイピングしたデータを CSV にエクスポートする
for() ループの終わりに、industry_cards はスクレイピングされたデータを struct インスタンスに格納します。ご想像のとおり、これは他のチームにデータを提供するのに最適な形式ではありません。そこで、取得したデータを CSV に変換します。
ベクターは、組み込みの C++ 関数で次のように CSV ファイルにエクスポートできます。
// initialize the CSV output file
std::ofstream csv_file("output.csv");
// write the CSV header
csv_file << "url,image,name" << std::endl;
// poupulate the CSV output file
for (IndustryCard industry_card : industry_cards)
{
// transfrom each industry card record to a CSV record
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// free up the file resources
csv_file.close();
上記のコードは output.csv ファイルを作成し、ヘッダーレコードで初期化します。次に、industry_cards 配列を繰り返し処理し、各要素を CSV 形式の文字列に変換して出力ファイルに追加します。
スクレイピング C++ スクリプトをビルドして実行すると、プロジェクトのルートディレクトリに次の output.csv ファイルが追加されます。
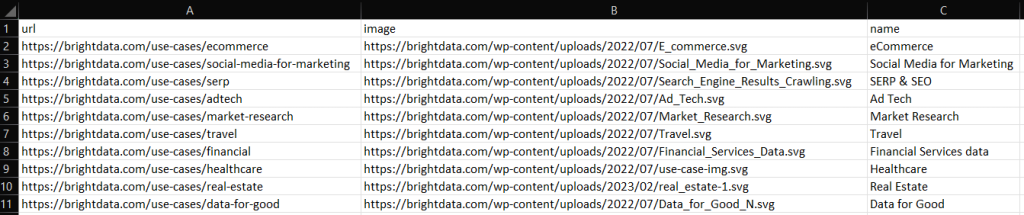
お疲れ様です!これで、スクレイピングされたデータを C++ で CSV にエクスポートする方法がわかりました!
ステップ 8: すべてをまとめる
C++ スクレイパー全体は次のようになります。
// scraper.cpp
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
#include <vector>
// define a struct where to store the scraped data
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
int main()
{
// define the user agent for the GET request
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// make an HTTP GET request to retrieve the target page
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// parse the HTML document returned by the server
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
// define an array to store all retrieved data
std::vector<IndustryCard> industry_cards;
// set the libxml2 context to the current document
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// select all industry card HTML elements
// with an XPath selector
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// iterate over the list of industry card elements
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// get the current element of the loop
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// set the libxml2 context to the current element
// to limit the XPath selectors to its children
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// instantiate an IndustryCard struct with the collected data
IndustryCard industry_card = {image, url, name};
// add the object with the scraped data to the vector
industry_cards.push_back(industry_card);
}
// free up the resource allocated by libxml2
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
// initialize the CSV output file
std::ofstream csv_file("output.csv");
// write the CSV header
csv_file << "url,image,name" << std::endl;
// poupulate the CSV output file
for (IndustryCard industry_card : industry_cards)
{
// transfrom each industry card record to a CSV record
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// free up the file resources
csv_file.close();
return 0;
}
これで完成です!約 80 行のコードで、C++ でデータスクレイピングスクリプトを作成できます!
まとめ
このチュートリアルでは、C++ が Web スクレイピングに効率的な言語である理由を解説しました。スクレイピングライブラリは他の言語ほど多くはありませんが、いくつか利用できるものがあります。このチュートリアルでは、どれが最も人気があるかをご覧いただきました。次に、CPR と libxml2 を使用して、実際のターゲットからデータを収集できるスパイダーを C++ でビルドする方法をご紹介しました。
しかし、Web スクレイピングには多くの課題が伴います。実際に、データを保護するためにボットおよびスクレイピング対策用のテクノロジーを実装しているサイトが増えています。これらのツールは、C++ のスクレイピングスクリプトによって実行される自動要求を検出し、アクセスを禁止することができます。幸い、データ収集のニーズに対応する自動化ソリューションは数多くあります。ユースケースに最適なソリューションについては、お問い合わせください。
Web スクレイピングに手間をかけたくないけれど、Web データには興味があるという方もいらっしゃるでしょう。 すぐに使えるデータセットをご覧ください。






