

TL:DR:取引・投資向けの財務分析に活用できるYahoo Financeスクレイパーを作成して株式データを抽出する方法を学びましょう。
このチュートリアルでは、次の内容を取り上げます。
- ウェブから財務データをスクレイピングするのはなぜか?
- 財務スクレイピングのライブラリとツール
- Seleniumを使ってYahoo Financeから株式データをスクレイピングする
ウェブから財務データをスクレイピングするのはなぜか?
ウェブから財務データをスクレイピングすることで、以下のようなさまざまな場面で役立つ貴重なインサイトを得られます。
- 自動取引:開発者は、株価や出来高など、市場のリアルタイムデータや履歴データを収集することで、自動取引戦略を構築できます。
- テクニカル分析:テクニカルアナリストにとって、市場の履歴データと指標は非常に重要です。これらを利用してパターンやトレンドを把握し、投資の意思決定に活用できます。
- 財務モデリング:研究者やアナリストは、財務諸表や経済指標などの関連データを収集し、企業業績の評価、収益予測、投資機会を評価する複雑なモデルを構築できます。
- 市場調査:財務データは、株式、市場指数、商品に関する多くの情報を提供します。このデータを分析することで、研究者は市場のトレンド、センチメント、業界の健全性を理解し、情報に基づいた投資判断を下せます。
Yahoo Financeは、市場を監視する上で人気のある財務ウェブサイトの1つです。このサイトは、株式、債券、ミューチュアルファンド、コモディティ、通貨、市場指数に関するリアルタイムデータや履歴データなど、幅広い情報とツールを投資家やトレーダーに提供しています。さらに、ニュース記事、財務諸表、アナリストの予測、チャート、その他の貴重なリソースも提供しています。
Yahoo Financeをスクレイピングすることで、財務分析、リサーチ、意思決定プロセスをサポートする豊富な情報にアクセスできます。
財務スクレイピングのライブラリとツール
Pythonは、構文、使いやすさ、ライブラリの豊富なエコシステムのおかげで、スクレイピングに最適な言語の1つと考えられています。Pythonを使ったウェブスクレイピングのガイドをご覧ください。
数あるスクレイピングライブラリの中から適切なものを選ぶため、ブラウザでYahoo Financeを検索してみましょう。サイト上のほとんどのデータがリアルタイムで、または対話処理の後に変更されるのに気づくでしょう。これは、ページを再読み込みせずに、データを動的に読み込んで更新するために、サイトがAJAXを多用していることを示しています。つまり、JavaScriptを実行できるツールが必要です。
Seleniumを使用すると、Pythonで動的なウェブサイトをスクレイピングできるようになります。データのレンダリングや取得にJavaScriptを使用している場合でも、ウェブブラウザでサイトをレンダリングし、プログラムで操作を実行します。
Seleniumがあれば、Pythonを使ってターゲットサイトをスクレイピングできます。その方法を学びましょう!
Seleniumを使ってYahoo Financeから株式データをスクレイピングする
このステップバイステップのチュートリアルに従って、Yahoo FinanceのウェブスクレイピングPythonスクリプトを構築する方法を確認してください。
ステップ1:セットアップ
財務スクレイピングを始める前に、以下の前提条件を満たしていることを確認してください。
- Python 3+がお使いのマシンにインストールされていること:インストーラをダウンロードしてダブルクリックし、インストールウィザードに従って操作を行います。
- お好みのPython IDE:PyCharm Community Edition、またはPython拡張機能付きのVisual Studio Codeなどがよいでしょう。
次に、以下のコマンドを使って、Pythonプロジェクトを仮想環境でセットアップします。
nmkdir yahoo-finance-scraperncd yahoo-finance-scrapernpython -m venv env
これで、yahoo-finance-scraperプロジェクトフォルダが初期化されます。その中に、以下のようにscraper.pyファイルを追加します。
print('Hello, World!')
Yahoo Financeをスクレイピングするロジックをここに追加します。現時点では、これは「Hello, World!」と表示するだけのサンプルスクリプトです。
起動して、動作することを確認します。
python scraper.py
ターミナルには次のように表示されているはずです。
Hello, World!
これで財務スクレイパー用のPythonプロジェクトができました。あとはプロジェクトの依存関係を追加するだけです。以下のターミナルコマンドで、SeleniumとWebdriver Managerをインストールします。
pip install selenium webdriver-manager
少し時間がかかる場合があります。しばらく待ってください。
webdriver-managerは厳密には必須ではありません。ただ、Seleniumでウェブドライバを管理するのが非常に簡単になるので、強くお勧めします。このおかげで、ウェブドライバを手動でダウンロード、設定、インポートする必要がなくなります。
scraper.pyを更新する
nfrom selenium import webdrivernfrom selenium.webdriver.chrome.service import Service as ChromeServicenfrom webdriver_manager.chrome import ChromeDriverManagernn# initialize a web driver instance to control a Chrome windowndriver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))nn# scraping logic...nn# close the browser and free up the resourcesndriver.quit()
このスクリプトは、ChromeWebDriverのインスタンスをインスタンス化するだけです。データ抽出ロジックを実装するために、すぐにそれを使うことになります。
ステップ2:ターゲットのウェブページに接続する
Yahoo Finenceの株式ページのURLは、以下のようになっています。
https://finance.yahoo.com/quote/AMZN
ご覧のように、これはティッカーシンボルによって変化する動的URLです。この概念に詳しくない方のために説明すると、これは株式市場で取引される株式を一意に識別するために使用される文字列の略称です。例えば、「AMZN」はAmazon株のティッカーシンボルです。
コマンドライン引数からティッカーを読み込むようにスクリプトを修正しましょう。
nimport sysnn# if there are no CLI parametersnif len(sys.argv) u003c= 1:n print('Ticker symbol CLI argument missing!')n sys.exit(2)nn# read the ticker from the CLI argumentnticker_symbol = sys.argv[1]nn# build the URL of the target pagenurl = f'https://finance.yahoo.com/quote/{ticker_symbol}'
sysは、コマンドライン引数へのアクセスを提供するPython標準ライブラリです。インデックス0の引数がスクリプトの名前であることを覚えておいてください。したがって、インデックス1の引数をターゲットにする必要があります。
CLIからティッカーを読み取った後、それをf文字列で使用し、スクレイピングするターゲットURLを生成します。
例えば、Teslaのティッカー「TSLA:」でスクレイパーを起動するとします。
python scraper.py TSLAn
urlには以下が含まれます。
https://finance.yahoo.com/quote/TSLA
CLIでティッカーシンボルを指定し忘れると、プログラムは以下のエラーで失敗します。
Ticker symbol CLI argument missing!
Seleniumでページを開く前に、すべての要素が見えるようにウィンドウサイズを設定することをお勧めします。
driver.set_window_size(1920, 1080)
get()関数はブラウザに、目的のページにアクセスするよう指示します。
driver.get(url)
get()関数はブラウザに、目的のページにアクセスするよう指示します。
Yahoo Financeのスクレイピングスクリプトは、現在のところ次のようになります。
nfrom selenium import webdrivernfrom selenium.webdriver.chrome.service import Service as ChromeServicenfrom webdriver_manager.chrome import ChromeDriverManagernimport sysnn# if there are no CLI parametersnif len(sys.argv) u003c= 1:n print('Ticker symbol CLI argument missing!')n sys.exit(2)nn# read the ticker from the CLI argumentnticker_symbol = sys.argv[1]nn# build the URL of the target pagenurl = f'https://finance.yahoo.com/quote/{ticker_symbol}'nn# initialize a web driver instance to control a Chrome windowndriver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))n# set up the window size of the controlled browserndriver.set_window_size(1920, 1080)n# visit the target pagendriver.get(url)nn# scraping logic...nn# close the browser and free up the resourcesndriver.quit()
起動すると、このウィンドウが一瞬だけ開いて終了します。
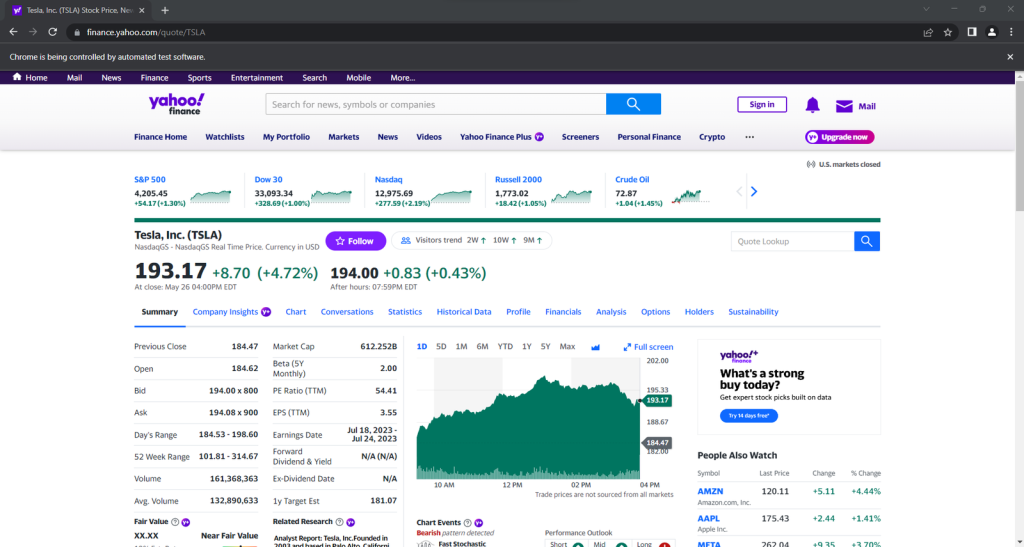
UI付きでブラウザを起動すると、スクレイパーがウェブページ上で何を実行しているかを監視してデバッグするのに便利です。ただし、これには多くのリソースが必要です。これを避けるには、ヘッドレスモードで実行するようにChromeを構成します。
nfrom selenium.webdriver.chrome.options import Optionsn# ...nnoptions = Options()noptions.add_argument('u002du002dheadless=new')nndriver = webdriver.Chrome(n service=ChromeService(ChromeDriverManager().install()),n options=optionsn)
制御対象のブラウザは、UIなしでバックグラウンドで起動します。
ステップ3:ターゲットページを検査する
効果的なデータマイニング戦略を構築したいのであれば、まずターゲットのウェブページを分析する必要があります。ブラウザを開き、Yahoo株式ページにアクセスします。
欧州に拠点を置いているのであれば、最初にクッキーを受け入れるよう求めるモーダルが表示されます。
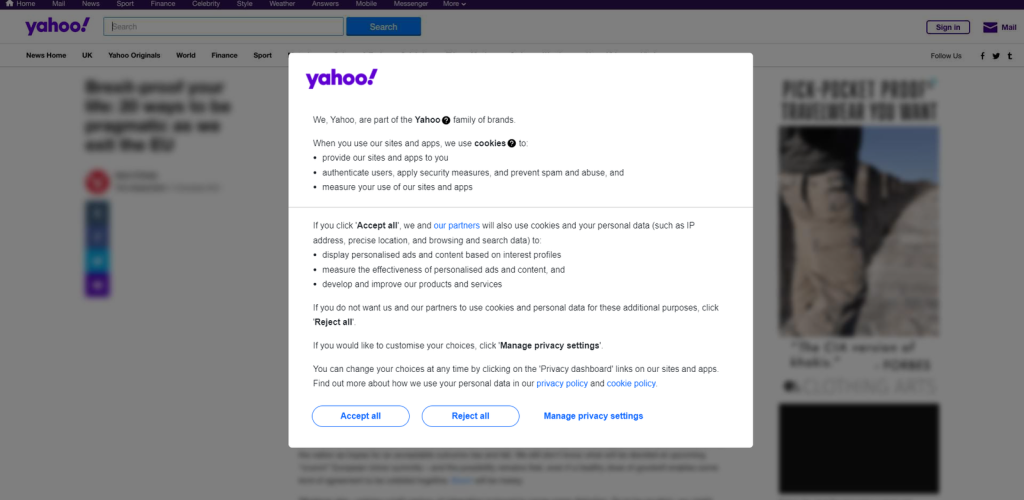
それを閉じて、目的のページにアクセスし続けるには、「すべて受け入れる」または「すべて拒否する」をクリックする必要があります。最初のボタンを右クリックし、「検査」オプションを選択すると、ブラウザのDevToolsが開きます。

ここで、次のCSSセレクタを使うと、そのボタンを選択できることがお分かりいただけるでしょう。
.consent-overlay .accept-all
以下の行を使用して、Seleniumの同意モーダルに対処します。
ntry:n # wait up to 3 seconds for the consent modal to show upn consent_overlay = WebDriverWait(driver, 3).until(n EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))nn # click the u0022Accept allu0022 buttonn accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')n accept_all_button.click()nexcept TimeoutException:n print('Cookie consent overlay missing')
WebDriverWaitを使用すると、予期される条件がページ上で発生するのを待機できます。指定されたタイムアウトの間に何も起こらなければ、TimeoutExceptionを発生させます。クッキーオーバーレイは、出口IPが欧州の場合にのみ表示されるため、try-catch命令で例外を扱うことができます。こうすることで、同意モーダルが存在しない場合でも、スクリプトは実行を続けます。
スクリプトを動作させるには、以下のimportを追加する必要があります。
nfrom selenium.webdriver.support.ui import WebDriverWaitnfrom selenium.webdriver.support import expected_conditions as ECnfrom selenium.webdriver.common.by import Bynfrom selenium.common import TimeoutException
DevToolsでターゲットサイトの検査を続けて、そのDOM構造に精通していきます。
ステップ4:株式データを抽出する
前のステップでお気づきのように、最も興味深い情報の一部がこのセクションにあります。
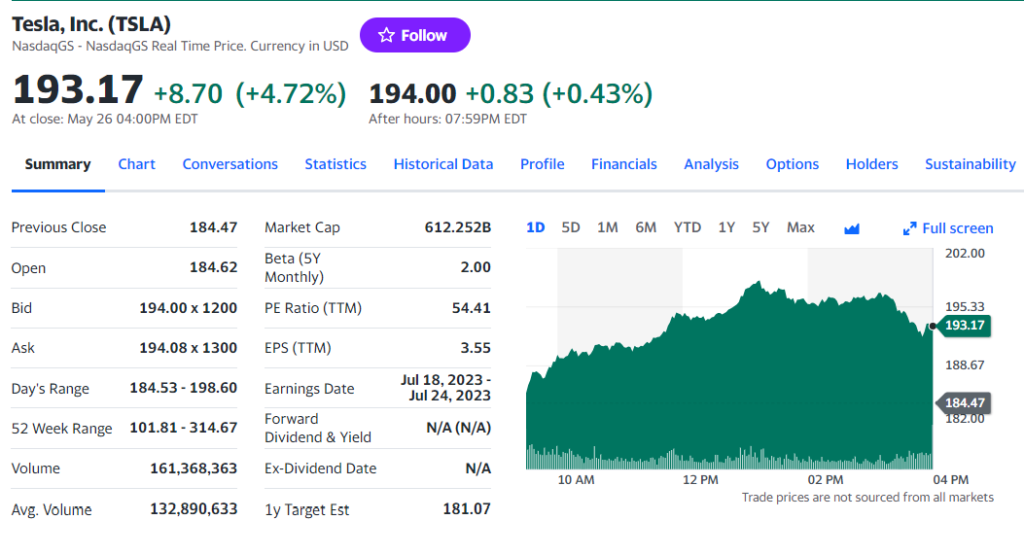
HTML価格指標要素を検査します。
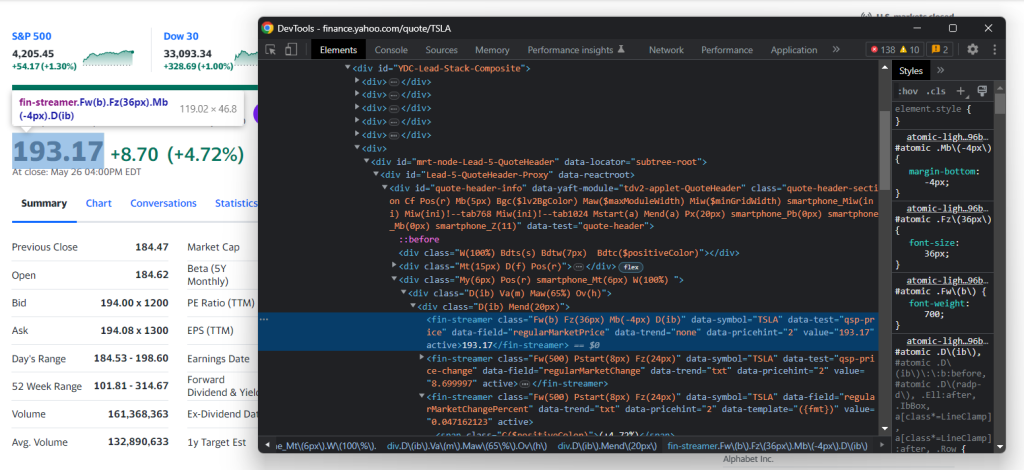
CSSクラスは、Yahoo Financeで適切なセレクタを定義するのには役に立たないことに留意してください。これらはスタイリングフレームワーク向けの特殊な構文に従っているようです。代わりに、他のHTML属性に注目します。例えば、以下のCSSセレクタで株価を取得できます。
[data-symbol=u0022TSLAu0022][data-field=u0022regularMarketPriceu0022]
同様の手法で、価格指標からすべての株式データを抽出します。
nregular_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketPriceu0022]')
.textnregular_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketChangeu0022]')
.textnregular_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketChangePercentu0022]')
.text
.replace('(', '').replace(')', '')n npost_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketPriceu0022]')
.textnpost_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketChangeu0022]')
.textnpost_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketChangePercentu0022]')
.text
.replace('(', '').replace(')', '')n
特定のCSSセレクタ戦略でHTML要素を選択した後、textフィールドでその内容を抽出できます。パーセントフィールドには丸括弧が含まれるため、replace()で丸括弧を削除します。
それらをstock辞書に追加して出力し、財務データのスクレイピングプロセスが期待通りに機能することを検証します。
n# initialize the dictionarynstock = {}nn# stock price scraping logic omitted for brevity...nn# add the scraped data to the dictionarynstock['regular_market_price'] = regular_market_pricenstock['regular_market_change'] = regular_market_changenstock['regular_market_change_percent'] = regular_market_change_percentnstock['post_market_price'] = post_market_pricenstock['post_market_change'] = post_market_changenstock['post_market_change_percent'] = post_market_change_percentnnprint(stock)
スクリプトをスクレイピングしたいセキュリティで実行すると、以下のようなものが表示されるはずです。
{'regular_market_price': '193.17', 'regular_market_change': '+8.70', 'regular_market_change_percent': '+4.72%', 'post_market_price': '194.00', 'post_market_change': '+0.83', 'post_market_change_percent': '+0.43%'}
その他の有用な情報は、#quote-summaryテーブルで見つけることができます。
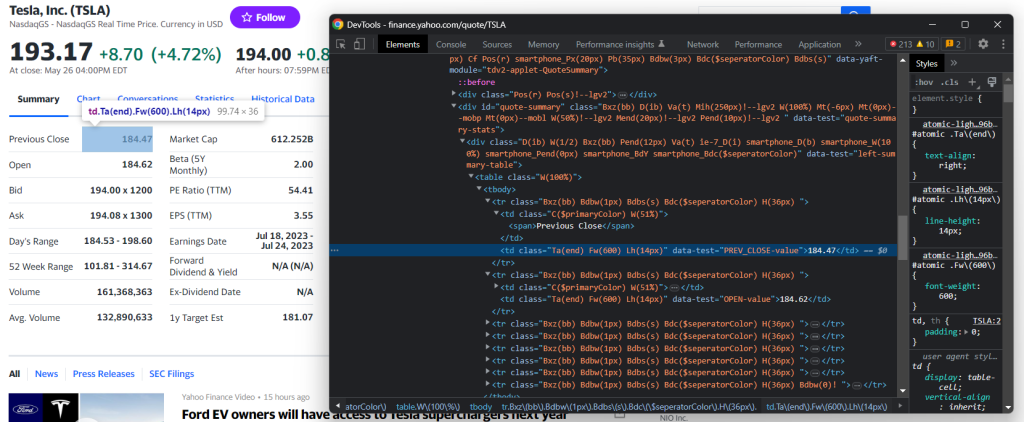
この場合、以下のCSSセレクタのように、data-test属性のおかげで各データフィールドを抽出できます。
#quote-summary [data-test=u0022PREV_CLOSE-valueu0022]
以下を使ってすべてをスクレイピングします。
nprevious_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022PREV_CLOSE-valueu0022]').textnopen_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022OPEN-valueu0022]').textnbid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022BID-valueu0022]').textnask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022ASK-valueu0022]').textndays_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022DAYS_RANGE-valueu0022]').textnweek_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022FIFTY_TWO_WK_RANGE-valueu0022]').textnvolume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022TD_VOLUME-valueu0022]').textnavg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022AVERAGE_VOLUME_3MONTH-valueu0022]').textnmarket_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022MARKET_CAP-valueu0022]').textnbeta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022BETA_5Y-valueu0022]').textnpe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022PE_RATIO-valueu0022]').textneps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EPS_RATIO-valueu0022]').textnearnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EARNINGS_DATE-valueu0022]').textndividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022DIVIDEND_AND_YIELD-valueu0022]').textnex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EX_DIVIDEND_DATE-valueu0022]').textnyear_target_est = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022ONE_YEAR_TARGET_PRICE-valueu0022]').text
その後、それらをstockに追加します。
nstock['previous_close'] = previous_closenstock['open_value'] = open_valuenstock['bid'] = bidnstock['ask'] = asknstock['days_range'] = days_rangenstock['week_range'] = week_rangenstock['volume'] = volumenstock['avg_volume'] = avg_volumenstock['market_cap'] = market_capnstock['beta'] = betanstock['pe_ratio'] = pe_rationstock['eps'] = epsnstock['earnings_date'] = earnings_datenstock['dividend_yield'] = dividend_yieldnstock['ex_dividend_date'] = ex_dividend_datenstock['year_target_est'] = year_target_est
素晴しいです!これで、Pythonを使って財務ウェブスクレイピングを実行できました!
ステップ5:複数の株式をスクレイピングする
分散投資ポートフォリオは、複数の証券で構成されます。これらすべてのデータを取得するには、複数のティッカーをスクレイピングするようにスクリプトを拡張する必要があります。
まず、スクレイピングロジックを関数にカプセル化します。
ndef scrape_stock(driver, ticker_symbol):n url = f'https://finance.yahoo.com/quote/{ticker_symbol}'n driver.get(url)nn # deal with the consent modal...nn # initialize the stock dictionary with then # ticker symboln stock = { 'ticker': ticker_symbol }nn # scraping the desired data and populate n # the stock dictionary...nn return stock
次に、CLIのティッカー引数を反復処理して、スクレイピング関数を適用します。
nif len(sys.argv) u003c= 1:n print('Ticker symbol CLI arguments missing!')n sys.exit(2)nn# initialize a Chrome instance with the rightn# configsnoptions = Options()noptions.add_argument('u002du002dheadless=new')ndriver = webdriver.Chrome(n service=ChromeService(ChromeDriverManager().install()),n options=optionsn)ndriver.set_window_size(1150, 1000)nn# the array containing all scraped datanstocks = []nn# scraping all market securitiesnfor ticker_symbol in sys.argv[1:]:n stocks.append(scrape_stock(driver, ticker_symbol))
forサイクルが終了すると、Python辞書のstocksのリストには、すべての株式市場のデータが含まれることになります。
ステップ6:スクレイピングしたデータをCSVにエクスポートする
わずか数行のコードで、収集したデータをCSVにエクスポートできます。
nimport csvnn# ...nn# extract the name of the dictionary fieldsn# to use it as the header of the output CSV filencsv_header = stocks[0].keys()nn# export the scraped data to CSVnwith open('stocks.csv', 'w', newline='') as output_file:n dict_writer = csv.DictWriter(output_file, csv_header)n dict_writer.writeheader()n dict_writer.writerows(stocks)
このスニペットは、open()でstocks.csvファイルを作成し、ヘッダ行で初期化し、それにデータを入力します。具体的にはDictWriter.writerows()は、各辞書をCSVレコードに変換して、出力ファイルに追加します。
csvはPython Standard Libraryから提供されているため、目的を達成するために追加の依存関係をインストールする必要はありません。
ウェブページに含まれる生データを、半構造化データにしてCSVファイルに格納できます。それでは、Yahoo Financeスクレイパー全体を見てみましょう。
ステップ7:すべてを統合する
以下に、完全なscraper.pyファイルを示します。
nfrom selenium import webdrivernfrom selenium.webdriver.chrome.service import Service as ChromeServicenfrom webdriver_manager.chrome import ChromeDriverManagernfrom selenium.webdriver.chrome.options import Optionsnfrom selenium.webdriver.support.ui import WebDriverWaitnfrom selenium.webdriver.support import expected_conditions as ECnfrom selenium.webdriver.common.by import Bynfrom selenium.common import TimeoutExceptionnimport sysnimport csvnndef scrape_stock(driver, ticker_symbol):n # build the URL of the target pagen url = f'https://finance.yahoo.com/quote/{ticker_symbol}'nn # visit the target pagen driver.get(url)nn try:n # wait up to 3 seconds for the consent modal to show upn consent_overlay = WebDriverWait(driver, 3).until(n EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))nn # click the 'Accept all' buttonn accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')n accept_all_button.click()n except TimeoutException:n print('Cookie consent overlay missing')nn # initialize the dictionary that will containn # the data collected from the target pagen stock = { 'ticker': ticker_symbol }nn # scraping the stock data from the price indicatorsn regular_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketPriceu0022]')
.textn regular_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketChangeu0022]')
.textn regular_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketChangePercentu0022]')
.text
.replace('(', '').replace(')', '')nn post_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketPriceu0022]')
.textn post_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketChangeu0022]')
.textn post_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketChangePercentu0022]')
.text
.replace('(', '').replace(')', '')nn stock['regular_market_price'] = regular_market_pricen stock['regular_market_change'] = regular_market_changen stock['regular_market_change_percent'] = regular_market_change_percentn stock['post_market_price'] = post_market_pricen stock['post_market_change'] = post_market_changen stock['post_market_change_percent'] = post_market_change_percentnn # scraping the stock data from the u0022Summaryu0022 tablen previous_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022PREV_CLOSE-valueu0022]').textn open_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022OPEN-valueu0022]').textn bid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022BID-valueu0022]').textn ask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022ASK-valueu0022]').textn days_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022DAYS_RANGE-valueu0022]').textn week_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022FIFTY_TWO_WK_RANGE-valueu0022]').textn volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022TD_VOLUME-valueu0022]').textn avg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022AVERAGE_VOLUME_3MONTH-valueu0022]').textn market_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022MARKET_CAP-valueu0022]').textn beta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022BETA_5Y-valueu0022]').textn pe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022PE_RATIO-valueu0022]').textn eps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EPS_RATIO-valueu0022]').textn earnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EARNINGS_DATE-valueu0022]').textn dividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022DIVIDEND_AND_YIELD-valueu0022]').textn ex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EX_DIVIDEND_DATE-valueu0022]').textn year_target_est = driver.find_element(By.CSS_SELECTOR,n '#quote-summary [data-test=u0022ONE_YEAR_TARGET_PRICE-valueu0022]').textnn stock['previous_close'] = previous_closen stock['open_value'] = open_valuen stock['bid'] = bidn stock['ask'] = askn stock['days_range'] = days_rangen stock['week_range'] = week_rangen stock['volume'] = volumen stock['avg_volume'] = avg_volumen stock['market_cap'] = market_capn stock['beta'] = betan stock['pe_ratio'] = pe_ration stock['eps'] = epsn stock['earnings_date'] = earnings_daten stock['dividend_yield'] = dividend_yieldn stock['ex_dividend_date'] = ex_dividend_daten stock['year_target_est'] = year_target_estnn return stocknn# if there are no CLI parametersnif len(sys.argv) u003c= 1:n print('Ticker symbol CLI argument missing!')n sys.exit(2)nnoptions = Options()noptions.add_argument('u002du002dheadless=new')nn# initialize a web driver instance to control a Chrome windowndriver = webdriver.Chrome(n service=ChromeService(ChromeDriverManager().install()),n options=optionsn)nn# set up the window size of the controlled browserndriver.set_window_size(1150, 1000)nn# the array containing all scraped datanstocks = []nn# scraping all market securitiesnfor ticker_symbol in sys.argv[1:]:n stocks.append(scrape_stock(driver, ticker_symbol))nn# close the browser and free up the resourcesndriver.quit()nn# extract the name of the dictionary fieldsn# to use it as the header of the output CSV filencsv_header = stocks[0].keys()nn# export the scraped data to CSVnwith open('stocks.csv', 'w', newline='') as output_file:n dict_writer = csv.DictWriter(output_file, csv_header)n dict_writer.writeheader()n dict_writer.writerows(stocks)
150行未満のコードで、Yahoo Financeからデータを取得するフル機能のウェブスクレイパーを構築できました。
以下の例のように、ターゲットの株式を指定してこれを起動します。
python scraper.py TSLA AMZN AAPL META NFLX GOOG
スクレイピングプロセスの最後に、このstocks.csvファイルがプロジェクトのルートフォルダに表示されます。

まとめ
このチュートリアルでは、Yahoo Financeがウェブ上の最高の財務ポータルの1つである理由と、そこからデータを抽出する方法を解説しました。特に、そこから株式データを取得するPythonスクレイパーの構築方法を見てきました。ご覧いただいておわかりのように、これは複雑なものではなく、わずか数行のコードで済むものです。
同時に、Yohoo FinanceはJavaScriptに大きく依存する動的なサイトです。この種のサイトを扱う場合、HTTPライブラリとHTMLパーサーに基づく従来のアプローチでは不十分です。その上、この種の人気サイトは高度なデータ保護技術を導入する傾向があります。それらをスクレイピングするには、CAPTCHAやフィンガープリンティング、自動再試行などを自動的に処理できる制御可能なブラウザが必要です。当社の新しいScraping Browserソリューションは、まさにそのためのツールです!
ウェブスクレイピングには全く関心がないとしても、財務データには興味がありませんか?当社のデータセットマーケットプレイスをご覧ください。




