

プロキシを使用した IP ローテーションは、特に制限がかけられている可能性のある最新の Web サイトの場合、Web スクレイピングに不可欠です。要求を複数の IP アドレスに分散させることは、ブロックされたりレート制限をかけられたりしないようにするために非常に重要です。IP アドレスをローテーションすると、Web サイトによるスクレイピングアクティビティの追跡と制限がより困難になります。これにより、Web スクレイピングプロセスの効率と信頼性が向上し、データをより効果的に抽出できるようになります。Web スクレイピング中にプロキシとローテーション IP アドレスを使用すると、IP に基づくアクセス禁止やペナルティを回避したり、レート制限を解決したり、地理的に制限されたコンテンツにアクセスしたりできます。
この記事では、Web スクレイピングのワークフローにプロキシを実装し、使用する IP アドレスをローテーションする方法について説明します。効果的なプロキシがどこで利用できるのか、IP ローテーションのコツ、そして対象の Web サイトからブロックされないようにする方法を解説します。
Python での IP ローテーション
Python の通常のスクレイピングプロセスでは、一般的に Requests や Scrapy などの Python ライブラリを使用して Web サイトにアクセスし、コンテンツを解析します。その後、抽出したい情報に合わせて Web サイトのコンテンツをフィルター処理できます。以下は一般的なスクレイピングプロセスの例です:
import requests
url = 'http://example.com'
# Make requests
response = requests.get(url)
print(response.text)
このプロセスでは必要な情報が得られるため、1 度限りの場合や、データを 1 度だけ抽出する必要がある場合であれば問題ありません。しかし、システム IP を使用して要求を行うため、要求が繰り返されたり継続したりすると、Web サイトが時間の経過とともにアクセスを制限するという問題が発生する可能性があります。
サンプルスクレイピングプロセスの結果は次のとおりです:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans",
…
Requests や Scrapy など、スクレイピングや Web 要求を目的としたほとんどの Python ライブラリには、これらの要求を行う際に使用する IP アドレスを切り替える手段があります。ただし、これを利用するには、有効な IP アドレスのリストまたはソースが必要です。このようなソースには無料のものもありますが、Bright Data プロキシなどの有料のものも利用できます。
有料オプションは有効性が保証されていて、プロキシの管理やローテーションを行うための便利なツールが提供されています。これにより、スクレイピングプロセスでダウンタイムが発生するのを防げます。たとえば、Bright Data は複数のカテゴリーのプロキシを提供していて、その用途や拡張性、要求したデータにブロックされずにアクセスできる保証の度合いによって、価格が異なります。
無料のプロキシを使用すると、Python で有効なプロキシを含むリストを作成し、スクレイピングプロセスの間中ローテーションできます:
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
これに必要なのは、複数の要求を行う際にリストから異なる IP アドレスを選択するローテーションのメカニズムだけです。Python では、次のような関数を使用します:
import random
import requests
def scraping_request(url):
ip = random.randrange(0, len(proxies))
ips = {"http": proxies[ip], "https": proxies[ip]}
response = requests.get(url, proxies=ips)
print(f"Proxy currently being used: {ips['https']}")
return response.text
このコードは、呼び出しが行われるたびにリストからランダムにプロキシを選択します。スクレイピングの要求にはプロキシが使用されます。
無効なプロキシを処理するためにエラーケースを含めると、完全なスクレイピングコードは次のようになります:
import random
import requests
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
def scraping_request(url):
ip = random.choice(proxies)
try:
response = requests.get(url, proxies={"http": ip, "https": ip})
if response.status_code == 200:
print(f"Proxy currently being used: {ip}")
ip = random.randrange(0, len(proxies))
ips = {"http": proxies[ip], "https": proxies[ip]}
response = requests.get(url, proxies=ips)
try:
if response.status_code == 200:
print(f"Proxy currently being used: {ips['https']}")
print(response.text)
elif response.status_code == 403:
print("Forbidden client")
elif response.status_code == 429:
print("Too many requests")
except Exception as e:
print(f"An unexpected error occurred: {e}")
scraping_request("http://example.com")
このプロキシのローテーションリストを使用して、Scrapy などの他のスクレイピングフレームワークで要求を行うこともできます。
Scrapy によるスクレイピング
Scrapy では、Web を正常にクロールするために、ライブラリをインストールして必要なプロジェクトアーティファクトを作成する必要があります。
Scrapy は、お使いの Python 対応環境で pip パッケージマネージャーを使用してインストールできます:
pip install Scrapy
インストールしたら、次のコマンドを使用して、現在のディレクトリにあるいくつかのテンプレートファイルを使用して、Scrapy プロジェクトを生成できます。
scrapy startproject sampleproject
cd sampleproject
scrapy genspider samplebot example.com
これらのコマンドは基本的なコードファイルも生成し、それに IP ローテーションメカニズムを加えることもできます。
sampleproject/spiders/samplebot.pysamplebot.py ファイルを開き、次のコードで更新します:
import scrapy
import random
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
ip = random.randrange(0, len(proxies))
class SampleSpider(scrapy.Spider):
name = "samplebot"
allowed_domains = ["example.com"]
start_urls = ["https://example.com"]
def start_requests(self):
for url in self.start_urls:
proxy = random.choice(proxies)
yield scrapy.Request(url, meta={"proxy": f"http://{proxy}"})
request = scrapy.Request(
"http://www.example.com/index.html",
meta={"proxy": f"http://{ip}"}
)
def parse(self, response):
# Log the proxy being used in the request
proxy_used = response.meta.get("proxy")
self.logger.info(f"Proxy used: {proxy_used}")
print(response.text)
このスクレイピングスクリプトを実行するには、プロジェクトディレクトリの一番上で次のコマンドを実行します:
scrapy crawl samplebot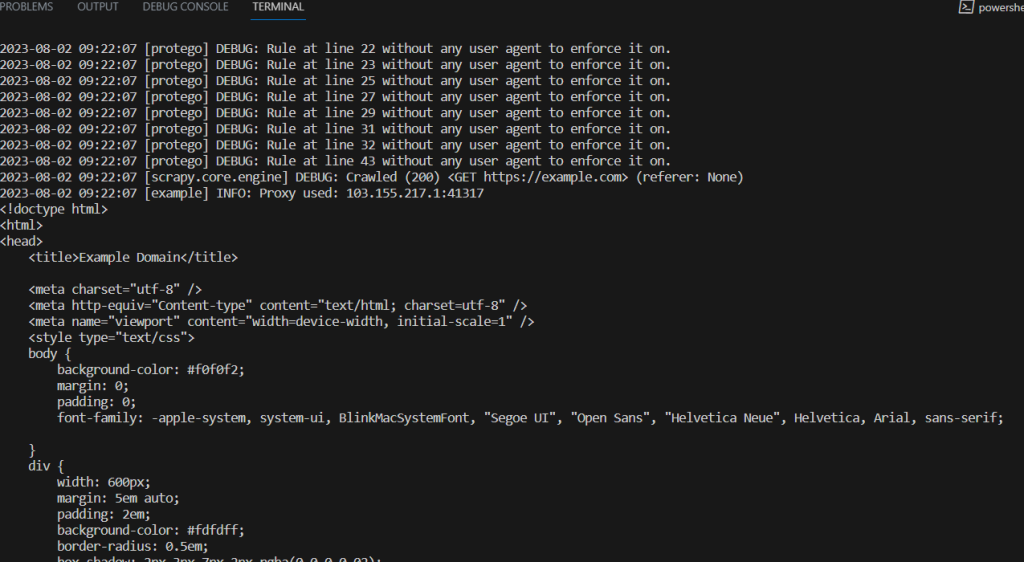
IP ローテーションのコツ
Web スクレイピングでは、Web サイトとスクレイパーの間で競争が繰り広げられています。スクレイパーは必要なデータを取得するための新しい手段や手法を考案し、Web サイトはアクセスをブロックするための新しい方法を模索しています。
IP ローテーションは、Web サイトによる制限を回避することを目的とした手法です。IP ローテーションの効果を最大限に引き出し、対象の Web サイトによってブロックされる可能性を最小限に抑えるには、次のコツを参考にしてください:
- 大規模で多様なプロキシプールを確保する: IP ローテーションを使用する場合、多数のプロキシとさまざまな種類の IP アドレスを備えた大規模なプロキシプールが必要です。このように多様性に優れたプールを使用することで、適切なローテーションを実現し、同様のプロキシを使いすぎることによるレート制限やアクセス禁止のリスクを軽減できます。IP アドレスの範囲や場所が異なる複数のプロキシプロバイダーを使用することをお勧めします。また、ユーザーの自然な行動により近づけるために、異なるプロキシによる要求のタイミングや間隔を変えることもお勧めします。
- 堅牢なエラー処理メカニズムを備えておく: Web スクレイピングのプロセスでは、一時的な接続の問題、プロキシのブロック、対象の Web サイトの変更が原因で、多くのエラーが発生する可能性があります。スクリプトにエラー処理を実装することで、接続エラー、タイムアウト、HTTP ステータスエラーなどの一般的な例外を検出して処理し、スクレイピングプロセスをスムーズに実行できます。短時間に大量のエラーが発生した場合にスクレイピング処理を一時的に停止する、サーキットブレーカーの設定もお勧めします。
- 使用前にプロキシをテストする: スクレイピングスクリプトを本番環境に展開する前に、プロキシプールのサンプルを使用して、さまざまなシナリオで IP ローテーションの機能とエラー処理メカニズムをテストします。サンプル Web サイトを使用して実際の状況をシミュレートすれば、スクリプトがこれらのケースを処理できることを確認できます。
- プロキシのパフォーマンスと効率を監視する: プロキシのパフォーマンスを定期的に監視して、応答時間が遅い、エラーが頻繁に発生するなどの問題を検出します。プロキシごとの成功率を把握して、効率の悪いプロキシを特定しましょう。Bright Data のようなプロキシプロバイダーは、プロキシの状態とパフォーマンスを確認するツールを提供しています。プロキシのパフォーマンスを監視することで、より信頼性の高いプロキシにすばやく切り替えて、パフォーマンスの低いプロキシをローテーションプールから排除できます。
Web スクレイピングは反復的なプロセスであり、Web サイトは構造や応答パターンを変更したり、スクレイピングを防止するための新しい対策を講じたりする場合があります。スクレイピングプロセスを定期的に監視し、変化に対応することで、スクレイピング作業の効果を維持できます。
まとめ
この記事では、IP ローテーションについて、そして Python を使用してスクレイピングプロセスに IP ローテーションを実装する方法について説明しました。また、Python でのスクレイピングプロセスの効果を維持するための実践的なコツもいくつかご紹介しました。
Bright Data は、Web スクレイピングソリューションのワンストッププラットフォームです。質の高い倫理的なプロキシ、Web スクレイピングブラウザ、スクレイピングボットの開発とプロセス用の IDE、すぐに使えるデータセット、スクレイピング中のプロキシのローテーションと管理を行うためのいくつかのツールを提供しています。





