

Node.jsを使ってウェブスクレイピングをしていると、ネット検閲にあったり、プロキシが低速だったりなどの問題に遭遇することがあります。そんな時に役立つのが、 Node Unblocker というツールです。
Node Unblockerは ウェブプロキシ ツールの一種で、これを使えばネット検閲を回避し、地域制限のあるコンテンツにアクセスできるようになります。Node Unblockerはオープンソースのツールで、データの高速中継、調整が用意な カスタマイズオプション、複数のプロトコルのサポートなど、様々な機能を備えています。Node Unblockerを使用すると、ネットの制限を回避し、本来はアクセスできないはずだったウェブサイトからもデータを効率的に収集できます。
この記事ではUnblockerをウェブスクレイピングで使うことの利点を含め、Node Unblockerについての全てを学んでいきます。また、Node Unblockerを使って地域制限のあるコンテンツをスクレイピングするために使えるプロキシプログラムを作成する方法も学びます。
Node Unblockerを使用することの利点
Node Unblockerは様々な特徴・機能を備えており、ウェブコンテンツへアクセスする際の障害を取り払える貴重なツールとなっています。Node Unblockerはオープンソースのソリューションであり、次のような特徴を持っています。
- 、クライアントと目的のウェブサイトの間の仲介役
- データを効率的に高速中継: Node Unblockerはバッファリングせずにクライアントにデータを配信できるという点で優れています。その結果、 Node Unblockerは現在利用可能なツールの中で、最も速いプロキシツールの1つとなっています。
- 使いやすい: Node Unblocker のユーザーインターフェースはとても使いやすく 、スキルレベルに関わらずどなたでも簡単に使用できます。Node Unblockerには実装がしやすくなる シンプルなAPI が用意されており、 既存のプロジェクトに簡単に取り入れるようになっています。
- 高度なカスタマイズが可能: Node Unblockerは、その時々に必要な要件に応じてプロキシ設定を柔軟にカスタマイズし、スクレイピングすることができます。例えばリクエストのヘッダーやレスポンス処理などのパラメーターを設定することで、スクレイピングプロセスの効率を上げつつ、自分に都合の良いものにカスタマイズできます。
- 複数のプロトコルをサポート: Node UnblockerはHTTP、HTTPS、WebSocketなどの様々なプロトコルをサポートしています。そのため、スクレイピングの際の多様なシナリオにシームレスに対応でき、開発者の都合の良い形で様々なデータの配信元と柔軟にデータのやりとりをすることができます。
Node Unblockerの使用準備
以上で、Unblockerの持つ特徴を全て学ぶことができました。では、さっそく実際に使ってみましょう。まずはシステムに Node.js と npm がインストールされていることを確認してください。また、プロジェクトをテストするためのウェブブラウザと、プロジェクトをホストするための無料の Renderアカウント も用意してください。
以上の準備ができたら、ウェブプロキシを作成していきます。まずは node-unblocker-proxyという名前のフォルダを作成してから、それをターミナルで開き、次のコマンドを実行して新しいNode.jsプロジェクトを作成します。
npm init -y
その後、次のコマンドを実行して必要な依存関係をインストールします。
npm install express unblocker
Express とはウェブサーバーの構築に使うウェブアプリケーションフレームワークです。 また、node-unblocker とはウェブプロキシを作成する際に役立つnpmパッケージです。
プロキシ機能を実装するためのスクリプトを作成する
すべての依存関係がインストールできたら、ウェブプロキシ用のスクリプトを実装していきます。
プロジェクトのルートフォルダに index.js ファイルを作成し、次のコードを貼り付けてください:
// import required dependencies
const express = require("express");
const Unblocker = require("unblocker");
// create an express app instance
const app = express();
// create a new Unblocker instance
const unblocker = new Unblocker({ prefix: "/proxy/" });
// set the port
const port = 3000;
// add the unblocker middleware to the Express application
app.use(unblocker);
// listen on specified port
app.listen(port).on("upgrade", unblocker.onUpgrade);
console.log(`proxy running on http://localhost:${port}/proxy/`);
このコードでは、必要な依存関係をインポートし、 Express アプリのインスタンスを作成しています。その後、新しい Node Unblocker のインスタンスを作成します。Node Unblockerのインスタンスを通して、様々な 設定が使えるようになります。ここでは、 prefix オプションのみを設定しています。prefixオプションではプロキシを使う際にURLの始めの部分に入れるパスを指定します。
Node UnblockerにはExpressと互換のあるAPIが用意されているため、簡単にExpress
アプリケーションに統合できます。ここでは、Expressインスタンスの use () メソッドを呼び出し、それに Node Unblocker のインスタンスを渡しています。これでNode Unblockerが使えるようになりました。次に listen () メソッドを使用し、Expressアプリケーションを起動させます。 .on ("upgrade", unblocker.onUpgrade) の部分は、WebSocket接続がUnblockerによって正しく処理されるようにするためのものです。
ローカル環境でプロキシをテスト
実装したプロキシをローカルでテストするには、ターミナルで次のコマンドを実行してください。
node index.js
プロキシ経由で行われる各リクエストの詳細情報を表示させたい場合は、
DEBUG=unblocker:* node index.jsコマンドを使用してください。
次に適当なURLを見つけ、そのプレフィックスとして localhost: 3000/proxy/ (例、 localhost/proxy/https://brightdata.com/)を付けて、ウェブブラウザで開きます。
Bright Data のホームページが表示されるはずです。ブラウザの ネットワーク タブから検証すると、すべてのリクエストがプロキシを経由していることがわかります。 ネットワーク タブの ドメイン 列をご覧ください:

プロキシをRenderにデプロイ
プロキシの正常な挙動が確認できたので、次はいよいよデプロイしていきます。その前に、プロジェクトルートフォルダにある package.json ファイルを開き、 スクリプトの キーと値のペアを次のように変更してください。
"scripts": {
"start": "node index"
}
こうすることで、Render上でExpressウェブサーバーを起動させるためのコマンドが実行できるようになります。
ウェブプロキシをデプロイし、プロキシプロジェクトをGitHubのリポジトリに アップロード します。次に、 Renderアカウント にサインインしてください:
New + ボタンをクリックし、 Web Serviceを選択します:

Connect ボタンを選んで、Renderとプロキシプロジェクトのリポジトリをつなげます。Renderがリポジトリにアクセスできない場合、 アカウント の設定を調節する必要があります。この設定が必要なのは、Renderが特定のGitHubレポジトリにアクセスできるように設定していない場合のみです:
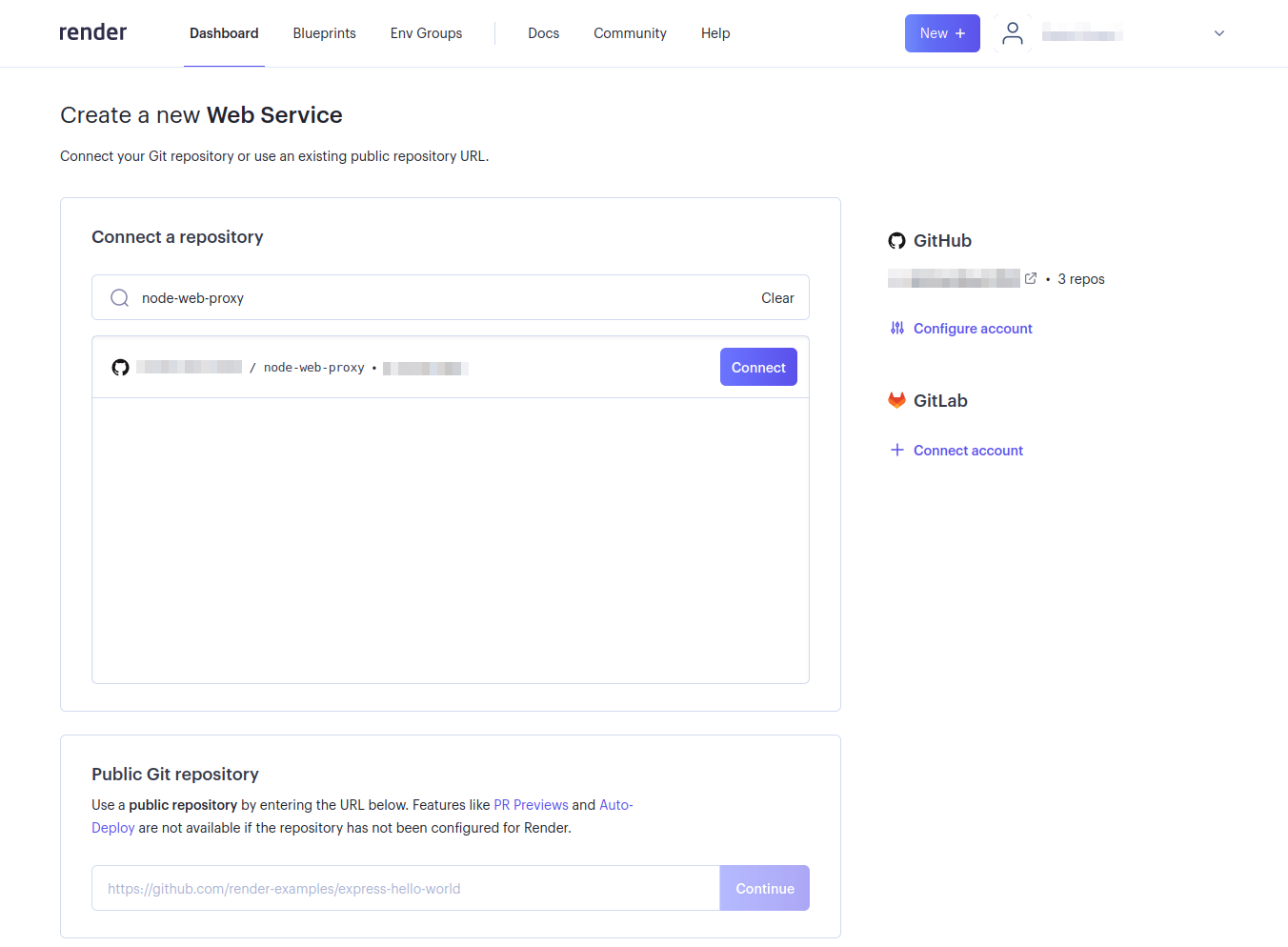
ウェブサービスの使用に必要な詳細情報を入力し、ページの下部の Create Web Service を選択します:

Yarnを使う場合は起動コマンドをそのままにしてください。npmを使う場合は
npm run startに変更することもできます。
ウェブプロキシが正常にデプロイされたら、次はテストを行います。適当なURLを使用し、先ほどデプロイした <DEPLOYED-APP-URL>/proxy/ をプレフィックスとして付けます。(例、 https://node-web-proxy-gvn6.onrender.com/proxy/https://brightdata.com/)ウェブブラウザで開いてみます。
ブラウザの [ネットワーク] タブを調べると、すべてのリクエストが先ほどデプロイしたプロキシを経由していることがわかります:

プロキシ経由でスクレイピングリクエストを送る
すべてのリクエストが先ほどデプロイしたプロキシを経由していることが確認できたら、次にスクレイピングリクエストを送ります。このチュートリアルでは Puppeteer ライブラリを使用しますが、 Cheerio や Nightmareなど、他のテストライブラリを使うこともできます。
Puppeteerをインストールしていない場合は、 npm i puppeteerを実行して、Puppeteerをインストールしてください。次に、プロジェクトのルートフォルダに scrape.js ファイルを作成し、次のコードを追加します。
// import puppeteer
const puppeteer = require("puppeteer");
const scrapeData = async () => {
// launch the browser
const browser = await puppeteer.launch({
headless: false,
});
// open a new page and navigate to the defined URL
const page = await browser.newPage();
await page.goto("<DEPLOYED-APP-URL>/proxy/https://brightdata.com/blog");
// get the content of the webpage
const data = await page.evaluate(() => {
// variable to hold all the posts data
let blogData = [];
// extract all elements with the specified class
const posts = document.querySelectorAll(".post_item");
// loop through the posts object, extract required data and push it to the blogData array
for (const post of posts) {
const title = post.querySelector("h5").textContent;
const link = post.href;
const author = post
.querySelector(".author_box")
.querySelector(".author_box__details")
.querySelector("div").textContent;
const article = { title, link, author };
blogData.push(article);
}
return blogData;
});
// log the data to the console
console.log(data);
// close the browser instance
await browser.close();
};
// call the scrapeData function
scrapeData();
その際、忘れずに
<DEPLOYED-APP-URL>の部分をRenderにデプロイしたアプリのURLに書き換えておきましょう。
このサンプルコードはPuppeteerの使用準備を行い、 Bright Dataのブログの記事データを収集するためのものです。Bright Dataのウェブサイトに掲載されているブログ記事のカードは全て .post_itemというクラス内に入れられています。このコードはすべての投稿を取得します。その過程では、 posts オブジェクトをループ処理し、各投稿のタイトル、リンク、作成者を抽出してから、そのデータを BlogData 配列に入れ込み、最後にその全てをコンソールに表示させるという手順が取られています。
Node Unblockerに最適なプロキシを選ぶためには
Node Unblockerでプロキシを使う際は、プロジェクトの要件や起こりうる問題に対応できるプロキシサービスを選ぶ必要があります。プロキシサービスを選ぶ際は次のようなポイントに注目してください。
- パフォーマンスと信頼性:シームレスにデータへアクセスし、効率よくウェブスクレイピングを行うためには、通信速度が速く、可用性が高いプロキシサービスを使う必要があります。
- 地域カバー率:幅広い地域をカバーしているプロキシサービスを選びましょう。そうすることで、地域制限を回避したり、特定地域にローカライズされたコンテンツにアクセスできます。
- IPローテーション:IPローテーションを提供するプロキシサービスを使うことで、ウェブサイトにブロックされるリスクを減らせます。IPローテーションとはリクエストのたびに使うIPを変えるサービスのことで、これを利用することでブロックを回避しやすくなります。
- セキュリティプロトコル:特に機密情報を扱う場合は、SSL暗号化などの強固なセキュリティ対策を提供するサービスを利用することで、データの整合性とプライバシーを保護しやすくなります。
- スケーラビリティ:スクレイピングのニーズが高まった場合に、それに合わせてプロキシサービスをスケールアップさせられるかどうかを考えてみましょう。リソースを柔軟にスケールアップさせられるサービスでなければ、スクレイピング作業の規模と複雑さが増した場合に対応できません。
- サポートとドキュメント:特に複雑な構成で使用する場合、包括的なサポートと詳細なドキュメントがあれば、Node Unblockerの統合作業が大幅にやりやすくなります。
これらのポイントを踏まえてサービスを注意深く比較することで、その時点で必要なことだけでなく、将来的な成長やスクレイピング作業の変化にも対応できるプロキシサービスを選ぶことができます。
まとめ
Node UnblockerはNode.jsでウェブスクレイピングをする際に有用なツールであり、これを使うことでネット検閲を回避し、地域制限のあるコンテンツにアクセスできるようになります。Node Unblockerはとても優秀なウェブスクレイピングツールで、インターフェイスがわかりやすく、豊富なカスタマイズオプションが用意されていて、さらに複数のプロトコルがサポートされています。この記事ではNode Unblockerとは何か、それがウェブスクレイピングにどう役立つのか、そしてその使い方などを学びました。
データ中心の現代社会において、価値のある情報を収集し、それを分析するためにはウェブスクレイピングが不可欠です。一方で、ウェブスクレイピングではIPブロッキングや通信頻度制限、地域制限などが原因で、データ収集作業が妨げられ、重要なデータの取得が失敗してしまうことがよくあります。
Bright Data はこういった課題に対処する包括的なプラットフォームを提供します。Bright Dataは住宅用IPやISP登録済みIP、データセンターIP、モバイルIPを含んだ広大なネットワークを保有しており、このネットワークを利用することで、世界中の様々なIPアドレスを経由してスクレイピング時のリクエストをルーティングできるようになります。プロキシを使うことで匿名性が保証されるだけでなく、地域制限のあるコンテンツにアクセスでき、データ収集の妨げとなる障害を取り除けます。
どのBright Dataプロキシが必要かわからない場合今すぐ登録して、当社のデータ専門家に相談し、ニーズにあったソリューションを探しましょう。





