

ウェブスクレイピングではしばしば、アンチボット機構を利用したり、Puppeteerのようなブラウザ自動化ツールを使って動的コンテンツをロードしたり、IPブロックを避けるためにプロキシローテーションを利用したり、CAPTCHAを解いたりする必要がある。これらの戦略を用いても、安定したセッションのスケーリングと維持は困難なままです。
この記事では、従来のプロキシベースのスクレイピングからBright Data Scraping Browserに移行する方法をご紹介します。プロキシ管理とスケーリングを自動化し、開発コストとメンテナンスを削減する方法を学びます。両方の方法を比較し、設定、パフォーマンス、スケーラビリティ、複雑さについて説明します。
注意:この記事の例は教育目的です。データをスクレイピングする前に、必ず対象となるウェブサイトの利用規約を確認し、関連法規を遵守してください。
前提条件
チュートリアルを始める前に、以下の前提条件が揃っていることを確認してください:
- Node.js
- ビジュアル・スタジオ・コード
- スクレイピング・ブラウザを使用するための無料のブライト・データ・アカウント
コードを保存するための新しいNode.jsプロジェクト・フォルダーを作成することから始めます。
次に、ターミナルかシェルを開き、以下のコマンドを使って新しいディレクトリを作成する:
mkdir scraping-tutorialrncd scraping-tutorial
新しい Node.js プロジェクトを初期化します:
npm init -y
yフラグはすべての質問に自動的にyesと答え、デフォルト設定のpackage.jsonファイルを作成する。
プロキシ・ベース・ウェブ・スクレイピング
典型的なプロキシベースのアプローチでは、Puppeteerのようなブラウザ自動化ツールを使ってターゲットドメインと対話し、ダイナミックコンテンツをロードし、データを抽出する。その際、IPバンを回避し匿名性を維持するためにプロキシを統合する。
早速、Puppeteerを使って、プロキシを使ってeコマースのウェブサイトからデータをスクレイピングするウェブスクレイピングスクリプトを作ってみましょう。
Puppeteerを使ってウェブスクレイピングスクリプトを作成する
まずPuppeteerをインストールする:
npm install puppeteer
それから、スクレイピング・チュートリアル・フォルダー内にproxy-scraper.jsというファイル(好きな名前でOK)を作成し、以下のコードを追加する:
const puppeteer = require(u0022puppeteeru0022);rnrn(async () =u0026gt; {rn // Launch a headless browserrn const browser = await puppeteer.launch({rn headless: true,rn });rn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(books); // Print the collected datarnrn await browser.close();rn})();rn
このスクリプトは、Puppeteerを使ってBooks to Scrapeウェブサイトの最初の5ページから本のタイトルと価格をスクレイピングする。ヘッドレスブラウザを起動し、新しいページを開き、各カタログページをナビゲートします。
各ページについて、スクリプトはpage.evaluate()内でDOMセレクタを使用して本のタイトルと価格を抽出し、データを配列に格納する。すべてのページが処理されると、データがコンソールに出力され、ブラウザが閉じられます。このアプローチは、ページ分割されたウェブサイトから効率的にデータを抽出します。
以下のコマンドを使ってコードをテストし、実行する:
node proxy-scraper.js出力はこのようになるはずだ:
Navigating to: https://books.toscrape.com/catalogue/page-1.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-2.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-3.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-4.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-5.htmlrn[rn { title: 'A Light in the Attic', price: '£51.77' },rn { title: 'Tipping the Velvet', price: '£53.74' },rn { title: 'Soumission', price: '£50.10' },rn { title: 'Sharp Objects', price: '£47.82' },rn { title: 'Sapiens: A Brief History of Humankind', price: '£54.23' },rn { title: 'The Requiem Red', price: '£22.65' },rn…output omitted…rn {rn title: 'In the Country We Love: My Family Divided',rn price: '£22.00'rn }rn]
プロキシの設定
プロキシは、リクエストを分割して追跡不可能にするために、スクレイピングの設定によく使われる。一般的なアプローチは、プロキシのプールを維持し、動的にそれらをローテートすることです。
お望みなら、プロキシを配列に入れるか、別のファイルに保存してください:
const proxies = [rn u0022proxy1.example.com:portu0022, rn u0022proxy2.example.com:portu0022rn // Add more proxies herern];
プロキシ・ローテーション・ロジックの活用
ブラウザを起動するたびにプロキシ配列をローテートするロジックでコードを拡張してみよう。proxy-scraper.jsを更新して、以下のコードを含める:
const puppeteer = require(u0022puppeteeru0022);rnrnconst proxies = [rn u0022proxy1.example.com:portu0022, rn u0022proxy2.example.com:portu0022rn // Add more proxies herern];rnrn(async () =u0026gt; {rn // Choose a random proxyrn const randomProxy =rn proxies[Math.floor(Math.random() * proxies.length)];rnrn // Launch Puppeteer with proxyrn const browser = await puppeteer.launch({rn headless: true,rn args: [rn `u002du002dproxy-server=http=${randomProxy}`,rn u0022u002du002dno-sandboxu0022,rn u0022u002du002ddisable-setuid-sandboxu0022,rn u0022u002du002dignore-certificate-errorsu0022,rn ],rn });rnrn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(`Using proxy: ${randomProxy}`);rn console.log(books); // Print the collected datarnrn await browser.close();rn})();rn
注:プロキシの回転を手動で行う代わりに、luminati-proxyのようなライブラリを使って処理を自動化することができます。
このコードでは、-proxy-server=${randomProxy}オプションを使用して、プロキシ一覧からランダムなプロキシが選択され、Puppeteerに適用されます。検出を避けるために、ランダムなユーザーエージェント文字列も割り当てられる。その後、スクレイピングロジックが繰り返され、製品データのスクレイピングに使用されたプロキシが記録されます。
もう一度コードを実行すると、前のような出力が表示されるが、使用されたプロキシが追加されているはずだ:
Navigating to: https://books.toscrape.com/catalogue/page-1.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-2.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-3.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-4.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-5.htmlrnUsing proxy: 115.147.63.59:8081rn…output omitted…
プロキシ・ベース・スクレイピングの課題
プロキシベースのアプローチは多くのユースケースで有効だが、以下のような課題に直面する可能性がある:
- 頻繁にブロックされる:プロキシは、サイトが厳しいアンチボット検出を持っている場合、ブロックされる可能性があります。
- パフォーマンスのオーバーヘッド:プロキシをローテーションし、リクエストを再試行することで、データ収集パイプラインが遅くなります。
- 複雑なスケーラビリティ:最適なパフォーマンスと可用性のために大規模なプロキシプールを管理し、ローテーションすることは複雑である。ロードバランシング、プロキシの使いすぎの防止、クールダウン期間、リアルタイムでの障害処理が必要です。ブラックリストに登録されたIPやパフォーマンスの低いIPを継続的に監視し、交換しながら、システムは検出を回避しなければならないため、同時リクエストによって課題は大きくなります。
- ブラウザのメンテナンス:ブラウザのメンテナンスは、技術的に困難であり、リソースを大量に消費します。実際のユーザー行動を模倣し、高度なボット対策コントロールを回避するために、ブラウザのフィンガープリント(クッキー、ヘッダー、その他の識別属性)を継続的に更新し、処理する必要があります。
- クラウド・ブラウザのオーバーヘッド:クラウドベースのブラウザは、リソース要件の増加や複雑なインフラ制御によって運用上のオーバーヘッドを追加し、運用コストの上昇を招きます。安定したパフォーマンスのためにブラウザのインスタンスをスケーリングすることは、プロセスをさらに複雑にします。
ブライトデータスクレイピングブラウザによるDynamicScraping
このような課題を解決するために、Bright Data Scraping BrowserのようなシングルAPIソリューションを使用することができます。操作を簡素化し、手作業によるプロキシのローテーションや複雑なブラウザのセットアップを不要にし、多くの場合、データ検索の成功率を高めます。
Bright Dataアカウントの設定
開始するには、Bright Dataアカウントにログインし、Proxies & Scrapingに移動し、Scraping Browserにスクロールダウンし、Get Startedをクリックします:
デフォルト設定のまま、Addをクリックして新しいScraping Browserインスタンスを作成する:
スクレイピング・ブラウザのインスタンスを作成したら、PuppeteerのURLをメモしておこう:
ブライト・データ・スクレイピング・ブラウザを使うためにコードを調整する
では、回転プロキシを使用する代わりに、Bright Data Scraping Browserのエンドポイントに直接接続するようにコードを調整してみましょう。
brightdata-scraper.jsという新しいファイルを作成し、以下のコードを追加する:
const puppeteer = require(u0022puppeteeru0022);rnrn(async () =u0026gt; {rn // Choose a random proxyrn const SBR_WS_ENDPOINT = u0022YOUR_BRIGHT_DATA_WS_ENDPOINTu0022rnrn // Launch Puppeteer with proxyrn const browser = await puppeteer.connect({rn browserWSEndpoint: SBR_WS_ENDPOINT,rn });rnrn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(books); // Print the collected datarnrn await browser.close();rn})();
YOUR_BRIGHT_DATA_WS_ENDPOINTを前のステップで取得したURLに置き換えてください。
このコードは前のコードと似ているが、プロキシのリストを持ち、異なるプロキシ間を行き来する代わりに、Bright Dataのエンドポイントに直接接続する。
以下のコードを実行する:
node brightdata-scraper.js
出力は以前と同じですが、プロキシを手動で回転させたり、ユーザーエージェントを設定する必要はありません。Bright Data Scraping Browserは、プロキシのローテーションからCAPTCHAのバイパスまで、すべてを処理し、中断のないデータスクレイピングを保証します。
コードをエクスプレス・エンドポイントに変える
Bright Data Scraping Browserをより大きなアプリケーションに統合したい場合は、Expressエンドポイントとして公開することを検討してください。
まずExpressをインストールする:
npm install express
server.jsというファイルを作成し、以下のコードを追加する:
const express = require(u0022expressu0022);rnconst puppeteer = require(u0022puppeteeru0022);rnrnconst app = express();rnconst PORT = 3000;rnrn// Needed to parse JSON bodies:rnapp.use(express.json());rnrn// Your Bright Data Scraping Browser WebSocket endpointrnconst SBR_WS_ENDPOINT =rn u0022wss://brd-customer-hl_264b448a-zone-scraping_browser2:[email protected]:9222u0022;rnrn/**rn POST /scraperrn Body example:rn {rn u0022baseUrlu0022: u0022https://books.toscrape.com/catalogue/page-u0022rn }rn*/rnapp.post(u0022/scrapeu0022, async (req, res) =u0026gt; {rn const { baseUrl } = req.body;rnrn if (!baseUrl) {rn return res.status(400).json({rn success: false,rn error: 'Missing u0022baseUrlu0022 in request body.',rn });rn }rnrn try {rn // Connect to the existing Bright Data (Luminati) Scraping Browserrn const browser = await puppeteer.connect({rn browserWSEndpoint: SBR_WS_ENDPOINT,rn });rnrn const page = await browser.newPage();rn const books = [];rnrn // Example scraping 5 pages of the base URLrn for (let i = 1; i {rn const data = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn const title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn const price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn data.push({ title, price });rn });rn return data;rn });rnrn books.push(...pageBooks);rn }rnrn // Close the browser connectionrn await browser.close();rnrn // Return JSON with the scraped datarn return res.json({rn success: true,rn books,rn });rn } catch (error) {rn console.error(u0022Scraping error:u0022, error);rn return res.status(500).json({rn success: false,rn error: error.message,rn });rn }rn});rnrn// Start the Express serverrnapp.listen(PORT, () =u0026gt; {rn console.log(`Server is listening on http://localhost:${PORT}`);rn});
このコードでは、Expressアプリを初期化し、JSONペイロードを受け入れ、POST /scrapeルートを定義します。クライアントはbaseUrlを含むJSONボディを送信し、そのJSONボディはターゲットURLと共にBright Data Scraping Browserのエンドポイントに転送されます。
新しいExpressサーバーを実行します:
node server.js
エンドポイントをテストするには、Postmanのようなツール(または他の任意のRESTクライアント)を使うか、ターミナルやシェルからcurlを使う:
curl -X POST http://localhost/scrape rn-H 'Content-Type: application/json' rn-d '{u0022baseUrlu0022: u0022https://books.toscrape.com/catalogue/page-u0022}'rn
出力はこのようになるはずだ:
{rn u0022successu0022: true,rn u0022booksu0022: [rn {rn u0022titleu0022: u0022A Light in the Atticu0022,rn u0022priceu0022: u0022£51.77u0022rn },rn {rn u0022titleu0022: u0022Tipping the Velvetu0022,rn u0022priceu0022: u0022£53.74u0022rn },rn {rn u0022titleu0022: u0022Soumissionu0022,rn u0022priceu0022: u0022£50.10u0022rn },rn {rn u0022titleu0022: u0022Sharp Objectsu0022,rn u0022priceu0022: u0022£47.82u0022rn },rn {rn u0022titleu0022: u0022Sapiens: A Brief History of Humankindu0022,rn u0022priceu0022: u0022£54.23u0022rn },rn {rn u0022titleu0022: u0022The Requiem Redu0022,rn u0022priceu0022: u0022£22.65u0022rn },rn {rn u0022titleu0022: u0022The Dirty Little Secrets of Getting Your Dream Jobu0022,rn u0022priceu0022: u0022£33.34u0022rn },rn {rn u0022titleu0022: u0022The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhullu0022,rn u0022priceu0022: u0022£17.93u0022rn },rn rn ... output omitted...rn rn {rn u0022titleu0022: u0022Judo: Seven Steps to Black Belt (an Introductory Guide for Beginners)u0022,rn u0022priceu0022: u0022£53.90u0022rn },rn {rn u0022titleu0022: u0022Joinu0022,rn u0022priceu0022: u0022£35.67u0022rn },rn {rn u0022titleu0022: u0022In the Country We Love: My Family Dividedu0022,rn u0022priceu0022: u0022£22.00u0022rn }rn ]rn}
以下は、手動セットアップ(回転プロキシ)とBright Data Scraping Browserのアプローチの対比を示す図です:
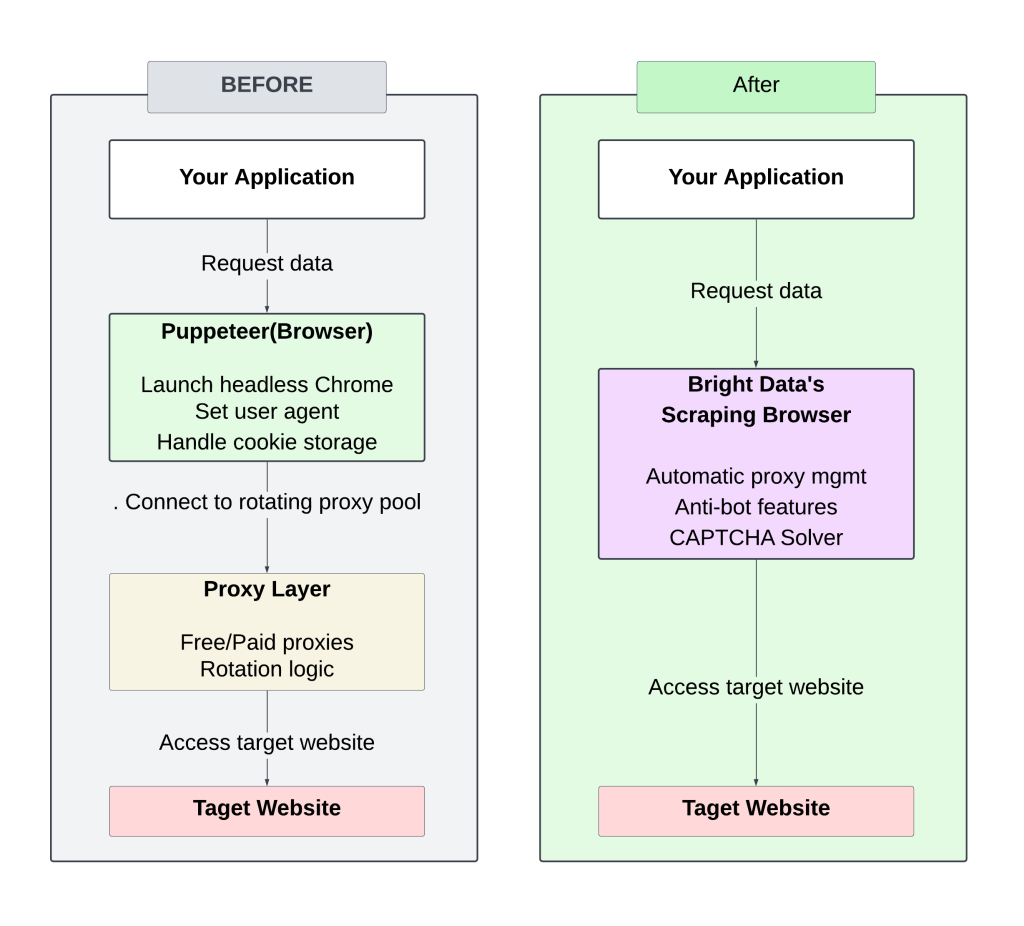
手動でローテーションするプロキシを管理するには、常に注意を払い、チューニングする必要があり、その結果、頻繁にブロックが発生し、スケーラビリティが制限される。
Bright Data Scraping Browserを使用することで、プロキシやヘッダーを管理する必要がなくなり、プロセスが効率化されます。統合されたアンチボット戦略が成功率を高め、ブロックされたりフラグを立てられたりする可能性を低くします。
このチュートリアルのコードはすべて、このGitHubリポジトリで公開されている。
ROIの計算
手動プロキシベースのスクレイピング設定からBright Data Scraping Browserに切り替えることで、開発時間とコストを大幅に削減できます。
伝統的なセットアップ
毎日ニュースサイトをスクレイピングするには、以下のことが必要である:
- 初期開発:~50時間(100米ドル/時間で5,000米ドル)
- 継続的なメンテナンス:コードの更新、インフラ、スケーリング、プロキシ管理で月10時間程度(1,000米ドル
- プロキシ/IPコスト:~250米ドル/月(IPのニーズによって異なる)
推定月額費用合計:~1,250米ドル
ブライト・データ・スクレイピング・ブラウザのセットアップ
- 開発時間:5~10時間(1,000米ドル)
- メンテナンス:~2~4時間/月(200米ドル)
- プロキシやインフラ管理が不要
- ブライトデータのサービス費用
- トラフィック使用量:8.40米ドル/GB(例:30GB/月=252米ドル)
推定月額費用合計:~450米ドル
プロキシ管理とBright Data Scraping Browserのスケーリングを自動化することで、初期開発コストと継続的なメンテナンスの両方を削減し、大規模なデータスクレイピングをより効率的でコスト効果の高いものにします。
結論
従来のプロキシベースのウェブスクレイピング設定からBright Data Scraping Browserに移行することで、プロキシローテーションや手動でのアンチボット処理の手間を省くことができます。
HTMLを取得するだけでなく、Bright Dataはデータ抽出を合理化するための追加ツールも提供している:
- データ抽出の整理整頓に役立つウェブスクレイパー
- より厳しいサイトをスクレイピングするWeb Unlocker API
- データセットにより、収集済みの構造化データにアクセス可能
これらのソリューションは、スクレイピング・プロセスを簡素化し、作業負荷を軽減し、スケーラビリティを向上させます。





