

データセットとデータベースは、データ処理において頻繁に耳にする二つの用語です。発音は似ていますが、それぞれ明確な特徴を持ち、異なる目的を果たします。本記事では、データセットとデータベースの主要な相違点に焦点を当て、構造、データ型、その他の様々な特徴を探求し、特定の要件に最適な選択肢を判断するための情報を提供します。
データセットとは?
データセットとは、特定の構造(通常は行と列で構成)で整理されたデータの集合体です。各行はインスタンス(観測値)を表し、各列は変数(特徴量)を表します。データセットは、研究、ビジネス分析、機械学習、データサイエンスなど様々な分野における基礎的な構成要素です。
データセットの特徴
- 構造:データセットは表形式で構造化され、行はインスタンスまたは観測値を表し、列は変数または特徴量を表します。
- データ型:データセットには数値データ(例:整数、浮動小数点数)、カテゴリカルデータ(例:文字列、ラベル)、時系列データ(例:日付、タイムスタンプ)など、異なる種類のデータが含まれます。
- 数値データ:測定値、カウント、スコアなどの定量的値を表します。
- カテゴリデータ:ラベル、カテゴリ、名前などの非数値値で構成されます。
- テキストデータ: 製品説明、顧客レビュー、ソーシャルメディア投稿などのテキストデータを含みます。
- 地理空間データ:座標、住所、地図データなどの地理情報を表します。
- 時系列データ:株価、気象観測、センサー測定値など、時間経過とともに収集されたデータポイントを含む。
- サイズ:アプリケーションや収集されるデータ量に応じて、データセットのサイズは数レコードから数十億レコードまで様々です。
- 品質:データセットの品質は、正確な分析と信頼性の高い結果を得るために極めて重要です。高品質なデータセットは完全性・一貫性を備え、エラーや矛盾を含みません。
データベースとは?
データベースとは、データ保存、検索、情報管理を効率化するために構造化されたデータの集合体です。データベースは、データの完全性、一貫性、セキュリティを確保しつつ、大規模なデータ量を処理できるように設計されています。
データベースの種類
データベースにはいくつかの種類があり、それぞれ特定のニーズを満たし、異なるタイプのデータやアプリケーションのパフォーマンスを最適化するよう設計されています。
- MySQL
- Redis
- Cassandra
データベースのコア機能と必須機能
データベースには、様々なアプリケーションにわたる大量のデータを管理・処理するための様々な主要な機能と特徴が備わっています。
- データ保存と操作:データベースは、通常テーブルやコレクションを用いて、構造化された方法でデータを保存・整理するための中央リポジトリを提供します。さらに、様々なインターフェースやプログラミング言語を通じて、データの挿入、更新、削除、クエリなどの操作を実行することを可能にします。
- データ整合性とアクセス制御:データベースはデータ整合性を維持するためのルールや制約を適用し、不整合を防ぎデータの正確性を保証します。加えて、包括的なデータアクセス制御を提供し、特定のデータを読み取り、変更、削除できるのは許可されたユーザーやアプリケーションのみであることを保証します。
- スケーラビリティ:データベースの主要な利点の一つはスケーラビリティです。現代のデータベースは、増大するデータ需要に対応するため、水平方向(サーバーの追加)または垂直方向(ハードウェアリソースのアップグレード)に拡張できるよう設計されています。このスケーラビリティは、eコマースプラットフォーム、ソーシャルメディアネットワーク、IoTシステムなど、膨大な量のデータを生成または処理するアプリケーションにとって不可欠です。
- セキュリティ機能: データベースはまた、機密データを不正アクセス、改ざん、侵害から保護するためのセキュリティ機能を優先します。これらのセキュリティ対策には以下が含まれます:
- 認証とアクセス制御:データベースは、許可された個人またはアプリケーションのみがデータにアクセスし操作できるように、ユーザー認証と認可メカニズムを実装します。
- 暗号化:機密データは保存時(保存データ)および転送時(送信中のデータ)に暗号化され、不正アクセスや傍受を防止します。
- 監査とロギング:ユーザー活動を記録する監査証跡とログを維持し、セキュリティインシデント発生時の監視とフォレンジック分析を可能にします。
- バックアップと復旧:ハードウェア障害、災害、人的ミスから保護するためのバックアップと復旧メカニズムを提供します。
データセットとデータベースの主な違い
データセットとデータベースの主な相違点は以下の通りです:
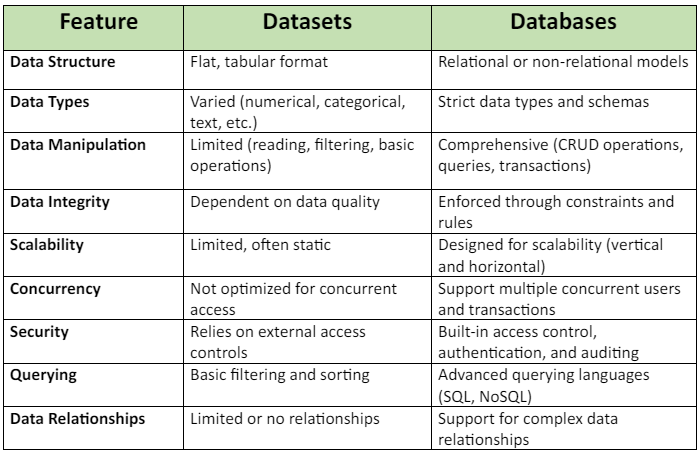
- データ構造:データセットは通常、行と列からなるフラットな表形式構造を持つ一方、データベースはリレーショナル(関係性を持つテーブル)やノンリレーショナル(ドキュメント、キーバリューペア、グラフ)など様々なモデルでデータを保存できる。
- データ型:データセットは数値、カテゴリ、テキストなど様々なデータ型を含めることができますが、データベースはデータ整合性を確保するため厳格なデータ型とスキーマを強制することが多いです。
- データ操作:データセットは読み取り、フィルタリング、基本操作など限定的な操作機能を提供するのに対し、データベースはCRUD操作や高度なクエリ機能を通じて包括的なデータ操作を実現します。
- データ整合性:データセットではデータ整合性はデータ自体の品質と一貫性に大きく依存しますが、データベースは制約、ルール、トランザクション管理を通じてデータ整合性を強制します。
- スケーラビリティ:データセットは 静的であるか、スケーラビリティが限定的であることが多い。一方、データベースは大規模なデータ量を処理するために、垂直方向(リソースの追加)および水平方向(複数のノードへのデータ分散)のスケーリングを可能にするように設計されている。
- 同時実行性:データセットは複数ユーザーやアプリケーションによる同時アクセスには最適化されていませんが、データベースはトランザクション管理やロック機構を通じて同時アクセスをサポートします。
- セキュリティ:データセットは 外部アクセス制御やセキュリティ対策に依存するのに対し、データベースはアクセス制御、認証、暗号化、監査などの組み込みセキュリティ機能を備えています。
- クエリ処理:データセットは通常、基本的なフィルタリングやソート操作をサポートしますが、データベースはリレーショナルデータベース向けのSQL(構造化問い合わせ言語)やNoSQLデータベース固有のクエリ言語といった高度なクエリ言語を提供します。
- データの関係性:データセットは データ要素間の関係性を表現する機能が限定的または存在しないのに対し、データベースは1対1、1対多、多対多といった複雑なデータ関係性を扱うように設計されている。
データセットとデータベースには明確な違いがあるものの、様々なデータ処理や分析ワークフローにおいて相互補完的に機能します。データセットはデータベースへの入力ソースや中間データ表現として使用されることが多く、データベースは構造化データの管理・分析のための堅牢でスケーラブルなリポジトリとして機能します。
データセットとデータベースの選択
データセットとデータベースのどちらを使用するかを決定する際には、特定のニーズに基づいて以下の要素を考慮してください:
データセットを使用すべき場合
- データサイズ:メモリや単一ファイルに収まる比較的小規模で静的なデータ量の場合。
- データ分析:主な目的がデータ分析、探索、可視化である場合。
- 迅速なプロトタイピング:迅速なプロトタイピング、概念実証プロジェクト、またはアドホックな分析タスクには、データセットの設定や操作が容易な場合が多い。
- 単純なデータ構造:データが複雑な関係性や整合性制約のない、フラットな表形式構造の場合。
- 移植性:データセットは異なる環境やアプリケーション間で容易に共有・転送・統合できるため、共同作業やデータ交換に適している。
データベースを使用すべき場合:
- 大規模なデータ量:メモリ容量や単一ファイルを超える大量のデータを保存・管理する必要がある場合。データベースは増大するデータ量に対応し、拡張できるように設計されています。
- データ整合性と一貫性:制約、ルール、トランザクション管理を通じてデータ整合性を強制します。
- 同時アクセスとトランザクション:複数のユーザーやアプリケーションが同時にデータにアクセスし変更する必要がある場合。
- 複雑なデータ関係:データに複雑な関係や階層構造(例:1対多、多対多)がある場合。
- クエリとレポート:データベースは、効率的なデータ取得、フィルタリング、集計のための強力なクエリ言語(例:SQL)とレポートツールを提供します。
データセットとデータベースの選択は必ずしも排他的ではありません。実世界のシナリオでは、データセットとデータベースを組み合わせることが可能です。データセットは入力ソースや中間表現として機能し、データベースは堅牢でスケーラブルなデータリポジトリとして作用します。
最終的には、データサイズ、複雑性、整合性要件、同時実行性、セキュリティ、スケーラビリティといった具体的な要件に基づいて判断すべきです。ユースケースを慎重に評価し、アプリケーションにとって最も重要な機能や能力を優先することが不可欠です。
結論
データセットとデータベースは、データ管理においてそれぞれ異なる目的と特定のニーズに対応し、重要な役割を果たします。データセットは主にデータ分析や研究に使用され、データベースは大量のデータを効率的に保存、検索、管理するために使用されます。
ただし、最適な選択肢を選定するには、この2つの概念の違いを理解することが不可欠です。決定は、データサイズ、複雑さ、整合性要件、同時実行性、セキュリティ、スケーラビリティといった具体的な要件に基づいて行うべきです。ユースケースを慎重に評価し、アプリケーションやプロジェクトにとって最も重要な機能や能力を優先することが重要です。
研究、分析、機械学習プロジェクト向けの高品質なデータセットをお探しなら、Bright Dataのデータセットマーケットプレイスをご利用ください。様々な業界や分野にわたる多様なデータセットを提供しており、無料サンプルや、登録後に必要なデータセットを閲覧・購入できるユーザーフレンドリーな環境を備えています。





