この詳細なガイドでは、以下のトピックを扱います。
- C#ウェブスクレイピングに最適なライブラリ
- 前提条件
- C#で静的コンテンツのウェブサイトをスクレイピングする
- C#で動的コンテンツのウェブサイトをスクレイピングする
- スクレイピングしたデータの活用方法
- プロキシを使ったデータプライバシー
- まとめ
C#ウェブスクレイピングに最適なライブラリ
ウェブスクレイピングは、適切なツールを採用することで容易になります。C#向けのNuGetスクレイピングライブラリの中で最も優れているものを見てみましょう。
HtmlAgilityPack:最も人気のあるC#スクレイパーライブラリ。HtmlAgilityPackは、ウェブページをダウンロードし、HTMLコンテンツを解析し、HTML要素を選択し、ウェブページからデータをスクレイピングする機能を提供します。HttpClient:最も人気のあるC# HTTPクライアント。HttpClientは、HTTPリクエストを簡単かつ非同期に実行できるため、ウェブクローリングに特に役立ちます。Selenium WebDriverは、複数のプログラミング言語をサポートするライブラリで、ウェブアプリの自動化テストを記述できます。また、ウェブスクレイピングの目的でも使用できます。Puppeteer Sharpは、PuppeteerのC#移植版です。Puppeteer Sharpは、ヘッドレスブラウザ機能を提供し、動的コンテンツページのスクレイピングを可能にします。
このチュートリアルでは、HtmlAgilityPackとSeleniumを使用してC#でウェブスクレイピングを実行する方法を見てゆきます。
C#でのウェブスクレイピングの前提条件
C#ウェブスクレイパーの最初のコード行を書く前に、いくつかの前提条件を満たしておく必要があります。
- Visual Studio:無料のVisual Studio 2022 Communityエディションで十分です。
- .NET 6+:6以上のLTSバージョンであればどれでも構いません。
これらの要件のいずれかを満たしていない場合は、上記のリンクをクリックしてツールをダウンロードし、インストールウィザードに従ってセットアップを行ってください。
これで、Visual StudioでC#のウェブスクレイピングプロジェクトを作成する準備が整いました。
Visual Studioでプロジェクトを設定する
Visual Studioを開き、「新規プロジェクトの作成」オプションをクリックします。
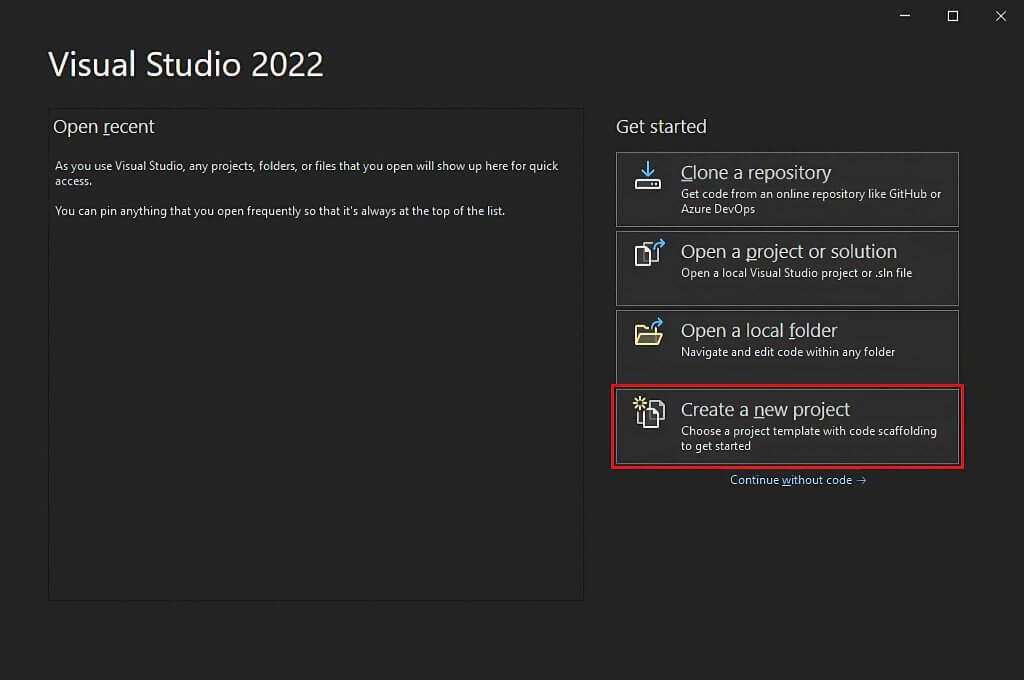
「新規プロジェクトの作成」ウィンドウで、ドロップダウンリストから「C#」を選択します。プログラミング言語を指定した後、「コンソールアプリ」テンプレートを選択し、「次へ」をクリックします。
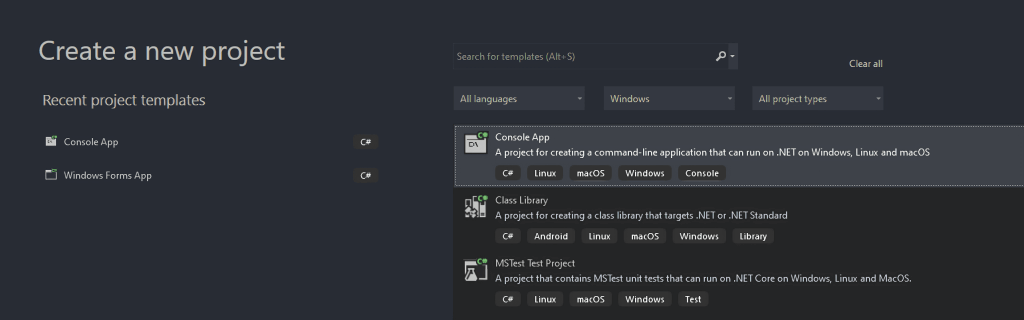
次に、プロジェクトをStaticWebScrapingという名前にして、「選択」をクリックし、.NETのバージョンを選択します。.NET 6.0をインストールした場合は、Visual Studioでそれが選択済みになっているはずです。
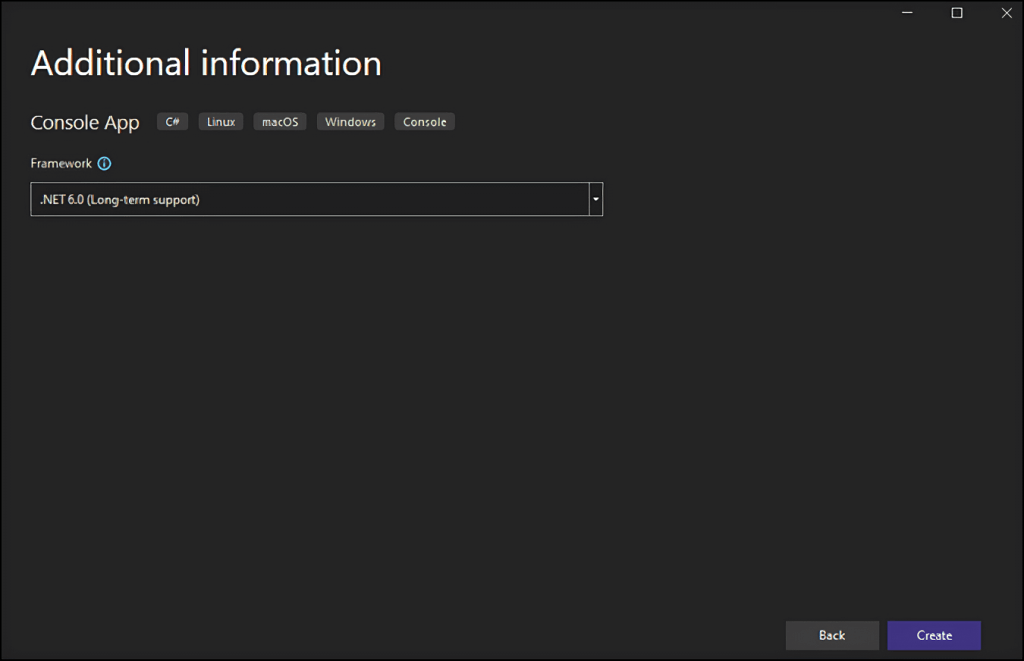
「作成」ボタンをクリックして、C#ウェブスクレイピングプロジェクトを初期化します。Visual Studioで、App.csファイルを含むStaticWebScrapingフォルダが初期化されます。このファイルには、C#でのウェブスクレイピングロジックが格納されます。
namespace WebScraping {
public class Program {
public static void Main() {
// scraping logic...
}
}
}
C#でウェブスクレイパーを構築する方法を理解する時が来ました!
C#で静的コンテンツのウェブサイトをスクレイピングする
静的コンテンツのウェブサイトでは、ウェブページのコンテンツがすでにサーバーから返されるHTMLドキュメントに格納されています。これは、静的コンテンツのウェブページがデータを取得するためのXHRリクエストを実行したり、JavaScriptをレンダリングしたりする必要がないことを意味します。
静的なウェブサイトのスクレイピングは、かなり簡単です。やるべきことは以下の通りです。
- ウェブスクレイピング用のC#ライブラリをインストールする
- 対象のウェブページをダウンロードし、そのHTMLドキュメントを解析する
- ウェブスクレイピングライブラリを使用して、関心のあるHTML要素を選択する
- それらからデータを抽出する
これらの手順すべてを「SpongeBob SquarePantsエピソードリスト」のWikipediaページに適用します。

これから作成するC#ウェブスクレイパーの目標は、静的コンテンツのWikipediaページからすべてのエピソードデータを自動的に取得することです。
さあ、始めましょう!
ステップ1:HtmlAgilityPackをインストールする
HtmlAgilityPackは、HTMLドキュメントを解析し、DOMから要素を選択し、それらからデータを抽出することができるオープンソースのC#ライブラリです。基本的に、HtmlAgilityPackは、静的コンテンツのウェブサイトをスクレイピングするために必要なすべてを提供します。
インストールするには、「ソリューションエクスプローラー」のプロジェクト名の下にある「依存関係」オプションを右クリックします。次に、「NuGetパッケージの管理」を選択します。NuGetパッケージマネージャのウィンドウで、「HtmlAgilityPack」を検索し、画面右側の「インストール」ボタンをクリックします。
ポップアップウィンドウで、プロジェクトに変更を加えることに同意するかどうか尋ねられます。「OK」をクリックして、HtmlAgilityPackをインストールします。これで、静的なウェブサイトに対してC#でウェブスクレイピングを実行する準備が整いました。
次に、App.csファイルの先頭に以下の行を追加して、HtmlAgilityPackをインポートします。
using HtmlAgilityPack;ステップ2:HTMLウェブページを読み込む
HtmlAgilityPackを使用して対象のウェブページに接続方法は、以下の通りです。
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// downloading to the target page
// and parsing its HTML content
var document = web.Load(url);
HtmlWebクラスのインスタンスを使って、Load()メソッドによりウェブページを読み込むことができます。裏側では、このメソッドはHTTP GETリクエストを実行し、パラメータとして渡されたURLに関連するHTMLドキュメントを取得します。その後、Load()は、ページからHTML要素を選択するために使用できるHtmlAgilityPack HtmlDocumentのインスタンスを返します。
ステップ3:HTML要素を選択する
XPathセレクタを使って、ウェブページからHTML要素を選択できます。具体的には、XPathを使って1つ以上の特定のDOM要素を選択できます。HTML要素に関連するXPathセレクタを取得するには、その要素を右クリックしてブラウザの検査ツールを開き、対象のDOM要素が選択されていることを確認して、DOM要素を右クリックして「XPathをコピー」を選択します。
C#のウェブスクレイパーの目標は、各エピソードに関連するデータを抽出することです。そのため、<tr>エピソード要素に上記の手順を適用して、XPathセレクタを抽出します。
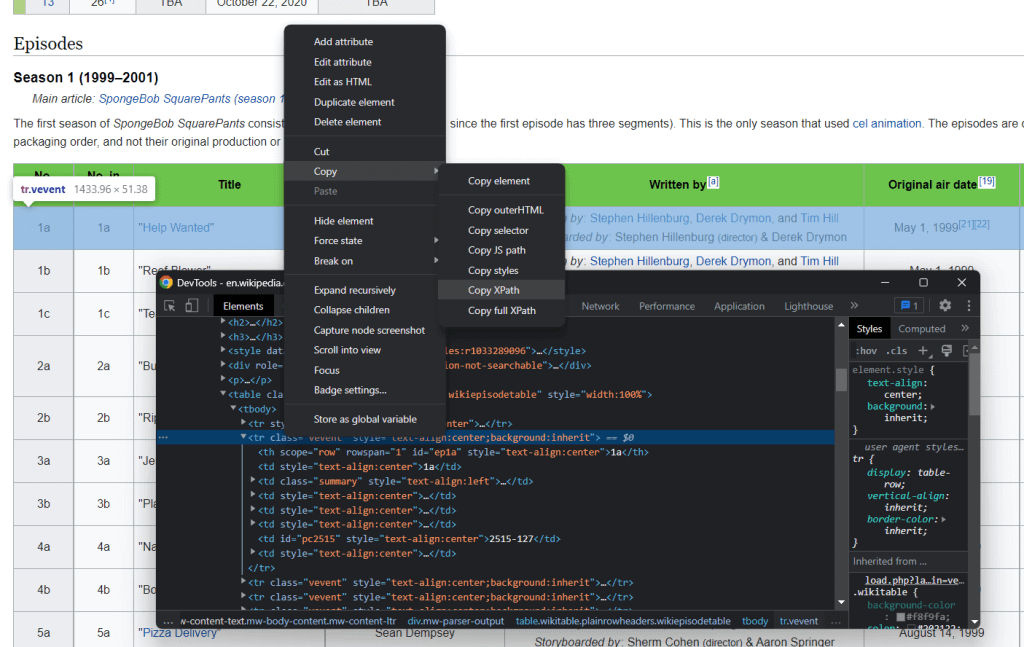
これにより、以下が返されます。
//*[@id="mw-content-text"]/div[1]/table[2]/tbody/tr[2]
すべての<tr>要素を選択したいことに念頭に置いておきます。そこで、選択した行要素に関連するインデックスを変更する必要があります。テーブルヘッダーしか含まれていないテーブルの最初の行をスクレイピングしたくないためです。XPathではインデックスが1から始まるため、ページの最初のエピソードテーブルのすべての<tr>要素を、position()>1のXPath構文を追加することで選択できます。
また、すべてのシーズンのテーブルからデータをスクレイピングしたいと考えています。Wikipediaのページでは、エピソードのデータを含むテーブルは、HTMLドキュメント内の2番目から15番目までのHTMLテーブルにあります。従って、最終的なXPath文字列は次のようになります。
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
これで、HtmlAgilityPackが提供するSelectNodes()を使って、次のように目的のHTML要素を選択できます。
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");なお、SelectNodes()メソッドは、HtmlNodeインスタンスに対してのみ呼び出すことができることに留意してください。そのため、DocumentNodeプロパティを使ってHTMLドキュメントのルートHTMLノードを取得する必要があります。
また、XPathセレクタは、ウェブページからHTML要素を選択するための数ある手法の1つに過ぎません。CSSセレクタもよく使われるオプションです。
ステップ4:HTML要素からデータを抽出する
まず、スクレイピングしたデータを格納するカスタムクラスが必要です。WebScrapingフォルダ内にEpisode.csファイルを作成し、以下のように初期化します。
namespace StaticWebScraping {
public class Episode {
public string OverallNumber { get; set; }
public string Title { get; set; }
public string Directors { get; set; }
public string WrittenBy { get; set; }
public string Released { get; set; }
}
}
ご覧のように、このクラスには、エピソードについてスクレイピングする最も重要な情報をすべて格納するための4つの属性があります。なお、SpongeBobのエピソード番号には必ず文字が含まれるため、OverallNumberは文字列です。
次に、以下のように、App.csファイルでウェブスクレイピングのC#ロジックを実装できます。
using HtmlAgilityPack;
using System;
using System.Collections.Generic;
namespace StaticWebScraping {
public class Program {
public static void Main() {
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// downloading to the target page
// and parsing its HTML content
var document = web.Load(url);
// selecting the HTML nodes of interest
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");
// initializing the list of objects that will
// store the scraped data
List<Episode> episodes = new List<Episode>();
// looping over the nodes
// and extract data from them
foreach (var node in nodes) {
// add a new Episode instance to
// to the list of scraped data
episodes.Add(new Episode() {
OverallNumber = HtmlEntity.DeEntitize(node.SelectSingleNode("th[1]").InnerText),
Title = HtmlEntity.DeEntitize(node.SelectSingleNode("td[2]").InnerText),
Directors = HtmlEntity.DeEntitize(node.SelectSingleNode("td[3]").InnerText),
WrittenBy = HtmlEntity.DeEntitize(node.SelectSingleNode("td[4]").InnerText),
Released = HtmlEntity.DeEntitize(node.SelectSingleNode("td[5]").InnerText)
});
}
// converting the scraped data to CSV...
// storing this data in a db...
// calling an API with this data...
}
}
}
このC#のウェブスクレイパーは、選択されたHTMLノードをループし、それぞれにEpisodeクラスのインスタンスを作成し、episodesリストに格納します。関心のあるHTMLノードは、テーブルの行であることに留意してください。そのため、SelectSingleNode()メソッドを使っていくつかの要素を選択する必要があります。次に、InnerText属性を使って、そこからスクレイピングする目的のデータを抽出します。HtmlEntity.DeEntitize()静的関数を使って、特殊なHTML文字を自然な表現に置き換えることに注意してください。
ステップ5:スクレイピングしたデータをCSVにエクスポートする
C#でウェブスクレイピングをする方法を学んだので、スクレイピングしたデータを好きなように使うことができます。最も一般的なシナリオの1つは、スクレイピングしたデータをCSVなどの人間が読める形式に変換することです。こうすることで、チームの誰もがスクレイピングしたデータをExcelで直接調べることができるようになります。
それでは、C#でスクレイピングしたデータをCSVに書き出す方法を学びましょう。
簡単にするために、ライブラリを使いましょう。CSVHelperは、CSVファイルの読み書きに使用できる、高速で使いやすい、強力な.NETライブラリです。CSVHelperの依存関係を追加するには、Visual Studioの「NuGetパッケージの管理」セクションを開き、「CSVHelper」を探してインストールします。
CSVHelperを使用すると、以下のようにスクレイピングしたデータをCSVに変換できます。
using CsvHelper;
using System.IO;
using System.Text;
using System.Globalization;
// scraping logic…
// initializing the CSV file
using (var writer = new StreamWriter("output.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
// populating the CSV file
csv.WriteRecords(episodes);
}
usingキーワードに慣れていない方のために説明すると、このキーワードはスコープを定義し、その中のオブジェクトは最後に破棄されます。つまり、usingはファイルリソースを扱うのに最適なのです。次に、WriteRecords() CSVHelper関数が、スクレイピングしたデータを自動的にCSVに変換し、output.csvファイルに書き込む処理を行います。
C#ウェブスクレイパーの実行が終了するとすぐに、プロジェクトのルートフォルダにoutput.csvファイルが表示されます。それをExcelで開くと、以下のようなデータが表示されます。
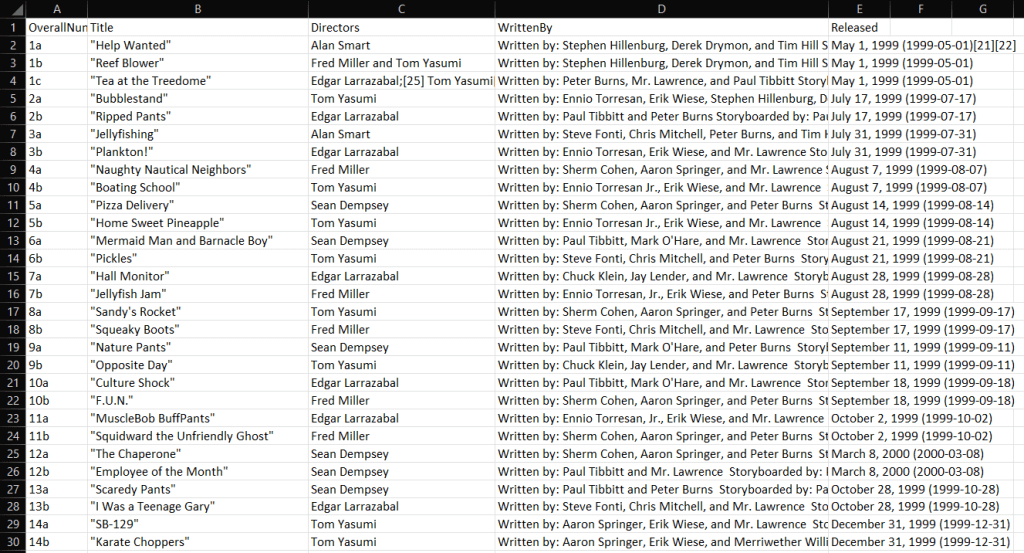
はい、できました!静的コンテンツのウェブサイトに対してC#でウェブスクレイピングを行う方法を学びました!
C#で動的コンテンツのウェブサイトをスクレイピングする
動的コンテンツのウェブサイトでは、JavaScriptを使用し、AJAX技術を介して動的にデータを取得できます。動的コンテンツページに関連するHTMLドキュメントは、基本的に空でかまいません。同時に、レンダリング時に動的にデータを取得し、表示する役割を担うJavaScriptスクリプトが含まれています。つまり、これらからデータを抽出したい場合、ページをレンダリングするブラウザが必要です。JavaScriptを実行できるのはブラウザだけだからです。
動的なウェブサイトのスクレイピングは厄介で、静的なウェブサイトのスクレイピングよりも確実に困難です。詳しく言うと、このようなウェブサイトをスクレイピングするには、ヘッドレスブラウザが必要です。この技術に馴染みのない方のために説明すると、ヘッドレスブラウザとは、GUIを持たないブラウザのことです。つまり、C#で動的コンテンツのウェブサイトをスクレイピングするには、Seleniumのようなヘッドレスブラウザ機能を提供するライブラリが必要です。
記事の冒頭の段落に従って、新しいC#プロジェクトを設定します。今回は、DynamicWebScrapingという名前にしましょう。
ステップ1:Seleniumをインストールする
Seleniumは、複数のプログラミング言語をサポートする、オープンソースの自動テストフレームワークです。Seleniumはヘッドレスブラウザ機能を提供し、特定のアクションを実行するようウェブブラウザに指示することができます。
Seleniumをプロジェクトの依存関係に追加するには、再度「NuGetパッケージの管理」セクションにアクセスし、「Selenium.WebDriver」を検索してインストールします。
App.csファイルの先頭に以下の2行を追加して、Seleniumをインポートします。
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
ステップ2:対象のウェブサイトに接続する
Seleniumは対象のウェブサイトをブラウザで開くので、手動でHTTP GETリクエストを実行する必要はありません。以下のようにSelenium Web Driverを使用するだけです。
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// to initialize the Chrome Web Driver in headless mode
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// connecting to the target web page
driver.Navigate().GoToUrl(url);
ここでは、Chromeウェブドライバのインスタンスを作成しました。別のブラウザを使用している場合は、適切なブラウザドライバを使用し、コードを適宜調整してください。次に、driver変数のNavigate()メソッドを使用して、GoToUrl()メソッドを呼び出し、対象のウェブページに接続できます。具体的には、この関数はURLパラメータを受け取り、それを使ってヘッドレスブラウザでURLに関連付けられたウェブページを閲覧します。
ステップ3:HTML要素からデータをスクレイピングする
前述の通り、以下のXPathセレクタを使って、目的のHTML要素を選択できます。
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
SeleniumでXPathセレクタを使用する:
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
具体的には、Selenium By.XPath()メソッドで、XPath文字列を適用して、ページのDOMからHTML要素を選択できます。
さて、先ほどと同様に、DynamicWebScraping名前空間の下にEpisode.csクラスを定義済みだとします。これで、以下のようにSeleniumを使用してC#ウェブスクレイパーを構築できます。
using System;
using System.Collections.Generic;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
namespace DynamicWebScraping {
public class Program {
public static void Main() {
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// to initialize the Chrome Web Driver in headless mode
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// connecting to the target web page
driver.Navigate().GoToUrl(url);
// selecting the HTML nodes of interest
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
// initializing the list of objects that will
// store the scraped data
List<Episode> episodes = new();
// looping over the nodes
// and extract data from them
foreach (var node in nodes) {
// add a new Episode instance to
// to the list of scraped data
episodes.Add(new Episode() {
OverallNumber = node.FindElement(By.XPath("th[1]")).Text,
Title = node.FindElement(By.XPath("td[2]")).Text,
Directors = node.FindElement(By.XPath("td[3]")).Text,
WrittenBy = node.FindElement(By.XPath("td[4]")).Text,
Released = node.FindElement(By.XPath("td[5]")).Text
});
}
// converting the scraped data to CSV...
// storing this data in a db...
// calling an API with this data...
}
}
}
見ての通り、ウェブスクレイピングのロジックは、HtmlAgilityPackで行ったのと比べてそれほど変わりません。詳細に言うと、SeleniumのFindElements()およびFindElement()メソッドのおかげで、以前と同様のスクレイピング目標を達成できます。本当に変わるのは、Seleniumがこれらの操作をすべてブラウザで実行することです。
なお、動的コンテンツのウェブサイトでは、データが取得され、レンダリングされるまで待つ必要がある場合があります。これは、WebDriverWaitを使って実現できます。
おめでとうございます!動的コンテンツのウェブサイトに対してC#でウェブスクレイピングを行う方法を学びました。あとは、スクレイピングしたデータをどう使うかを学ぶだけです。
スクレイピングしたデータの活用方法
- 必要に応じてクエリを実行するためにデータベースに保存します。
- JSONに変換して、APIを呼び出すために使用します。
- CSVなどの人間が読める形式に変換して、Excelで開きます。
これらはほんの一例です。本当に重要なのは、スクレイピングしたデータをコードに取り込んだら、それを好きなように使えるということです。通常、スクレイピングしたデータは、マーケティング、データ分析、または営業チームにとってより有用な形式に変換されます。
ただし、ウェブスクレイピングにはいくつかの課題が伴います!
プロキシを使ったデータプライバシー
IPを晒さずに、ブロックされることを避け、自らの身元を守りたいのであれば、ウェブスクレイピングプロキシの採用を検討してください。プロキシサーバーは、お使いのアプリケーションと対象ウェブサイトのサーバーとの間のゲートウェイとして機能し、結果としてお使いのIPを隠します。
その結果、プロキシサービスを利用することで、IPブロックを回避し、匿名でデータを収集し、あらゆる国のコンテンツをロック解除できます。プロキシのタイプはさまざまで、それぞれユースケースや目的が異なります。確実に適切なプロキシプロバイダーを選択するようにしてください。
では、ウェブプロキシがウェブスクレイピングプロセスにどのようなメリットをもたらすか、見ていきましょう。
IPアドレス制限を回避する
ウェブスクレイピングアプリケーションがインターネット上のウェブサイトにアクセスしようとすると、リクエストの発信元であるIPアドレスが公開されます。これは、ウェブサイトがそれを追跡して、リクエストが多すぎるユーザーをブロックできることを意味します。これがボット検出です。ウェブプロキシを使用している場合、ターゲットサーバーには、あなたのIPではなく、ローテーションするプロキシのIPが表示されます。つまり、プロキシを使用すれば、IPアドレス制限を簡単に回避できるのです。
IPアドレスのローテーション
プレミアムプロキシは、一般にIPローテーション機能を提供します。つまり、プロキシサーバーに連絡するたびに、大量のIPプールから新しいIPアドレスが割り当てられるのです。これは、スクレイピング防止システムによる追跡を回避するのに役立ちます。
地域別スクレイピング
多くのウェブサイトは、リクエストがどこから来たかに基づいて情報を変更します。また、一部のウェブサイトは、特定の地域でのみ利用可能です。これらのウェブサイトをスクレイピングして世界的な市場調査を行うことは問題になるかもしれません。幸いなことに、匿名プロキシを使用して、出口IPアドレスの場所を選択できます。これは、国際化されたウェブサイトから商品に関する貴重な情報を収集するのに適した方法です。
まとめ
ここでは、C#を使ってウェブスクレイパーを構築する方法を学びました。ご覧いただいたように、コードの行数はそれほど多くありません。同時に、対象とするウェブページが変更されると、それに合わせてスクレイパーを更新する必要があります。ウェブサイトによっては、日々、構造が変更されています。このため、高度なウェブスクレイパーIDEを試すべきなのです。Bright Dataのスクレイパーは常に最新であるため、何度もスクレイパーを設定することなく、データに集中できます。