

豊富なライブラリとツールのおかげで、PHPはウェブスクレイパーを構築するのに最適な言語です。ウェブ開発向けに特別に設計されたPHPは、ウェブスクレイピング作業を簡単かつ確実に処理します。
PHPを使ってウェブサイトをスクレイピングする方法にはさまざまなものがありますが、この記事ではいくつかの異なる方法を紹介します。具体的には、curl、file_get_contents、Symfony BrowserKit、およびSymfonyのPantherコンポーネントを使ってウェブサイトをスクレイピングする方法を解説します。さらに、ウェブスクレイピング中に直面する可能性のある一般的な課題とその回避方法についても説明します。
目次
- PHPを使ったウェブスクレイピング
- curl
- file_get_contents
- Symfony BrowserKit
- Symfony Panther
PHPを使ったウェブスクレイピング
このセクションでは、基本的なサイトと複雑で動的なサイトの両方のウェブスクレイピングでよく使われる方法をいくつか紹介します。
注記:このチュートリアルではさまざまな方法を取り上げていますが、これは決して網羅的なリストではありません。
前提条件
このチュートリアルを進めるには、最新バージョンのPHPと、PHPの依存関係マネージャーであるComposerが必要です。この記事は、PHP 8.1.18とComposer 2.5.5を使ってテストしました。
PHPとComposerをセットアップしたら、php-web-scrapingというディレクトリを作成し、cdでそこに入ります。
mkdir php-web-scraping
cd $_
チュートリアルの残りの部分は、このディレクトリで作業します。
curl
curlは、C言語で書かれた、ほぼユビキタスな低レベルライブラリおよびCLIツールです。これを使うと、HTTPまたはHTTPSを利用してウェブページの内容を取得できます。ほぼすべてのプラットフォームで、PHPはデフォルトでcurlに対応しています。
このセクションでは、国連の推計に基づいて国名を人口別にリストアップした、ごく基本的なウェブページをスクレイピングします。メニュー内のリンクをリンクテキストとともに抽出します。
まず、curl.phpというファイルを作成し、その中でcurl_init数を使ってcurlを初期化します。
<?php
$ch = curl_init();
次に、ウェブページを取得するためのオプションを設定します。これには、curl_setopt関数を使用したURLとHTTPメソッド(GET、POSTなど)の設定が含まれます。
curl_setopt($ch, CURLOPT_URL, 'https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)');
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
このコードでは、ターゲットURLをウェブページに、メソッドをGETに設定しています。CURLOPT_RETURNTRANSFERは、HTMLレスポンスを返すようにcurlに指示します。
curlの準備ができたら、curl_execを使用してリクエストを行うことができます。
$response = curl_exec($ch);
HTMLデータの取得は、ウェブスクレイピングの最初のステップにすぎません。HTMLレスポンスからデータを抽出するには、いくつかのテクニックを使う必要があります。最も単純な方法は、ごく基本的なHTML抽出に正規表現を使うことです。ただし、正規表現を使って任意のHTMLを解析することはできないことに留意してください。ただし、ごく単純な解析であれば正規表現で十分です。
例えば、hrefとtitle属性を持ち、<span>を含む<a>タグを抽出します。
if(! empty($ch)) {
preg_match_all(
'/<a href="([^"]*)" title="([^"]*)"><span>([^<]*)</span></a>/',
$response, $matches, PREG_SET_ORDER
);
foreach($matches as $link) {
echo $link[1] . " => " . $link[3] . "n";
}
}
次に、curl_close関数を使ってリソースを開放します。
curl_close($ch);
次のようにコードを実行します。
php curl.php
リンクが正しく抽出されていることが確認できます。

curlを使用すると、HTTP/HTTPS経由でウェブページをフェッチする方法を非常に低レベルで制御できます。さまざまな接続プロパティを微調整したり、プロキシサーバー(詳細は後述)、ユーザーエージェント、タイムアウトなどの追加手段を加えることもできます。
さらに、curlはほとんどのオペレーティングシステムにデフォルトでインストールされているため、クロスプラットフォームのウェブスクレイパーを作成するのに最適な選択肢となります。
ただし、ご覧のとおり、curlだけでは十分ではなく、データを適切にスクレイピングするにはHTMLパーサーが必要です。また、curlはウェブページ上でJavaScriptを実行することができないので、curlを使用して動的ウェブページやシングルページアプリケーション(SPA)をスクレイピングすることはできません。
file_get_contents
file_get_contents関数は、主にファイルの内容を読み取るのに使用します。ただし、HTTP URLを渡すことで、ウェブページからHTMLデータを取得できます。これは、file_get_contentsで前のコード内のcurlの使用を置き換えられることを意味します。
このセクションでは、前と同じページをスクレイピングしますが、今回はスクレイパーがより高度になり、テーブルからすべての国名を抽出できるようになります。
file_get-contents.phpという名前のファイルを作成し、まずURLをfile_get_contentsに渡します。
<?php
$html = file_get_contents('https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)');
これで、$html変数にウェブページのHTMLコードが格納されます。
前の例と同様、HTMLデータの取得は最初のステップに過ぎません。ひと味添えるために、libxmlを使用し、XPathセレクタを使って要素を選択します。そのためには、まずDOMDocumentを初期化し、そこにHTMLをロードする必要があります。
$doc = new DOMDocument;
libxml_use_internal_errors(true);
$doc->loadHTML($html);
libxml_clear_errors();
ここでは、最初のtbody要素、tbody内のtr要素、tr要素内の最初のtd、td要素内のtitle属性を持つaの順に国を選択します。
以下のコードでは、DOMXpathクラスを初期化し、evaluateを使用してXPathセレクタを使う要素を選択します。
$xpath = new DOMXpath($doc);
$countries = $xpath->evaluate('(//tbody)[1]/tr/td[1]//a[@title=true()]');
あとは要素をループしてテキストを表示するだけです。
foreach($countries as $country) {
echo $country->textContent . "n";
}
次のようにコードを実行します。
php file_get_contents.php
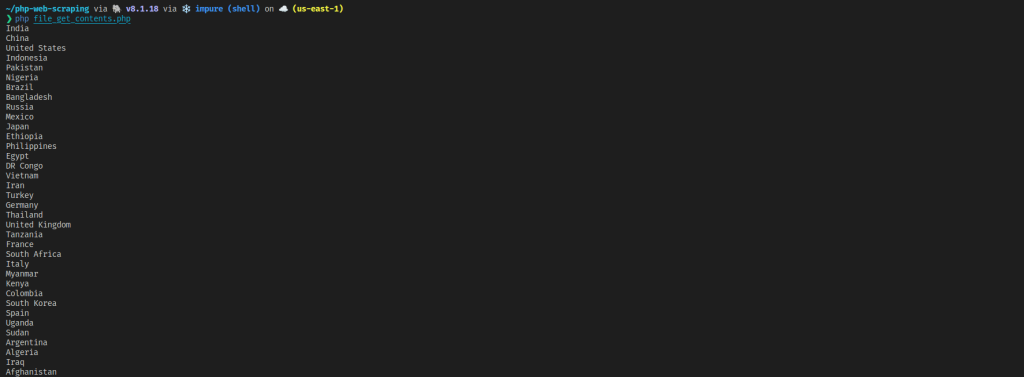
ご覧のように、file_get_contentsはcurlよりも使い方が簡単で、ウェブページのHTMLコードを素早く取得するのによく使われます。ただし、これにはcurlと同じ欠点があります。つまり、追加のHTMLパーサーが必要であり、動的なウェブページやSPAをスクレイピングすることはできません。加えて、curlの提供するきめ細かな制御を利用することもできません。ただし、シンプルであるため、基本的な静的サイトのスクレイピングには適しています。
Symfony BrowserKit
Symfony BrowserKitは、実際のブラウザの動作をシミュレートするSymfonyフレームワークのコンポーネントです。これは、実際のブラウザのようにウェブページと対話できることを意味します。例えば、ボタンやリンクをクリックしたり、フォームを送信したり、履歴を戻ったり進んだりできます。
このセクションでは、Bright Dataブログにアクセスし、検索ボックスに「PHP」と入力して、検索フォームを送信します。そして、その結果から記事名をスクレイピングします。
Symfony BrowserKitを使用するには、ComposerでBrowserKitコンポーネントをインストールする必要があります。
composer require symfony/browser-kit
また、インターネット経由でHTTPリクエストを行うには、HttpClientコンポーネントをインストールする必要があります。
composer require symfony/http-client
BrowserKitは、デフォルトでXPathセレクターを使用した要素の選択をサポートします。この例では、CSSセレクターを使用しています。そのためには、CssSelectorコンポーネントもインストールする必要があります。
composer require symfony/css-selector
symfony-browserkit.phpという名前のファイルを作成します。このファイルで、HttpBrowserを初期化します。
<?php
require "vendor/autoload.php";
use SymfonyComponentBrowserKitHttpBrowser;
$client = new HttpBrowser();
request関数を使用してGETリクエストを作成します。
$crawler = $client->request('GET', 'https://brightdata.com/blog');
検索ボタンがあるフォームを選択するには、ボタン自体を選択し、form関数を使用してそれを囲むフォームを取得する必要があります。ボタンは、filter関数でボタンのIDを渡すことで選択できます。フォームを選択したら、Httpbrowserクラスのsubmit関数を使用してフォームを送信できます。
入力値のハッシュを渡すことで、submit関数は送信前にフォームを埋めることができます。次のコードでは、qという名前の入力に値PHPが与えられています。これは、検索ボックスにPHPと入力するのと同じです。
$form = $crawler->filter('#blog_search')->form();
$crawler = $client->submit($form, ['q' => 'PHP']);
submit関数は結果のページを返します。そこから、CSS セレクター.col-md-4.mb-4 h5を使用して記事名を抽出できます。
$crawler->filter(".col-md-4.mb-4 h5")->each(function ($node) {
echo $node->text() . "n";
});
次のようにコードを実行します。
php symfony-browserkit.php

Symfony BrowserKitはウェブページと対話処理する点では前の2つのメソッドより一歩進んでいますが、JavaScriptを実行できないため、まだ制限があります。このため、BrowserKitを使用して動的ウェブサイトやSPAをスクレイピングすることはできません。
Symfony Panther
Symfony Pantherは、BrowserKitコンポーネントをラップするもう1つのSymfonyコンポーネントです。ただし、Symfony Pantherには大きな利点が1つあります。それは、ブラウザをシミュレートする代わりに、WebDriverプロトコルを使用して実際のブラウザでコードを実行し、実際のブラウザをリモートで制御することです。つまり、動的なウェブサイトやSPAを含む、あらゆるウェブサイトをスクレイピングできるということです。
このセクションでは、OpenWeatherホームページを読み込み、検索ボックスに都市名を入力して検索を実行し、その都市の現在の天気をスクレイピングします。
最初に、ComposerでSymfony Pantherをインストールします。
composer require symfony/panther
また、dbrekelmans/browser-driver-installerをインストールする必要があります。これにより、システムにインストールされているブラウザが自動的に検出され、そのブラウザに適切なドライバがインストールされます。システムにFirefoxまたはChromiumベースのブラウザがインストールされていることを確認してください。
composer require dbrekelmans/bdi
driversディレクトリに適切なドライバをインストールするには、bdiツールを実行します。
vendor/bin/bdi detect drivers
symfony-panther.phpという名前のファイルを作成し、Pantherクライアントを初期化することから始めます。
<?php
require 'vendor/autoload.php';
use SymfonyComponentPantherClient;
$client = Client::createFirefoxClient();
注:ブラウザによっては、
createFirefoxClientの代わりに、createChromeClientまたはcreateSeleniumClientを使用する必要があるかもしれません。
PantherはバックグラウンドでSymfony BrowserKitを使用するため、次のコードはSymfony BrowserKitセクションのコードと非常によく似ています。
まず、request機能を使ってウェブページを読み込みます。ページが読み込まれると、最初はowm-loaderクラスのdivでカバーされ、ローディング進捗バーが表示されます。ページの対話処理を開始する前に、このdivが消えるのを待つ必要があります。これはwaitForStaleness関数を使って行えます。この関数は、CSSセレクターを受け取り、DOMから削除されるのを待ちます。
ローディングバーが消えたら、クッキーを受け入れてクッキーのバナーが閉じるようにする必要があります。そのためには、テキストでボタンを検索可能なselectButton関数が便利です。ボタンを取得したら、click関数でボタンをクリックします。
$client->request('GET', 'https://openweathermap.org/');
try {
$crawler = $client->waitForStaleness(".owm-loader");
} catch (FacebookWebDriverExceptionNoSuchElementException $e) {
}
$crawler->selectButton('Allow all')->click();
注:ページの読み込み速度によっては、
waitForStaleness関数が実行される前にローディングバーが消える場合があります。これにより例外がスローされます。そのため、この行はtry-catchブロックで囲まれています。
次に、検索バーにKolkataと入力します。filter関数で検索バーを選択し、sendKeys関数を使用して検索バーに入力を提供します。次にSearchボタンをクリックします。
$crawler->filter('input[placeholder="Search city"]')->sendKeys('Kolkata');
$crawler->selectButton('Search')->click();
ボタンを選択すると、オートコンプリート候補ボックスがポップアップ表示されます。waitForVisibility関数を使ってリストが表示されるまで待機し、先ほどと同様にfilterとclickの組み合わせを使って最初の項目をクリックできます。
$crawler = $client->waitForVisibility(".search-dropdown-menu li");
$crawler->filter(".search-dropdown-menu li")->first()->click();

最後に、waitForElementToContainを使用して結果が読み込まれるのを待ち、filterを使用して現在の温度を抽出します。
$crawler = $client->waitForElementToContain(".orange-text+h2", "Kolkata");
$temp = $crawler->filter(".owm-weather-icon+span.orange-text+h2")->text();
echo $temp;
ここでは、セレクター.orange-text+h2を持つ要素にKolkataが含まれるのを待っています。これは、結果が読み込まれたことを示します。
次のようにコードを実行します。
php symfony-panther.php
出力は次のようになります。

ウェブスクレイピングの課題と考えられる解決策
PHPを使用するとウェブスクレイパーを簡単に作成できますが、実際のスクレイピングプロジェクトの操作は複雑になる場合があります。さまざまな状況が発生して、対処する必要がある課題が生じる可能性があります。これらの課題の原因としては、データの構造(例:ページネーション)やウェブサイトの所有者が講じたボット対策(例:ハニーポット トラップ)などが考えられます。
このセクションでは、いくつかの一般的な課題とその対処方法について説明します。
ページ分割されたウェブサイト内の移動
大抵の現実のウェブサイトをスクレイピングする場合、すべてのデータが一度に読み込まれない状況に遭遇する可能性があります。言い換えれば、データがページ分割されています。ページネーションには2つのタイプがあります。
- すべてのページが別々のURLに配置されている。ページ番号はクエリーパラメーターかパスパラメーターで渡される。例えば、
example.com?page=3やexample.com/page/3など。 - 次へボタンが選択されると、JavaScriptを使って新しいページが読み込まれる。
最初のシナリオでは、ページをループで読み込み、個別のウェブページとしてスクレイピングできます。例えば次のコードは、file_get_contentsを使用してサンプルサイトの最初の10ページをスクレイピングします。
for($page = 1; $page <= 10; $page++) {
$html = file_get_contents('https://example.com/page/{$page}');
// DO the scraping
}
2番目のシナリオでは、Symfony PantherなどのJavaScriptを実行可能なソリューションを使用する必要があります。この例では、適切なボタンをクリックして次のページを読み込む必要があります。新しいページが読み込まれるまで、少し待つことをお忘れなく。
for($page = 1; $page <= 10; $page++>) {
// Do the scraping
// Load the next page
$crawler->selectButton("Next")->click();
$client->waitForElementToContain(".current-page", $page+1)
}
注:スクレイピングする特定のウェブサイトにとって意味のある適切な待機ロジックに置き換えてください。
回転プロキシ
プロキシサーバーは、お使いのコンピューターとターゲットウェブサーバーの仲介役を果たします。ウェブサーバーにあなたのIPアドレスが表示されるのを防ぎ、匿名性を保ちます。
ただし、禁止される可能性を視野に入れ、単一のプロキシ サーバーに依存することは避けてください。代わりに、複数のプロキシサーバーを使用し、それらをローテーションする必要があります。次のコードは、プロキシの配列を使用し、そのうちの1つをランダムに選択するという、非常に基本的なソリューションを提供します。
$proxy = array();
$proxy[] = '1.2.3.4';
$proxy[] = '5.6.7.8';
// Add more proxies
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "https://example.com");
curl_setopt($ch, CURLOPT_PROXY, $proxy[array_rand($proxy)]);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 15);
$result = curl_exec($ch);
curl_close($ch);
CAPTCHAの処理
CAPTCHA は、ユーザーがボットではなく人間であることを確認するために多くのウェブサイトで使用されています。残念ながら、これによりお使いのウェブスクレイパーが捕まえられる可能性があります。
CAPTCHAには、「あなたは人間ですか?」と尋ねる単純なチェックボックスのような、非常に原始的なものもあります。あるいは、GoogleのreCAPTCHAやhCaptchaのような、より高度なアルゴリズムが使用されることもあります。原始的なCAPTCHAであれば、基本的なウェブページの操作(例:チェックボックスにチェックを付ける)で何とかなるでしょうが、高度なCAPTCHAに対応するには、2Captchaのような専用ツールが必要です。2Captchaでは、人間がCAPTCHAを解決します。必要な詳細を2Captcha APIに渡すだけで、解決済みのCAPTCHAが返されます。
2Captchaの使用を開始するには、アカウントを作成し、APIキーを取得する必要があります。
Composerで2Captchaをインストールします。
composer require 2captcha/2captcha
コード内で、TwoCaptchaのインスタンスを作成します。
$solver = new TwoCaptchaTwoCaptcha('YOUR_API_KEY');
次に、2Captchaを使ってCAPTCHAを解決します。
// Normal captcha
$result = $solver->normal('path/to/captcha.jpg');
// ReCaptcha
$result = $solver->recaptcha([
'sitekey' => '6Le-wvkSVVABCPBMRTvw0Q4Muexq1bi0DJwx_mJ-',
'url' => 'https://mysite.com/page/with/recaptcha',
'version' => 'v3',
]);
// hCaptcha
$result = $solver->hcaptcha([
'sitekey' => '10000000-ffff-ffff-ffff-000000000001',
'url' => 'https://www.site.com/page/',
]);
ハニーポットトラップの回避
ハニーポットトラップは、サービスやネットワークを模倣してスクレイパーやクローラーをおびき寄せ、実際のターゲットからそらせるボット対策です。ハニーポットはボット攻撃の防止には役立ちますが、ウェブスクレイピングでは問題になる可能性があります。スクレイパーがハニーポットにはまってしまうことは望ましくありません。
ハニーポットトラップを避けるために講じることのできる手段には、さまざまなものがあります。たとえば、ハニーポットリンクは実際のユーザーには見えないように隠されていることがよくありますが、ボットがそれらを見つけてしまう可能性があります。このトラップを回避するために、非表示のリンク(display: noneまたはvisibility: noneの CSSプロパティを持つリンク)をクリックしないようにします。
もうひとつの選択肢は、プロキシサーバーのIPアドレスの1つがハニーポットに捕まって禁止されても、他のプロキシを経由して接続できるように、プロキシをローテーションさせることです。
まとめ
PHPの優れたライブラリとフレームワークのおかげで、ウェブスクレイパーの作成は簡単です。この記事では、以下の方法を説明しました。
- curlと正規表現を使って静的ウェブサイトをスクレイピングする
file_get_contentsとlibxmlを使って静的ウェブサイトをスクレイピングする- Symfony BrowserKitを使用して静的サイトをスクレイピングし、フォームを送信する
- Symfony Pantherを使用して複雑な動的サイトをスクレイピングする
残念ながら、これらの方法を使用してスクレイピングしているうちに、PHPを使用したスクレイピングには複雑さが伴うことがわかりました。例えば、ハニーポットを避けるために複数のプロキシを手配し、スクレイパーを慎重に構築することが必要になるかもしれません。
このような複雑な作業をしたくない場合は、包括的なウェブスクレイピングサービスであるBright Data Web Scraper IDEの使用を検討してください。手間をかけずにウェブサイトをスクレイピングするのに役立ちます。




