ここでは、Goウェブスクレイパーを構築する方法を説明します。この自動化スクリプトは、Bright Data ホームページからデータを自動的に取得できます。Goウェブスクレイピングプロセスの目標は、ページからいくつかのHTML要素を選択し、そこからデータを抽出し、収集したデータを探索しやすい形式に変換することです。
You can apply a CSS or XPath selector in Colly as follows:nnc.OnHTML(u0022.your-css-selectoru0022, func(e *colly.HTMLElement) {nn // data extraction logic...nn})
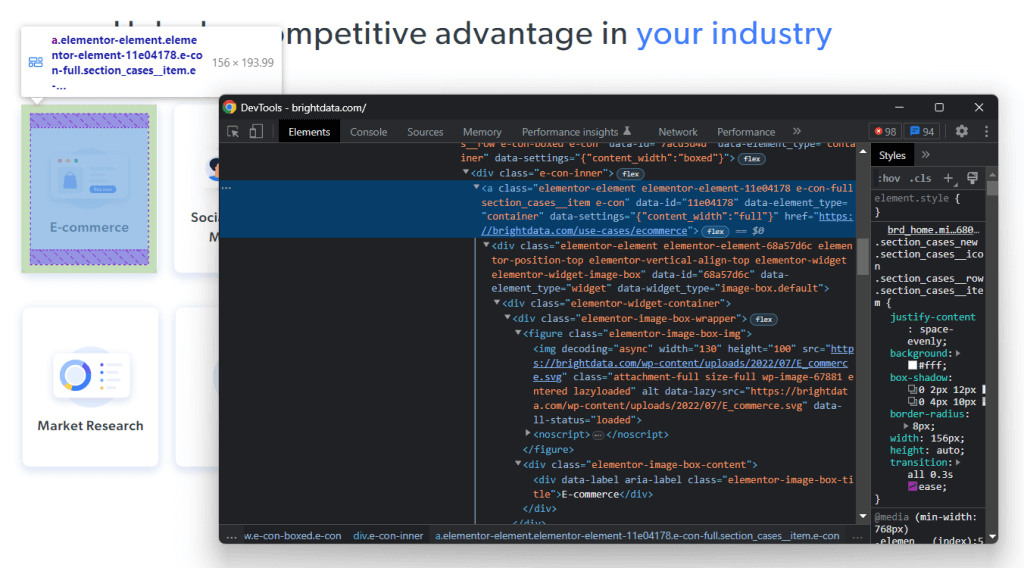
n // iterating over the list of industry cardnn // HTML elementsnn c.OnHTML(u0022.elementor-element-6b05593c .section_cases__itemu0022, func(e *colly.HTMLElement) {nn url := e.Attr(u0022hrefu0022)nn image := e.ChildAttr(u0022.elementor-image-box-img imgu0022, u0022data-lazy-srcu0022)nn name := e.ChildText(u0022.elementor-image-box-content .elementor-image-box-titleu0022)nn // filter out unwanted datann if url!= u0022u0022 || image != u0022u0022 || name != u0022u0022 {nn // initialize a new Industry instancenn industry := Industry{nn Url: url,nn Image: image,nn Name: name,nn }nn // add the industry instance to the listnn // of scraped industriesnn industries = append(industries, industry)nn }nn })
n// open the output CSV filenfile, err := os.Create(u0022industries.csvu0022)n// if the file creation failsnif err != nil {n log.Fatalln(u0022Failed to create the output CSV fileu0022, err)n}n// release the resource allocated to handlen// the file before ending the executionndefer file.Close()nn// create a CSV file writernwriter := csv.NewWriter(file)n// release the resources associated with the n// file writer before ending the executionndefer writer.Flush()nn// add the header row to the CSVnheaders := []string{n u0022urlu0022,n u0022imageu0022,n u0022nameu0022,n}nwriter.Write(headers)nn// store each Industry product in then// output CSV filenfor _, industry := range industries {n // convert the Industry instance ton // a slice of stringsn record := []string{n industry.Url,n industry.Image,n industry.Name,n }n n // add a new CSV recordn writer.Write(record)n}
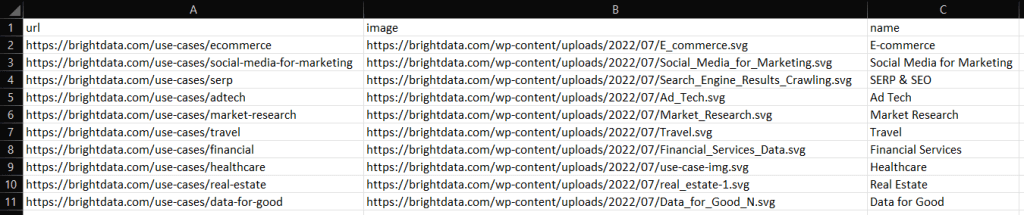
file, err:= os.Create(u0022industries.jsonu0022)nnif err != nil {nn log.Fatalln(u0022Failed to create the output JSON fileu0022, err)nn}nndefer file.Close()nn// convert industries to an indented JSON stringnnjsonString, _ := json.MarshalIndent(industries, u0022 u0022, u0022 u0022)nn// write the JSON string to filennfile.Write(jsonString)nnThis will produce the JSON file below:nn[nn {nn u0022Urlu0022: u0022https://brightdata.com/use-cases/ecommerceu0022,nn u0022Imageu0022: u0022https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svgu0022,nn u0022Nameu0022: u0022E-commerceu0022nn },nn // ...nn {nn u0022Urlu0022: u0022https://brightdata.com/use-cases/real-estateu0022,nn u0022Imageu0022: u0022https://brightdata.com/wp-content/uploads/2022/07/real_estate-1.svgu0022,nn u0022Nameu0022: u0022Real Estateu0022nn },nn {nn u0022Urlu0022: u0022https://brightdata.com/use-cases/data-for-goodu0022,nn u0022Imageu0022: u0022https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svgu0022,nn u0022Nameu0022: u0022Data for Goodu0022nn }nn ]
完了です!これで、収集したデータをより便利な形式に移行する方法がわかりました!
ステップ8:すべてをまとめる
Golangスクレイパーの完全なコードは次のようになります。
n// scraper.gonpackage mainnnimport (n u0022encoding/csvu0022n u0022encoding/jsonu0022n u0022logu0022n u0022osu0022n // import Collyn u0022github.com/gocolly/collyu0022n)nn// definr some data structuresn// to store the scraped datantype Industry struct {n Url, Image, Name stringn}nnfunc main() {n // initialize the struct slicesn var industries []Industrynn // initialize the Collectorn c := colly.NewCollector()nn // set a valid User-Agent headern c.UserAgent = u0022Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36u0022n n // iterating over the list of industry cardn // HTML elementsn c.OnHTML(u0022.elementor-element-6b05593c .section_cases__itemu0022, func(e *colly.HTMLElement) {n url := e.Attr(u0022hrefu0022)n image := e.ChildAttr(u0022.elementor-image-box-img imgu0022, u0022data-lazy-srcu0022)n name := e.ChildText(u0022.elementor-image-box-content .elementor-image-box-titleu0022)n // filter out unwanted datan if url != u0022u0022 u0026u0026 image != u0022u0022 u0026u0026 name != u0022u0022 {n // initialize a new Industry instancen industry := Industry{n Url: url,n Image: image,n Name: name,n }n // add the industry instance to the listn // of scraped industriesn industries = append(industries, industry)n }n })nn // connect to the target siten c.Visit(u0022https://brightdata.com/u0022)nn // u002du002d- export to CSV u002du002d-nn // open the output CSV filen csvFile, csvErr := os.Create(u0022industries.csvu0022)n // if the file creation failsn if csvErr != nil {n log.Fatalln(u0022Failed to create the output CSV fileu0022, csvErr)n }n // release the resource allocated to handlen // the file before ending the executionn defer csvFile.Close()nn // create a CSV file writern writer := csv.NewWriter(csvFile)n // release the resources associated with then // file writer before ending the executionn defer writer.Flush()nn // add the header row to the CSVn headers := []string{n u0022urlu0022,n u0022imageu0022,n u0022nameu0022,n }n writer.Write(headers)nn // store each Industry product in then // output CSV filen for _, industry := range industries {n // convert the Industry instance ton // a slice of stringsn record := []string{n industry.Url,n industry.Image,n industry.Name,n }n // add a new CSV recordn writer.Write(record)n }nn // u002du002d- export to JSON u002du002d-nn // open the output JSON filen jsonFile, jsonErr := os.Create(u0022industries.jsonu0022)n if jsonErr != nil {n log.Fatalln(u0022Failed to create the output JSON fileu0022, jsonErr)n }n defer jsonFile.Close()n // convert industries to an indented JSON stringn jsonString, _ := json.MarshalIndent(industries, u0022 u0022, u0022 u0022)nn // write the JSON string to filen jsonFile.Write(jsonString)n}