

このガイドで、あなたは発見するだろう:
- n8n、Bright Data、OpenAIを使ってLinkedInのスクレイピングを自動化する方法
- 候補者のプロフィールを受信トレイに直接送信する、コード不要のワークフローを構築する方法
- Web Unlocker、ChatGPT、SMTPを組み合わせることで、強力なリクルーティング・ツールが生まれる理由
始めよう!
はじめに
このワークフローはn8nでご覧いただけます。しかし、最も簡単なセットアップのために、最初にやらなければならないことがいくつかある。
セルフ・ホスティング n8n
このワークフローはn8nのCommunity Nodesに依存しています。Community Nodesはn8nコミュニティの良きサマリア人によって提供されるサードパーティツールです。これらの可動部分をすべてDockerコンテナにラップして管理するのがベストな方法です。
Dockerのインストール
Windows上でネイティブのUbuntuまたはWSL経由のUbuntuを使用して、以下のコマンドを実行してDockerをインストールする。他のプラットフォームへのDockerのインストールについては、こちらをご覧ください。
sudo snap install dockerDockerをインストールしたら、ストレージ・ボリュームを作成し、コンテナを実行する。
n8nコンテナの作成
sudo docker volume create n8n_data
sudo docker run -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8nコミュニティ・ノードの設置
ブラウザでhttp://localhost:5678/ を開いてください。完全にセルフホストされたn8nウェブアプリがローカルで動作するようになります。
サイドバーで、プロフィールの横にある3つの点をクリックし、「設定」を選択します。

設定メニューが表示されたら、”Community Nodes “を選択する。これで、先ほど紹介したサードパーティ製ツールにアクセスできるようになる。
インストール」をクリックすると、インストールしたいノードのポップアップが表示されます。npmパッケージセクションに、以下のパッケージを貼り付ける。
n8n-nodes-brightdata準備ができたら「インストール」をクリックする。

次に、このプロセスをドキュメント・ジェネレーターでも繰り返します。
n8n-nodes-document-generator
コンテナの再起動
コミュニティノードをインストールしたら、ctrl+cでコンテナを強制終了します。以下のコマンドを実行してn8nを再起動します。
sudo docker run -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8nワークフローのインポート
セットアップが終わったら、いよいよ先ほどのワークフローをインポートする準備だ。n8nのページに行き、”Use for free “ボタンをクリックする。

いくつかの異なるオプションのポップアップが表示されるはずです。最も簡単な方法は、”Import template to localhost:5678 self-hosted instance “を選択することです。

資格情報の入力またはインポート
ここで、Bright Data、OpenAI、SMTPの認証情報を入力するよう自動的に促されます。

APIキーの取得
ブライトデータ
このワークフローでは、Web Unlockerを使って検索を行います。Web Unlockerにサインアップした後、Web Unlocker Dashboardに移動し、APIキーを取得します。n8nはこのキーを使ってBright Dataで結果をスクレイピングします。

オープンAI
OpenAIのDeveloper Platformにアクセスして、アカウントを作成してください。そして、”API keys “をクリックしてキーを生成する。

SMTP
このプロセスは、どのSMTPクライアントにも対応しています。現在、私はElastic Emailを使っている。無料プランはこのようなローカルプロジェクトに最適です。ユーザー名、パスワード、サーバー、ポートを保存します。これらをn8nで使ってメールプロセスを自動化します。

ワークフローのステップ

ユーザーがフォームに入力した場合
ユーザがウェブフォームを完了すると、ワークフローが開始されます。自由にこのノードを開いて、パラメータや設定を見てください。しかし、このステップのすべてはあらかじめ設定されているはずなので、編集する必要はありません。

LinkedInのURLと企業検索の作成
フォームが完了すると、2つの別々のワークフローが起動する。
そのうちの1人が、この人物のLinkedInプロフィールを検索するためのGoogle URLを作成する。

もうひとつは、自社のLinkedInを検索するためにGoogleのURLを別に作っている。
これらのURLはどちらも、ブロックされないようにWeb Unlockerに渡される。

結果からHTMLを抽出する
次に、結果からHTMLを抽出します。”Extract Body and Title from Website “という2つのノードがあります。どちらもBright DataのJSONレスポンスからタイトルと 本文を取り出します。

ワークフローでは、これらの強調表示されたステップの両方が同時に起こっている。

ChatGPTによる結果の解析
各検索からタイトルと 本文を引き出したので、処理のためにHTMLの結果をChatGPTに渡します。これらの各ノードには以下のような処理が含まれています。モデル(GPT-4o mini)を定義し、データを抽出するプロンプトを与えます。

下記をご覧いただければわかるように、これは両方のプロセスで同時に起こっている。
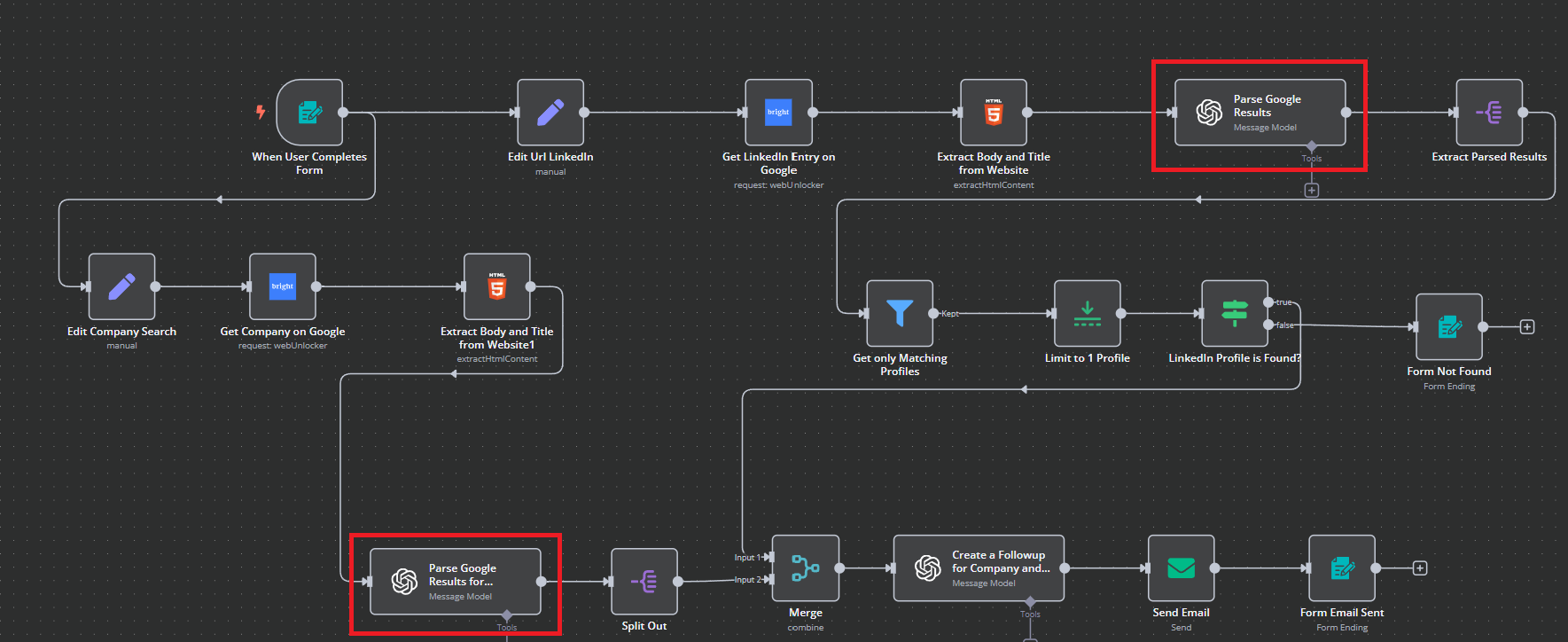
解析された結果を取り出し、分割して企業検索を終了する。
このステップで、別々のワークフローの1つが “Split Out “で終了する。Company “ワークフローが終了すると、”Person “ワークフローから解析結果が抽出されます。
以下は抽出の手順である。ご覧のとおり、基本的には、大きなJSON本体から小さな断片を抜き出しているだけです。

会社 “ワークフローは終了し、”人 “ワークフローはあと数ステップで完了します。Company “ワークフローは、これらのプロセスがマージされるまで一時停止しています!

プロファイルを1つに限定し、その存在を検証する
当社の “Person “ワークフローは、一致するプロファイルのみを使用するように結果をフィルタリングします。次に、プロファイルを1つに限定し、そのプロファイルが存在することを確認します。存在しない場合は、フォームを更新し、プロファイルが見つからなかったことをユーザーに伝えることで対処します。

プロファイルが存在する限り、単一の一貫したワークフローにマージする準備が整った。

ワークフローのマージ
下記のように、両方のワークフローからのデータが入力として使用されます。これらは1つの出力にマージされ、最後にChatGPTに渡されます。

すべてがようやくまとまった。ワークフローが1つにまとまったら、最後のステップを実行しよう。

アウトリーチとフォローアップのステップを作る
さて、この単一の出力をChatGPTに戻してメールを完成させます。カスタムHTMLも書いてくれるので、マークアップコードを気にする必要もありません。

HTMLが戻ってきたら、結果をメールで送る準備ができた。

メールの送信
Send Email “ノードを開き、認証情報と接続の詳細が正しいことを確認する。ご覧のように、メールを作成するためにjson.message.content.contentを渡しています。これは文字通りChatGPTからHTMLを取得し、メール本文に直接貼り付けます。

From Email “を使用しているSMTPメールに変更します。To Email “にメールが送信されます。これを個人のメールに変更すると、個人の受信トレイで結果を受け取ることができます。

完了を示すフォームの更新
最後に、操作が成功したことをユーザーに伝えるためにフォームを更新します。フォームメール送信” を開くと、フォーム更新のためのさまざまなパラメータが表示されます。ご覧のように、”ありがとうございました!”という “完了タイル “と、”メールを送信しました “というメッセージを表示しています。

これでワークフローの最終ステップが終了しました!ワークフローのテスト」ボタンをクリックして、ワークフロー全体がどのように実行されるかを確認してください。

結果
ワークフローを実行する場合、まず検索フォームの入力を求めるポップアップが表示されます。フォームに記入し、「リファレンスを取得」をクリックします。

処理が完了すると、フォームは以下のようになります。ご覧の通り、”Thank you!”と表示され、完了メッセージが表示されています。
受信トレイを開くと、候補者のウェブサイトやLinkedInプロフィールへのリンクが付いた、候補者の詳細な概要が記載された新しいメールが届きます。その下には、ChatGPTからのアウトリーチとフォローアップの推奨が表示されます。

結論
n8n、Bright Data、OpenAI、SMTPを使えば、複雑なコードを書くことなく、完全に自動化されたLinkedInスクレイピングとアウトリーチワークフローを構築できます。この強力なセットアップにより、採用プロセスが合理化され、充実した候補者プロフィールとパーソナライズされたアウトリーチが受信トレイに直接届きます。
採用パイプラインを拡大するにしても、リードジェネレーションを強化するにしても、このワークフローは始まりに過ぎません。ブライトデータでは、自動化を次のレベルに引き上げるためのツール一式を提供しています:
- Web Unlocker: CAPTCHA、ブロック、ボット検知を回避し、LinkedInやその他のサイトを確実にスクレイピング。
- レジデンシャル・プロキシ:世界中のリアルユーザーIPにアクセスし、高い成功率とジオターゲティングを実現します。
- スクレイピング・ブラウザ:JavaScriptを多用するページに最適な、プロキシをサポートしたヘッドレスブラウザ。
- スクレイパーAPI:あらかじめ用意されたスクレイピング・テンプレートを使って、構造化されたデータを簡単に抽出できます。
- データセット:求人情報、企業データなど、すぐに使えるデータセットを活用して、アウトリーチを充実させましょう。
無料トライアルに登録して、今すぐスマートな自動化を始めましょう!





