

インターネットに直接アクセスすると、Web サイトは要求を簡単に追跡し、ユーザーの IP アドレスを割り出せます。このような情報の露出は、ターゲティング広告やオンライントラッキングにつながり、デジタルアイデンティティが危険にさらされる可能性があります。
そこでプロキシの出番です。プロキシはコンピューターとインターネットの間の仲介役となり、デジタルアイデンティティを保護するのに役立ちます。プロキシサーバーを使用すると、ユーザーに代わりそのプロキシ自体の IP アドレスを使用して Web サイトに要求が送信されます。
Web スクレイピングの場合、プロキシは IP によるアクセス禁止やジオブロックを回避し、アイデンティティを保護するのに有効です。この記事では、あらゆる Web スクレイピングプロジェクトで C# でプロキシを実装する方法を解説します。
前提条件
このチュートリアルを始める前に、次のものが揃っていることを確認してください:
- Visual Studio 2022
- .NET 7 またはそれ以降
- HtmlAgilityPack
この記事の例では、別の .NET コンソールアプリケーションを使用しています。独自のコンソールアプリケーションを作成するには、以下のガイドのいずれかを使用できます:
まずはじめに、WebScrapApp と WebScrapBrightData の 2 つのコンソールアプリケーションを作成する必要があります:

Web スクレイピングには、特に HTML コンテンツを扱う場合、HtmlAgilityPack のような特定のツールが必要です。このライブラリは HTML の解析と操作を簡素化し、Web ページからデータをより抽出しやすくします。
両方のプロジェクト (つまり WebScrapApp と WebScrapBrightData) で、NuGet フォルダーを右クリックし、[NuGet パッケージの管理] をクリックして、NuGet パッケージ HtmlAgilityPack を追加します。ポップアップウィンドウが表示されたら、「HtmlAgilityPack」を検索して、両方のプロジェクトにインストールします:

以下のプロジェクトのいずれかを実行するには、コマンドプロンプトでプロジェクトディレクトリに移動し、cd pathtoyourproject に続けて dotnet run を使用する必要があります。または、F5 を押して Visual Studio でプロジェクトを作成して実行することもできます。どちらの方法もアプリケーションをコンパイルして実行し、それに応じて出力を表示します。
注: Visual Studio 2022 がインストールされていない場合、.NET 7 をサポートする任意の IDE を代わりに使用できます。ただし、このガイドの一部の手順が異なる可能性があるのでご注意ください。
ローカルプロキシの設定方法
Web スクレイピングでまずしなければならないのは、プロキシサーバーの使用です。このチュートリアルでは、オープンソースのプロキシ mitmproxy を使用します。
はじめに、mitmproxy のダウンロードページに移動し、バージョン 10.1.6 をダウンロードして、ご使用のオペレーティングシステムに適したバージョンを選択します。さらにガイダンスが必要な場合は、公式の mitmproxy インストールガイドを参照してください。
mitmproxy をインストールしたら、ターミナルを開いて次のコマンドを入力し、起動します:
mitmproxy
シェルまたはターミナルに次のようなウィンドウが表示されます:

プロキシをテストするには、別のターミナルまたはシェルを開き、次の curl 要求を実行します:
curl --proxy http://localhost:8080 "http://wttr.in/Dunedin?0"
出力は次のようになります:
Weather report: Dunedin
Cloudy
.--. +11(9) °C
.-( ). ↙ 15 km/h
(___.__)__) 10 km
0.0 mm
mitmproxy ウィンドウで、ローカルプロキシ経由で呼び出しがインターセプトされたことを確認できます:

C# での Web スクレイピング
次のセクションでは、C# コンソールアプリケーション WebScrapApp を Web スクレイピング用に設定します。このアプリケーションはプロキシサーバーを使用し、効率を高めるためにプロキシローテーションが統合されています。
HttpClient の作成
ProxyHttpClient クラスは、指定されたプロキシサーバー経由で要求をルーティングするよう HttpClient インスタンスを構成します。
WebScrapApp プロジェクトで、ProxyHttpClient.cs という名前の新しいクラスファイルを作成し、次のコードを追加します:
namespace WebScrapApp
{
public class ProxyHttpClient
{
public static HttpClient CreateClient(string proxyUrl)
{
var httpClientHandler = new HttpClientHandler()
{
Proxy = new WebProxy(proxyUrl),
UseProxy = true
};
return new HttpClient(httpClientHandler);
}
}
}
プロキシローテーションの実装
プロキシローテーションを実装するには、WebScrapApp ソリューションの下に ProxyRotator.cs クラスファイルを作成します:
namespace WebScrapApp
{
public class ProxyRotator
{
private List<string> _validProxies = new List<string>();
private readonly Random _random = new();
public ProxyRotator(string[] proxies, bool isLocal)
{
if (isLocal)
{
_validProxies.Add("http://localhost:8080/");
}
else
{
_validProxies = ProxyChecker.GetWorkingProxies(proxies.ToList()).Result;
}
if (_validProxies.Count == 0)
throw new InvalidOperationException();
}
public HttpClient ScrapeDataWithRandomProxy(string url)
{
if (_validProxies.Count == 0)
throw new InvalidOperationException();
var proxyUrl = _validProxies[_random.Next(_validProxies.Count)];
return ProxyHttpClient.CreateClient(proxyUrl);
}
}
}
このクラスはプロキシのリストを管理し、Web 要求ごとにプロキシをランダムに選択するメソッドを提供します。このようなランダム化は、Web スクレイピング中の検出や IP によるアクセス禁止のリスクを減らすうえで鍵となります。
IsLocal が True に設定されている場合、mitmproxy のローカルプロキシが使用されます。False に設定されている場合は、プロキシのパブリック IP が使用されます。
ProxyChecker はプロキシサーバーのリストを検証するために使用されます。
次に、ProxyChecker.cs という名前の新しいクラスファイルを作成し、次のコードを追加します:
using WebScrapApp;
namespace WebScrapApp
{
public class ProxyChecker
{
private static SemaphoreSlim consoleSemaphore = new SemaphoreSlim(1, 1);
private static int currentProxyNumber = 0;
public static async Task<List<string>> GetWorkingProxies(List<string> proxies)
{
var tasks = new List<Task<Tuple<string, bool>>>();
foreach (var proxyUrl in proxies)
{
tasks.Add(CheckProxy(proxyUrl, proxies.Count));
}
var results = await Task.WhenAll(tasks);
var workingProxies = new List<string>();
foreach (var result in results)
{
if (result.Item2)
{
workingProxies.Add(result.Item1);
}
}
return workingProxies;
}
private static async Task<Tuple<string, bool>> CheckProxy(string proxyUrl, int totalProxies)
{
var client = ProxyHttpClient.CreateClient(proxyUrl);
bool isWorking = await IsProxyWorking(client);
await consoleSemaphore.WaitAsync();
try
{
currentProxyNumber++;
Console.WriteLine($"Proxy: {currentProxyNumber} de {totalProxies}");
}
finally
{
consoleSemaphore.Release();
}
return new Tuple<string, bool>(proxyUrl, isWorking);
}
private static async Task<bool> IsProxyWorking(HttpClient client)
{
try
{
var testUrl = "http://www.google.com";
var response = await client.GetAsync(testUrl);
return response.IsSuccessStatusCode;
}
catch
{
return false;
}
}
}
}
このコードは、プロキシサーバーのリストを検証するための ProxyChecker を定義します。GetWorkingProxies メソッドをプロキシ URL のリストで使用すると、CheckProxy メソッドを介して各プロキシのステータスを非同期的にチェックし、稼働中のプロキシを workingProxies リストに収集します。CheckProxy 内で、プロキシ URL を使用して HttpClient を確立し、http://www.google.com に対してテスト要求を行い、セマフォを使用して進行状況を安全に記録します。
isProxyWorking メソッドは、応答ステータスコードでプロキシが機能していることを確認し、稼働中のプロキシに対し true を返します。このクラスは、指定されたリストから稼働しているプロキシを識別するのに役立ちます。
Web データのスクレイピング
データをスクレイピングするには、WebScrapApp ソリューションの下に新しい WebScraper.cs クラスファイルを作成し、次のコードを追加します:
using HtmlAgilityPack;
namespace WebScrapApp
{
public class WebScraper
{
public static async Task ScrapeData(ProxyRotator proxyRotator, string url)
{
try
{
var client = proxyRotator.ScrapeDataWithRandomProxy(url);
// Use HttpClient to make an asynchronous GET request
var response = await client.GetAsync(url);
var content = await response.Content.ReadAsStringAsync();
// Load the HTML content into an HtmlDocument
HtmlDocument doc = new();
doc.LoadHtml(content);
// Use XPath to find all <a> tags that are direct children of <li>, <p>, or <td>
var nodes = doc.DocumentNode.SelectNodes("//li/a[@href] | //p/a[@href] | //td/a[@href]");
if (nodes != null)
{
foreach (var node in nodes)
{
string hrefValue = node.GetAttributeValue("href", string.Empty);
string title = node.InnerText; // This gets the text content of the <a> tag, which is usually the title
// Since Wikipedia URLs are relative, we need to convert them to absolute
Uri baseUri = new(url);
Uri fullUri = new(baseUri, hrefValue);
Console.WriteLine($"Title: {title}, Link: {fullUri.AbsoluteUri}");
// You can process each title and link as required
}
}
else
{
Console.WriteLine("No article links found on the page.");
}
// Add additional logic for other data extraction as needed
}
catch (Exception ex)
{
throw ex;
}
}
}
}
このコードでは、Web スクレイピング機能をカプセル化する WebScraper を定義します。ScrapeData メソッドを呼び出す際、ProxyRotator インスタンスとターゲット URL を指定します。このメソッド内では、HttpClient を使用して URL に対して非同期 GET 要求を行い、HTML コンテンツを取得し、HtmlAgilityPack ライブラリを使用して解析します。次に、XPath クエリを使用して、特定の HTML 要素からリンクと対応するタイトルを検索して抽出します。記事のリンクが見つかった場合は、そのタイトルと絶対 URL を表示し、見つからなかった場合はリンクが見つからなかったことを示すメッセージを表示します。
プロキシローテーションメカニズムを構成し、Web スクレイピング機能を実装したら、これらのコンポーネントをアプリケーションのプライマリエントリーポイント (通常は Program.cs 内) にシームレスに統合する必要があります。この統合により、アプリケーションが Wikipedia ホームページからのデータのスクレイピングに特化したローテーションプロキシを利用し、Web スクレイピングタスクを実行できるようになります:
namespace WebScrapApp {
public class Program
{
static async Task Main(string[] args)
{
string[] proxies = {
"http://162.223.89.84:80",
"http://203.80.189.33:8080",
"http://94.45.74.60:8080",
"http://162.248.225.8:80",
"http://167.71.5.83:3128"
};
var proxyRotator = new ProxyRotator(proxies, false);
string urlToScrape = "https://www.wikipedia.org/";
await WebScraper.ScrapeData(proxyRotator, urlToScrape);
}
}
}
このコードでは、アプリケーションがプロキシ URL のリストを初期化し、ProxyRotator インスタンスを作成して、スクレイピングのターゲット URL (この場合は https://www.wikipedia.org/) を指定し、WebScraper.ScrapeData メソッドを呼び出して Web スクレイピングプロセスを開始します:
アプリケーションがプロキシ配列で指定された利用可能なプロキシ IP のリストを使用して Web スクレイピングの要求をルーティングし、信頼できるソースを隠すことで、Wikipedia サーバーによってブロックされるリスクを最小限に抑えます。ScrapeData メソッドは、Wikipedia ホームページをスクレイピングし、記事のタイトルとリンクを抽出してコンソールに表示するよう設定されています。ProxyRotator クラスはこれらのプロキシのローテーションを行い、スクレイピングの離散性を高めます。
WebScrapApp の実行
WebScrapApp を実行するには、WebScrapApp アプリケーションのルートディレクトリで新しいターミナルまたはシェルを開き、次のコマンドを実行します:
dotnet build
dotnet run
出力は次のようになります:
…output omitted…
Title: Latina, Link: https://la.wikipedia.org/
Title: Latviešu, Link: https://lv.wikipedia.org/
Title: Lietuvių, Link: https://lt.wikipedia.org/
Title: Magyar, Link: https://hu.wikipedia.org/
Title: Македонски, Link: https://mk.wikipedia.org/
Title: Bahasa Melayu, Link: https://ms.wikipedia.org/
Title: Bahaso Minangkabau, Link: https://min.wikipedia.org/
Title: bokmål, Link: https://no.wikipedia.org/
Title: nynorsk, Link: https://nn.wikipedia.org/
Title: Oʻzbekcha / Ўзбекча, Link: https://uz.wikipedia.org/
Title: Қазақша / Qazaqşa / قازاقشا, Link: https://kk.wikipedia.org/
Title: Română, Link: https://ro.wikipedia.org/
Title: Simple English, Link: https://simple.wikipedia.org/
Title: Slovenčina, Link: https://sk.wikipedia.org/
Title: Slovenščina, Link: https://sl.wikipedia.org/
Title: Српски / Srpski, Link: https://sr.wikipedia.org/
Title: Srpskohrvatski / Српскохрватски, Link: https://sh.wikipedia.org/
Title: Suomi, Link: https://fi.wikipedia.org/
Title: தமிழ், Link: https://ta.wikipedia.org/
…output omitted…
WebScraper クラスの ScrapeData メソッドが呼び出されると、Wikipedia からのデータ抽出が実行され、記事のタイトルとそれに対応するリンクがコンソールに表示されます。このコードは一般利用可能なプロキシを使用しており、アプリケーションを実行するたびに、リストの IP アドレスのいずれかをプロキシとして選択します。
mitmproxy のローカルプロキシでテストするには、Program ファイルの ProxyRotator メソッドを次のように更新します:
var proxyRotator = new ProxyRotator(proxies, true)
string urlToScrape = "http://toscrape.com/";
値を true に設定すると、localhost ポート 8080 (つまり mitmproxy サーバー) で実行されているローカルプロキシサーバーが使用されます。
マシンに証明書を設定する際の構成プロセスを簡素化するには、URL を http://toscrape.com/ に変更します。
mitmproxy サーバーが稼働中であることを確認してから、同じコマンドをもう一度実行します:
dotnet build
dotnet run
出力は次のようになります:
…output omitted…
Title: fictional bookstore, Link: http://books.toscrape.com/
Title: books.toscrape.com, Link: http://books.toscrape.com/
Title: A website, Link: http://quotes.toscrape.com/
Title: Default, Link: http://quotes.toscrape.com/
Title: Scroll, Link: http://quotes.toscrape.com/scroll
Title: JavaScript, Link: http://quotes.toscrape.com/js
Title: Delayed, Link: http://quotes.toscrape.com/js-delayed
Title: Tableful, Link: http://quotes.toscrape.com/tableful
Title: Login, Link: http://quotes.toscrape.com/login
Title: ViewState, Link: http://quotes.toscrape.com/search.aspx
Title: Random, Link: http://quotes.toscrape.com/random
…output omitted…
ターミナルまたはシェルで mitmproxy ウィンドウを確認すると、呼び出しがインターセプトされたことを確認できます:

ご覧のとおり、ローカルプロキシの設定やさまざまなプロキシの切り替えは、複雑で時間がかかる場合があります。しかし、Bright Data のようなツールを使えば、そのような課題を解決できます。次のセクションでは、Bright Data のプロキシサーバーを使用してスクレイピングプロセスを簡素化する方法を解説します。
Bright Data のプロキシ
Bright Data は、195 か所に広がるプロキシサービスネットワークを提供しています。このネットワークには Bright Data プロキシローテーション機能が統合されており、システムによりサーバーを切り替えることで、より効果的で安全な Web スクレイピングが可能になります。
このローテーションプロキシシステムを使用すると、Web スクレイピング中に通常発生する IP によるアクセス禁止やブロックのリスクが軽減されます。要求ごとに異なるプロキシが使用されるため、スクレイパーのアイデンティティがわからなくなり、Web サイトによる検出やアクセス制限が難しくなります。このアプローチにより、データ収集の信頼性が高まり、匿名性とセキュリティが強化されます。
Bright Data プラットフォームは、使いやすく、簡単にセットアップできる設計のため、次のセクションでご覧いただくとおり、C# での Web スクレイピングプロジェクトに最適です。
住宅用プロキシの作成
プロジェクトで Bright Data プロキシを使用する前に、アカウントを設定する必要があります。アカウントを設定するには、Bright Data の Web サイトにアクセスし、無料トライアルに登録します。
アカウントを設定したらサインインし、左側のロケーションアイコンをクリックして、プロキシとスクレイピングインフラストラクチャに移動します。次に、[[追加] をクリックして [住宅用プロキシ] を選択します:

デフォルトの名前のまま [追加] をもう一度クリックして、住宅用プロキシを作成します:

プロキシを作成したら、ホスト、ポート、ユーザー名、パスワードなどの認証情報が表示されます。これらの認証情報は後で必要になるため、安全な場所に保管してください:
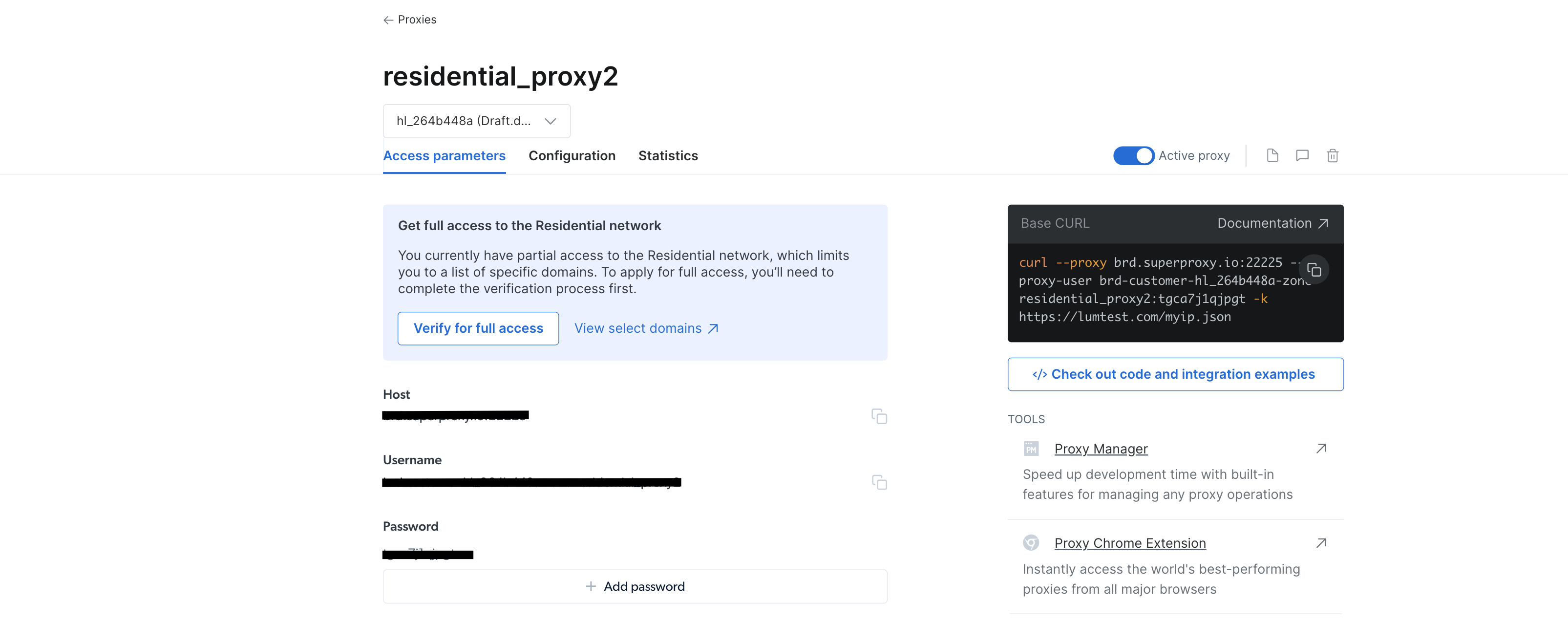
IDE またはターミナル/シェルで WebScrapingBrightData プロジェクトに移動します。次に、BrightDataProxyConfigurator.cs クラスファイルを作成し、次のコードを追加します:
using System.Net;
namespace WebScrapBrightData
{
public class BrightDataProxyConfigurator
{
public static HttpClient ConfigureHttpClient(string proxyHost, string proxyUsername, string proxyPassword)
{
var proxy = new WebProxy(proxyHost) {
Credentials = new NetworkCredential(proxyUsername, proxyPassword)
};
var httpClientHandler = new HttpClientHandler() {
Proxy = proxy,
UseProxy = true
};
var client = new HttpClient(httpClientHandler);
client.DefaultRequestHeaders.Add("User-Agent", "YourUserAgent");
client.DefaultRequestHeaders.Add("Accept", "application/json");
client.DefaultRequestHeaders.TryAddWithoutValidation("Proxy-Authorization", Convert.ToBase64String(System.Text.Encoding.UTF8.GetBytes($"{proxyUsername}:{proxyPassword}")));
return client;
}
}
}
このコードでは、BrightDataProxyConfigurator クラスを定義し、このクラスには ConfigureHttpClient メソッドが含まれます。このメソッドは呼び出されると、プロキシサーバーを使用するよう設定された HttpClient を構成し、返します。このプロセスを行うには、提供されたユーザー名、パスワード、ホスト、ポートを使用してプロキシ URL を作成し、このプロキシで HttpClientHandler を構成します。このメソッドは最終的に、すべての要求を指定されたプロキシ経由でルーティングする HttpClient インスタンスを返します。
次に、WebScrapingBrightData プロジェクトの下に WebContentScraper.cs クラスファイルを作成し、次のコードを追加します:
using HtmlAgilityPack;
namespace WebScrapBrightData
{
public class WebContentScraper
{
public static async Task ScrapeContent(string url, HttpClient client)
{
var response = await client.GetAsync(url);
var content = await response.Content.ReadAsStringAsync();
HtmlDocument doc = new();
doc.LoadHtml(content);
var nodes = doc.DocumentNode.SelectNodes("//li/a[@href] | //p/a[@href] | //td/a[@href]");
if (nodes != null)
{
foreach (var node in nodes)
{
string hrefValue = node.GetAttributeValue("href", string.Empty);
string title = node.InnerText;
Uri baseUri = new(url);
Uri fullUri = new(baseUri, hrefValue);
Console.WriteLine($"Title: {title}, Link: {fullUri.AbsoluteUri}");
}
}
else
{
Console.WriteLine("No article links found on the page.");
}
}
}
}
このコードは WebContentScraper クラスを静的非同期メソッド ScrapeContent で定義します。このメソッドは URL と HttpClient を受け取り、Web ページのコンテンツを取得して HTML として解析し、特定の HTML 要素 (リスト項目、段落、表のセル) からリンクを抽出します。次に、これらのリンクのタイトルと絶対 URI をコンソールに表示します。
Program クラス
それでは、もう一度 Wikipedia をスクレイピングして、Bright Data がどのようにアクセスと匿名性を向上させるか見てみましょう。
Program.cs クラスファイルを次のコードで更新します:
namespace WebScrapBrightData
{
public class Program
{
public static async Task Main(string[] args)
{
// Bright Data Proxy Configuration
string host = "your_brightdata_proxy_host";
string username = "your_brightdata_proxy_username";
string password = "your_brightdata_proxy_password";
var client = BrightDataProxyConfigurator.ConfigureHttpClient(host, username, password);
// Scrape content from the target URL
string urlToScrape = "https://www.wikipedia.org/";
await WebContentScraper.ScrapeContent(urlToScrape, client);
}
}
}
注: Bright Data のプロキシ認証情報は、先ほど保存したものと置き換えます。
次に、アプリケーションをテストして実行するには、WebScrapBrightData プロジェクトのルートディレクトリからシェルまたはターミナルを開き、次のコマンドを実行します:
dotnet build
dotnet run
パブリックプロキシを使用したときと同じ出力が得られます:
…output omitted…
Title: Latina, Link: https://la.wikipedia.org/
Title: Latviešu, Link: https://lv.wikipedia.org/
Title: Lietuvių, Link: https://lt.wikipedia.org/
Title: Magyar, Link: https://hu.wikipedia.org/
Title: Македонски, Link: https://mk.wikipedia.org/
Title: Bahasa Melayu, Link: https://ms.wikipedia.org/
Title: Bahaso Minangkabau, Link: https://min.wikipedia.org/
Title: bokmål, Link: https://no.wikipedia.org/
Title: nynorsk, Link: https://nn.wikipedia.org/
Title: Oʻzbekcha / Ўзбекча, Link: https://uz.wikipedia.org/
Title: Қазақша / Qazaqşa / قازاقشا, Link: https://kk.wikipedia.org/
Title: Română, Link: https://ro.wikipedia.org/
Title: Simple English, Link: https://simple.wikipedia.org/
Title: Slovenčina, Link: https://sk.wikipedia.org/
Title: Slovenščina, Link: https://sl.wikipedia.org/
Title: Српски / Srpski, Link: https://sr.wikipedia.org/
Title: Srpskohrvatski / Српскохрватски, Link: https://sh.wikipedia.org/
Title: Suomi, Link: https://fi.wikipedia.org/
Title: தமிழ், Link: https://ta.wikipedia.org/
…output omitted…
このプログラムは Bright Data のプロキシを使用して Wikipedia ホームページをスクレイピングし、抽出されたタイトルとリンクをコンソールに表示します。以上で、Bright Data のプロキシを C# での Web スクレイピングプロジェクトに統合すると、どれだけ簡単かつ効果的にアイデンティティを特定されず堅牢なデータ抽出が可能になるか、おわかりいただけたことでしょう。
Bright Data のプロキシを使用した場合の効果を視覚的に把握するには、http://lumtest.com/myip.json に GET 要求を送信してみましょう。この Web サイトは、現在同 Web サイトにアクセスしようとしているクライアントの位置やその他のネットワーク関連の詳細を返します。ご自身で試してみたい方は、新しいブラウザタブでリンクを開いてください。自分の公開されているネットワーク詳細が表示されます。
Bright Data のプロキシで試すには、WebContentScraper.cs のコードを以下と一致するように更新します:
using HtmlAgilityPack;
public class WebContentScraper
{
public static async Task ScrapeContent(string url, HttpClient client)
{
var response = await client.GetAsync(url);
var content = await response.Content.ReadAsStringAsync();
HtmlDocument doc = new();
doc.LoadHtml(content);
Console.Write(content);
}
}
次に、Program.cs ファイルの urlToScrape 変数を更新して Web サイトをスクレイピングします:
string urlToScrape = "http://lumtest.com/myip.json";
ここで、アプリをもう一度実行してみてください。ターミナルに次のような出力が表示されます:
{"ip":"79.221.123.68","country":"DE","asn":{"asnum":3320,"org_name":"Deutsche Telekom AG"},"geo":{"city":"Koenigs Wusterhausen","region":"BB","region_name":"Brandenburg","postal_code":"15711","latitude":52.3014,"longitude":13.633,"tz":"Europe/Berlin","lum_city":"koenigswusterhausen","lum_region":"bb"}}
これにより、要求が Bright Data のプロキシサーバーを経由していることが確認できます。
まとめ
この記事では、C# での Web スクレイピングにプロキシサーバーを使用する方法を解説しました。
ローカルプロキシサーバーは、シナリオによっては有効ですが、通常 Web スクレイピングプロジェクトでは制約が課されます。しかし、プロキシサーバーを使用すれば、そのような課題を解決できます。広範なグローバルネットワークと、住宅用、ISP、データセンター、モバイルプロキシなどの多様なプロキシオプションにより、Bright Data は高い柔軟性と信頼性を保証します。特に、プロキシローテーション機能は大規模なスクレイピングにおいて非常に重要となり、匿名性を維持し、IP によるアクセス禁止のリスクを軽減するのに役立ちます。
Web スクレイピングの取り組みを続けるにあたり、Web スクレイピングのベストプラクティスに従い、効率的にデータを収集するための強力かつスケーラブルな手段として、Bright Data ソリューションの使用をご検討ください。
このチュートリアルで使用されたコードは、すべてこちらの GitHub リポジトリで利用できます。





